降维之主成分分析法(PCA)
这篇博客整理主成分分析法(PCA)相关的内容,包括:
1、主成分分析法的思想
2、主成分的选择
3、主成分矩阵的求解
4、主成分的方差贡献率和累计方差贡献率
5、基于投影方差最大化的数学推导
一、主成分分析法的思想
我们在研究某些问题时,需要处理带有很多变量的数据,比如研究房价的影响因素,需要考虑的变量有物价水平、土地价格、利率、就业率、城市化率等。变量和数据很多,但是可能存在噪音和冗余,因为这些变量中有些是相关的,那么就可以从相关的变量中选择一个,或者将几个变量综合为一个变量,作为代表。用少数变量来代表所有的变量,用来解释所要研究的问题,就能从化繁为简,抓住关键,这也就是降维的思想。
主成分分析法(Principal Component Analysis,PCA)就是一种运用线性代数的知识来进行数据降维的方法,它将多个变量转换为少数几个不相关的综合变量来比较全面地反映整个数据集。这是因为数据集中的原始变量之间存在一定的相关关系,可用较少的综合变量来综合各原始变量之间的信息。这些综合变量称为主成分,各主成分之间彼此不相关,即所代表的的信息不重叠。
那么主成分分析法是如何降维的呢?我们从坐标变换的角度来获得一个感性的认识。
我们先从最简单的情形开始,假定数据集中的原始变量只有两个,即数据是二维的,每个观测值都用标准的X-y坐标轴来表示。如果每一个维度都服从正态分布(这比较常见),那么这些数据就会形成椭圆形状的点阵。如下图所示,椭圆有一个长轴和一个短轴,二者是垂直的。
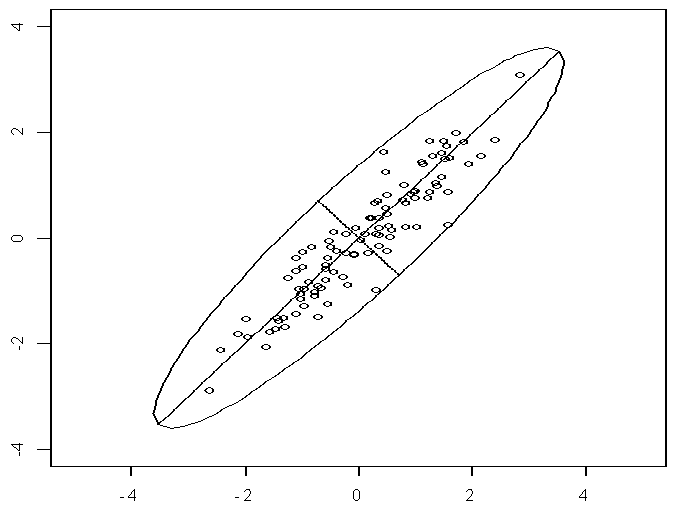
在短轴上,观测点数据的变化比较小,如果把这些点垂直地投影到短轴上,那么有很多点的投影会重合,这相当于很多数据点的信息都没有被充分利用到;而在长轴上,观测点的数据变化比较大。因此,如果坐标轴和椭圆的长短轴平行,那么代表长轴的变量直接可以从数据集的原始变量中找到,它描述了数据的主要变化,而另一个原始变量就代表短轴的变量,描述的是数据的次要变化。在极端情况下,短轴退化成一个点,那么就只能用长轴的变量来解释数据点的所有变化,就可以把二维数据降至一维。
但是,坐标轴通常并不和椭圆的长短轴平行,就像上图所展示的那样。因此,需要构建新的坐标系,使得新坐标系的坐标轴与椭圆的长短轴重合或平行。这需要用到坐标变换,把观测点在原坐标轴的坐标转换到新坐标系下,同时也把原始变量转换为了长轴的变量和短轴的变量,这种转换是通过对原始变量进行线性组合的方式而完成的。
比如一个观测点在原X-y坐标系中的坐标为(4,5),坐标基为(1,0)和(0,1),如果长轴为斜率是1的线,短轴为斜率是-1的线,新坐标系以长轴和短轴作为坐标轴,那么新坐标基可以取为(1/√2, 1/√2)和(-1/√2, 1/√2)。我们把两个坐标基按行放置,作为变换矩阵,乘以原坐标,也就是对原坐标进行线性组合,可以得到该点在新坐标系下的坐标。可以看到变换后长轴变量的值远大于短轴变量的值。
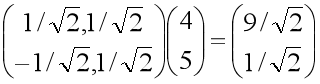
如果长轴变量解释了数据集中的大部分变化,那么就可以用长轴变量来代表原来的两个变量,从而把二维数据降至一维。椭圆的长轴和短轴的长度相差越大,这种做法的效果也就越好。
接着我们把二维变量推广到多维变量,具有多维变量的数据集其观测点的形状类似于一个高维椭球,同样的,把高维椭球的轴都找出来,再把代表数据大部分信息的k个最长的轴作为新变量(相互垂直),也就是k个主成分,那么主成分分析就完成了。
选择的主成分越少,越能体现降维二字的内涵,可是不可避免会舍弃越多的信息。因此以什么标准来决定我们应该选几个主成分呢?
