influxDB框架 & 数据存储 & TSM & 数据操作等详解
influxdb
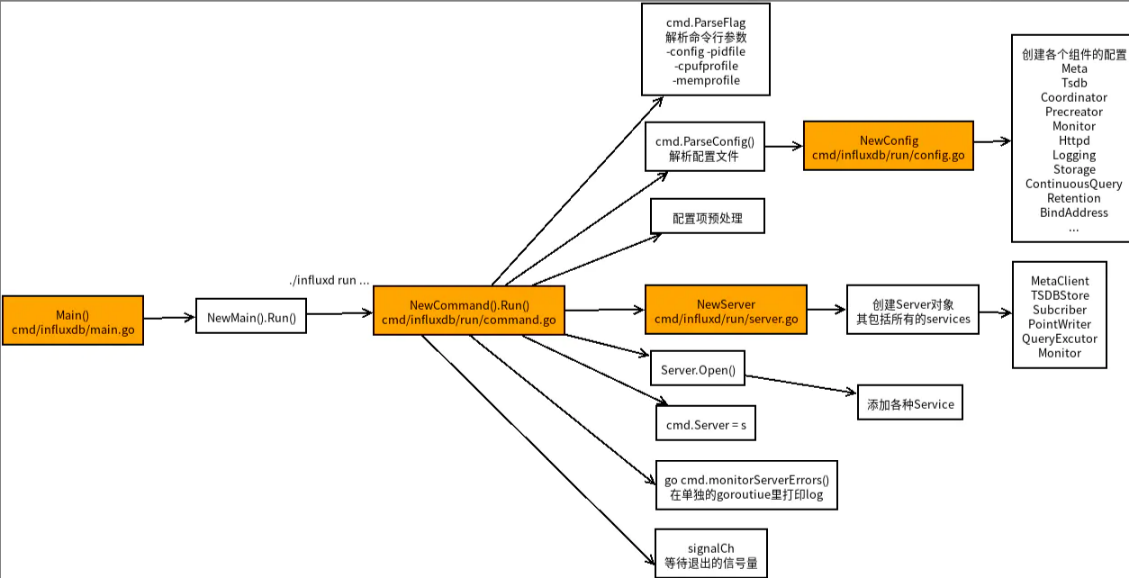
influxdata主目录结构
[root@localhost influxdata]# pwd
/root/dev/golib/src/github.com/influxdata
[root@localhost influxdata]# tree -d -L 1
.
├── influxdb
├── influxql
├── usage-client
├── yamux
└── yarpc
目录解析说明:
- influxdb
为源码的主目录
- influxql
实现了InfluxDB查询语言的解析器(源码主目录里面引用的是influxdata/influxdb/influxql,没有该目录的相关引用)
- usage-client
client lib V1版本
- yamux
Yet another Multiplexer(又一个多路复用器)是Golang的多路复用库
- yarpc
Yet Another RPC (又一个RPC)是Golang的RPC库
源码主目录结构
一级目录结构如下:
[root@localhost influxdb]# pwd
/root/dev/golib/src/github.com/influxdata/influxdb
[root@localhost influxdb]# tree -d -L 1
.
├── client
├── cmd
├── coordinator
├── etc
├── importer
├── influxql
├── internal
├── man
├── models
├── monitor
├── pkg
├── scripts
├── services
├── stress
├── tcp
├── tests
├── toml
├── tsdb
└── uuid
二级目录结构如下:
[root@localhost influxdb]# tree -d -L 2
.
├── client
│ └── v2
├── cmd
│ ├── influx
│ ├── influxd
│ ├── influx_inspect
│ ├── influx_stress
│ └── influx_tsm
├── coordinator
├── etc
│ └── burn-in
├── importer
│ └── v8
├── influxql
│ ├── internal
│ └── neldermead
├── internal
├── man
├── models
├── monitor
│ └── diagnostics
├── pkg
│ ├── deep
│ ├── escape
│ ├── limiter
│ ├── pool
│ └── slices
├── scripts
├── services
│ ├── admin
│ ├── collectd
│ ├── continuous_querier
│ ├── graphite
│ ├── httpd
│ ├── meta
│ ├── opentsdb
│ ├── precreator
│ ├── retention
│ ├── snapshotter
│ ├── subscriber
│ └── udp
├── stress
│ ├── stress_test_server
│ └── v2
├── tcp
├── tests
│ ├── siege
│ ├── tmux
│ └── urlgen
├── toml
├── tsdb
│ ├── engine
│ └── internal
└── uuid
目录解析说明:
- client
client lib V2版本
cmd目录
InfluxDB相关程序所在目录
其中:
influxd目录为InfluxDB主程序代码;
influx为InfluxDB自带的控制台管理工具源码;
influx_inspect为InfluxDB数据查看工具源码;
influx_stress为InfluxDB压力测试工具源码;
influx_tsm为数据库转换工具(将数据库从b1或bz1格式转换为tsm1格式)源码
其他目录
- coordinator
协调器,负责数据的写入和一些创建语句的执行。
在InfluxDB的ChangeLog中显示在v1.0.0中使用coordinator替换cluster,感觉自建集群功能可以通过此模块实现。
- etc
存放默认配置
- importer
版本向后兼容相关代码,在ReadMe中已经提到:Version 0.8.9 of InfluxDB adds support to export your data to a format that can be imported into 0.9.3 and later.
