循环神经网络之LSTM和GRU
看了一些LSTM的博客,都推荐看colah写的博客《Understanding LSTM Networks》 来学习LSTM,我也找来看了,写得还是比较好懂的,它把LSTM的工作流程从输入到输出整个撸了一遍,清晰地展示了整个流程,不足之处就是那个语言模型的例子不知道到底在表达什么。
But!
我觉得邱锡鹏老师的书写得更好!我又要开始推荐这本免费的书了:《神经网络与深度学习》。这本书第六章循环神经网络的LSTM部分,阐述了为什么要引入门控机制、LSTM的工作流程、LSTM的数学表达式、LSTM它为什么就叫这个名儿以及其他变体,数学公式和图都清晰明了,全是干货。粉丝在视频上看到自己的爱豆会想舔屏,我看这本书的时候想舔书。这本书比那本被吹上天的花书也好太多!真是低调的实力派,强推!
决定按照邱锡鹏老师的书来整理这部分知识点。
一、为什么要在循环神经网络中引入门控机制?
引入门控机制是为了缓解循环神经网络中的长期依赖问题。
回顾一下,如果t时刻的预测yt依赖于t-k时刻的输入xt-k,当时间间隔k比较大时,容易出现梯度消失或梯度爆炸的问题,那么循环神经网络就难以学习到如此久远的输入信息。在这种情况下,当目前的预测又需要用到比较久远的信息时,就会出现长期依赖问题。
但是如果我们为了学习到非常久远的信息,而把所有过去时刻输入的信息都存储起来的话,会造成隐状态h上存储信息的饱和与重要信息的丢失。为此,一种比较好的方案是引入门控机制来控制信息的累积速度,包括有选择的加入新信息,并有选择地遗忘之前积累的信息。这一类网络称为基于门控的循环神经网络(Gated RNN)。比较经典的基于门控的循环神经网络有长短期记忆网络(LSTM)和门控循环单元网络(GRU)。
二、长短期记忆网络(LSTM)
(一)LSTM的网络结构
