读书笔记 - -《Python网络编程》重点
一、前言
~~~~~~ 这是在我研一阶段,高等计算机网络在结课前一周布置了一些实验作业,所以我选择了这本《Python网络编程》来更好的接触网络;很多不太重要的部分我都省略了,每一章后面的小结是非常重要的,简明地概括了重点和非重点!
二、客户/服务器网络编程简介
协议栈(protocol stack):复杂的网络服务建立在简单网络服务的基础之上;
下面从一个例子:谷歌地理编码协议(Google Geocoding protocol)入手;
-
安装
pygeocoder包;
-
获取经纬度:
# search1.py from pygeocoder import Geocoder if __name__ == '__main__': # api访问的key,可能会失效 a = Geocoder(api_key='AIzaSyDYOkkJiTPVd2U7aTOAwhc9ySH6oHxOIYM') a.proxy = "127.0.0.1:1080" address = '207 N. Definace St,Archbold,OH' print(a.geocode(address)[0].coordinates) ## 返回经纬度 (41.5219761, -84.3066486)
如果没有这个库,我们如何获得经纬度,或者说如何为谷歌地图API编写客户端?
import requests
def geocode(address):
proxy = {'https': '127.0.0.1:8787'}
# key可能会因为失效而导致程序运行失败
parameters = {'address': address, 'key': 'AIzaSyAQBosdfjL6Dz-l9csflsdhPDDLsR0w40I'}
base = 'https://maps.googleapis.com/maps/api/geocode/json'
response = requests.get(base, params=parameters, proxies=proxy)
answer = response.json()
print(answer['results'][0]['geometry']['location'])
if __name__ == '__main__':
geocode('207 N. Defiance St, Archbold, OH')
~~~~~~ search2.py与search1.py完成的功能相同, 但前者并没有通过地址和纬度这样的语义直接解决该问题,而是通过构造url,获取查询响应,然后将结果转化为JSON,一步步解决问题;
~~~~~~ 这样的区别同网络协议栈高层和底层协议,高层代码描述了查询的意义,而底层代码则展示了查询的构造细节;
~~~~~~ URL之所以可以用来获取某个文档,真正原因显然是其描述了网络上该特定文档的位置以及获取方法。URL包含了协议的名称,后面跟着保存文档的主机名,最后是该主机上特定文档的路径。URL提供了更底层协议查询该文档所需的指令。这样一来,search2.py就能够解析URL并获取响应文档;
~~~~~~ 事实上,这个URL使用的底层协议就是著名的 HTTP( Hypertext Transfer Protocol,超文本传输协议)、HTTP协议几乎是所有现代网络通信的基础。
~~~~~~ HTTP是无法通过稀薄的空气在两台机器间传输数据的;HTTP协议必须使用一些更简单的抽象来完成操作;事实上,现代操作系统提供了使用TCP协议在IP网络的不同程序间进行纯文本网络会话的功能,而HTTP协议正是使用了这一功能;换句话说, HTTP协议精确描述了两台主机间通过TCP传输的信息格式,并以此提供HTTP的各项功能;
~~~~~~ 最底层:使用主机操作系统提供的原始==socket()==函数来支持IP网络上的网络通信;换句话说,这种编写网络程序的方式和使用C语言的底层系统程序员所用的一样;
协议栈:先构建利用网络硬件在两台计算机之间传送文本字符串的原始对话功能,然后在此基础上创建更复杂、更高层、语义更丰富的对话;
前面例子中分析过的协议栈包含四层:
- 最上层的谷歌地理编码API,对如何用URL表示地理信息查询和如何获取包含坐标信息的JSON数据进行了封装;
- URL,标识了可通过HTTP获取的文档;
- HTTP层,支持面向文档的命令(例如GET ),该层的操作使用了原始TCP/IP套接字;
- TCP/IP套接字,只处理字节串的发送和接收;
~~~~~~ 随着使用的通信协议越来越底层,程序的质量也明显下降,所以应尽可能地使用标准库or第三方库;高层网络协议通常都会将其底层网络细节隐藏;
~~~~~~
其次socket()也并不是涉及到的最底层的协议,套接字这一抽象其实也基于更底层的协议,不过这些协议由OS管理,而非python:
- 传输控制协议(TCP),该层通过发送(可能重发)、接收以及重排称为数据包( packet)的小型网络信息,支持由字节流组成的双向网络会话;
- 网际协议(IP),该层处理不同计算机间数据包的发送;
- 最底层的“链路层”,该层负责在直接相连的计算机之间发送物理信息,由网络硬件设备组成,如以太网端口和无线网卡;
python中的字符串包含了Unicode字符;
解码(decoding):在应用程序使用字节时发生的,此时需要理解这些字节的意义;即当应用程序从文件或网络接受到字节时,程序要对通信信道间传输的原始字节进行解密;
编码(encoding):程序将字符串对外输出时所实施的过程;应用程序使用某种编码方法将字符串转化为字节,当计算机需要传输或存储符号时,字节才是真正使用的格式;
网络互联( networking ):指的是通过物理链路将多台计算机连接,使之可以相互通信;
网际互联( internetworking ):指的是将相邻的物理网络相连,使之形成更大的网络系统,比如互联网;
网际协议(IP):是为全世界通过互联网连接的计算机赋予统一地址系统的一种机制,它使得数据包能够从互联网的一端发送至另一端。理想情况下,网络浏览器无需了解具体使用哪种网络设备来传输数据包,就能够连接上任意一台主机;
~~~~~~ DNS域名解析系统将主机名解析到IP地址,这一过程由操作系统完成;
import socket
if __name__ == '__main__':
hostname = "www.baidu.com"
addr = socket.gethostbyname(hostname)
print("the ip of {} is {}".format(hostname, addr))
# output:
# the ip of www.baidu.com is 112.80.248.75
两个特殊的地址段:
127.x.x.x:以127开头的ip地址段由机器上运行的本地应用程序使用,表示运行该程序的机器本身,大多机器只用其中一个,即127.0.0.1,可通过主机名localhost来访问;- 还有就是私有子网,运营互联网的机构保证过:绝不会把这三个地址段中的任何地址分发给运行服务器或服务的实体公司。因此,在连接互联网时,可以确定,这些地址是没有意义的,它们并不对应可连接的任一主机。所以,如果要构建组织内部网络,可以随意使用这些地址来自由分配内部的IP地址,不需让外网访问这些主机。
路由(routing):根据目的IP地址选择将IP数据包发往何处的机器;
数据包分组:网络中数据包的容量时有限的,你不能把一个文件全部装在一个数据包中发过去,而是要把它切割为若干个数据包分别发送,这样有利于丢失重发、有利于减轻网络负担;
~~~~~~ 数据包是否分组一般会用标志位DF(Don’t Fragment)表示,若DF=0,表示分组,当数据包容量超过网络容纳上限时,对数据包进行分组;DF=1表示不分组,若超过上限则丢弃;
最大传输单元MTU(Maximum Transmission Unit):一个互联网子网能够接受的最大数据包;比如以太网MTU=1500B;
~~~~~~ 两个独立的应用程序如何维护一个会话,并保证每个数据包传输到正确的目的地(应用程序)?
-
多路复用(multiplexing):为两台主机间传送的大量数据包打上标签,区分用于表示网页和电子邮件的数据包;即不同标签的数据包同时传输;
-
可靠传输(reliable transport):数据包流发生错误要进行修复,丢失的要重传,直到发送成功,顺序错乱要重组回正确的顺序,最后丢弃重复的数据包,保证线路上没有冗余;
UDP解决了第一个问题,而TCP解决了两个问题;
三、UDP
用户数据包协议UDP(User Datagram Protocol):UDP 为应用程序提供了一种无需建立连接就可以发送封装的 IP 数据包的方法;
3.1 端口号
多路复用:允许多个会话共享同一介质or机制的一种解决方案,即使用不同的频率来区分无线电信号;
端口号(port number):标识了源/目的机器上发送/接受数据包的特定进程或程序;
Source(IP:port number)->Destination(IP:port number)
- 知名端口(0~1023):被分配给最重要、最常用的服务,普通用户程序一般无法监听这些端口;
- 注册端口(1024~49151):建议只有在使用其指定服务时才使用这些端口;
- 其余端口:OS在端口池中随机选取;
3.2 套接字
~~~~~~ 网络操作背后的系统调用都是围绕着套接字来进行的;OS使用整数(本质是一个文件描述符 file descriptor)来标识套接字,而Python使用socket.socket对象来表示,实质上该对象会自动使用内部维护的套接字整数标识符;