- influxql
实现了InfluxDB查询语言的解析器
- internal
主要实现了MetaClient接口
- man
帮助手册
- models
基础数据类型定义
- monitor
InfluxDB系统监控
- pkg
一些通用包的集合。
deep里面主要实现了deepValueEqual方法,用于深层次比较两个值是否相等;
escape里面主要实现了byte和string两种数据类型转义字符的相关操作;
limiter里面主要是一个基于channel实现的简单并发限制器Fixed;
pool里面主要实现了Bytes和Generic两种类型的Pool,在Pool中的对象不使用时不会被垃圾回收自动清理掉;
slices 里面主要实现了一些string数组的操作;
- scripts
该目录存放的是一些关于InfluxDB的脚本。
- services
该目录存放的是一些关于InfluxDB的服务。
admin 为InfluxDB内置的管理服务;
collectd 为collectd(https://collectd.org)对接服务,可以接收通过UDP发送过来的collectd格式数据;
continuous_querier 为InfluxDB的CQ服务;
graphite 为InfluxDB的graphite服务;
httpd 为InfluxDB的http服务,可以通过该接口进行数据库数据的写入和查询等操作;
meta 为InfluxDB的元数据服务,用于管理数据库的元数据相关内容;
opentsdb 为InfluxDB的opentsdb服务,可用于替换opentsdb;
precreator 为InfluxDB的Shard预创建服务;
retention 为InfluxDB的数据保留策略的强制执行服务,主要用于定时删除文件;
snapshotter 为InfluxDB的快照服务;
subscriber 为InfluxDB的订阅服务;
udp 为InfluxDB的udp服务,可以通过该接口进行数据库的写入和查询等操作;
- stress
该目录存放的是压力测试相关内容。
- tcp
网络连接的多路复用。
- tests
测试相关内容
- toml
toml的解析器,和另一个toml解析器(github.com/BurntSushi/toml)不同,为独立的解析模块,主要是解析时间字符串和磁盘容量数据。
- tsdb
tsdb目录主要是时序数据库的实现。
- uuid
该目录里面主要存放uuid生成的相关代码。
数据操作
CLI–influx命令行操作
执行influx
在src源文件中编译执行influx:
step1:先执行cmd\influxd\main.go文件,启动本地influxDB实例;
step2:执行cmd\influx\main.go文件,将influx连接到本地的influxDB实例上;
在cmd中运行influx.exe可执行文件,从而执行influx:
//用cmd方式执行influx可执行文件:influx2/bin/influx.exe(前提先运行influxd.exe)
$ influx -precision rfc3339
Connected to http://localhost:8086 version 1.2.x
InfluxDB shell 1.2.x
###说明
# InfluxDB的HTTP接口默认起在8086上,所以influx默认也是连的本地的8086端口,你可以通过influx --help来看怎么修改默认值。
# -precision参数表明了任何返回的时间戳的格式和精度,在上面的例子里,rfc3339是让InfluxDB返回RFC339格式(YYYY-MM-DDTHH:MM:SS.nnnnnnnnnZ)的时间戳。
这样这个命令行已经准备好接收influx的查询语句了(简称InfluxQL),用exit可以退出命令行。
第一次安装好InfluxDB之后是没有数据库的(除了系统自带的_internal),因此创建一个数据库是我们首先要做的事,通过CREATE DATABASE <db-name>这样的InfluxQL语句来创建,其中<db-name>就是数据库的名字。数据库的名字可以是被双引号引起来的任意Unicode字符。 如果名称只包含ASCII字母,数字或下划线,并且不以数字开头,那么也可以不用引起来;
创建数据库
创建一个mydb数据库:
> CREATE DATABASE mydb
说明:在输入上面的语句之后,并没有看到任何信息,这在CLI里,表示语句被执行并且没有错误,如果有错误信息展示,那一定是哪里出问题了,这就是所谓的没有消息就是好消息;
查看数据库
现在数据库mydb已经创建好了,我们可以用SHOW DATABASES语句来看看已存在的数据库:
> SHOW DATABASES
name: databases
name
----
_internal
mydb
说明:_internal数据库是用来存储InfluxDB内部的实时监控数据的。
使用数据库
大部分InfluxQL需要作用在一个特定的数据库上。你当然可以在每一个查询语句上带上你想查的数据库的名字,但是CLI提供了一个更为方便的方式USE,这会为你后面的所以的请求设置到这个数据库上;
> USE mydb
Using database mydb
以下的操作都作用于mydb这个数据库之上;
数据行协议
首先对数据存储的格式来个入门介绍;InfluxDB里存储的数据被称为时间序列数据,其包含一个数值,就像CPU的load值或是温度值;时序数据有零个或多个数据点,每一个都是一个指标值;数据点包括time(一个时间戳),measurement(例如cpu_load),至少一个k-v格式的field(也即指标的数值例如 “value=0.64”或者“temperature=21.2”),零个或多个tag,其一般是对于这个指标值的元数据(例如“host=server01”, “region=EMEA”, “dc=Frankfurt);