在标准的RNN模型中,第t时刻的隐状态输出ht是由如下公式计算得到的:
![]()
U、W、b是神经网络的参数,f(•)是非线性的激活函数,假设为Tanh函数。这一切计算是在一个隐藏层中完成的,这个隐藏层里就是用Tanh层做了非线性变换,如下图所示:
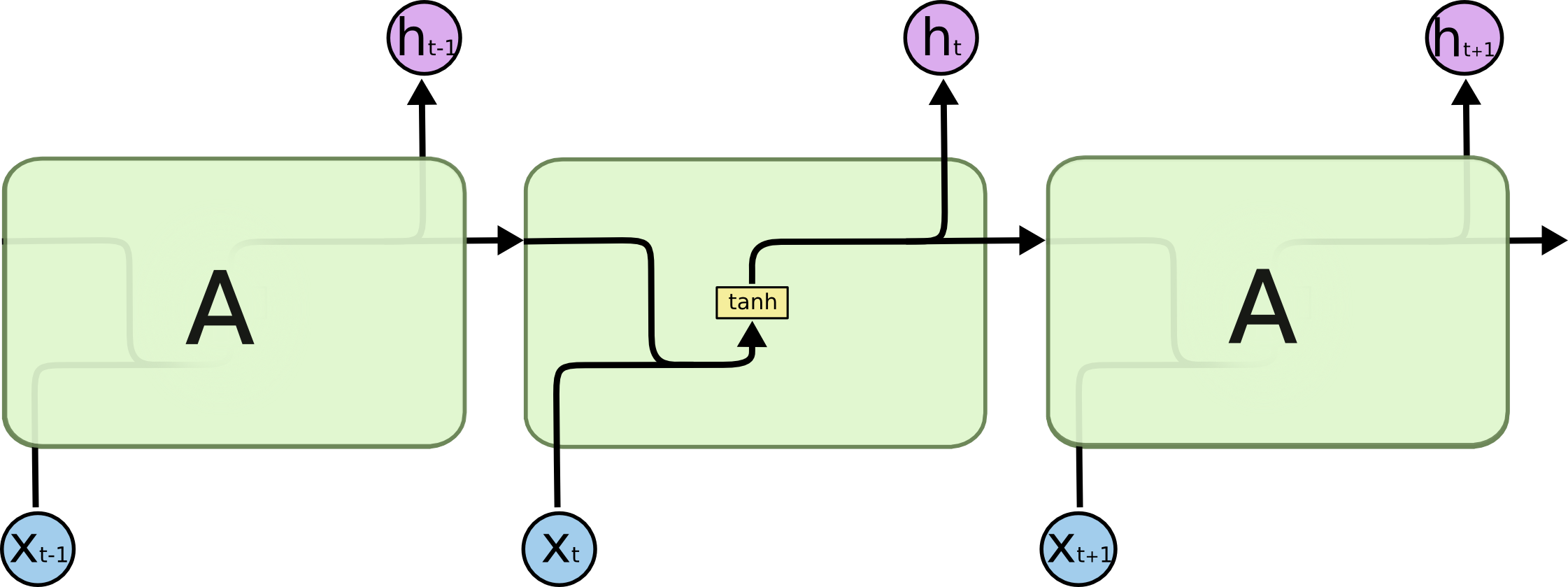
那么,在LSTM中,就是对这个隐藏层A进行了精心设计,添加了除Tanh层以外的东西,来避免长期依赖问题,如下图所示:
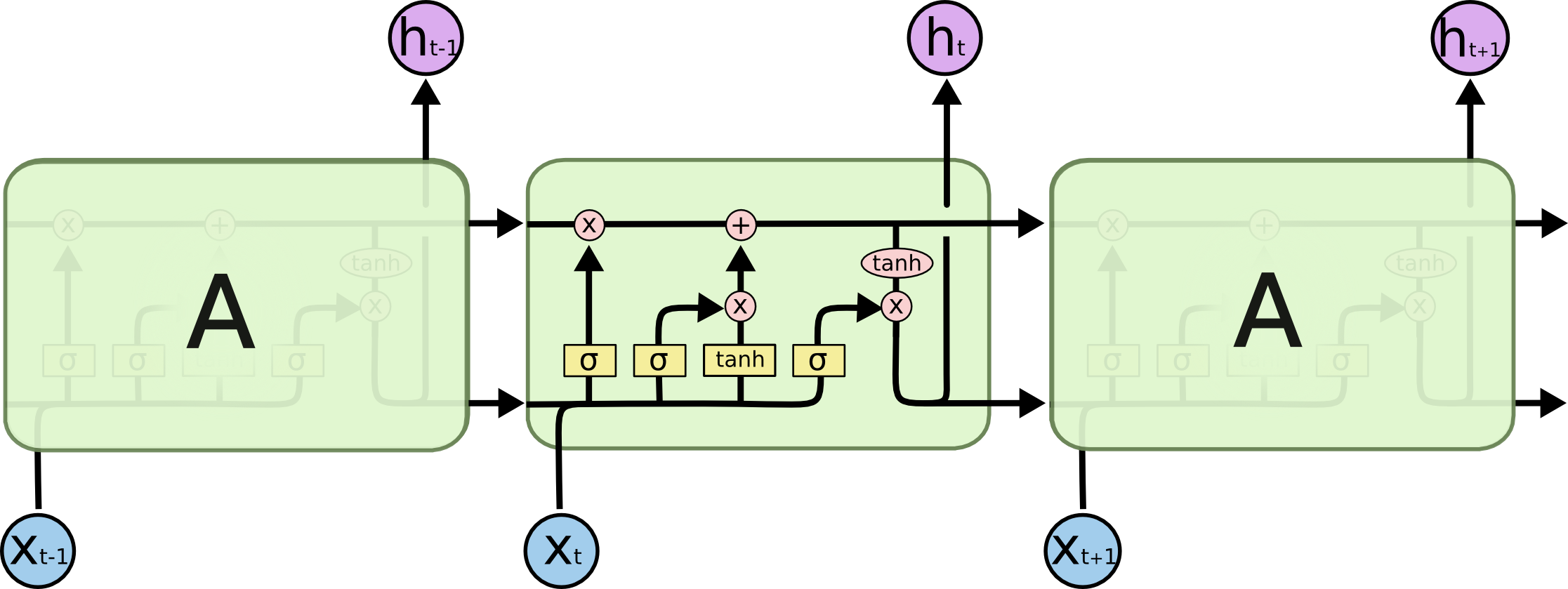
好,那接下来看,LSTM在这个隐藏层中到底添加了什么东西,做了哪些改进。
(二)LSTM的网络改进
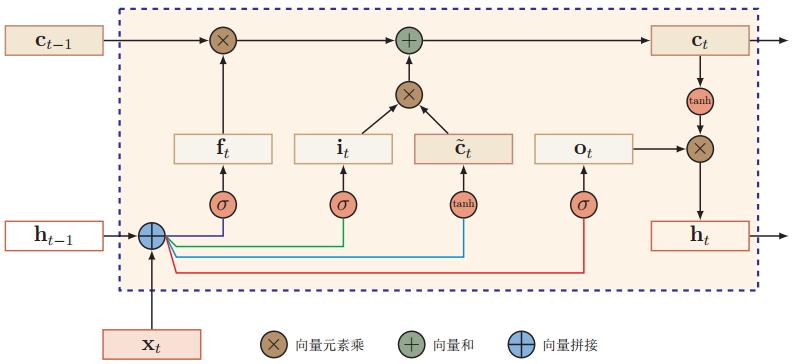
相对于传统的RNN,LSTM的网络结构有两个改进:1是加入了新的内部状态,2是引入了门机制。下面将用这个图来解释LSTM的运作流程,ct就表示当前的内部状态,三个σ(•)则表示三种门。
1、新的内部状态
LSTM网络引入了一个新的内部状态ct,一方面进行线性的循环信息传递,比如图中的ct-1从左往右传递的过程,另一方面非线性地输出信息给隐藏层的外部状态ht ,比如图中ct从上往下的传递过程。这个内部状态ct的作用就是记录到当前时刻t为止所有的历史信息。传递的过程中会进行哪些计算,这里暂且按下不表。
2、门机制
LSTM网络引入门机制来控制信息传递的路径,一共有三个门:遗忘门ft,输入门it,输出门ot。LSTM网络中的门不是一个二值变量(即只能取0或1),而是取值在(0,1)之间的“软门”,表示以一定的比例让信息通过。
- 三个门的作用为

当ft=0,it=1时,包含历史信息的内部状态ct-1被丢弃,历史信息被清空,此时的内部状态ct只记录了t-1时刻的信息,也就是候选状