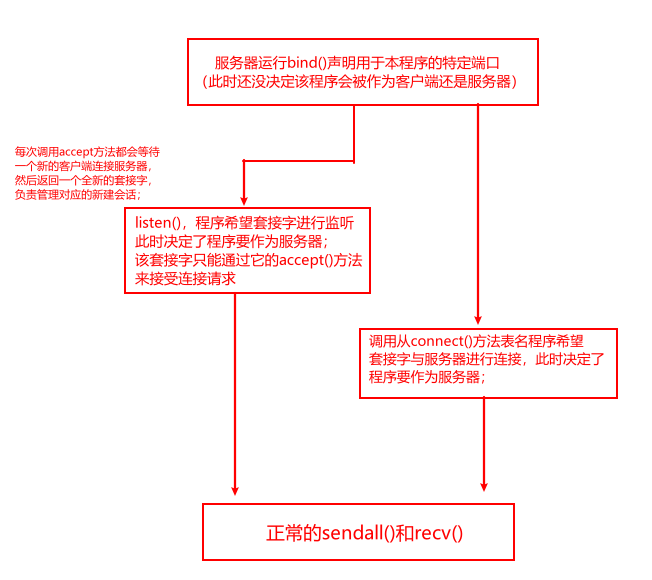
- 首先,服务器使用socket()调用创建了一个空套接字。这个新创建的套接字没有与任何IP地址或端口号绑定,也没有进行任何连接。如果此时就尝试使用其进行任何通信操作,那么将会抛出一个异常;
- 然后,服务器使用
bind()请求绑定一个UDP网络地址(ip,port); - 一旦套接字成功绑定,服务器就准备好开始接收请求了;服务器会进入一个循环,不断运行
recvfrom();recvfrom(NAX_BYTES)表示可接收最长为MAX_BYTES=65535字节的信息,这也是一个UDP数据报可以包含的最大长度。因此,服务器将接收每个数据报的完整内容;在没有收到客户端发送的请求信息前,recvfrom()将永远保持等待;
~~~~~~ 这里的客户端和服务器通过自环接口进行通信,而没有使用可能产生信号故障的物理网卡,因此数据包不可能丢失,所以需要模拟一个比较真实的环境,来体现UDP的麻烦之处;
~~~~~~ 这里随机选择,只对收到的一半客户端请求做出响应;

~~~~~~ 首先,UDP的不可靠性意味着客户端必须在一个循环内发送请求。客户端可以选择永远等待某个请求的响应,也可以在它认为等待“太久”的时候重新发送另一个请求,而等待多久算“太久”其实是个有点儿随意的决定。这一选择虽然困难,但是十分必要;
~~~~~~ 由于这一原因,该客户端不会在调用recv()后永久暂停,而是调用了套接字的settimeout()方法。该方法通知操作系统,客户端进行一个套接字操作的最长等待时间是delay秒;一旦等待时间超过delay秒,就会抛出一个socket.timeout异常,recv()调用就会中断;

~~~~~~ 阻塞这一术语用来描述像recv()这样的调用,只要没有接收到新数据,客户端就会一致等待下去;
指数退避(exponential backoff):如果客户端的请求没有成功,以指数型延迟重试;
~~~~~~ 指数退避使得尝试重发数据包的频率会越来越低,由于正在运行的客户端对他们的请求采用了退避策略,因此发送的数据包会渐渐减少。这样,拥塞的网络就有可能在丢弃了一些请求和响应数据包后慢慢地恢复正常;
~~~~~~ 连接UDP套接字:connect()操作,如果使用sendto(),那么每次向服务器发送信息的时候都必须显式地给出服务器的IP地址和端口。而如果使用connect()调用,那么操作系统事先就已经知道数据包要发送到的远程地址,这样就可以简单地把要发送的数据作为参数传入send()调用,而无需重复给出服务器地址;
~~~~~~ 在使用connect()连接了一个UDP套接字之后,可以使用套接字的getpeername()方法得到所连接的地址,如果该套接字尚未连接,则会返回socket.error;
- 使用
connect()连接UDP套接字,没有在网络上传输任何信息,也没有通知服务器将会收到任何数据包,它只是简单地将连接的地址写入操作系统的内存,一共之后调用send()和recv()的时候使用; - 使用
connect()并不安全;
import argparse, random, socket, sys
MAX_BYTES = 65535
# 服务端
def server(interface, port):
# UDP套接字
sock = socket.socket(socket.AF_INET, socket.SOCK_DGRAM)
sock.bind((interface, port))
print("Listening at", sock.getsockname())
while True:
data, address = sock.recvfrom(MAX_BYTES)
if random.random() < 0.5:
print("Pretending to drop packet from {}".format(address))
continue
text = data.decode('ascii')
print("The client at {} says {!r}".format(address, text))
message = "Your data was {} bytes long".format(len(data))
sock.sendto(message.encode('ascii'), address)
# 客户端
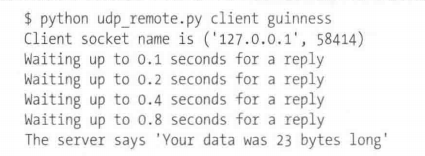
def client(hostname, port):
sock = socket.socket(socket.AF_INET, socket.SOCK_DGRAM)
hostname = sys.argv[2]
sock.connect((hostname, port))
print("Client socket name is {}".format(sock.getsockname()))
delay = 0.1
text = "This is another message"
data = text.encode('ascii')
while True:
sock.send(data)
print("Waiting up to {} seconds for a reply".format(delay))
sock.settimeout(delay)
try:
data = sock.recv(MAX_BYTES)
except socket.timeout:
delay *= 2
if delay > 2.0:
raise RuntimeError("I think the server is down")
else:
break
print("The server says {!r}".format(data.decode('ascii')))
if __name__ == '__main__':
# 运行时选择哪个角色
choices = {'client': client, 'server': server}
parser = argparse.ArgumentParser(description="send and receive UDP,""pretending packets are often dropped")
# 运行时输入选择的角色 server or client
parser.add_argument('role', choices=choices, help="which role to take")
# 输入host(client的host务必要与server的host保持一致)
parser.add_argument('host', help="interface the server listens at;""host the client sends to")
# 端口号,有默认值,想设置就设置
parser.add_argument('-p', metavar='PORT', type=int, default=1060, help='UDP port (default 1060)')
args = parser.parse_args()
function = choices[args.role]
function(args.host, args.p)
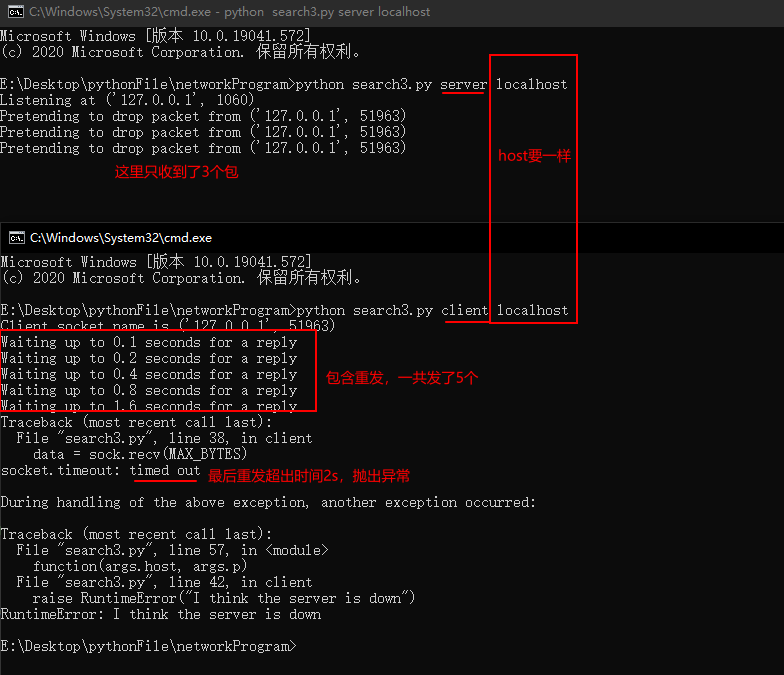
如果二者的host不一样,则会出现下列错误:
socket.gaierror: [Errno 11001] getaddrinfo failed
~~~~~~
到目前为止,我们已经知道,服务器在进行bind()调用的时候可以使用两个IP地址。可以使用127.0.0.1表示只接收来自本机上其他运行程序的数据包,也可以使用空字符串""作为通配符,表示可以接收通过该服务器的任何网络接口收到的数据包;
3.3 UDP分组
UDP必须把较大的UDP数据报分为多个较小的数据报,但这样较大的数据包在传输过程中更易发生丢包现象,因为只要它分隔出的任一小数据包没有传至目标地址,便无法重组出原始的大数据包,正在监听的操作系统也就无法正确接收了;
import argparse, socket
IP_MTU_DISCOVER = 3
IP_PMTUDISC_DO = 2
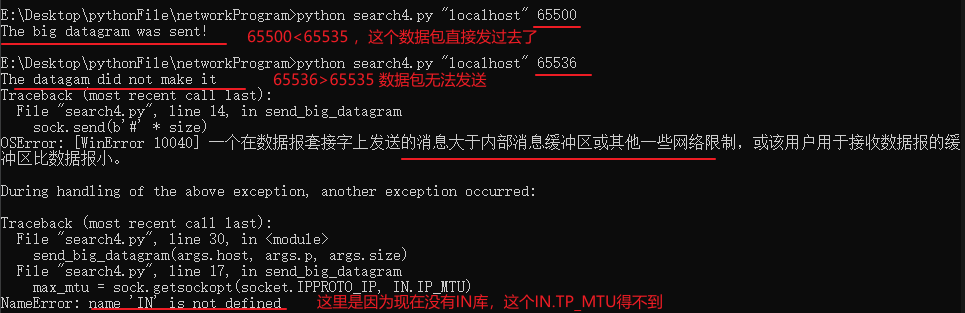
def send_big_datagram(host, port, size):
sock = socket.socket(socket.AF_INET, socket.SOCK_DGRAM)
# 后面两个参数不知道什么意思
sock.setsockopt(socket.IPPROTO_IP, IP_MTU_DISCOVER, IP_PMTUDISC_DO)
sock.connect((host, port))
try:
# size为指定发送的数据包大小
sock.send(b'#' * size)
except socket.error:
print('The datagam did not make it')
max_mtu = sock.getsockopt(socket.IPPROTO_IP, IN.IP_MTU)
print('Actual MTU: {}'.format(max_mtu))
else:
print('The big datagram was sent!')