在概念上,你可以将measurement类比于SQL里面的table,其主键索引总是时间戳;tag和field是在table里的其他列,tag是被索引起来的,field没有;不同之处在于,在InfluxDB里,你可以有几百万的measurements,你不用事先定义数据的scheme,并且null值不会被存储;
将数据点写入InfluxDB,只需要遵守如下的行协议:
<measurement>[,<tag-key>=<tag-value>...] <field-key>=<field-value>[,<field2-key>=<field2-value>...] [unix-nano-timestamp]

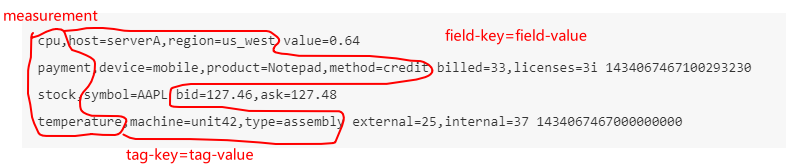
插入数据行
使用CLI插入单条的时间序列数据到InfluxDB中,用INSERT后跟数据点:
INSERT cpu,host=serverA,region=us_west value=0.64
说明:我们在写入的时候没有包含时间戳,当没有带时间戳的时候,InfluxDB会自动添加本地的当前时间作为它的时间戳。
这样一个measurement为cpu,tag是host和region,value值为0.64的数据点被写入了InfluxDB中;
查看数据
跟SQL语法类型
> SELECT "host", "region", "value" FROM "cpu"
name: cpu
time host region value
---- ---- ------ -----
1604823941584418500 serverA us_west 0.64
> select * from cpu
name: cpu
time host region value
---- ---- ------ -----
1604823941584418500 serverA us_west 0.64
常用命令
CREATE DATABASE "testDB" --创建数据库
show databases --展示所有数据库
use testDB --使用testDB数据库
SHOW MEASUREMENTS --查询当前数据库中含有的表
SHOW FIELD KEYS --查看当前数据库所有表的字段
SHOW series from pay --查看key数据
SHOW TAG KEYS FROM "pay" --查看key中tag key值
SHOW TAG VALUES FROM "pay" WITH KEY = "merId" --查看key中tag 指定key值对应的值
SHOW TAG VALUES FROM cpu WITH KEY IN ("region", "host") WHERE service = 'redis'
DROP SERIES FROM <measurement_name[,measurement_name]> WHERE <tag_key>='<tag_value>' --删除key
SHOW CONTINUOUS QUERIES --查看连续执行命令
SHOW QUERIES --查看最后执行命令
KILL QUERY <qid> --结束命令
SHOW RETENTION POLICIES ON mydb --查看保留数据
查询数据
SELECT * FROM /.*/ LIMIT 1 --查询当前数据库下所有表的第一行记录
select * from pay order by time desc limit 2
select * from db_name."POLICIES name".measurement_name --指定查询数据库下数据保留中的表数据 POLICIES name数据保留
删除数据
delete from "query" --删除表所有数据,则表就不存在了
drop MEASUREMENT "query" --删除表(注意会把数据保留删除使用delete不会)
DELETE FROM cpu
DELETE FROM cpu WHERE time < '2000-01-01T00:00:00Z'
DELETE WHERE time < '2000-01-01T00:00:00Z'
DROP DATABASE “testDB” --删除数据库
DROP RETENTION POLICY "dbbak" ON mydb --删除保留数据为dbbak数据
DROP SERIES from pay where tag_key='' --删除key中的tag
SHOW SHARDS --查看数据存储文件
DROP SHARD 1
SHOW SHARD GROUPS
SHOW SUBSCRIPTIONS
参考文字:
使用HTTP接口操作数据库
cmd命令行中可以通过HTTP接口连接数据库,从而进行读写操作;
创建数据库
使用POST方式发送到URL的/query路径,参数q为CREATE DATABASE,下面的例子发送一个请求到本地运行的InfluxDB创建数据库mydb:
curl -i -XPOST http://localhost:8086/query --data-urlencode "q=CREATE DATABASE mydb"
写入数据
通过HTTP接口POST数据到/write路径是我们往InfluxDB写数据的主要方式。下面的例子写了一条数据到mydb数据库。这条数据的组成部分是measurement为cpu_load_short,tag 的 key为 host 和 region,对应 tag 的 value 是server01和us-west,field的key是value,对应的数值为0.64,而时间戳是1434055562000000000;
第一次尝试
>>C:\Users\Luweir>curl -i -XPOST 'http://localhost:8086/write?db=mydb' --data-binary 'cpu_load_short,host=server01,region=us-west value=0.64 1434055562000000000'
