

Spark Streaming 读取 Kafka 中数据
一、什么是 Spark Streaming
1、SparkStreaming 是 Spark核心API 的扩展。可实现可伸缩、高吞吐、容错机制的实时流处理。
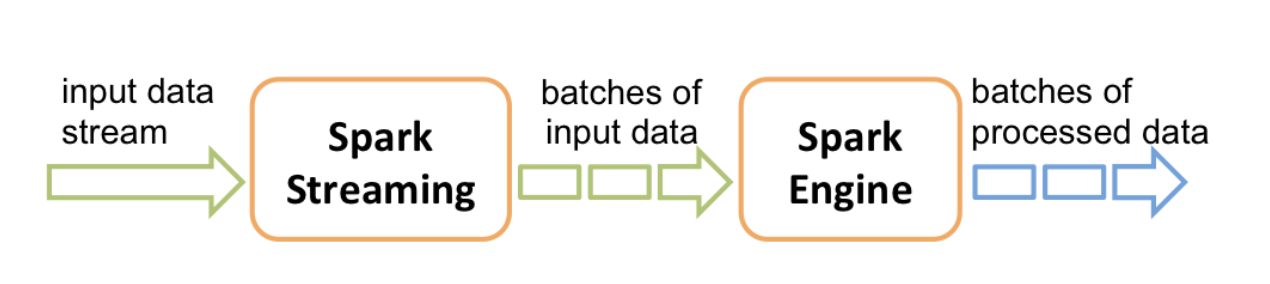
如图,数据可从 Kafka、Flume、HDFS 等多种数据源获得,最后将数据推送到 HDFS、数据库 或者 Dashboards 上面。

2、SparkStreaming 接收到实时的数据,然后按照时间段将实时数据分成多个批次,经过Spark处理引擎的数据处理,最后按照批次输出。
3、SparkStreaming 提供了一个高抽象的离散流或者叫做 DStream,它相当于连续的数据流。
外部数据不断的涌入,数据按照自定义的时间将数据进行切片,每个时间段内的数据是连续的,时间段与时间段之间的关系史相互独立的。这就是 离散流。
DStream 是 RDD 的序列化,DStream 可以看作一组 RDD 的集合。