if __name__ == '__main__':
parser = argparse.ArgumentParser(description='Send UDP packet to get MTU')
parser.add_argument('host', help='the host to which to target the packet')
parser.add_argument('-p', metavar='PORT', type=int, default=1060, help='UDP port (default 1060)')
# 输入发送的数据包大小 默认63000
parser.add_argument('size',type=int, default=63000)
args = parser.parse_args()
send_big_datagram(args.host, args.p, args.size)
这里我会测试size=65500 和 size=65536,结果如下:
3.4 小结
~~~~~~ 用户数据报协议使得用户级程序能够在IP网络中发送独立的数据包。通常情况下,客户端程序向服务器发送一个数据包,而服务器通过每个UDP数据包中包含的返回地址发送响应数据包;
~~~~~~ POSIX网络栈让我们能够通过“套接字”的概念来操作UDP。套接字是一个通信端点,给出了IP地址和UDP端口号。IP地址和UDP端口的二元组叫作套接字的名字( name)或地址( address ),可以用来发送与接收数据报。Python通过内置的socket模块提供了这些网络操作原语。
~~~~~~ 服务器在接收数据包时需要使用bind()绑定一个IP地址和端口。由于操作系统会自动为客户端的UDP程序选择一个端口号,客户端的UDP程序可以直接发送数据包。
~~~~~~ UDP建立在网络数据包的基础上,因此它是不可靠的。丢包现象发生的原因可能是网络传输媒介的故障,也可能是某个网段过于繁忙。因此,客户端需要弥补UDP的不可靠性,不断重发请求直至收到响应为止。为了不使繁忙的网络情况变得更糟,客户端应该在重复传输失败时使用指数退避。如果请求往返于服务器和客户端之间的时间超过了最初设置的等待时间,那么应该延长该等待时间;
~~~~~~ 请求ID是解决重复响应问题的重要利器。重复响应问题指的是,我们收到所有数据包后,又收到了一个被认为已经丢失的响应。此时可能会把该响应误认为是当前请求的响应。如果随机选择请求ID的话,就可以预防最简单的电子欺诈攻击;
~~~~~~ 使用套接字时有一点至关重要,那就是区分绑定( binding)和客户端的连接( connecting )这两个行为。绑定指定了要使用的特定UDP端口,而连接限制了客户端可以接收的响应,表示只接收从正在连接的特定服务器发来的数据包。
~~~~~~ 在可用于UDP套接字的套接字选项中,功能最强大的就是广播。使用广播可以一次向子网内的所有主机发送数据包,而无需向每台主机单独发送。这在编写本地LAN游戏或其他协作计算程序时是很有用的。这也是在编写新应用程序时选用UDP的原因之一。
四、TCP
~~~~~~ 传输控制协议是互联网的重要部分。TCP的第一个版本是在1974年定义的,它建立在网际层协议(IP)提供的数据包传输技术之上。TCP使得应用程序可以使用连续的数据流进行相互通信。除非由于网络原因导致连接中断或冻结,TCP都能保证将数据流完好无缺地传输至接收方,而不会发生丢包、重包或是乱序的问题;
~~~~~~ 传输文档和文件的协议几乎都是使用TCP的。这包括通过浏览器浏览网页、文件传输以及用于电子邮件传输的所有主要机制。TCP也是用于人机之间进行长对话的协议的基础之一,例如SSH终端会话和许多流行的聊天协议;
~~~~~~ 早期,UDP还是很有诱惑力的,常用UDP来构建程序,不过需要仔细选择每个数据包大小和发送时机;而TCP出现后,很少有人能在改进TCP栈的性能;
4.1 TCP工作原理
- 通过序列号能正确排序,也能发现丢失的数据包,并请求重传,序列号采用包的字节大小作为序列号,一个2个字节的包序列号为1,那么下一个包的序列号就是3;意味着重传不需要记录数据流是如何分割数据包的,还可以选择别的分割方式将数据流进行分割;
- 安全的TCP初始序列号都是随机选择的,这样坏人就无法假设序列号都从0开始,就难以伪造数据包;
- TCP并不通过锁步的方式进行通信,就是收到一个发一个确认,收到确认再发下一个,这样很慢。相反,TCP无须等待响应就能一口气发送多个数据包,在某一时刻发送方希望同时传输的数据量叫作TCP窗口 ( window )的大小。
- 接收方的TCP实现可以通过控制发送方的窗口大小来减缓或暂停连接,这叫作流量控制( flowcontrol )。这使得接收方在输入缓冲区已满时可以禁止更多数据包的传输。此时如果还有数据到达的话,那么这些数据也会被丢弃。
- 最后,如果TCP认为数据包被丢弃了,它会假设网络正变得拥挤,然后减少每秒发送的数据量;
~~~~~~ TCP完成一个完整的请求至少需要6个数据包;如果需要长时间的连接,那么TCP还是很好的选择,因为三次握手的时间开销只需一次,连接建立后就能利用TCP在重传、指数退避以及流量控制方面提供的支持;
~~~~~~ 而在客户端与服务器之间不存在长时间连接的情况下,使用UDP更为合适。尤其是客户端太多的时候。一台典型的服务器如果要为每台与之相连的客户端保存单独的数据流的话,那么就可能会内存溢出了;
~~~~~~ UDP数据报通常是互联网实时多媒体流的基础;
~~~~~~ 使用UDP通信只需要一个套接字,服务器打开一个UDP端口后,可以从数千个不同的客户端接受数据报;也可以通过connect()将一个数据报套接字与另一个连接,这样该套接字就只能使用send()向与之连接的套接字发送数据包,recv()调用也只会接受来自特定套接字的数据包;连接只是提供了操作的便利,直接使用sendto()也可以由应用程序决定数据包的唯一目标并且忽略其他所有地址;
~~~~~~ 而TCP的connect()调用时后续所有网络通信的第一步,这与UDP的connect()不同;TCP连接需要一端处于监听状态并做好接受连接请求的准备;服务器端不进行connect()调用,而是接受客户端connect()调用的初始SYN数据包,即新建被动套接字(监听套接字);主动套接字(连接套接字)将一个特定的IP地址及端口号和某个与其进行远程会话的主机绑定,主动套接字只用于与该特定远程主机进行通信;
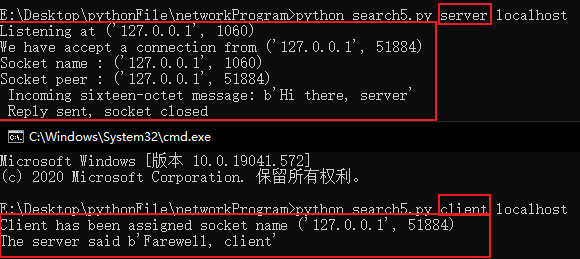
import argparse, socket
def recvall(sock, length):
data = b''
while len(data) < length:
more = sock.recv(length - len(data))
if not more:
raise EOFError(
'was excepting %d bytes but only received %d bytes before the socket closed' % (length, len(data)))
data += more
return data
def server(interface, port):
sock = socket.socket(socket.AF_INET, socket.SOCK_STREAM) # 建立监听套接字,服务器通过监听套接字设定某个端口用于监听连接请求
sock.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1) # 设置套接字参数
sock.bind((interface, port)) # 声明端口,也可以用作客户端,指定端口发送消息
sock.listen(1) # 程序调用该声明,希望套接字能够监听,此时真正决定了程序要作为服务器
# listen()方法传入的整形参数,指明了处在等待连接的最大数目
print('Listening at', sock.getsockname())
while True:
sc, sockname = sock.accept() # 接受连接请求,新建套接字,sc为新建套接字,sockname为连接套接字名称,如果没有客户端连接,则保持阻塞状态
print('We have accept a connection from', sockname)
print('Socket name :', sc.getsockname())
print('Socket peer :', sc.getpeername())
# 可以从代码中看到,getsockname同时适用于接听套接字和连接套接字。如果想获取连接套接字对应的客户端地址,可以随时运行getpeername,也可以
# 存储accept方法的第二个返回值
message = recvall(sc, 16)
print(' Incoming sixteen-octet message:', repr(message))
sc.sendall(b'Farewell, client')
sc.close() # 关闭套接字
print(' Reply sent, socket closed')
def client(host, port):
sock = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
sock.connect((host, port)) # 连接远程服务器IP地址和端口,这里的connect是有可能失败的
print('Client has been assigned socket name', sock.getsockname())
sock.sendall(b'Hi there, server')
reply = recvall(sock, 16)
print('The server said', repr(reply))
sock.close() # 关闭套接字
if __name__ == '__main__':
choices = {'client': client, 'server': server}
parser = argparse.ArgumentParser(description='Send and receive over TCP')
parser.add_argument('role', choices=choices, help='which role to play')
parser.add_argument('host', help='interface the server listens at;''host the client sends to')
parser.add_argument('-p', metavar='PORT', type=int, default=1060, help='TCP port (default 1060)')
args = parser.parse_args()
function = choices[args.role]
function(args.host, args.p)
~~~~~~ UDP要么发送这个数据报,要么接受一个数据报,只有成功发送接受或失败两种状态,及UDP应用程序接收到的只可能是完整无损的数据包;而TCP则不一样,它是发送/接受的数据流,而流是没有开始和结束标志的,所以存在这么三个情况:
- 发送缓冲区未满,且剩余空间大于本次发送的字节数,那么这一段数据都发送出去;
- 发送缓冲区满了,那么本次待发送的数据则会等待至下次发送;
- 发送缓冲区未满,且剩余空间小于本次发送的字节数,那么会先发一部分,有一部分则尚未被处理;
~~~~~~ 对于最后一种情况,需要对send()检查返回值,因为它返回本次发送的字节数,如果有剩余,还要循环至发送完,这一过程代码如下:
bytes_sent = 0
while bytes_sent < len():
message_remaining=message[bytes_sent:]
bytes_sent+=sc.send((message_remaining))
所以,python也嫌麻烦,提供了这么个函数sendall()包装上述过程;
Q:服务器在绑定端口之前为什么要谨慎地设置套接字地SO_REUSEADDR选项呢?
~~~~~~ 像TCP这样的可靠协议在停止通信时会存在这样的问题:逻辑上来说,一些表示通信结束的数据包必须是无需接收响应的,否则系统在机器最终关机前都会无限等待类似“好的,我们双方都同意通信结束,好吧?”这样的消息。然而就算是这些表示通信结束的数据包,其自身也可能丢失,并需要重传多次,直至另一方最终接收。解决方案:一旦应用程序认为某个TCP连接最终关闭了,OS的网络栈实际上会在一个等待状态中将该连接的记录最多保持4分钟;RFC将这些状态命名为CLOSE-WAIT和TIME-WAIT;等于说在这个时间内,FIN数据包还是可以得到适当响应的;
~~~~~~ 因此,当一个服务器试图声明某个几分钟前运行的连接所使用的端口时,其实是在试图声明一个从某种意义上来讲仍在使用的端口。这就是试图通过bind()绑定该地址时会返回错误的原因;
4.2 绑定接口
~~~~~~ 我使用本地IP地址127.0.0.1,表示代码不会接受来自其它机器的连接请求,连拒绝提示都没有;不过,如果使用空字符串作为主机名来运行服务器的话,python的bind()机制就知道我们希望接受来自机器任意运行的网络接口的连接请求,这样客户端就能成功连接另一台主机了;
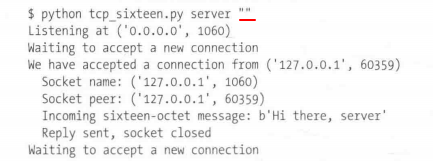
~~~~~~ 如果我的OS使用特殊IP地址0.0.0.0表示“接受传至任意接口的连接请求”,意思就是如果我们把主机名设置为“”空字符串,那么就会把IP地址设置为特殊的0.0.0.0;
4.3 死锁
死锁(deadlock):当两个程序共享有限的资源时,由于糟糕的计划,只能一直等待对方结束资源占用,这种情况就是死锁;
# 可能造成死锁的TCP服务器和客户端
import argparse, socket, sys
# 服务器
# 功能:将客户端上传的字符串中单词的首字符转换成大写,因为一次性处理的话可能由于数据量多大导致崩溃,所以采用分段处理
def server(host, port, bytecount):
sock = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
sock.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1)
sock.bind((host, port))
sock.listen(1)
print('Listening at', sock.getsockname())
while True:
sc, sockname = sock.accept()
print('Processing up to 1024 bytes at a time from ', sockname)
n = 0
while True:
# 每次处理1024字节
data = sc.recv(1024)
if not data:
break
output = data.decode('ascii').upper().encode('ascii')
sc.sendall(output)
n += len(data)
print('\r %d bytes processed so far' % (n,), end=' ')
sys.stdout.flush()
print()
sc.close()
print(' Socket closed')
def client(host, port, bytecount):
sock = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
bytecount = (bytecount + 15)
message = b'capitalize this'
# 发送bytecount个message(1个message由16个字节)
print('Sending', bytecount, 'bytes of data, in chuncks of 16 bytes')
sock.connect((host, port))
sent = 0
while sent < bytecount:
sock.sendall(message)
sent += len(message)
print('\r %d bytes sent' % (sent,), end=' ')
sys.stdout.flush()
print()
sock.shutdown(socket.SHUT_WR)
print('Receiving all the data the server sends back')
received = 0;
while True:
data = sock.recv(42)
if not received:
print(' The first data received says', repr(data))
if not data:
break
received += len(data)
print('\r %d bytes received' % (received,), end=' ')
print()
sock.close()
if __name__ == '__main__':
choices = {'client': client, 'server': server}
parser = argparse.ArgumentParser(description='Get deadlocked over TCP')
parser.add_argument('role', choices=choices, help='which role to play')
parser.add_argument('host', help='interface the serever listen at;''host the client sends to')
parser.add_argument('bytecount', type=int, nargs='?', default=16,
help='number of bytes for client to send (default 16)')
parser.add_argument('-p', metavar='PORT', type=int, default=1060, help='TCP port(default 1060)')
args = parser.parse_args()
function = choices[args.role]
function(args.host, args.p, args.bytecount)
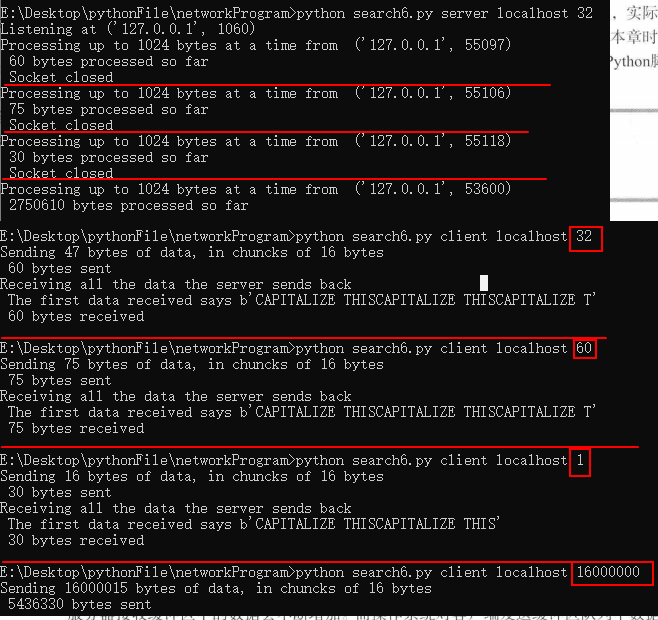
Q:为什么客户端和服务器都会停止?