态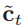 经过输入 门it控制后留下的信息。
经过输入 门it控制后留下的信息。
当ft=1,it=0时,内部状态ct只复制了前一个内部状态ct-1中的历史信息,而不写入由xt带来的新信息。
当然这三个门是不会取到0或1这种极端值的。
- 三个门的计算公式如下
每个门都选择sigmoid激活函数σ(•),输出区间为(0,1),xt为当前时刻的输出,ht-1为上一时刻的外部状态。W*,U*,b*表示三个
门(三个神经层)中待学习的参数,*∈{i, f, o}。

(三)LSTM网络的时间循环单元结构的计算过程
1、首先利用上一时刻的外部状态ht-1和当前时刻的输入xt,计算出三个门;
2、然后利用上一时刻的外部状态ht-1和当前时刻的输入xt,计算出候选状态:
![]()
3、结合遗忘门ft、输入门it、上一时刻的内部状态ct-1和候选状态,计算当前的内部状态ct:
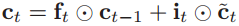
4、把当前内部状态ct扔进tanh激活函数中,结合输出门ot,将内部状态的信息传递给外部状态ht。

再次对照下面这个图,结合上面这四个步骤,那么LSTM网络的计算过程就比较清楚了。外部状态ht最终以两条路径进行下一步传递:一条路径是跳出了这个框,从下往上输出给了另一隐藏层或者输出层;另一条路径是按时间循环,传递给了下一时刻,用来计算ht+1。下面这个图只表示了第2条路径。
通过LSTM的内部状态记录所有时刻的历史信息,整个网络就可以建立较长距离的时序依赖关系。
以上的工作流程可以用简洁的公式概括为:
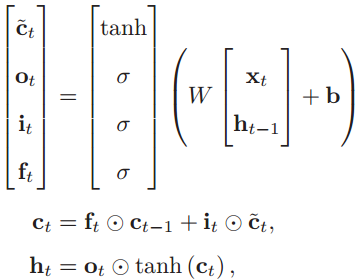
(四)什么是长短期记忆?