二、主成分的选择问题
到这里,我们应该有三个问题需要思考:一是进行坐标变换的矩阵是怎么得到的呢?二是用什么指标来衡量一个主成分所能解释的数据变化的大小?三是以什么标准来决定选多少个主成分呢?
首先来解决第二和第三个问题。
假定我们有m个观测值,每个观测值有n个特征(变量),那么将其按列排成n行m列的矩阵,并且每一行都减去该行的均值,得到矩阵X(减去均值是为了下面方便求方差和协方差)。并按行把X整理成n个行向量的形式,即用X1, X2, ..., Xn来表示n个原始变量。
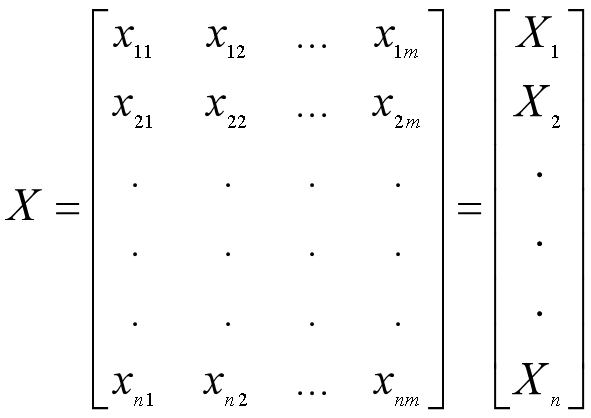
第一部分的例子说明了通过一个n×n的转换矩阵对数据集中的原始变量进行线性组合,就可以得到n个新的变量。转换矩阵可以有很多个,也就是变换的坐标系有很多个,但是只有一个可以由原始变量得到主成分。我们先不管这个独特的矩阵是怎么得到的,假定我们已经得到了这个转换矩阵P,那么把转换后的n个主成分记为Y1, Y2, ..., Yn,那么由Y=PX,就可以得到主成分矩阵:

这n个行向量都是主成分,彼此之间是线性无关的,按照对数据变化解释力的强度降序排列(并非被挑出来的前k个行向量才叫做主成分)。
那么如何衡量每一个主成分所能解释的数据变化的大小呢?
我们先看n=2时,主成分为Y1和Y2,原变量为X1和X2。从下图可见Y1为长轴变量,数据沿着这条轴的分布比较分散,数据的变化比较大,因此可以用Y1作为第一主成分来替代X1和X2。那用什么指标来量化数据的变化和分散程度呢?用方差!