弹出以下提示:
curl: (1) Protocol "'http" not supported or disabled in libcurl
curl: (6) Could not resolve host: value=0.64
curl: (6) Could not resolve host: 1434055562000000000'
查阅后发现这个命令中 ' ' 的部分都要使用 " "
更正后:
>>C:\Users\Luweir>curl -i -XPOST "http://localhost:8086/write?db=mydb" --data-binary "cpu_load_short,host=server01,region=us-west value=0.64 1434055562000000000"
HTTP/1.1 204 No Content
Content-Type: application/json
Request-Id: 410f780d-219d-11eb-800a-9c7bef3eea50
X-Influxdb-Build: OSS
X-Influxdb-Version: unknown
X-Request-Id: 410f780d-219d-11eb-800a-9c7bef3eea50
Date: Sun, 08 Nov 2020 08:34:45 GMT
HTTP返回值:
2xx:如果你写了数据后收到HTTP 204 No Content ,说明写入成功了;
4xx:表示InfluxDB不知道你发的是什么鬼;
5xx:系统过载或是应用受损;
当写入这条数据点的时候,你必须明确存在一个数据库对应名字是db参数的值。如果你没有通过rp参数设置retention policy的话,那么这个数据会写到db默认的retention policy中;
POST的请求体我们称之为Line Protocol,包含了你希望存储的时间序列数据。它的组成部分有measurement,tags,fields和timestamp。measurement是InfluxDB必须的,严格地说,tags是可选的,但是对于大部分数据都会包含tags用来区分数据的来源,让查询变得容易和高效。tag的key和value都必须是字符串。fields的key也是必须的,而且是字符串**,**默认情况下field的value是float类型的。timestamp在这个请求行的最后,是一个从1/1/1970 UTC开始到现在的一个纳秒级的Unix time,它是可选的,如果不传,InfluxDB会使用服务器的本地的纳米级的timestamp来作为数据的时间戳,注意无论哪种方式,在InfluxDB中的timestamp只能是UTC时间。
写入文件中的数据:
把下列数据行写入一个txt文件:以cpu_data.txt为例
cpu_load_short,host=server02 value=0.67
cpu_load_short,host=server02,region=us-west value=0.55 1422568543702900257
cpu_load_short,direction=in,host=server01,region=us-west value=2.0 1422568543702900257
把cpu_data.txt的数据写入mybd数据库:
curl -i -XPOST 'http://localhost:8086/write?db=mydb' --data-binary @cpu_data.txt
说明:如果你的数据文件的数据点大于5000时,你必须把他们拆分到多个文件再写入InfluxDB。因为默认的HTTP的timeout的值为5秒,虽然5秒之后,InfluxDB仍然会试图把这批数据写进去,但是会有数据丢失的风险;
无模式设计
InfluxDB是一个无模式(schemaless)的数据库,你可以在任意时间添加measurement,tags和fields。注意:如果你试图写入一个和之前的类型不一样的数据(例如,filed字段之前接收的是数字类型,现在写了个字符串进去),那么InfluxDB会拒绝这个数据;
使用HTTP接口查询数据
采样和数据保留
相关概念
以下列数据为例:
数据展示了在2015年8月18日午夜至2015年8月18日上午6时12分在两个地点location(地点1和地点2)显示两名科学家scientists(langstroth和perpetua)计数的蝴蝶(butterflies)和蜜蜂(honeybees)数量;

其中census是measurement,butterflies和honeybees是field key,location和scientist是tag key;
时间戳
InfluxDB是一个时间序列数据库,因此我们开始一切的根源就是——时间。在上面的数据中有一列是time,在InfluxDB中所有的数据都有这一列。time存着时间戳,这个时间戳以RFC3339格式展示了与特定数据相关联的UTC日期和时间;
field
接下来两个列叫作butterflies和honeybees,称为fields。fields由field key和field value组成。field key(butterflies和honeybees)都是字符串,他们存储元数据;field key butterflies告诉我们蝴蝶的计数从12到7;field key honeybees告诉我们蜜蜂的计数从23变到22;
field value就是你的数据,它们可以是字符串、浮点数、整数、布尔值,因为InfluxDB是时间序列数据库,所以field value总是和时间戳相关联;
示例中,field value如下:
12 23
1 30
11 28
3 28
2 11
1 10
8 23
7 22
field是InfluxDB数据结构所必需的一部分——在InfluxDB中不能没有field;还要注意,field是没有索引的;如果使用field value作为过滤条件来查询,则必须扫描其他条件匹配后的所有值;因此,这些查询相对于tag上的查询(下文会介绍tag的查询)性能会低很多。 一般来说,字段不应包含常用来查询的元数据;
