决策树(Decision Tree)&ID3
决策树(Decision Tree)
本文学习内容来自西瓜书和机器学习导论。
什么是决策树
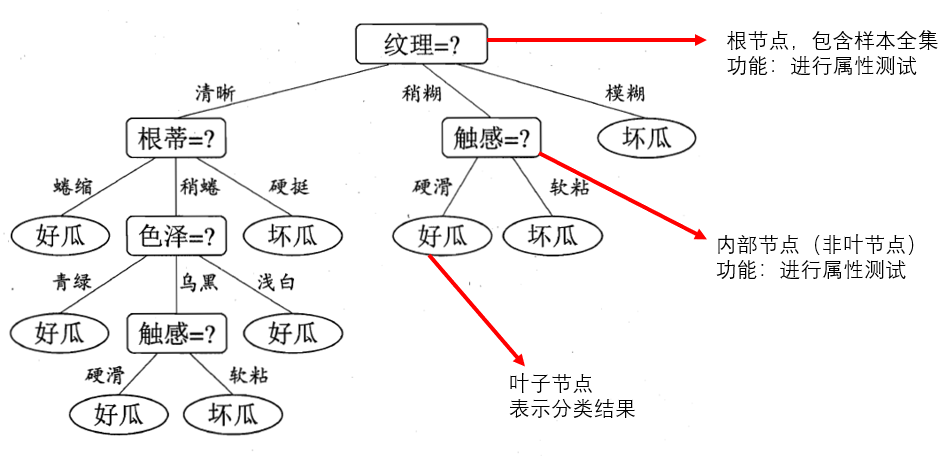
目的:产生一棵泛化能力强的决策树。泛化能力强指对非训练集的样本进行预测时仍能保持较高的准确性。
思想:分治(divide and conquer)
算法

\((x_1,y_1)\)表示第一个样本,\(x_1\)为该样本在各个属性中值的集合\(\{x_{11},x_{12}...x_{1n}\}\),\(y_1\)指该样本的类别(好瓜or坏瓜)。
图中算法为递归算法,共有三处可返回递归:
- line 2~3:当前节点下的所有样本均属于同一类别,将此节点记为叶节点,并标记出分类结果。
- line 5~7:当前节点下属性值为空(不再有可以用于划分的属性),或者所有样本在所有属性上取值相同,此时无法进行下一步划分,那么将此节点记为叶节点,分类结果为大多数样本的类别。
- line 11~12:当前无样本,无法划分,将其记为叶节点,分类结果为其父节点中大多数样本的类别。
第二点使用的是当前节点的后验分布。
后验分布:
其中\(\theta\)为我们要估计的参数,这里可以理解为用于判断样本类别的函数,\(x\)为已知的参数,可以理解为我们现在对这些样本的属性值和类别都已知。\(c_x\)为\(f(x)\)的倒数,这里可视为常数。\(L(\theta,x)\)为最大似然估计。\(g(\theta)\)为先验分布。
第三点把父节点的样本分布作为当前节点的先验分布。
以上是我对西瓜书上内容的理解,不太准确,希望大神不吝赐教。
然后我们来介绍决策树的第一个算法:ID3。
ID3(Iterative Dichotomiser 3)
如何选择最优划分属性
在非叶节点中,我们需要找到一个属性,通过样本在该属性上取值的不同,将其分类,最终得到我们的决策树。
那么如何来评判这个属性是否适合用来划分样本集呢?