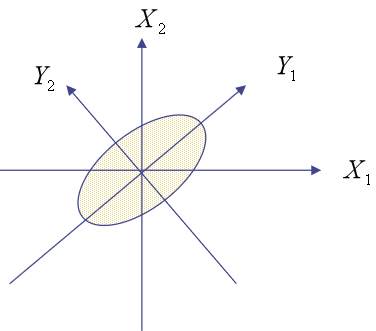
我们把向量X1和X2的元素记为x1t、x2t(t=1,2,...,m),把主成分Y1和Y2的元素记为y1t、y2t(t=1,2,...,m),那么整个数据集上的方差可以如下表示(数据早已经减去均值,所以行向量的均值为0)。
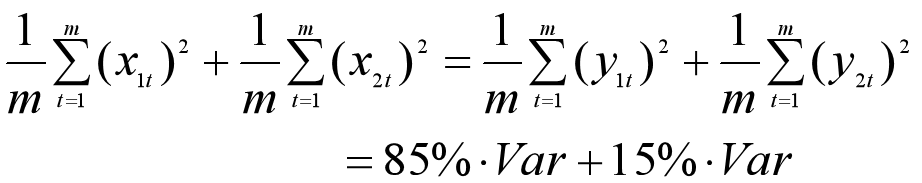
第一主成分Y1所能解释的数据的变化,可以用主成分的方差来衡量,也就是:

也可以用主成分的方差占总体方差的比重来衡量,这里假设为85%,这个比例越大,则反映的信息越多。
我们回到有n个原始变量和n个主成分的例子,那么选择合适的转换矩阵P来计算得到主成分矩阵Y时,要让单个主成分在数据集上的方差尽可能大。那么选择主成分的第一个一般标准是少数k个主成分(1≤k<n)的方差占数据集总体方差的比例超过85%。
于是我们初步解决了第二个问题和第三个问题,也就是如果已知转换矩阵P和主成分矩阵Y,那么就用一个主成分的方差占数据集总体方差的比例,来衡量该主成分能解释的数据集方差的大小,然后按这个比例从大到小进行排序,并进行累加,如果到第k个主成分时,累加的比例恰好等于或者超过85%,那么就选择这k个主成分作为新变量,对数据集进行降维。
接下来问题倒回至第一个问题,也就是求解第二个问题和第三个问题的前提:转换矩阵P怎么算出来?
三、求解转换矩阵和主成分矩阵
前面我们说了主成分矩阵Y的一个特点是,单个主成分向量Yi的方差占总体方差的比例尽可能大,而且按照方差占比的大小,对所有的主成分进行降序排列。另外还有一个特性是所有的主成分都是线性无关的,或者说是正交的,那么所有主成分中,任意两个主成分Yi和Yj的协方差都是0。
第一个特点涉及到主成分的方差,第二个特点涉及到主成分之间的协方差,这自然而然让我们想到协方差矩阵的概念,因为主成分矩阵Y的协方差矩阵的对角元素,就是每个主成分的方差,而非对角元素就是协方差。由于协方差为0,那么主成分矩阵的协方差矩阵为一个对角矩阵,且对角元素是降序排列的!
由于数据集已经减去了均值,那么同样,主成分矩阵中的行向量也是0均值的,于是某两个主成分的协方差为;
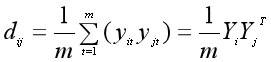
进一步得到主成分矩阵Y的协方差矩阵为:
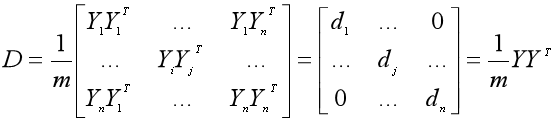
那知道了主成分矩阵Y的协方差矩阵是对角矩阵,对于我们求出转换矩阵P和主成分矩阵有什么用呢?