~~~~~~ 服务器的输出缓冲区和客户端的输入缓冲区最后都会被填满,然后TCP使用滑动窗口协议来处理这种情况,套接字就会停止发送更多的数据,及时发送也会被丢弃再重传;
Q:为什么会导致死锁?
~~~~~~ 考虑一下每个数据块的传输过程中发生了什么,客户端使用sendall()发送数据块,然后服务器使用recv()来接收、处理,接着将数据转换为大写,并再次使用sendall()调用将结果传回。然后呢?好吧,没有了!由于还有数据需要发送,客户端此时没有运行任何recv()调用。因此,越来越多的数据填满了操作系统的缓冲区,缓冲区就无法再接收更多数据了;
~~~~~~ 解决方案:要不在服务器端使用多线程优化,要不就运行select()或poll()等系统调用来控制程序在发送套接字和接受套接字繁忙时等待,有空闲时才做出响应;
4.4 小结
~~~~~~ 基于TCP的“流”套接字提供了所有必需的功能,包括重传丢失数据包、重新排列接收到的顺序错误的数据包,以及将大型数据流分割为针对特定网络的具有最优大小的数据包。这些功能提供了对在网络上两个套接字之间传输并接收数据流的支持;
~~~~~~ 跟UDP一样的是,TCP也使用端口号来区分同一台机器上可能存在的多个流端点。想要接收TCP连接请求的程序需要通过bind()绑定到一个端口,在套接字上运行listen(),然后进入一个循环,不断运行accept(),为每个连接请求新建一个套接字(该套接字用于与特定客户端进行通信)。如果程序想要连接到已经存在的服务器端口,那么只需要新建一个套接字,然后调用connect()连接到一个地址即可;
~~~~~~ 服务器通常都要为绑定的套接字设置SO_REUSEADDR选项,以防同一端口上最近运行的正在关闭中的连接阻止操作系统进行绑定;
~~~~~~ 实际上,数据是通过send()和recv()来发送和接收的。一些基于TCP的协议会对数据进行标记,这样客户端和服务器就能够自动得知通信何时完成。其他协议把TCP套接字看作真正的流,会不断发送和接收数据,直到文件传输结束。套接字方法shutdown()可以用来为套接字生成一个方向上的文件结束符(所有套接字本质上都是双向的),同时保持另一方向的连接处于打开状态。
~~~~~~ 如果通信双方都写数据,套接字缓冲区被越来越多的数据填满,而这些数据却从未被读取,那么就可能会发生死锁。最终,在某个方向上会再也无法通过send()来发送数据,然后可能会永远等待缓冲区清空,从而导致阻塞;
~~~~~~ 如果想要把一个套接字传递给一个支持读取或写入普通文件对象的Python模块,可以使用makefile()方法。该方法返回一个Python对象。调用方需要读取及写入数据时,该对象会在底层调用recv()和send();
五、套接字名与DNS
5.1 套接字方法和指标
~~~~~~ 每个顶级域名(TLD,Top-Level Domain)都有自己的服务器,这些服务器由机构来运行,机构负责为该TLD下所有的域名进行授权;注册一个域名时。机构会在服务器上增加一个相应域名的条目;各地使用该系统来对名称查询做出响应的服务器集合提供了域名服务(DNS,Domain Name Service);
~~~~~~ 回顾一下套接字的方法:
mysocket.accept():该方法由TCP流的监听套接字调用。每当有准备好发送至应用程序的连接请求时,该方法就会被调用。它会返回一个二元组,二元组的第二项是已连接的远程地址(二元组的第一项是新建的连接至远程地址的套接字);mysocket.bind(address):该方法将特定的本地地址(该地址为要发送的数据包的源地址)分配给套接字。如果其他机器要发起连接请求,那么该地址也可作为要连接的地址;mysocket.connect(address):该方法说明,通过套接字发送的数据会被传输至特定的远程地址。对于UDP套接字来说,该方法只是设置了一个默认地址。如果调用方没有使用sendto()和recvfrom(),而是使用了send()和recv(),就会使用这一默认地址。该方法本身没有马上做任何网络通信操作。然而,对于TCP套接字来说,该方法会与另一台机器通过三次握手建立一个新的流,并且会在连接建立失败时抛出一个Python异常;mysocket.getpeername():该方法返回了与套接字连接的远程地址;mysocket.getsockname():该方法返回了套接字自身的本地端点地址;mysocket.recvfrom(...):用于UDP套接字,该方法返回一个二元组,包含了返回数据的字符串和数据的来源地址;mysocket.sendto(data, address):未连接的UDP端口使用该方法向特定远程地址发送数据;
在创建和部署每个套接字对象时总共需要做出5个主要的决定,主机名和IP地址只是其中的最后两个:
- 地址族(Address Family):通常使用AF_INET,因为它提供的连接与互联网套接字提供的非常相似,且UDP和TCP时AF_INET协议族特有的;其它的地址族有AppleTalk、Bluetooth等;
- 套接字类型(socket type):即给出希望在已经选择的网络上使用的特定通信技术;UDP用SOCK_DGRAM,TCP用SOCK_STREAM;
- 协议(protocol):一般默认0,即自动选择协议;系统若发现你在IP层上使用流,它就自动选择TCP,否则选择UDP;
5.2 现代地址解析
~~~~~~ getaddrinfo()是我们用来将用户指定的主机名和端口号转换为可供套接字方法使用的地址时所需的唯一方法;它使得我们能够在一个调用中指明要创建的连接所需的一切已知信息,即返回先前讨论的全部指标;

~~~~~~ 将使用getaddrinfo()返回值的前3项作为socket()构造函数的参数,然后使用返回值的第5项作为传入地址,用于任何需要套接字地址的调用,比如本章第一节中列出的connect();
~~~~~~ getaddrinfo()除了允许提供主机名之外,还允许提供www这样的符号(而不是整数)作为端口名,即用户可以使用www或者smtp这样的符号作为端口号,而不是80或25;
5.2.1 使用getaddrinfo()连接服务
~~~~~~ 准备调用connect()或sendto()连接服务或向服务发送数据时,调用getaddrinfo(),并设置AI_ADDRCONFIG标记,该标记将把计算机无法连接的所有地址都过滤掉;
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-zp0rp9ko-1606977471766)(https://raw.githubusercontent.com/Luweir/picpicgo/main/img/20201203142755.png)]](https://img-blog.csdnimg.cn/20201203145307691.png)
~~~~~~ 这样就从getaddrinfo()的返回值中得到了我们所需要的信息:这是一个列表,包含了通过TCP方式连接ftp.kernel.org主机FTP端口的所有方式。注意到返回值中包括了多个IP地址。这是因为,为了负载均衡,该服务部署在了互联网的多个不同地址上,当返回值像上面这样包含了多个地址时,通常应该使用返回的第一个地址。只有在连接失败时才应该尝试使用剩下的地址。远程服务的管理员根据他们的希望用户要连接的服务器赋予了一定顺序,这样用户提供的负载就会与管理员的设想相一致;
~~~~~~ 当我们需要知道属于通信对方套接字IP地址的官方主机名,IP地址的拥有者可以根据它们的希望令DNS服务器返回任意值作为查询结果;
反向DNS查询:对规范主机名的查询会将IP地址映射到一个主机名,而不是将主机名映射到IP地址;
~~~~~~ 此时,我们可能要先查阅并确认它确实可以被解析为原始的IP地址,然后才能信任该返回结果;
~~~~~~ 一般做法就是支队IP地址进行日志记录,如果某个IP地址引发了问题,可以先从日志文件中找到该地址,然后手动查询对应主机名;如果有必要,可以尝试反向查询,只要在运行getaddrinfo()时设置AI_CANONNAME标记即可,返回元组的第4项包含规范主机名(只有在IP地址拥有者正好定义了反向主机名才适用;);
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-vm2yUj6z-1606978350373)(https://raw.githubusercontent.com/Luweir/picpicgo/main/img/20201203142759.png)]](https://img-blog.csdnimg.cn/20201203145244360.png)
使用getaddrinfo():
import argparse, socket, sys
def connect_to(hostname_or_ip):
try:
infolist = socket.getaddrinfo(hostname_or_ip, 'www', 0, socket.SOCK_STREAM, 0, socket.AI_ADDRCONFIG | socket.AI_V4MAPPED | socket.AI_CANONNAME)
# getaddrinfo()请求连接到hostname_or_ip提供的HTTP服务所需的可能方法,返回一个可以提供链接的方法
# AI_ADDRCONFIG标记,把计算机无法连接的所有地址过滤掉
# AI_V4MAPPED,将IPv4地址重新编码为可实际使用的IPv6地址
# AI_CANNONNAME,反向查询,返回元组的第四项中包含规范主机名
except socket.gaierror as e:
print('Name service failure:', e.args[1])
sys.exit(1)
info = infolist[0] # 返回元组列表中第一项
socket_args = info[0:3] # 协议族
address = info[4] # 规范主机名
s = socket.socket(*socket_args)
try:
s.connect(address)
except socket.error as e:
print('Network failure:', e.args[1])
else:
print('Success: host', info[3], ' is listening on port 80.')
