

高并发分布式系统中生成全局唯一Id汇总
高并发分布式系统中生成全局唯一Id汇总
(转自:http://www.cnblogs.com/baiwa/p/5318432.html)
数据在分片时,典型的是分库分表,就有一个全局ID生成的问题。
单纯的生成全局ID并不是什么难题,但是生成的ID通常要满足分片的一些要求:
1 不能有单点故障。
2 以时间为序,或者ID里包含时间。这样一是可以少一个索引,二是冷热数据容易分离。
3 可以控制ShardingId。比如某一个用户的文章要放在同一个分片内,这样查询效率高,修改也容易。
4 不要太长,最好64bit。使用long比较好操作,如果是96bit,那就要各种移位相当的不方便,还有可能有些组件不能支持这么大的ID。
一 twitter
twitter在把存储系统从MySQL迁移到Cassandra的过程中由于Cassandra没有顺序ID生成机制,于是自己开发了一套全局唯一ID生成服务:Snowflake。
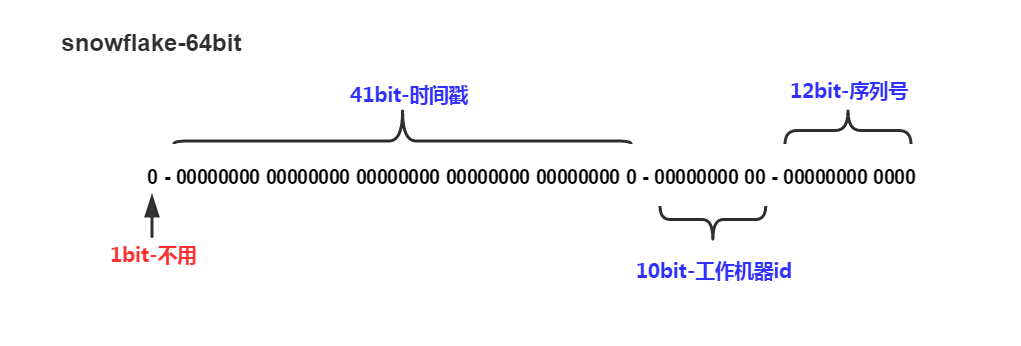
1 41位的时间序列(精确到毫秒,41位的长度可以使用69年)
2 10位的机器标识(10位的长度最多支持部署1024个节点)
3 12位的计数顺序号(12位的计数顺序号支持每个节点每毫秒产生4096个ID序号) 最高位是符号位,始终为0。
优点:高性能,低延迟;独立的应用;按时间有序。 缺点:需要独立的开发和部署。
原理
java 实现代码
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
|
public class IdWorker {private final long workerId;private final static long twepoch = 1288834974657L;private long sequence = 0L;private final static long workerIdBits = 4L;public final static long maxWorkerId = -1L ^ -1L << workerIdBits;private final static long sequenceBits = 10L;private final static long workerIdShift = sequenceBits;private final static long timestampLeftShift = sequenceBits + workerIdBits;public final static long sequenceMask = -1L ^ -1L << sequenceBits;private long lastTimestamp = -1L;public IdWorker(final long workerId) {super();if (workerId > this.maxWorkerId || workerId < 0) {throw new IllegalArgumentException(String.format("worker Id can't be greater than %d or less than 0",this.maxWorkerId));}this.workerId = workerId;}public synchronized long nextId() {long timestamp = this.timeGen();if (this.lastTimestamp == timestamp) {this.sequence = (this.sequence + 1) & this.sequenceMask;if (this.sequence == 0) {System.out.println("###########" + sequenceMask);timestamp = this.tilNextMillis(this.lastTimestamp);}} else {this.sequence = 0;}if (timestamp < this.lastTimestamp) {try {throw new Exception(String.format("Clock moved backwards. Refusing to generate id for %d milliseconds",this.lastTimestamp - timestamp));} catch (Exception e) {e.printStackTrace();}}this.lastTimestamp = timestamp;long nextId = ((timestamp - twepoch << timestampLeftShift))| (this.workerId << this.workerIdShift) | (this.sequence);System.out.println("timestamp:" + timestamp + ",timestampLeftShift:"+ timestampLeftShift + ",nextId:" + nextId + ",workerId:"+ workerId + ",sequence:" + sequence);return nextId;}private long tilNextMillis(final long lastTimestamp) {long timestamp = this.timeGen();while (timestamp <= lastTimestamp) {timestamp = this.timeGen();}return timestamp;}private long timeGen() {return System.currentTimeMillis();}public static void main(String[] args){IdWorker worker2 = new IdWorker(2);System.out.println(worker2.nextId());}} |