有的,我们把Y=PX这个等式代入协方差矩阵中进行变换,就把已知的数据X和需要求的P都放到了协方差矩阵中:
![]()
比较神奇的是,主成分矩阵Y的协方差矩阵可以由数据集X的协方差矩阵![]() 得到。
得到。
数据集X的协方差矩阵显然是一个实对称矩阵,实对称矩阵有一系列好用的性质:
1、n阶实对称矩阵A必然可以对角化,而且相似对角阵的对角元素都是矩阵的特征值;
2、n阶实对称矩阵A的不同特征值对应的特征向量是正交的(必然线性无关);
3、n阶实对称矩阵A的某一特征值λk如果是k重特征根,那么必有k个线性无关的特征向量与之对应。
因此数据集X的协方差矩阵![]() 作为n阶实对称矩阵,一定可以找到n个单位正交特征向量将其相似对角化。设这n个单位特征向量为e1, e2, ..., en,并按列组成一个矩阵:
作为n阶实对称矩阵,一定可以找到n个单位正交特征向量将其相似对角化。设这n个单位特征向量为e1, e2, ..., en,并按列组成一个矩阵:
![]()
那么数据集X的协方差矩阵可以对角化为:
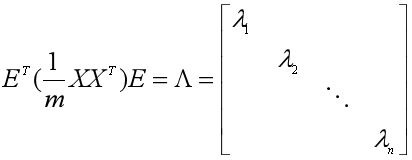
相似对角阵上的元素λ1、λ2、... 、λn是协方差矩阵的特征值(可能存在多重特征值),E中对应位置的列向量是特征值对应的单位特征向量。
接下来是高能时刻。我们把这个对角阵Λ上的元素从大到小降序排列,相应的把单位特征向量矩阵E里的特征向量也进行排列。我们假设上面已经是排列好之后的形式了,那么由于主成分矩阵的协方差矩阵也是元素从大到小降序排列的对角矩阵,那么就可以得到:

也就是取X的协方差矩阵的单位特征向量矩阵E,用它的转置ET来作为转换矩阵P,而X的协方差矩阵的特征值λ就是各主成分的方差!有了转换矩阵P,那么由PX我们自然就可以得到主成分矩阵Y。如果我们想把数据从n维降至k维,那么从P中挑出前k个行向量,去乘以数据集X就行,就可以得到前k个主成分。
至此第一个问题,也就是转换矩阵P和主成分矩阵的求解就可以完成了。
四、主成分的方差贡献率和累计方差贡献率
我们来拆细了看各主成分是怎么得到的。主成分可以由协方差矩阵的单位特征向量和原始变量进行线性组合得到。
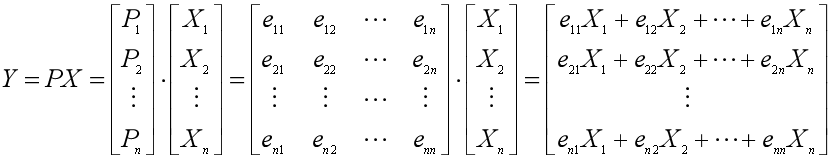
P1就是由,X的协方差矩阵最大特征根λ1的单位特征向量e1转置而成(列向量变为行向量),于是第一主成分就是:
![]()
第一主成分的方差是最大的。然后第二主成分满足:(1)和第一主成分正交,(2)在剩余的其他主成分中,方差最大,表达式为:
![]()
同理,第k个主成分的表达式为:
![]()
我们知道用主成分的方差来衡量其所能解释的数据集的方差,而主成分的方差就是X的协方差矩阵的特征值λ,所以第k个主成分的方差就是λk。我们来定义一个指标,叫做主成分Yk的方差贡献率,它是第k个主成分的方差占总方差的比例:
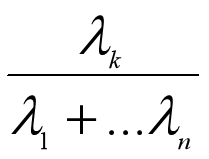
那么前k个主成分的方差累计贡献率为:
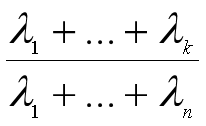
如果前k个主成分的方差累计贡献率超过了85%,那么说明用前k个主成分去代替原来的n个变量后,不能解释的方差不足15%,没有损失太多信息,于是我们可以把n个变量减少为k个变量,达到降维的目的。