if __name__ == '__main__':
parser = argparse.ArgumentParser(description = 'Try connecting to port 80')
parser.add_argument('hostname', help='hostname that you want to contact')
connect_to(parser.parse_args().hostname)
5.3 DNS协议
域名系统(DNS,Domain Name System):对互联网主机之间相互协作,对主机名与IP地址映射关系查询做出响应的一种机制;
~~~~~~ 如果本地机构(本地计算机和名称服务器)无法解析你要访问的主机名(原因是该主机名既不属于本机机构,也没有在近期访问并仍然处于名称服务器的缓存中),这种情况就要查询世界上的某个顶级名称服务器,获取负责查询的域名的DNS服务器,一旦返回DNS服务器的IP地址,就反过来访问该地址,完成域名查询;/etc/hosts文件相当于用户定义的一些主机名-IP地址;
~~~~~~ 整个域名查询过程:
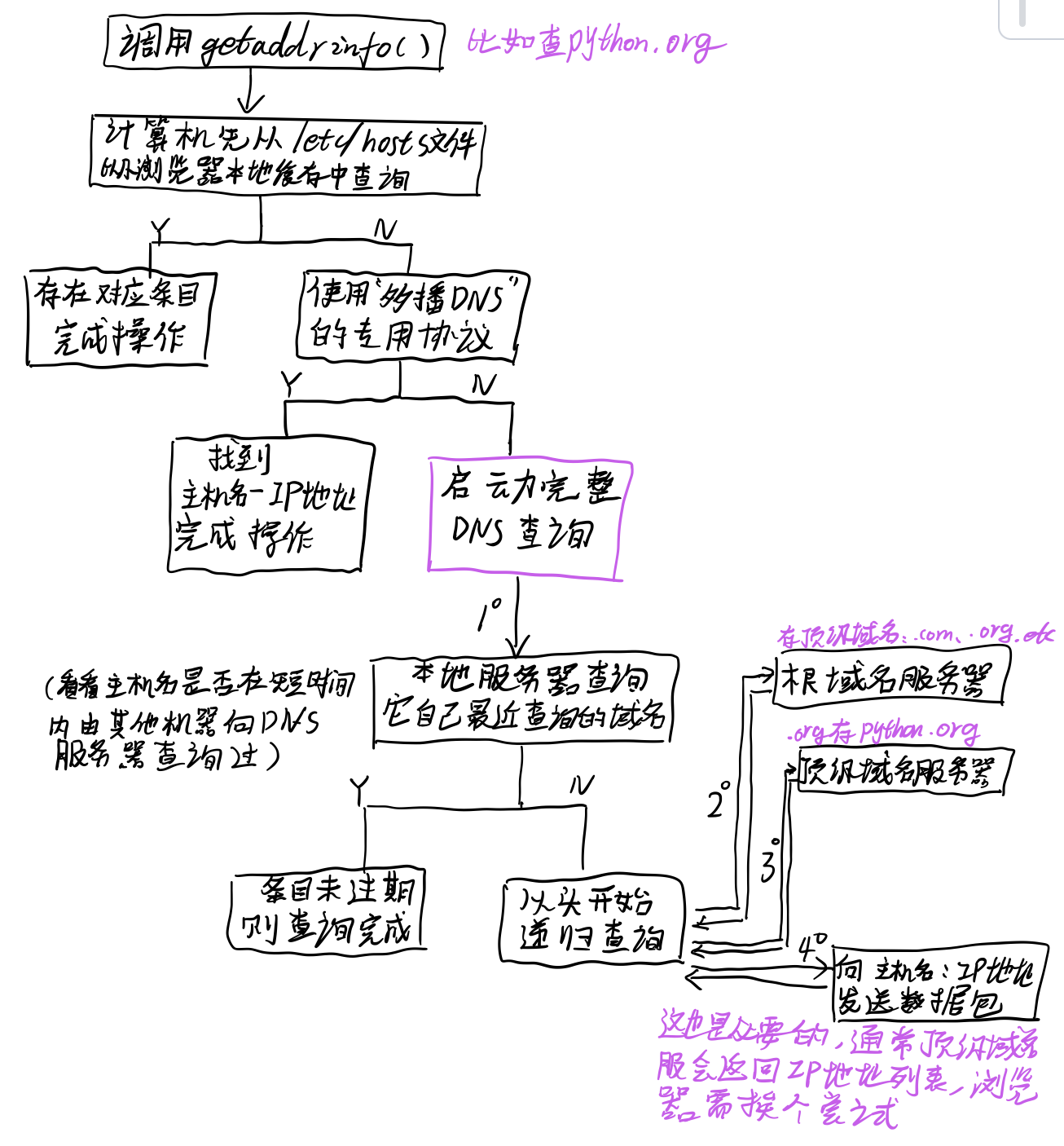
~~~~~~
缓存在IP地址查询过程中扮演很重要的角色;
~~~~~~
python的dnspython3包能够进行DNS查询,这是一个包含递归的简单DNS查询:
import argparse,dns.resolver
def lookup(name):
for qtype in 'A', 'AAAA', 'CNAME', 'MX', 'NS': # 记录类型,顺序是MX->A->AAAA->CNAME对应的MX记录或者A记录
answer = dns.resolver(name, qtype, raise_on_no_answer=False)
if answer.rrset is not None:
print(answer.rrset)
if __name__ == '__main__':
parser = argparse.ArgumentParser(description="Resolve a name using DNS")
parser.add_argument('name', help='name that you want to lookup')
lookup(parser.parse_args().name)
程序显示:No module named ‘dns’,但我的python库里面由dns这个包,奇怪了;
5.4 小结
~~~~~~ Python程序通常需要将主机名转换为可以实际连接的套接字地址;
~~~~~~ 多数主机名查询都应该通过socket模块的getsockaddr()函数完成。这是因为,该函数的智能性通常是由操作系统提供的。它不仅知道如何使用所有可用的机制来查询域名,还知道本地IP栈配置支持的地址类型(IPv4或IPv6 );
~~~~~~ 传统的IPv4地址仍然是互联网上最流行的,但IPv6正在变得越来越常见。通过使用getsockaddr()进行主机名和端口号的查询,Python程序能够将地址看成单一的字符串,而无需担心如何解析与解释地址。
~~~~~~ DNS是多数名称解析方法背后的原理。它是一个分布在世界各地的数据库,用于将域名查询直接指向拥有相应域名的机构的服务器。尽管在Python中直接使用原始DNS查询的频率不高,但是它在基于电子邮件地址中@符号后的域名直接发送电子邮件时还是很有帮助的;
六、网络数据与网络错误
~~~~~~ 计算机的内存芯片和网卡都支持将字节作为通用传输单元;
~~~~~~ Python 3的字符串能够包含的字符远远不止是ASCII字符,一个叫作Unicode的标准,我们现在不仅仅能够像ASCII一样为0~127这128个数字分配字符代码,还能够为多达几千甚至几百万个数字分配字符代码。Python把字符串看成是由Unicode字符组成的序列;对字符进行编码(encoding),即将真正的Unicode字符串转换为字节字符串;对字节数据进行解码(decoding),即将字节字符串转换为真正的Unicode字符;
6.1 封帧与引用
~~~~~~ 计算机存储二进制数字的字节顺序是不同的:
- 大端法:低位字节存储在低地址;
- 小端法:低位字节存储在高地址;
Q:如何分割消息,使接收方能够识别消息的开始与结束?
- 模式一:只涉及数据的发送,而不关注响应。因此,接收方永远不会认为“数据已经够了”,然后向发送方发送响应。在这种情况下,可以使用这种模式:发送方循环发送数据,直到所有数据都被传递给
sendall()为止,然后使用close()关闭套接字。接收方只需要不断调用recv(),直到recv()最后返回一个空字符串(表示发送方已经关闭了套接字)为止;需要注意的是,由于这个套接字并没有准备接收任何数据,因此,当客户端和服务端不再进行某一方向的通信时会立即关闭该方向的连接; - 模式二:使用定长消息,使用
sendall()方法发送字节字符串,然后使用自己设计的recv()循环确保接受完整的消息; - 模式三:通过某些方法,使用特殊字符来划分消息的边界;接收方会进入与上面类似的
recv()循环并不断等待,直到不断累加的返回字符串包含表示消息结束的定界符为止。如果能够确保消息中的字节或字符在特定的有限范围内,那么自然就可以选择该范围外的某个符号作为消息的结束符;比如,如果正在发送的是ASCII字符串,那么可以选择空字符'\0'作为定界符,也可以选择像'xff'这样处于ASCii字符范围之外的字符;如果消息中包含定界符,则使用引用\xx来表示; - 模式四:在每个消息前加上其长度作为前缀,如果使用该模式,那么无需进行分析、引用或者插人就能够一字不差地发送二进制数据块。因此,对于高性能协议来说,这是一个很流行的选择。当然,消息长度本身需要使用帧封装。通常会使用一个定长的二进制整数或是在变长的整数字符串后面加上一个文本定界符来表示长度。无论使用哪种方法,只要接收方读取并解码了长度,就能够进入循环,重复调用
recv(),直到整个消息都传达为止。 - 模式六:如果无法知道每个消息的长度,那么使用这个模式。我们并非只发送单个消息,而是会发送多个数据块,并且在每个数据块前加上数据块长度作为其前缀。这意味着,每个新的信息块对发送者来说都是可见的,可以使用数据块的长度为其打上标签,然后将数据块置入发送流中。抵达信息结尾时,发送方可以发送一个与接收方事先约定好的信号(比如数字0表示的长度字段),告知接收方,所有数据块已经发送完毕;
使用长度前缀将每个数据块封装为帧:
# search8.py
#!/usr/bin/env python3
# -*- encoding:utf8 -*-
import socket, struct
from argparse import ArgumentParser
header_struct = struct.Struct('!I') #messages up to 2**32 -1 in length
def recvall(sock, length):
blocks = []
while length:
block = sock.recv(length)
if not block:
raise EOFError('socket closed with %d bytes left''in this block'.format(length))
length -= len(block)
blocks.append(block)
return b''.join(blocks)
def get_block(sock):
data = recvall(sock, header_struct.size)
(blcok_length,) = header_struct.unpack(data)
return recvall(sock, blcok_length)
def put_block(sock, message):
block_length = len(message)
sock.send(header_struct.pack(block_length))
sock.send(message)
def server(addr):
sock = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
sock.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1)
sock.bind(addr)
sock.listen(1)
print('Run this script in another window with "-c" to connect ')
print('Listening at', sock.getsockname())
sc, sockname = sock.accept()
print('Accept connection from ', sockname)
# 不允许服务器发送数据
sc.shutdown(socket.SHUT_WR)
while True:
block = get_block(sc)
if not block: break
print('Block says:', repr(block))
sc.close()
sock.close()
def client(addr):
sock = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
sock.connect(addr)
# 不允许客户端接受数据
sock.shutdown(socket.SHUT_RD)
put_block(sock, b'Beautiful is better than ugly')
put_block(sock, b'Explicit is better than implicit')
put_block(sock, b'Simple is better than complex')
sock.close()
if __name__ == "__main__":
parser = ArgumentParser(description="Transmit & receive blocks over TCP")
parser.add_argument('hostname', nargs='?', default='127.0.0.1',
help='IP address or Hostname(default:%(default)s)')
parser.add_argument('-c', action='store_true', help='run as the client')
parser.add_argument('-p', type=int, metavar='port', default=1060,
help='TCP port number(default:%(default)s)')
args = parser.parse_args()
function = client if args.c else server
function((args.hostname, args.p))
Q:shutdown()和close()有什么区别?