tag
样本数据中的最后两列(location和scientist)就是tag; tag由tag key和tag value组成。tag key和tag value都作为字符串存储,并记录在元数据中。示例数据中的 tag key是location和scientist。 location有两个tag value:1和2。scientist还有两个tag value:langstroth和perpetua。
在上面的数据中,tag set 是不同的每组 tag key 和 tag value的集合,示例数据里有四个tag set:
location = 1, scientist = langstroth
location = 2, scientist = langstroth
location = 1, scientist = perpetua
location = 2, scientist = perpetua
tag不是必需的字段,但是在你的数据中使用tag总是大有裨益,因为不同于field, tag是索引起来的。这意味着对tag的查询更快,tag是存储常用元数据的最佳选择;
measurement
measurement作为tag,fields和time列的容器,measurement的名字是存储在相关fields数据的描述。 measurement的名字是字符串,对于一些SQL用户,measurement在概念上类似于表。样本数据中唯一的测量是census。 名称census告诉我们,fields值记录了butterflies和honeybees的数量,而不是不是它们的大小,方向或某种幸福指数;
单个measurement可以有不同的retention policy。 retention policy描述了InfluxDB保存数据的时间(DURATION)以及这些存储在集群中数据的副本数量(REPLICATION);
在样本数据中,measurement census中的所有内容都属于autogen的retention policy。 InfluxDB自动创建该存储策略; 它具有无限的持续时间和复制因子设置为1。
series
series是共同retention policy,measurement 和 tag set 的集合;以上数据由四个series组成:

point
最后,point就是具有相同timestamp的相同series的field集合。例如,这就是一个point:
例子里的series的retention policy为autogen,measurement为census,tag set为location = 1, scientist = perpetua。point的timestamp为2015-08-18T00:00:00Z。
刚刚涵盖的所有内容都存储在数据库(database)中——示例数据位于数据库my_database中。 InfluxDB数据库与传统的关系数据库类似,并作为users,retention policy,continuous以及point的逻辑上的容器。;
数据库可以有多个users,retention policy,continuous和measurement。 InfluxDB是一个无模式数据库,意味着可以随时添加新的measurement,tag和field。 它旨在使时间序列数据的工作变得非常棒;
专业术语
更多见:https://jasper-zhang1.gitbooks.io/influxdb/content/Concepts/glossary.html
duration
retention policy中的一个属性,决定InfluxDB中数据保留多长时间;在duration之前的数据会自动从database中删除掉;
point
InfluxDB数据结构的一部分由series中的的一堆field组成。 每个点由其series和timestamp唯一标识。
你不能在同一series中存储多个具有相同timestamp的点。 相反,当你使用与该series中现有点相同的timestamp记将新point写入同一series时,该field set将成为旧field set和新field set的并集;
shard
shard包含实际的编码和压缩数据,并由磁盘上的TSM文件表示。 每个shard都属于唯一的一个shard group。多个shard可能存在于单个shard group中。每个shard包含一组特定的series。给定shard group中的给定series上的所有点将存储在磁盘上的相同shard(TSM文件)中;
SQL VS InfluxDB
形式上
下表是一个叫foodships的SQL数据库的例子,并有没有索引的#_foodships列和有索引的park_id,planet和time列;
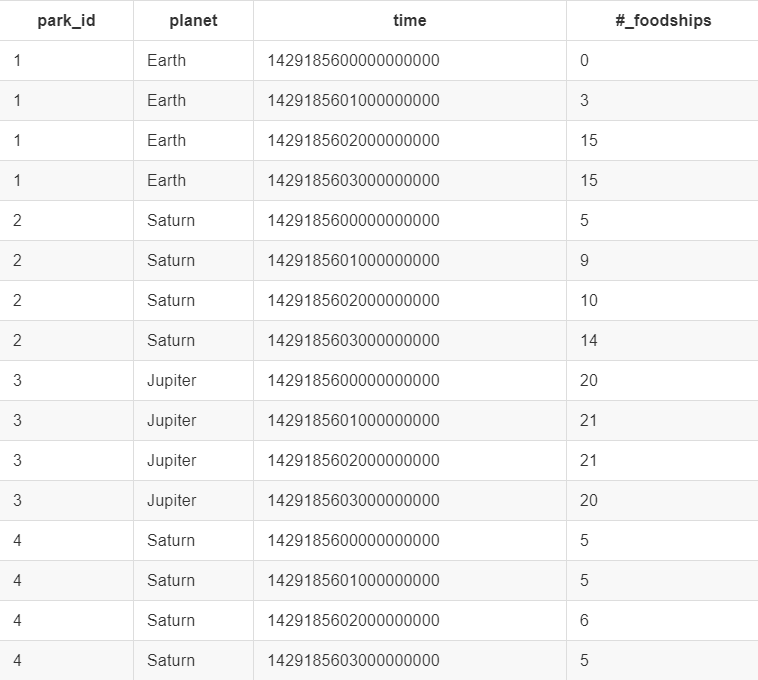
这些数据在influxdb中看起来像这样:
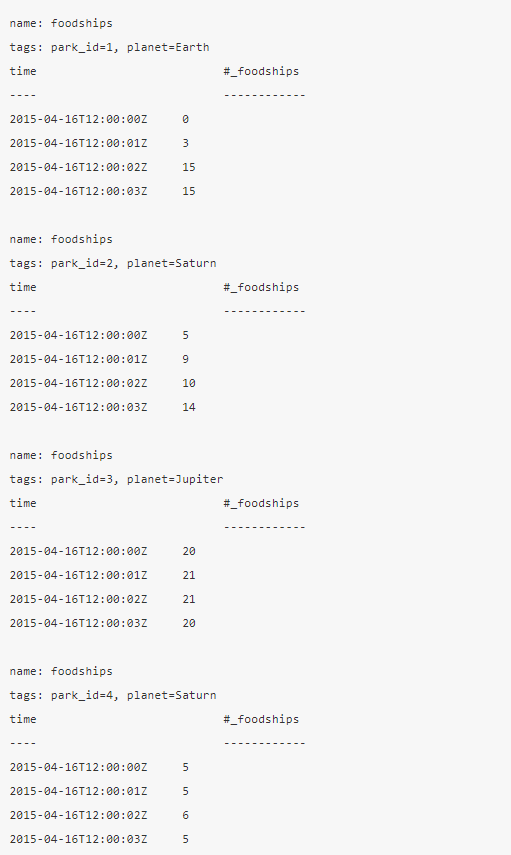
参考上面的数据,一般可以这么说:
- InfluxDB的measurement(
foodships)和SQL数据库里的table类似; - InfluxDB的tag(
park_id和planet)类似于SQL数据库里索引的列; - InfluxDB中的field(
#_foodships)类似于SQL数据库里没有索引的列; - InfluxDB里面的数据点(例如
2015-04-16T12:00:00Z 5)类似于SQL数据库的行;
基于这些数据库术语的比较,InfluxDB的continuous query和retention policy与SQL数据库中的存储过程类似。 它们被指定一次,然后定期自动执行。