4、在DStream上执行的任何操作都转换为对基础RDD的操作。
二、需要的maven包
<!-- Spark Streaming --> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-streaming_2.11</artifactId> <version>${spark.version}</version> </dependency> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-streaming-kafka-0-10_2.11</artifactId> <version>${spark.version}</version> </dependency> <!-- config的统一配置 --> <dependency> <groupId>com.typesafe</groupId> <artifactId>config</artifactId> <version>1.3.3</version> </dependency> <!-- json格式转化 --> <dependency> <groupId>com.alibaba</groupId> <artifactId>fastjson</artifactId> <version>1.2.62</version> </dependency>
三、项目参数的配置文件
首先在 src/resources 路径下创建一个 application.conf 文件,上面 maven 文件中添加的 config 依赖默认会读取 src/resources 路径下的 application.conf 文件。
applicaltion.conf
kafka.topic = "topicName"
kafka.group.id = "Your group"
kafka.broker.list = "your Kafka's host:port"
redis.host = "redisIP, no port"
redis.db=1
Redis 会有 16个库,这里面 redis.db=1,代表我会将数据存入到redis的1库中。
然后我会创建一个 Object,通过 ConfigFactory 来获取 application 中的参数的值.
object ParamsConf {
private lazy val conf = ConfigFactory.load()
val topics = conf.getString("kafka.topic").split(",")
val groupId = conf.getString("kafka.group.id")
val brokers = conf.getString("kafka.broker.list")
val redisHost = conf.getString("redis.host")
val redisDB = conf.getInt("redis.db")
val kafkaParams = Map[String, Object](
"bootstrap.servers" -> brokers,
"key.deserializer" -> classOf[StringDeserializer],
"value.deserializer" -> classOf[StringDeserializer],
"group.id" -> groupId,
"auto.offset.reset" -> "latest",
"enable.auto.commit" -> (false: java.lang.Boolean)
)
}
这样项目就会很方便的通过这个工具类来获取到统一的参数配置了。
四、向 Kafka 传入 Demo 数据
通过 KafkaProducer 创建与 Kafka 之间的连接,KafkaProducer 在创建对象的时候需要传入生产者的配置参数。通过读 Source Code 都可以查到对应的参数配置
val prop = new Properties()
// 序列化用到的 key、value
prop.put("key.serializer","org.apache.kafka.common.serialization.StringSerializer")
prop.put("value.serializer","org.apache.kafka.common.serialization.StringSerializer")
// kafka的地址,在上面的配置里
prop.put("bootstrap.servers", ParamsConf.brokers)
prop.put("request.required.acks", "1")
val topic = ParamsConf.topics(0)
val producer = new KafkaProducer[String, String](prop)
其中 request.required.acks 是 Kafka 的发送确认,有 -1、0、1 三个级别。-1 代表 producer 会获得所有同步replicas 都收到数据的确认,才会发下一条消息;0代表 producer 不等待确认消息,producer中有message就会发给broker;1代表 获得leader replica已经接收了数据的确认信息。
之后利用循环编造数据,并将数据发送给 Kafka
val random = new Random()
val dateFormat = FastDateFormat.getInstance("yyyyMMddHHmmss")
for(i <- 1 to 100) {
val time = dateFormat.format(new Date())
val userId = random.nextInt(1000).toString
val courseid = random.nextInt(500).toString
val fee = random.nextInt(400).toString
val result = Array("0","1") // 0 表示未成功;1 表示成功
val flag = result(random.nextInt(2)).toString
var orderId = UUID.randomUUID().toString()
val map = new util.HashMap[String, Object]()
map.put("time",time)
map.put("userId",userId)
map.put("courseid",courseid)
map.put("fee",fee)
map.put("result",result)
map.put("flag",flag)
map.put("orderId",orderId)
val json = new JSONObject(map)
producer.send(new ProducerRecord[String, String](topic, i.toString, json.toString()))
}
五、 Spark Streaming 对接 Kafka
初始化 SparkStreaming 程序,首先需要创建 StreamingContext。StreamingContext的创建方式:
val conf = new SparkConf().setMaster("local[2]").setAppName("hunterV2")
val sc = new SparkContext(conf)
val ssc = new StreamingContext(sc, Seconds(5))
...
... Do Something...
...
ssc.start()
ssc.awaitTermination()
在逻辑代码之后要调用 ssc.start() 来开始实时处理数据。ssc.awaitTermination() 方法也是必需的, 来等待应用程序的终止,也可以用 ssc.stop() 来终止程序。或者就是让它持续不断的运行进行计算
通过 KafkaUtils 以直连方式拉取数据,这种方式不会修改数据的偏移量,需要手动的更新
val stream = KafkaUtils.createDirectStream(ssc,
LocationStrategies.PreferConsistent,
ConsumerStrategies.Subscribe[String, String](ParamsConf.topics, ParamsConf.kafkaParams))
createDirectStream 有三个参数,查看 Source Code
def createDirectStream[K, V](
ssc: StreamingContext,
locationStrategy: LocationStrategy,
consumerStrategy: ConsumerStrategy[K, V]
)
前两个参数较明确,第三个参数中则是要添加 kafka 的 topic 以及 Kafka 的信息,在 ParamsConf 中已经定义好了,这个也可以在官网文档中可以找到。(https://spark.apache.org/docs/latest/streaming-kafka-0-10-integration.html)
拉取数据之后,SparkStreaming 提供的 stream 变量是 DStream 类型数据。DStream 是一组 RDD 的序列,DStream 任何操作都转换为对基础 RDD 的操作。因此需要用到 DStream 的 action -- foreachRDD.
stream.foreachRDD( rdd => {
val offsetRanges = rdd.asInstanceOf[HasOffsetRanges].offsetRanges
...
... Do SomeThing
...
stream.asInstanceOf[CanCommitOffsets].commitAsync(offsetRanges)
})
在逻辑代码的前后有两行 关于 offsetRanges 的语句,这是 kafka 自带的用作管理 offset 的语句。第一句是读取当前的偏移量的数据,逻辑执行成功之后,最后一句是将偏移量提交到 Kafka 上。(https://spark.apache.org/docs/latest/streaming-kafka-0-10-integration.html#kafka-itself)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号