shutdown():为了保证通信双方都能够收到应用程序发出的所有数据,一个合格的应用程序的做法是通知接受双发都不在发送数据!这就是所谓的“正常关闭”套接字的方法,而这个方法就是由shutdown函数,传递给它的参数有SD_RECEIVE,SD_SEND,SD_BOTH三种,如果是SD_RECEIVE就表示不允许再对此套接字调用接受函数。这对于协议层没有影响,另外对于TCP套接字来说,无论数据是在等候接受还是即将抵达,都要重置连接(注意对于UDP协议来说,仍然接受并排列传入的数据,因此UDP套接字而言shutdown毫无意义)。如果选择SE_SEND,则表示不允许再调用发送函数。对于TCP套接字来说,这意味着会在所有数据发送出并得到接受端确认后产生一个FIN包;如果指定SD_BOTH,答案不言而喻。close:对此函数的调用会释放套接字的描述,这个道理众所周知,因此,调用此函数后,再是用此套接字就会发生调用失败,通常返回的错误是WSAENOTSOCK。此时与被close()的套接字描述符相关联的资源都会被释放,包括丢弃传输队列中的数据!!!!对于当前进程中的线程来讲,所有被关起的操作,或者是被挂起的重叠操作以及与其关联的任何事件,完成例程或完成端口的执行都将调用失败!另外SO_LINGER标志还影响着close()的行为,但对于传统的socket程序,这里不加解释;- 因此可以可以看出
shutdown()对切断连接有着合理的完整性,即shutdown()会确保windows建立的数据传输队列中的数据不被丢失,而close()会冒然的抛弃所有的数据;
参考文章:
~~~~~~ HTTP协议混合使用上面的模式三和模式四,也可以使用模式五;如果服务器要使用流发送长度未知的响应,那么HTTP可以使用“分块编码”来发送一系列包含长度前缀的数据块,使用长度为0的字段表示传输结束;
6.2 XML与JSON
Q:为什么要使用XML与JSON?
~~~~~~ 如果要设计支持其他编程语言的协议,或者只是希望使用通用标准,而不是特定于Python的格式,那么JSON和XML这两种数据格式都是很流行的选择。注意,这两种格式本身都不支持封帧。因此,在处理网络数据前,先要使用某种方法提取出完整的文本字符串;
~~~~~~ JSON使用过一个字符串来表示的,按照它的标准,需要使用UTF-8对JSON字符串进行编码,用于网络传输;对于文档来说,XML更为适用;
6.3 压缩
~~~~~~ 数据在网络中传输所需的时间通常远远多于CPU准备数据所用的时间。因此,在发送前对数据进行压缩,通常是非常值得的。GNU的zlib是当今互联网最普遍的压缩形式之一,Python标准库提供了对zlib的支持;在传递一个压缩过的数据流时,zlib能够识别出压缩数据何时到达结尾,如果后面还有未经压缩的数据,用户也可以直接访问;
Q:存在压缩后数据量反而变多的情况吗?
~~~~~~ 存在,大多数压缩机制在接收的数据量极小时,得到的结果都比原始数据更长,而不是更短。这是由于为了进行压缩而额外需要的数据量反而超过了压缩掉的数据量;
6.4 网络异常:
socket.timeout()异常:套接字发出超时通知,即超过设定时间客户端还没获得响应;OSError:这是socket模块可能抛出的主要错误,网络传输的所有阶段可能发生的任何问题几乎都会抛出该异常;socket.gaierror:在getaddrinfo()无法找到提供的名称或服务时被抛出;
异常处理:
- 不处理网络异常;
- 将网络错误封装成我们自己的异常,能在发生网络错误时构造出更清晰的错误信息,明确地解释导致错误地库操作;
6.5 小结
~~~~~~ 要把机器信息存放到网络上,就必须先进行相应的转换。无论我们的机器使用的是哪种私有的特定存储机制,转换后的数据都要使用公共且可重现的表示方式。这样的话,其他系统和程序,甚至其他编程语言才能够读取这些数据;
~~~~~~ 对于文本来说,最重要的问题就是选择一种编码方式,将想要传输的字符转换为字节。这是因为,包含8个二进制位的字节是IP网络上的通用传输单元。我们需要格外小心地处理二进制数据,以确保字节顺序能够兼容不同的机器。Python的struct模块就是用来帮助解决这个问题的。有时候,最好使用JSON或XML来发送数据结构和文档。这两种格式提供了在不同机器之间共享结构化数据的通用方法;
~~~~~~ 使用TCP/IP流时,我们会面临的一个重要问题,那就是封帧,即在长数据流中,如何判定一个特定消息的开始与结束。为了解决这个问题,有许多技术可供选用。由于recv()每次可能只返回传输的部分信息,因此无论使用哪种技术,都需要小心处理。为了识别不同的数据块,可以使用特殊的定界符或模式、定长消息以及分块编码机制来设计数据块;
~~~~~~ Python的pickle除了能把数据结构转换为能用于网络传输的字符串外,还能够识别接收到的pickle的结束符。这使得我们不仅可以使用pickle来为数据编码,也可以使用pickle来为单独的流消息封帧。压缩模块zlib通常会和HTTP一起使用。它也可以识别压缩的数据段何时结束,也因此提供了一种花销不高的封帧方法;
~~~~~~ 与我们的代码使用的网络协议一样,套接字也可以抛出各种异常。何时使用try. ..except从句取决于代码的用户——我们是为其他开发者编写库还是为终端用户编写工具?除此之外,这一选择也取决于代码的语义。如果从调用者或终端用户的角度来看,某个代码段进行的是同一个较为宏观的操作,那么就可以将整个代码段放在一个try. ..except从句中;
~~~~~~ 最后,如果某个操作引发的错误只是暂时的,而调用晚些时候可能会成功,并且我们希望该操作能自动重试的话,就应将其单独包含在一个try. ..except从句中;
七、TLS/SSL
~~~~~~ 传输层安全协议(TLS,Transport Layer Security)可能是如今互联网上应用最广泛的加密方法了;TLS的前身是安全套接层(SSL,Secure Sockets Layer),用于验证服务器身份,并保持传输过程中的数据;
7.1 TLS无法保护的信息
~~~~~~ TLS能保护得信息包括:
- 与请求URL之间的HTTPS连接以及返回内容、密码或cookie等可能在套接字双向传递得任意认证信息;
~~~~~~ TLS无法保护的信息,或者对第三方可见的信息:
- 本机与远程主机的地址;
- 端口号;这两个都在IP头信息里;
- DNS查询;
整个过程举例:
~~~~~~ 比如我们最喜欢的网络浏览器访问htps:/pypi.python.org/pypiskyfield,在咖啡店中,"观察者”可能是连接到咖啡店无线网络的任何人,也可能是控制了咖啡店与外网之间的路由器的某个人;那么观察者可能会了解到哪些信息呢?观察者首先会发现我们的机器向pypi.python.org发出了一个DNS查询。除非返回的IP地址上还托管了许多其他网站,否则的话,观察者会猜测我们与该IP地址443端口之间进行的后续通信都是为了查看https:/pypi.python.org的网页。HTTP是一个支持锁步的协议,服务器完整读取请求后才会返回响应,因此观察者同样能够区分我们的HTTP请求与服务器响应。除此之外,观察者还知道返回文档的大致大小以及我们获取这些文档的顺序;
~~~~~~ 一旦建立并运行了套接字,同时完成了表示协议启用加密的几次交互之后,TLS就会负责接下来的工作了;它能够保证,窃听者绝对无法破译通信对方的数据。同时,在与通信对方的通信过程中,窃听者也绝对无法破译传输的数据;
~~~~~~ TLS客户端需要的第一样东西就是远程服务器提供的一个二进制文档,称为证书( certificate)。证书中包含了被密码学家叫作公钥( public key )的东西。公钥是一个整数,用于对数据加密。只有拥有与公钥对应的私钥(也是一个整数),才能解密并理解相应的信息。如果远程服务器配置正确,并且没有被破解,那么它将是互联网上唯一拥有该私钥的服务器(可能有一个例外,相同集群中的其他机器可能也会拥有该私钥)。
~~~~~~ TLS实现是如何验证远程服务器确实拥有该私钥的呢?这很简单! TLS库会向服务器发送一些已经用公钥加密过的信息,然后要求服务器返回一个校验码,表示服务器能够使用私钥成功解密接收到的数据;TLS会话保存了一个证书机构(CA)列表,该列表中包含了我们在对互联网主机进行身份验证时信任的机构;
~~~~~~ 为了证明一个证书的合法性。CA会为证书加上一个数学标记,该标记叫作签名(signature )。TLS库使用相应CA证书的公钥验证了证书的签名之后,才会认为该证书是合法的,还会保存证书的有效期;
7.2 小结:
~~~~~~ 在一个典型的TLS交换场景中,客户端向服务器索取证书——表示身份的电子文件。客户端与服务器共同信任的某个机构应该对证书进行签名。证书中必须包含一个公钥。之后服务器需要证明其确实拥有与该公钥对应的私钥。客户端要对证书中声明的身份进行验证,确定该身份是否与想连接的主机名匹配。最后,客户端与服务器就加密算法、压缩以及密钥这些设定进行协商,然后使用协商通过的方案对套接字上双向传输的数据进行保护;
~~~~~~ 许多管理员甚至都没有尝试在他们的应用程序中支持TLS;反之,他们把应用程序隐藏在了工业强度的前端工具之后,比如Apache、nginx或是HAProxy这些可以自己提供TLS功能的工具。在前端使用了内容分发网络的服务也必须把支持TLS功能的责任留给第三方工具,而不是将其嵌入自己的应用程序中;
~~~~~~ 尽管网络搜索的结果会提供一些使用第三方库在Python中提供TLS支持的建议,不过Python标准库的ssl模块实际上已经内置了对OpenSSL的支持。如果我们的操作系统以及Python版本上支持ssl模块,而且它能正常工作,那么只需要一个服务器的证书,就可以建立基本的加密连接。
~~~~~~ 由Python 3.4编写的应用程序通常会遵循如下模式:先创建一个**“上下文”对象**,然后打开连接,调用上下文对象的wrap_socket()方法,表示使用TLS协议来负责后续的连接。尽管可以在旧式风格的代码中看到ssl模块提供的一个或两个简短形式的函数,但是上下文-连接-包装这一模式才是最通用,也是最灵活;
八、服务器架构
8.1 部署
~~~~~~ 使用单台机器上的服务,客户端只需直接连接到该机器的IP地址即可;如果要使用运行在多台机器上的服务,有以下更复杂的方法:
- 法一:把该服务的某个实例地址给客户端连接,如果服务宕机了,连接断开;