五、主成分分析法的流程总结
我们为了推导出主成分分析法的线性代数解法,铺垫了很多,但推导出的结果却是相当简洁漂亮。现在我们省略中间的过程,看主成分分析法的计算流程。
假设我们拿到了一份数据集,有m个样本,每个样本由n个特征(变量)来描述,那么我们可以按照以下的步骤进行降维:
1、将数据集中的每个样本作为列向量,按列排列构成一个n行m列的矩阵;
2、将矩阵的每一个行向量(每个变量)都减去该行向量的均值,从而使得新行向量的均值为0,得到新的数据集矩阵X;
3、求X的协方差矩阵![]() ,并求出协方差矩阵的特征值λ和单位特征向量e;
,并求出协方差矩阵的特征值λ和单位特征向量e;
4、按照特征值从大到小的顺序,将单位特征向量排列成矩阵,得到转换矩阵P,并按PX计算出主成分矩阵;
5、用特征值计算方差贡献率和方差累计贡献率,取方差累计贡献率超过85%的前k个主成分,或者想降至特定的k维,直接取前k个主成分。
六、主成分分析法计算的案例
为了更好地掌握主成分分析法的计算过程,我们来看一个例子。
假设我们想研究上海、北京房地产指数与其他价格指数之间的关系,设定了4个变量,如下表所示。
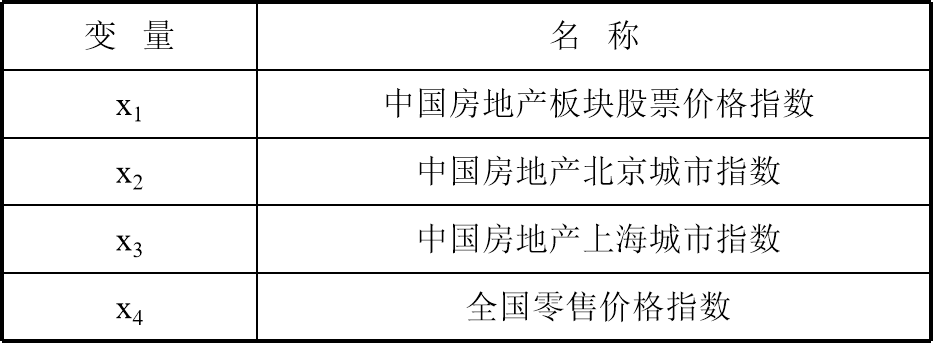
样本数据取自1997年1月~2000年6月的统计资料,时间跨度为42个月,因此样本容量为m=42,为了简单起见,数据就不展示了。
第一步:计算数据集的协方差矩阵
将每个样本作为列向量构成一个矩阵,并对矩阵的每一个行向量进行0均值化,得到了4行42列的数据集矩阵X。我们直接由X得到其协方差矩阵:

第二步:计算协方差矩阵的特征值和单位特征向量
我们用numpy来计算,代码如下:
import numpy as np from numpy import linalg # 协方差矩阵 C = [[1,-0.339,0.444,0.525], [-0.339,1,0.076,-0.374], [0.444,0.076,1,0.853], [0.525,-0.374,0.853,1]] # 计算特征值和特征向量 value,vector = linalg.eig(C) print('特征值为:',np.round(value,4),'\n') for i in range(4): print('特征值',np.round(value[i],4),'对应的特征向量为:\n',np.round(vector[:,i].T,4),'\n') # 求每一列的L2范数,如果都是1,则已经单位化了。 print('特征向量已经是单位特征向量了:',linalg.norm(vector,ord=2,axis=0))
特征值为: [2.3326 1.0899 0.5399 0.0376] 特征值 2.3326 对应的特征向量为: [ 0.4947 -0.2687 0.5464 0.6201] 特征值 1.0899 对应的特征向量为: [-0.2019 0.8378 0.5004 0.0832] 特征值 0.5399 对应的特征向量为: [-0.844 -0.3399 0.1652 0.3805] 特征值 0.0376 对应的特征向量为: [ 0.0458 0.3322 -0.651 0.681 ] 特征向量已经是单位特征向量了: [1. 1. 1. 1.]