在循环神经网络中,记忆能力分为短期记忆、长期记忆和长短期记忆。
1、短期记忆
短期记忆指简单循环神经网络中的隐状态h。因为隐状态h存储了历史信息,但是隐状态每个时刻都会被重写,因此可以看做是一种短期记忆(short-term memory)。
2、长期记忆
长期记忆指神经网络学习到的网络参数。因为网络参数一般是在所有“前向”和“后向”计算都完成后,才进行更新,隐含了从所有训练数据中学习到的经验,并且更新周期要远远慢于短期记忆,所以看做是长期记忆(long-term memory)。
3、长短期记忆
在LSTM网络中,由于遗忘门的存在,如果选择遗忘大部分历史信息,则内部状态c保存的信息偏于短期,而如果选择只遗忘少部分历史信息,那么内部状态偏于保存更久远的信息,所以内部状态c中保存信息的历史周期要长于短期记忆h,又短于长期记忆(网络参数),因此称为长短期记忆(long short-term memory)。
三、LSTM的变体:GRU
对LSTM的门机制进行改进可以得到多种变体,而GRU(Gated Recurrent Unit,门控循环单元网络)就是其中一种比LSTM网络更简单的循环神经网络。
GRU网络对LSTM网络的改进有两个方面:
1、将遗忘门和输入门合并为一个门:更新门,此外另一门叫做重置门。
2、不引入额外的内部状态c,直接在当前状态ht和历史状态ht-1之间引入线性依赖关系。
GRU网络的结构如下图所示,第一眼看上去感觉好复杂啊,哪里简单了,比LSTM复杂多了。

好,那接下来按输入数据xt和历史状态ht-1在GRU网络中流动的过程,来阐述GRU网络的工作流程。
1、计算重置门rt和候选状态
重置门rt用来控制候选状态![]() 的计算是否依赖于上一时刻的状态ht-1。
的计算是否依赖于上一时刻的状态ht-1。
![]()
当前时刻的候选状态为:
![]()
2、计算更新门zt和当前状态ht
更新门zt用来控制当前状态ht需要从历史状态ht-1中保留多少信息,以及需要从候选状态![]() 中接收多少新信息。
中接收多少新信息。
![]()
然后计算出隐状态ht:
![]()
可以看到,当zt=0,rt=1时,隐状态ht为简单循环神经网络中的计算公式,GRU网络退化为简单循环神经网络。
![]()
此外,把求隐状态ht的公式整理如下,可以看到当前状态ht和历史状态ht-1之间存在线性关系,也存在非线性关系,在一定程度上可以缓解梯度消失问题。
![]()
参考资料:
1、邱锡鹏:《神经网络与深度学习》
2、colah:《Understanding LSTM Networks》
网址:http://colah.github.io/posts/2015-08-Understanding-LSTMs/


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· go语言实现终端里的倒计时
· 如何编写易于单元测试的代码
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· 分享一个免费、快速、无限量使用的满血 DeepSeek R1 模型,支持深度思考和联网搜索!
· 基于 Docker 搭建 FRP 内网穿透开源项目(很简单哒)
· ollama系列1:轻松3步本地部署deepseek,普通电脑可用
· 按钮权限的设计及实现
· 【杂谈】分布式事务——高大上的无用知识?