- 法二:令DNS服务器返回运行该服务的所有IP地址,如果客户端连不上第一个IP地址,就连第二个,以此类推;即在服务前端配置一个负载均衡器( load balancer ),客户端直接连接到负载均衡器,然后由负载均衡器将连接请求转发至实际的服务器。如果某台服务器宕机了,那么负载均衡器会将转发至该服务器的连接请求予以停止,直到该服务器恢复服务为止。这样的话,服务器的故障对于大量用户来说是不可见的;
~~~~~~ 大型的互联网服务则结合了上述两种方法:每个机房中都配置了一个负载均衡器与服务器群,而公共的DNS名会返回与用户距离最近的机房中的负载均衡器的IP地址;
8.2 单线程服务器
单线程服务器:最简单的可用服务器;
8.3 多线程与多进程服务器
~~~~~~ 多线程与多进程服务器:如果希望服务器能同时与多个客户端进行会话,即利用OS的内置支持,使用多个控制线程单独运行同一段代码,可以创建多个共享相同内存空间的线程,也可以创建完全独立运行的进程;
- 优点是简洁:可以直接使用单线程服务器的代码,创建多个线程运行它的多份副本;
- 缺点是:服务器能够同时通信的客户端数量受操作系统并发机制规模的限制;即使某个客户端处于空闲状态,或是运行缓慢状态,它也会占用整个线程或进程。就算程序被
recv()阻塞,也会占用系统RAM以及进程表中的一个进程槽。当同时运行的线程数量达到几千甚至更多时,操作系统很少能够维持良好的表现。此时系统在切换服务的客户端时需要进行大量上下文切换,这使得服务的运行效率大大降低;
8.4 异步服务器
~~~~~~ 异步服务器:从服务器向客户端发送响应到接收客户端的下一个请求之间有一段时间的间隔,如何在不为每个客户端分配一个操作系统级的控制线程的前提下保证CPU在这段时间内处于繁忙状态呢?可以采用一种异步( asynchronous )模式来编写服务器。使用这种模式的话,代码就不需要等待数据发送至某个特定的客户端或由这个客户端接收。相反,代码可以从整个处于等待的客户端套接字列表中读取数据。只要任何一个客户端做好了进行通信的准备,服务器就可以向该客户端发送响应。
异步(asynchronous):表示服务器代码不会停下等待某个特定的客户端,即控制线程不会以锁步的方式等待任何一个进行会话的客户端,它能在所有连接的客户端中自由切换;
8.5 小结
~~~~~~ 之前的示例网络服务器只能够在同一时刻与一个客户端进行交互,此时其他所有客户端都要进行等待,直到上一个客户端套接字关闭为止。有两种技术可以解决这一问题:
~~~~~~ 从编程的角度来看,最简单的方法就是多线程(或者多进程)。使用多线程时通常可以不加修改地使用单线程服务器程序,操作系统会负责隐式地完成切换,使得等待中的客户端能够快速得到响应,而空闲的客户端则不会消耗服务器的CPU。这一技术不仅允许同时进行多个客户端会话,而且很好地利用了服务器的CPU。而对于原始的单线程服务器,由于其大多数时间都在等待客户端的操作,因此CPU在很多时候都是空闲的。
~~~~~~ 更复杂但是更强大的方法是使用异步编程的风格在单个控制线程中完成对大量客户端的服务切换。这种方法向操作系统提供了当前正在进行会话的完整套接字列表。复杂之处在于需要将读取客户端请求然后构造响应的过程分割为小型的非阻塞代码块,这样就能在等待客户端操作时将控制权交还给异步框架。尽管可以通过select()或poll()这样的机制手动编写异步服务器,不过多数程序员还是会使用一个框架来提供异步功能,比如Python 3.4或更新版本Python标准库中内置的asyncio框架;
~~~~~~ 将编写的服务安装到服务器上,并且在系统启动时运行服务器的过程叫作部署( deployment )。可以使用许多现代机制进行自动化部署,比如使用supervisord这样的工具或是将控制权交给一个平台即服务容器。在一台基本的Linux服务器上可以使用的最简单的部署方法可能就是古老的inetd守护进程了。inetd提供了一种极其简单的方法,能够在客户端需要连接时保证服务处于启动状态。
九、HTTP客户端
9.1 Python客户端库
urllib vs Request:
- Requests一开始就声明其支持gzip和deflate两种压缩格式的HTTP响应,而urllib则不支持;
- Requests能够自己确定正确的解码方式,并将HTTP响应从原始字节转换为文本;而urllib库则只会返回原始字节,用户需要自己进行解码;
9.2 端口、加密与封帧
~~~~~~ 在HTTP中,客户端首先向会服务器发送一个获取文档的请求( request )。一旦发送完整个请求,客户端就会进行等待,直到从服务器接收到完整的响应( response)为止。响应中可能会包含错误信息,也可能会提供客户端请求的文档信息。至少在今天最流行的HTTP/1.1版本的协议中,不允许客户端在尚未收到上一个请求的响应前就在同一个套接字上开始发送第二个请求;
~~~~~~ HTTP中有一种很重要的平衡——请求和响应采取了相同的格式化与封帧规则:
- 在请求消息中,第一行包含一个方法名和要请求的文档名;在响应消息中,第一行包含了返回码和描述信息。无论是在请求还是响应消息中,第一行都以回车和换行(CR-LF,ASCII码13和10)结尾;
- 第二部分包含零个或多个头信息,每个头信息由一个名称、一个冒号以及一个值组成。HTTP头的名称是区分大小写的,因此可以根据客户端或服务器的要求自由使用大写字母。每个头信息由一个CR-LF结尾。在列出了所有的头信息之后再跟上一个空行,空行由CR-LF-CR-LF四个连续字节组成。无论第二部分中是否包含头信息,都必须包含该空行;
- 第三部分是一个可选的消息体。消息体紧跟着头信息后面的空行。我们会简要介绍用于对各实体进行封帧的一些选项。
9.3 路径与主机
~~~~~~ 第一个版本的HTTP允许只在请求中包含方法名和路径;这在互联网早期没有问题,因为当时每台服务器上只会托管一个网站。但是,后来管理员开始希望在大型HTTP服务器上部署几十甚至几百个网站,此时上述做法就行不通了。如果只提供路径的话,服务器要如何猜测用户在URL中输人的是哪个主机名呢?尤其是现在几乎每个网站上都存在/这样的路径;
~~~~~~
解决方法就是至少要强制使用Host头。现代HTTP协议也要求提供协议版本,一个请求至少需要提供下述信息:
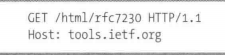
9.4 状态码:
~~~~~~ 标准(特指RFC 7231)制定了二十多个返回码,既覆盖了通用情况,也覆盖了一些特定情况。可以查阅标准文档来获取完整列表。一般来说,200-300的状态码表示成功,300-400表示重定向,400-500表示客户端的请求无法被识别或非法,500~600表示服务器错误导致了一些意外错误:
- 200 OK:请求成功。如果是POST操作的话,表明已经对服务器产生了预期的影响;
- 301 Moved Permanently:尽管路径合法,但是该路径已经不是所请求资源目前的官方路径了(尽管曾经可能是)。客户端若要获取响应,应请求Location头中给出的URL。如果客户端希望将新URL存入缓存,则所有后续的请求都会直接忽略旧URL,直接转向新URL;
- 303 See Other:通过某个路径请求资源时,客户端可以通过使用GET方法对响应信息的Location头中给出的URL进行请求,以获取响应结果,但是对该资源的后续请求仍然需要通过当前请求路径来完成。任何使用POST正确提交的表单都应该返回303状态码,这样就能通过安全、幂等GET方法获取客户端实际看到的页面了;
- 304 Not Modified:不需要在响应中包含文档内容,原因在于请求头指出了客户端已经在缓存中存储了所请求文档的最新版本;
- 400 Bad Request:请求不是一个合法的HTTP请求;
- 404 Not Found:路径没有指向一个已经存在的资源。因为用户在请求成功时只会在屏幕上看到所请求的文档,而不会看到200状态码,所以404可能是最著名的异常码了;
- 500 Server Error:这是另一个熟悉的状态,服务器希望完成请求,但是由于某些内部错误,暂时无法请求;
- 502 Bad Gateway:请求的服务器是一个网关或代理(见第10章),它无法连接到真正为该请求路径提供响应的服务器;
9.5 小结
~~~~~~ HTTP协议用于根据保存资源的主机名和路径来获取资源,标准库的urllib客户端提供了在简单情况下获取资源所需的基本功能。但是,比起Requests,urllib的功能就弱了很多。Requests提供了许多urllib没有的特性,是互联网上最热门的Python库。程序员如果想要从网上获取资源的话,Requests是最佳选择;
~~~~~~ HTTP运行于80端口,通过明文发送。而通过TLS保护的HTTP (HTTPS)则在443端口运行)。客户端的请求和服务器的响应在传输过程中都使用相同的基本结构:首行信息,然后是若干行由名字和值组成的HTTP头信息,最后是一个空行,然后是可选的消息体。消息体可以使用多种不同的方式进行编码和分割。客户端总是先发送请求,然后等待服务器返回响应;
~~~~~~ 最常用的HTTP方法是用于获取资源的GET和用于更新服务器信息的POST,除了GET和POST之外,还有其他方法,不过本质上都与GET或POST类似。服务器在每个响应中都会返回一个状态码,表示请求成功、失败或需要客户端重定向以载入另一个资源;
~~~~~~ HTTP的设计采用了像同心圆一样的分层结构。可以对头信息进行缓存,将资源存储在客户端的缓存中,这样可以重复使用资源,避免不必要的重复获取;这些缓存的头信息也可以避免服务器重复发送没有修改过的资源。这两种优化方法对于繁忙站点的性能都至关重要;
~~~~~~ 内容协商可以保证根据客户端和人类用户的真实偏好来决定返回的数据格式和语言。不过在实际应用中,内容协商会带来一些问题,这使得它没有得到广泛应用。内置的HTTP认证在交互设计上很糟糕,已经被自定义的登录页面和cookie替代。不过,在使用TLS保护的API时,有时还是会使用基本认证。
~~~~~~ HTTP/1.1版的连接在默认情况下是保持打开并且可以复用的,而Requests库也在需要的时候精心提供了这一功能;
十、HTTP服务器
WSGI
~~~~~~ WSGI即Web服务器网关接口:Web server Gateway Interface;
~~~~~~ David Wheeler有一句名言:“计算机科学中的任何问题,都可以通过加上另一层间接的中间层来解决。”而WSGI标准就是添加了一层中间层。通过这一中间层,用Python编写的HTTP服务就能够与任何Web服务器进行交互了。WSGI标准指定了一个调用惯例,如果所有主流的Web服务器的实现都遵循这一惯例,那么就能够直接在服务器中应用底层服务以及功能完整的Web框架,而无需修改原来的代码。各大Web服务器很快就遵循WSGI进行了实现。现在,WSGI已经成为了使用Python进行HTTP操作的标准方法;