2 来自Flicker的解决方案
因为MySQL本身支持auto_increment操作,很自然地,我们会想到借助这个特性来实现这个功能。
Flicker在解决全局ID生成方案里就采用了MySQL自增长ID的机制(auto_increment + replace into + MyISAM)。一个生成64位ID方案具体就是这样的:
先创建单独的数据库(eg:ticket),然后创建一个表:
|
1
2
3
4
5
6
|
CREATE TABLE Tickets64 (id bigint(20) unsigned NOT NULL auto_increment,stub char(1) NOT NULL default '',PRIMARY KEY (id),UNIQUE KEY stub (stub)) ENGINE=MyISAM |
当我们插入记录后,执行SELECT * from Tickets64,查询结果就是这样的:
+-------------------+------+
| id | stub |
+-------------------+------+
| 72157623227190423 | a |
+-------------------+------+
在我们的应用端需要做下面这两个操作,在一个事务会话里提交:
|
1
2
|
REPLACE INTO Tickets64 (stub) VALUES ('a');SELECT LAST_INSERT_ID(); |
这样我们就能拿到不断增长且不重复的ID了。
到上面为止,我们只是在单台数据库上生成ID,从高可用角度考虑,接下来就要解决单点故障问题:Flicker启用了两台数据库服务器来生成ID,通过区分auto_increment的起始值和步长来生成奇偶数的ID。
|
1
2
3
4
5
6
7
|
TicketServer1:auto-increment-increment = 2auto-increment-offset = 1TicketServer2:auto-increment-increment = 2auto-increment-offset = 2 |
最后,在客户端只需要通过轮询方式取ID就可以了。
优点:充分借助数据库的自增ID机制,提供高可靠性,生成的ID有序。
缺点:占用两个独立的MySQL实例,有些浪费资源,成本较高。
三 UUID
UUID生成的是length=32的16进制格式的字符串,如果回退为byte数组共16个byte元素,即UUID是一个128bit长的数字,
一般用16进制表示。
算法的核心思想是结合机器的网卡、当地时间、一个随即数来生成UUID。
从理论上讲,如果一台机器每秒产生10000000个GUID,则可以保证(概率意义上)3240年不重复
优点:
(1)本地生成ID,不需要进行远程调用,时延低
(2)扩展性好,基本可以认为没有性能上限
缺点:
(1)无法保证趋势递增
(2)uuid过长,往往用字符串表示,作为主键建立索引查询效率低,常见优化方案为“转化为两个uint64整数存储”或者“折半存储”(折半后不能保证唯一性)
四 基于redis的分布式ID生成器
首先,要知道redis的EVAL,EVALSHA命令:
原理
利用redis的lua脚本执行功能,在每个节点上通过lua脚本生成唯一ID。
生成的ID是64位的:
使用41 bit来存放时间,精确到毫秒,可以使用41年。
使用12 bit来存放逻辑分片ID,最大分片ID是4095
使用10 bit来存放自增长ID,意味着每个节点,每毫秒最多可以生成1024个ID
比如GTM时间 Fri Mar 13 10:00:00 CST 2015 ,它的距1970年的毫秒数是 1426212000000,假定分片ID是53,自增长序列是4,则生成的ID是:
5981966696448054276 = 1426212000000 << 22 + 53 << 10 + 41
redis提供了TIME命令,可以取得redis服务器上的秒数和微秒数。因些lua脚本返回的是一个四元组。
second, microSecond, partition, seq
客户端要自己处理,生成最终ID。
((second * 1000 + microSecond / 1000) << (12 + 10)) + (shardId << 10) + seq;
五 MongoDB文档(Document)全局唯一ID
为了考虑分布式,“_id”要求不同的机器都能用全局唯一的同种方法方便的生成它。因此不能使用自增主键(需要多台服务器进行同步,既费时又费力),
因此选用了生成ObjectId对象的方法。
ObjectId使用12字节的存储空间,其生成方式如下:
|0|1|2|3|4|5|6 |7|8|9|10|11|
|时间戳 |机器ID|PID|计数器 |
前四个字节时间戳是从标准纪元开始的时间戳,单位为秒,有如下特性:
1 时间戳与后边5个字节一块,保证秒级别的唯一性;
2 保证插入顺序大致按时间排序;
3 隐含了文档创建时间;
4 时间戳的实际值并不重要,不需要对服务器之间的时间进行同步(因为加上机器ID和进程ID已保证此值唯一,唯一性是ObjectId的最终诉求)。
机器ID是服务器主机标识,通常是机器主机名的散列值。
同一台机器上可以运行多个mongod实例,因此也需要加入进程标识符PID。
前9个字节保证了同一秒钟不同机器不同进程产生的ObjectId的唯一性。后三个字节是一个自动增加的计数器(一个mongod进程需要一个全局的计数器),保证同一秒的ObjectId是唯一的。同一秒钟最多允许每个进程拥有(256^3 = 16777216)个不同的ObjectId。
总结一下:时间戳保证秒级唯一,机器ID保证设计时考虑分布式,避免时钟同步,PID保证同一台服务器运行多个mongod实例时的唯一性,最后的计数器保证同一秒内的唯一性(选用几个字节既要考虑存储的经济性,也要考虑并发性能的上限)。
"_id"既可以在服务器端生成也可以在客户端生成,在客户端生成可以降低服务器端的压力。