信息熵(Information Entropy)
信息熵度量样本的纯度,信息熵越小代表样本越纯。
| 样本 | 性别 |
|---|---|
| 男 | |
| 女 |
| 样本 | 性别 |
|---|---|
| 男 | |
| 女 |
以上两个样本集均为6个人,第一个样本集男女各为3人,第二个样本集男生达到5人,女生只有1人。我们称第二个样本集的纯度较高。
其中,\(D\)表示所有用于计算样本。\(p_k\)表示样本属于第\(k\)个类别的概率。\(\gamma\)表示样本中共有多少种不同的类别。
若所有样本均属于同一类别,此时我们记:\(0\log_20\equiv0\)。
仅仅了解信息熵是不够的,我们需要判断如果使用某个属性作为划分属性,那么是否会使分类后的样本纯度提高。
信息增益(Information Gain)
对于某个属性\(a\)以及样本集\(D\),我们可以计算信息增益:
其中\(|D|\)表示\(D\)中样本的数量,\(|D^v|\)表示样本集中在\(a\)属性上值为\(v\)的样本数量
信息增益越大,表示用此属性进行划分后的样本集纯度提高程度越大。所以我们要找到:
举个例子,对于西瓜书P76表4.1:
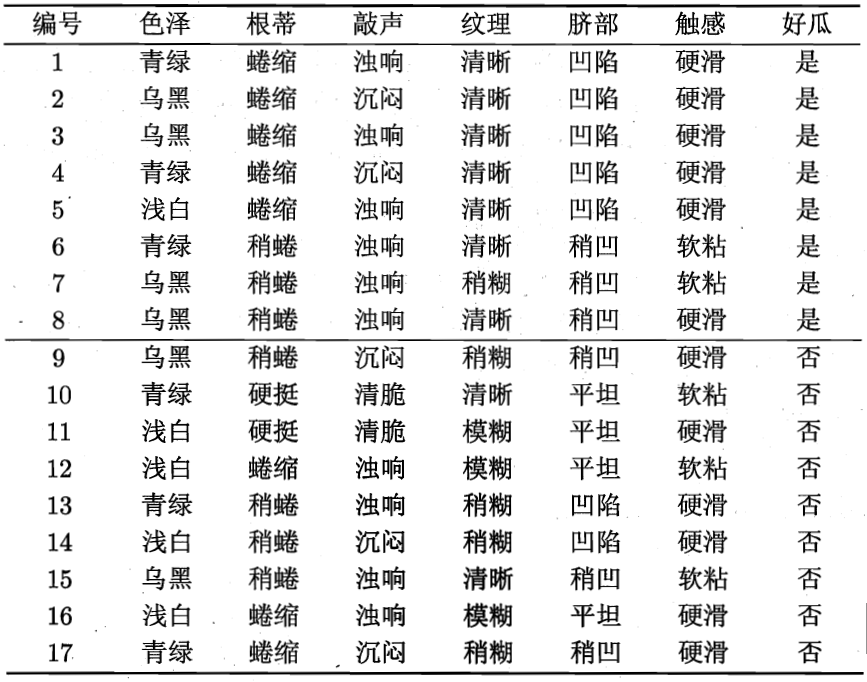
\(\gamma=2\),好瓜or坏瓜
我们选择属性“色泽 ”,可以看到:
\(V=3\),分别为“青绿”,“乌黑”,“浅白”。
\(|D_1|=6\),“青绿”,其中好瓜3个,坏瓜3个。
\(|D_2|=6\),“乌黑”,其中好瓜4个,坏瓜2个。
\(|D_3|=5\),“浅白”,其中好瓜1个,坏瓜4个。
则:
然后我们在所有的属性中找到最优的属性,作为此节点的划分属性。然后对分类后的每一个样本子集递归计算最优划分属性。
但是我们使用信息增益会有什么问题么?看下表
| 序号 | 居住地 | 学历 | 性别 |
|---|---|---|---|
| 1 | 北京 | 小学 | 男 |
| 2 | 北京 | 初中 | 男 |
| 3 | 北京 | 高中 | 女 |
| 4 | 北京 | 大学 | 女 |
| 5 | 上海 | 小学 | 女 |
| 6 | 上海 | 初中 | 女 |
| 7 | 上海 | 高中 | 男 |
| 8 | 上海 | 大学 | 男 |
对于“居住地”属性来说:
对于“学历”属性来说:
之前学的比较浅,单纯的知道信息增益倾向于选择可取值数目较多的属性,其实这是很片面的!
如上表计算,“学历”属性明显比“居住地”属性取值要多\((4>2)\),但是通过计算,选择两个属性的信息增益相同,说明选择这两个属性进行划分的效果相同。仔细分析数据,发现这个结论也符合常识。
所以我仔细查了一下信息增益的缺点。当我们只处理离散值时,其实信息增益和之后要说的信息增益率其实差别不大,但是当我们的属性为离散值的时候就很有帮助了。
如果我们把序号也作为一个侯选属性,那么很明显信息增益会选择序号作为侯选属性。更直观的例子:对于中国人这个群体,我们会直接选取身份证号来作为最优划分属性,但是这样得到的是广度很大,深度很浅的一颗分类树。
这当然不是我们想要的,所以这才是信息增益的缺点所在。
那么如何解决这个问题呢?伟大的学者就搞出了C4.5这个东西。请看下章
Code
使用的jupyter-notebook,可以先下载Anaconda再使用。