异步服务器与框架
前向代理与反向代理
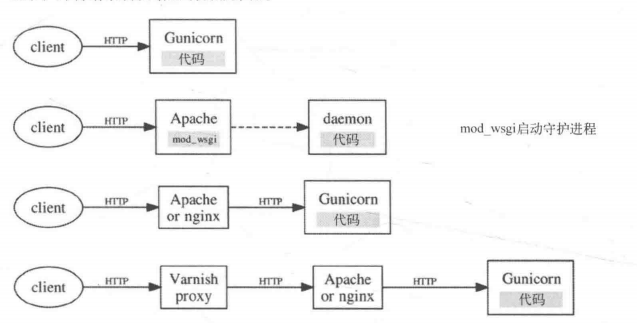
4种架构:
~~~~~~ 单独部署Python代码或将Python代码部署在反向HTTP代理后端的4种常用技术:
平台即服务
PaaS(Platform as a Service)平台即服务: 把服务器平台作为一种服务提供的商业模式,通过网络进行程序提供的服务称之为SaaS(Software as a Service),而云计算时代相应的服务器平台或者开发环境作为服务进行提供就成为了PaaS(Platform as a Service)。
~~~~~~ 有了PaaS以后,构建和运行HTTP服务过程中的许多烦人事儿就自动消失了,或者至少是不用开发者自己来担心了,PaaS提供商会解决这些问题。我们不需要自己去租赁服务器、提供存储设备和IP地址、配置管理和重启服务器所需的root权限,或是安装正确版本的Python。服务器重启或断电之后,我们也不需要使用系统脚本将应用程序复制到所有服务器上,然后自动运行服务;
小结
~~~~~~
Python有一个内置的http.server模块,从命令行启动该服务器时,它可向客户端返回当前工作目录下的文件。尽管在紧急情况下以及所请求的网站直接存储在磁盘上时使用起来很方便,但是该模块现在已经很少用于新型HTTP服务的创建了;
~~~~~~ 在Python中,标准的同步HTTP通常会用到WSGI标准。服务器负责解析收到的请求,然后生成一个保存了所有信息的字典,应用程序从字典中获取信息,然后返回HTTP头以及响应体(如果有的话)。这使得我们能够自由选择Web服务器,来与任意标准的Python Web框架配合使用;
~~~~~~ WSGI生态系统并不支持异步Web服务器。WSGI可调用对象不是完整意义上的协程,因此所有异步HTTP服务器都需要针对使用各自的Web框架所编写的服务采用特定的处理方式。在这种情况下﹐服务器和框架是绑定在一起的,通常不会与其他服务器或框架有更多的互操作性。
~~~~~~ 要使用Python提供HTTP服务,有4种流行的架构:
- 第一种是使用Gunicorn或其他纯Python服务器(如CherryPy )直接运行单独的服务器。其他架构会选择通过mod_wsgi在Apache的控制下运行Python。然而由于反向代理服务器的概念是所有种类Web服务的首选模式,许多架构师发现直接将Gunicorn或其他纯Python服务器部署在nginx或Apache后端更简单。nginx或Apache和纯Python服务器都作为独立的HTTP服务。当请求路径指向动态资源时,nginx或Apache会将请求转发给后端的纯Python服务器;
- 可以在上面所有架构模式的前端部署Varnish或其他反向代理,用于增加一层缓存。缓存实例可以存在于请求机器的同一机房中(甚至是同一台机器上),不过通常会根据其地理位置的分布进行部署,使得各特定的HTTP客户群都有距离较近的缓存实例;
- 可以将服务安装在某个PaaS提供商提供的PaaS服务内。这些PaaS提供商通常提供了缓存、反向代理以及负载均衡的功能。我们的应用程序只需要负责对HTTP请求做出响应(通常使用Gunicorn这样的容器)即可;
- 对于服务,有一个非常流行的问题:它们是否是RESTful的?它们是否满足该标准的提出者RoyFielding博士所提出的特性?Fielding博士提出的这些特性是HTTP设计的基本原则。尽管现在的很多服务都已经不再隐藏所选的方法和路径(这会隐藏服务的真正目的),但还是很少有服务会采用Fielding博士关于将语义置于超媒体而非面向程序员的文档中这一远见。
- 可以将一些小型服务(尤其是对HTTP请求进行过滤或变换的小型服务)编写成WSGI可调用对象。无论是使用WebOb还是Werkzeug,都能够将原始WSGI环境封装到一个便于使用的Request对象中。我们可以从Request对象中获取信息,然后使用Response类来编写并返回响应信息。
十一、万维网
~~~~~~ HTTP是专为万维网设计的。万维网通过超链接将海量文档连接起来,每个超链接都用URL来表示其指向的页面或页面中的某个小节。用户可以直接点击超链接来访问它所指向的页面。Python标准库也提供了用于解析及构造URL的方法。此外,还可以使用标准库提供的功能根据页面的基URL地址将相对URL转化为绝对URL;
~~~~~~ Web应用程序通常会在对HTTP请求进行响应的服务器程序中连接持久化的数据存储(如数据库),然后构造作为响应信息的HTML。在这一过程中有一点是十分重要的,即应该使用数据库本身提供的功能来引用由Web外部传递来的不可信信息;
~~~~~~ Web框架各不相同,有的只提供最简单的功能,有的则提供了全栈式服务。如果使用简单的Web框架,就需要自己选择模板语言、ORM或其他持久层方案。而全栈式的框架则内置了工具来提供这些功能。无论选择哪种框架,都可以在自己的代码中支持静态URL及/person/123/这样包含可变组件的URL。这些框架同样会提供生成与返回模板的方法,以及返回重定向信息或HTTP错误的功能;
~~~~~~ 每个网站编写者都会遇到一个大麻烦:在像Web这样一个复杂的系统中,组件之间的交互可能会使得用户违背了自己的操作本意,或者允许用户损害他人的利益。在代码中涉及与外部网络的接口时,一定要考虑跨站脚本攻击、跨站请求伪造以及对用户隐私攻击的可能性。在编写会从URL路径、URL查询字符串、POST请求或文件上传等途径接收数据的代码之前,一定要彻底理解这些安全威胁;
~~~~~~ 我们通常会在全栈式的框架以及轻量级的框架之间进行权衡。像Django这样的全栈式解决方案鼓励用户全部使用它所提供的工具,而且它会为用户提供一个很不错的默认配置(比如自动提供表单的CSRF保护);而Flask或Bottle这样的轻量级框架则要求我们自己选择其他工具,相互结合,形成最终的解决方案。此时我们就需要理解所有用到的组件。例如,如果选择使用Flask来开发应用程序,但是却不知道要提供CSRF保护,那么最后开发出的应用程序就无法抵御CSRF攻击了;
~~~~~~ Tornado框架因其提供的异步方法而与别的框架有所不同。Tornado允许在同一个操作系统级的线程内为多个客户端提供服务。随着Python 3中asyncio的出现,类似于Tornado的方法会渐渐变得越来越通用。这和如今WSGI为多线程Web框架提供的支持是类似的。
~~~~~~ 要抓取一个Web页面,就需要对网站的工作原理有透彻的理解,这样才能在脚本中模拟正常的用户交互——包括登录、填写以及提交表单这些复杂操作。在Python中,有很多方法可以用来获取和解析页面。目前,Requests和Selenium是最流行的用来获取页面的库,而Beautiful Soup和Ixml则是人们解析页面时最喜欢使用的方案。
十二、SMTP
简单邮件传输协议:(Simple Mail Transport Protocol,SMTP)
- (1)当用户在笔记本电脑或台式机上输入电子邮件消息时,电子邮件客户端会使用SMTP将用户输入的电子邮件提交至服务器,由该服务器负责将电子邮件发送至接收服务器。
- (2)电子邮件服务器使用SMTP来传输消息,每条消息中途都会经过互联网上的多台邮件服务器,直到到达负责接收电子邮件地址域(domain,指电子邮件地址中在@符号后面的部分)的服务器为止;
~~~~~~
SMTP用于将电子邮件消息发送至电子邮件服务器。Python的smtplib模块提供了SMTP客户端供开发者使用。可以通过调用SMTP对象的sendmail()方法来传输消息。指定消息真正接收者的唯一方法就是将接收者作为参数提供给sendmail(),To、Cc和Bcc这些消息文本中的消息头与真正的接收者是无关的;
~~~~~~
在SMTP会话中可能会抛出多个不同的异常。交互式的程序应该正确地检查并处理这些异常。ESMTP是SMTP的扩展。通过ESMTP,可以在传输消息前获取远程服务器所能支持的消息大小的最大值。
~~~~~~
在使用ESMTP时,也可以通过TLS来加密与远程服务器的会话;有些SMTP服务器要求进行认证。可以使用login()方法来进行认证。SMTP并没有提供能够将收件箱中的消息下载到本地的函数;
十三、POP
POP( Post Office Protocol,邮局协议):是一个用于从服务器下载电子邮件的简单协议
~~~~~~ POP最大的优点就在于它的简单,而这同样也是它最大的缺点。如果只需要从一个远程邮箱中读取并下载电子邮件,然后在下载完成后选择性地删除电子邮件,那么POP就是最佳选择。我们可以使用POP快速地解决这个问题,而无需编写复杂的代码;
~~~~~~ POP提供了一种将存储在远程服务器上的电子邮件消息下载下来的简单方法。可以通过Python的poplib库来获取邮箱中的消息编号及大小,并可以通过消息编号来获取或删除消息。
~~~~~~ 连接POP服务器可能会锁死邮箱。因此,一定要让POP会话尽量简短,并且始终在POP会话结束时调用quit()。
~~~~~~ 在使用POP时,要尽量使用SSL来保护密码和电子邮件消息的内容。如果不使用SSL的话,至少要使用APOP。只有在特别需要使用POP而又不需要使用高级选项时,才可以使用明文发送密码。
~~~~~~ 尽管POP是一种简单而又广为流行的协议,但是它存在着很多缺点,这使得其对于某些应用程序来说显得并不适用。例如,POP只支持访问一个文件夹,并且不提供对单个消息的持久跟踪功能;
十四、IMAP
IMAP消息访问协议是比POP更强大的协议:
- 可以对邮件进行分类,并将其存入多个文件夹中,而无需将所有邮件都置于单个收件箱中。
- 支持对每条消息进行标记,如“已读”“已回复”和“已删除”。
- 可以直接在服务器上对消息进行文本字符串搜索,无需事先下载消息。
- 可以直接将存储在本地的消息上传至某一远程文件夹。
- 维护了持久化的唯一消息编号,为本地与服务器之间的可靠消息同步提供了支持。
- 可以将文件夹与其他用户共享,也可以将文件夹标记为只读。
- 有些IMAP服务器可以在电子邮件文件夹中显示非邮件源,比如Usenet新闻组。
- IMAP客户端可以选择性地下载消息的某一部分,比如可以抽取特定的某个附件或是只下载消息头,而无需等待消息剩余部分下载完成。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号