当然,SQL数据库和InfluxDB之间存在一些重大差异。SQL中的JOIN不适用于InfluxDB中的measurement。而且,正如我们上面提到的那样,一个measurement就像一个SQL的table,其中主索引总是被预设为时间;InfluxDB的时间戳记必须在UNIX epoch(GMT)或格式化为日期时间RFC3339格式的字符串才有效。
数据操作上
InfluxQL的select语句来自于SQL中的select形式:
SELECT <stuff> FROM <measurement_name> WHERE <some_conditions>
where是可选的,在InfluxDB里为了查询到上面数据,需要输入:
SELECT * FROM "foodships"
如果你仅仅想看planet为Saturn的数据:
SELECT * FROM "foodships" WHERE "planet" = 'Saturn'
如果你想看到planet为Saturn,并且在UTC时间为2015年4月16号12:00:01之后的数据:
SELECT * FROM "foodships" WHERE "planet" = 'Saturn' AND time > '2015-04-16 12:00:01'
如上例所示,InfluxQL允许您在WHERE子句中指定查询的时间范围。您可以使用包含单引号的日期时间字符串,格式为YYYY-MM-DD HH:MM:SS.mmm(mmm为毫秒,为可选项,您还可以指定微秒或纳秒。您还可以使用相对时间与now()来指代服务器的当前时间戳:
SELECT * FROM "foodships" WHERE time > now() - 1h
该查询输出measurement为foodships中的数据,其中时间戳比服务器当前时间减1小时(即最近一小时的数据);与now()做计算来决定时间范围的可选单位有:
| 字母 | 意思 |
|---|---|
| u或µ | 微秒 |
| ms | 毫秒 |
| s | 秒 |
| m | 分钟 |
| h | 小时 |
| d | 天 |
| w | 星期 |
InfluxQL还支持正则表达式,表达式中的运算符,SHOW语句和GROUP BY语句;
InfluxDB是针对时间序列数据进行了优化的数据库;这些数据通常来自分布式传感器组,来自大型网站的点击数据或金融交易列表等。
这个数据有一个共同之处在于它只看一个点没什么用。一个读者说,在星期二UTC时间为12:38:35时根据他的电脑CPU利用率为12%,这个很难得出什么结论。只有跟其他的series结合并可视化时,它变得更加有用。随着时间的推移开始显现的趋势,是我们从这些数据里真正想要看到的。另外,时间序列数据通常是一次写入,很少更新。
结果是,由于优先考虑create和read数据的性能而不是update和delete,InfluxDB不是一个完整的CRUD数据库,更像是一个CR-ud。
写入协议–行协议
InfluxDB的行协议是一种写入数据点到InfluxDB的文本格式。必须要是这样的格式的数据点才能被Influxdb解析和写入成功;
语法
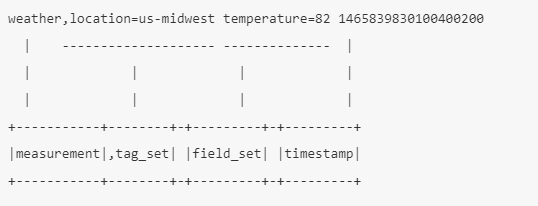
measurement
你想要写入数据的measurement,这在行协议中是必需的,例如这里的measurement是weather。
Tag set
你想要数据点中包含的tag,tag在行协议里是可选的。注意measurement和tag set是用不带空格的逗号分开的;
用不带空格的=来分割一组tag的键值:
<tag_key>=<tag_value>
多组tag直接用不带空格的逗号分开:
<tag_key>=<tag_value>,<tag_key>=<tag_value>
例如上面的tag set由一个tag组成location=us-midwest,现在加另一个tag(season=summer),就变成了这样:
weather,location=us-midwest,season=summer temperature=82 1465839830100400200
为了获得最佳性能,您应该在将它们发送到数据库之前按键进行排序;排序应该与Go bytes.Compare function的结果相匹配;
空格1
分离 measurement 和 field set,或者如果您使用数据点包含tag set,则使用空格分隔tag set和field set;行协议中空格是必需的;
没有 tag set 的有效行协议:
weather temperature=82 1465839830100400200
Field set
每个数据点在行协议中至少需要一个field。使用无空格的=分隔field的键值对:
<field_key>=<field_value>
多组field直接用不带空格的逗号分开:
<field_key>=<field_value>,<field_key>=<field_value>
例如上面的field set由一个field组成temperature=82,现在加另一个field(bug_concentration=98),就变成了这样:
weather,location=us-midwest temperature=82,bug_concentration=98 1465839830100400200
空格2
使用空格分隔field set和可选的时间戳。如果你包含时间戳,则行协议中需要空格。
Timestamp
数据点的时间戳记以纳秒精度Unix时间。行协议中的时间戳是可选的。 如果没有为数据点指定时间戳,InfluxDB会使用服务器的本地纳秒时间戳。
在这个例子中,时间戳记是1465839830100400200(这就是RFC6393格式的2016-06-13T17:43:50.1004002Z)。下面的行协议是相同的数据点,但没有时间戳;当InfluxDB将其写入数据库时,它将使用您的服务器的本地时间戳而不是2016-06-13T17:43:50.1004002Z。
weather,location=us-midwest temperature=82