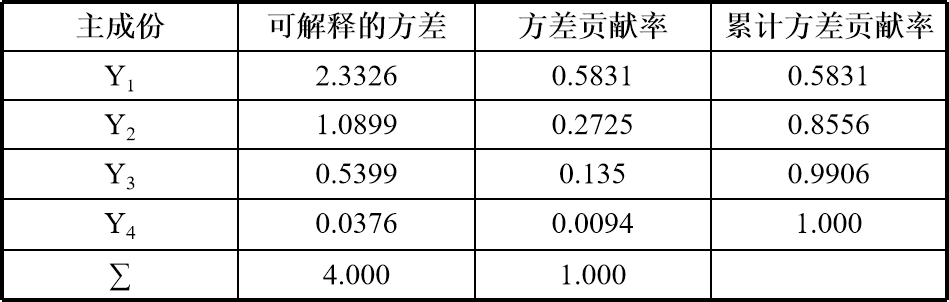
得到特征值是λ1=2.3326 ,λ2=1.0899 ,λ3=0.5399 ,λ4=0.0376,已经是从大到小排列好的了。而且特征向量已经是单位特征向量了。

第三步:得到转换矩阵P和主成分矩阵Y
我们得到第一个主成分如下,也就是用最大特征值的特征向量对原始变量进行线性组合。
![]()
其他三个主成分同样可以得到。
第四步:计算主成分的方差贡献率和累计方差贡献率,选择k个主成分
有了协方差矩阵的特征值,计算就非常简单了。
# 方差贡献率 contrib_rate = value/sum(value) print('方差贡献率为:',np.round(contrib_rate,4)) # 累计方差贡献率 cum_contrib_rate = np.cumsum(contrib_rate) print('\n累计方差贡献率为:',np.round(cum_contrib_rate,4))
方差贡献率为: [0.5831 0.2725 0.135 0.0094]
累计方差贡献率为: [0.5831 0.8556 0.9906 1. ]
得到的结果整理如下。可以看到第一主成分Y1和第二主成分Y2的累积方差贡献率已经达到了85.56%,可以认为用来代替4个原始变量,也不会造成太多信息损失。
七、基于投影方差最大化的数学推导
不要不耐烦,数学还是很有意思的,哈哈。我们下面用其他的方法来推导转换矩阵和主成分的计算公式,可以把主成分的求解问题转换为一个约束条件下的求最大值的问题。
假设数据集X有m个样本,每个样本是一个n维的列向量,我们把X整理成n行m列的矩阵:X=(X1, X2,..., Xn)T,且已经对行向量进行了0均值化。现在我们希望用主成分分析法将n维变量降至k维。首先进行坐标变换,经过坐标变换后的新坐标系为W={w1, w2, ..., wn},其中wi是标准正交基,WTW是单位向量。如果第一主成分Y1的方向就是w1这条坐标轴的方向,那么样本投影到w1上之后会被广泛散布,使得样本之间的差别变得特别明显,也就是投影的方差最大。
设数据集X在w1上的投影为z1=w1TX,那么问题就成了希望在w1的L2范数平方为1的约束条件下,寻找向量w1,使得投影的方差最大化。记数据集X的协方差矩阵为Cov(X)=Σ,则投影方差最大化问题为:
![]()
写成拉格朗日问题:
![]()
对w1求导并令其为0,得到如下表达式。Σ是数据集X的协方差矩阵,所以w1可以看做是协方差矩阵的一个特征值λ的特征向量。
![]()
对于以上的式子,等式左右两边都左乘一个w1T,得到数据集X在w1上投影的方差,也就是特征值λ。由于w1是第一主成分Y1所在的坐标轴,那么由方差最大得到λ是最大的特征值。
![]()
第一主成分怎么求出来呢?很简单,Y1=w1TX(这里的w1是特指方差最大化的解)就是了。
求出了第一主成分,我们可以再求第二主成分。假设第二主成分Y2在新坐标轴w2的方向上,那么Y2应该是剩余的主成分中,使数据集在w2上投影的方差最大的那个。
数据集X在w2上的投影为z2=w2TX,除了满足w2的L2范数平方为1的条件外,还需要满足w2Tw1=0,其中w1是我们已经求出来的。于是投影方差最大化问题写成拉格朗日的格式为:
![]()
对w2求导,经过一系列的推导,我们最终可以得到Σw2=λw2。
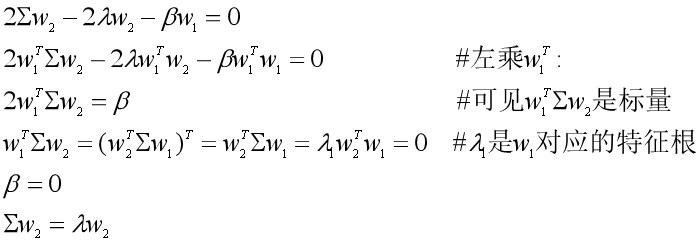
那么w2可以看做是协方差矩阵Σ的特征向量,对应的特征值为第二大特征值λ2,第二主成分Y2=w2TX。
类似的,其他主成分所在的坐标轴的标准正交基wi是依次递减的特征值所对应的单位特征向量。
参考资料
1、《PCA数学原理》:http://www.360doc.com/content/13/1124/02/9482_331688889.shtml

 浙公网安备 33010602011771号
浙公网安备 33010602011771号