使用HTTP API来指定精度超过纳秒的时间戳,例如微秒,毫秒或秒。我们建议使用最粗糙的精度,因为这样可以显着提高压缩率;
数据类型
Field value可以是整数、浮点数、字符串和布尔值:
-
浮点数 —— 默认是浮点数,InfluxDB假定收到的所有field value都是浮点数。
以浮点类型存储上面的82:weather,location=us-midwest temperature=82 1465839830100400200 -
整数 —— 添加一个
i在field之后,告诉InfluxDB以整数类型存储:
以整数类型存储上面的82:weather,location=us-midwest temperature=82i 1465839830100400200 -
字符串 —— 双引号把字段值引起来表示字符串:
以字符串类型存储值too warm:weather,location=us-midwest temperature="too warm" 1465839830100400200 -
布尔型 —— 表示TRUE可以用
t,T,true,True,TRUE;表示FALSE可以用f,F,false,False或者FALSE:
以布尔类型存储值true:
weather,location=us-midwest too_hot=true 1465839830100400200
在measurement中,field value的类型在分片内不会有差异,但在分片之间可能会有所不同。例如,如果InfluxDB尝试将整数写入到与浮点数相同的分片中,则写入会失败:
> INSERT weather,location=us-midwest temperature=82 1465839830100400200
> INSERT weather,location=us-midwest temperature=81i 1465839830100400300
ERR: {"error":"field type conflict: input field \"temperature\" on measurement \"weather\" is type int64, already exists as type float"}
但是,如果InfluxDB将整数写入到一个新的shard中,虽然之前写的是浮点数,那依然可以写成功:
> INSERT weather,location=us-midwest temperature=82 1465839830100400200
> INSERT weather,location=us-midwest temperature=81i 1467154750000000000
>
引号
- 时间戳不要双或单引号。下面这是无效的行协议;
-
field value不要单引号,即时是字符串类型。下面这是无效的行协议。 例:
> INSERT weather,location=us-midwest temperature='too warm' ERR: {"error":"unable to parse 'weather,location=us-midwest temperature='too warm'': invalid boolean"} -
measurement名称,tag keys,tag value和field key不用单双引号。InfluxDB会假定引号是名称的一部分;
InfluxDB的设计见解和权衡
InfluxDB是一个时间序列数据库。针对这种用例进行优化需要进行一些权衡,主要是以牺牲功能为代价来提高性能;以下列出了一些权衡过的设计见解:
1、对于时间序列用例,我们假设如果相同的数据被多次发送,那么认为客户端几次都是同一笔数据。
- 优势:通过简化的冲突解决增加了写入性能
- 劣势:不能存储重复数据;可能会在极少数情况下覆盖数据
2、删除是罕见的事情,当它们发生时,肯定是针对大量的旧数据,这些数据对于写入来说是冷数据。
- 优势:限制删除操作,从而增加查询和写入性能
- 劣势:删除功能受到很大限制
3、对现有数据的更新是罕见的事件,持续地更新永远不会发生。时间序列数据主要是永远不更新的新数据。
- 优势:限制更新操作,从而增加查询和写入性能
- 劣势:更新功能受到很大限制
4、绝大多数写入都是接近当前时间戳的数据,并且数据是按时间递增的顺序添加。
- 优势:按时间递增的顺序添加数据明显更高效些
- 劣势:随机时间或时间不按升序写入点的性能要低得多
5、 规模至关重要。数据库必须能够处理大量的读取和写入。
- 优势:数据库可以处理大量的读取和写入
- 劣势:InfluxDB开发团队被迫做出权衡来提高性能
6、能够写入和查询数据比具有强一致性更重要。
- 优势:多个客户端可以在高负载的情况下完成查询和写入数据库操作
- 劣势:如果数据库负载较重,查询返回结果可能不包括最近的点
7、许多时间序列都是短暂的。经常是时间序列,只出现了几个小时,然后消失,例如一个新的主机,开机并监控数据被写入一段时间,然后被关闭。
- 优势:InfluxDB善于管理不连续数据
- 劣势:无模式设计意味着不支持某些数据库功能,例如没有交叉表连接
8、没有数据点太重要了。
- 优势:InfluxDB具有非常强大的工具来处理聚合数据和大数据集
- 劣势:数据点没有传统意义上的ID,它们被时间戳和series区分开来
存储引擎
influxdb的存储引擎具有wal和一组只读数据文件,它们在概念上与LSM树中的SSTables类似;TSM文件包含排序,压缩的series数据。
存储引擎将多个组件结合在一起,并提供用于存储和查询series数据的外部接口。 它由许多组件组成,每个组件都起着特定的作用:
- In-Memory Index —— 内存中的索引是分片上的共享索引,可以快速访问measurement,tag和series。 引擎使用该索引,但不是特指存储引擎本身。
- WAL —— WAL是一种写优化的存储格式,允许写入持久化,但不容易查询。 对WAL的写入就是append到固定大小的段中。
- Cache —— Cache是存储在WAL中的数据的内存中的表示。 它在运行时可以被查询,并与TSM文件中存储的数据进行合并。
- TSM Files —— TSM Files中保存着柱状格式的压缩过的series数据。
- FileStore —— FileStore可以访问磁盘上的所有TSM文件。 它可以确保在现有的TSM文件被替换时以及删除不再使用的TSM文件时,创建TSM文件是原子性的。
- Compactor —— Compactor负责将不够优化的Cache和TSM数据转换为读取更为优化的格式。 它通过压缩series,去除已经删除的数据,优化索引并将较小的文件组合成较大的文件来实现。
- Compaction Planner —— Compaction Planner决定哪个TSM文件已准备好进行压缩,并确保多个并发压缩不会彼此干扰。
- Compression —— Compression由各种编码器和解码器对特定数据类型作处理。一些编码器是静态的,总是以相同的方式编码相同的类型; 还有一些可以根据数据的类型切换其压缩策略。
- Writers/Readers —— 每个文件类型(WAL段,TSM文件,tombstones等)都有相应格式的Writers和Readers。
InfluxDB的0.9版本使用BoltDB作为底层存储引擎。下面要介绍的TSM,它在0.9.5中发布,是InfluxDB 0.11+中唯一支持的存储引擎,包括整个1.x系列。
BoltDB,这是一个基于内存映射B+ Tree的引擎,它是针对读取进行了优化的。最后,我们最终建立了我们自己的存储引擎,它在许多方面与LSM树类似。借助我们的新存储引擎,我们可以达到比B+ Tree实现高达45倍的磁盘空间使用量的减少,甚至比使用LevelDB及其变体有更高的写入吞吐量和压缩率。
influxdb + 混合压缩算法
找源代码与 gzip 压缩有关的部分
restore
数据的恢复restore要使用gzip压缩算法压缩,在路径influxd/restore/restore.go中;
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-RjN0lCD9-1606126788698)(https://raw.githubusercontent.com/Luweir/picpicgo/main/img/20201123144327.png)]
back up
数据的备份back up要使用gzip压缩算法压缩,在路径influxd/backup/restore.go中;
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-IJqbunkv-1606126788699)(https://raw.githubusercontent.com/Luweir/picpicgo/main/img/20201123144331.png)]
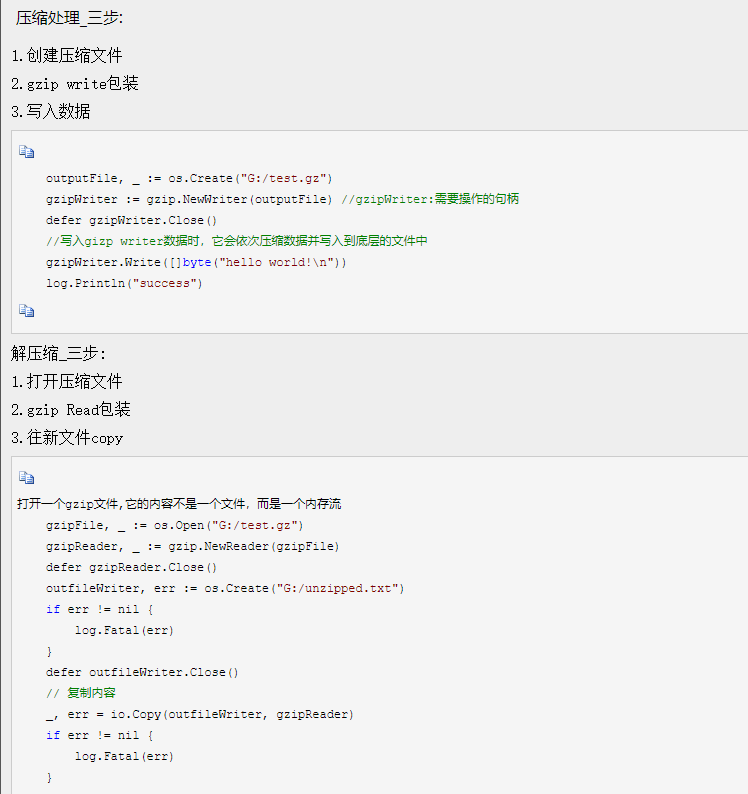
Go语言的compress/gzip
压缩
func NewWriter
func NewWriter(w io.Writer) *Writer
NewWriter创建并返回一个Writer;写入返回值的数据都会在压缩后写入w;调用者有责任在结束写入后调用返回值的Close方法。因为写入的数据可能保存在缓冲中没有刷新入下层;
func (*Writer) Write
func (z *Writer) Write(p []byte) (int, error)
Write将p压缩后写入下层 io.Writer 接口(NewWriter返回的Writer);压缩后的数据不一定会立刻刷新(压缩后的数据放在缓存中),除非Writer被关闭或者显式的刷新,才会将缓存中的数据刷新到下层 io.Writer 接口中;
接下来,关闭或者刷新缓存
func (*Writer) Flush
func (z *Writer) Flush() error
Flush将缓冲中的压缩数据刷新到下层io.Writer接口中;本方法主要用在传输压缩数据的网络连接中,以保证远端的接收者可以获得足够的数据来重构数据报。Flush会阻塞直到所有缓冲中的数据都写入下层io.Writer接口后才返回;
所以关闭即可
func (*Writer) Close
func (z *Writer) Close() error
调用Close会关闭z,但不会关闭下层io.Writer接口;
func Copy
func Copy(dst Writer, src Reader) (written int64, err error)
将src的数据拷贝到dst,直到在src上到达EOF或发生错误。返回拷贝的字节数和遇到的第一个错误。
对成功的调用,返回值err为nil而非EOF,因为Copy定义为从src读取直到EOF,它不会将读取到EOF视为应报告的错误。如果src实现了WriterTo接口,本函数会调用src.WriteTo(dst)进行拷贝;否则如果dst实现了ReaderFrom接口,本函数会调用dst.ReadFrom(src)进行拷贝。
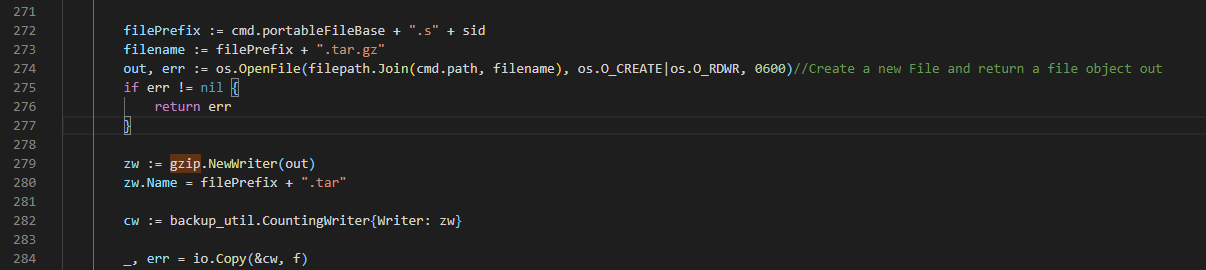
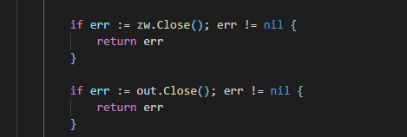
源代码cmd/influxd/backup/backup.go
解压
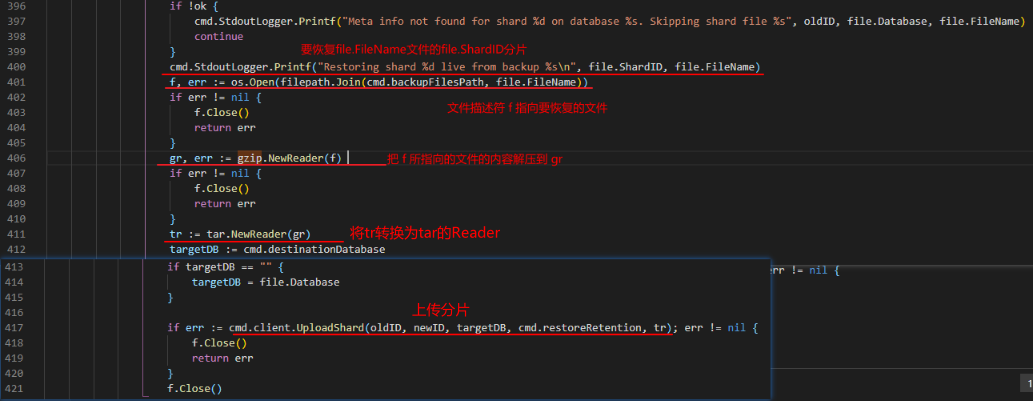
func NewReader
func NewReader(r io.Reader) (*Reader, error)
NewReader返回一个从 r 读取并解压数据的*Reader;其实现会缓冲输入流的数据,并可能从r中读取比需要的更多的数据;调用者有责任在读取完毕后调用返回值的Close方法;
源代码cmd/influxd/restore/restore.go:

简化整个压缩和解压流程

 浙公网安备 33010602011771号
浙公网安备 33010602011771号