文本离散表示(三):TF-IDF结合n-gram进行关键词提取和文本相似度分析
这是文本离散表示的第二篇实战文章,要做的是运用TF-IDF算法结合n-gram,求几篇文档的TF-IDF矩阵,然后提取出各篇文档的关键词,并计算各篇文档之间的余弦距离,分析其相似度。
TF-IDF与n-gram的结合可看我的这篇文章:https://www.cnblogs.com/Luv-GEM/p/10543612.html
用TF-IDF来分析文本的相似度可看阮一峰大佬的文章:http://www.ruanyifeng.com/blog/2013/03/cosine_similarity.html
本文用hanlp进行分词,hanlp比jieba安装起来复杂,网上的安装教程也没看到比较好的,我会附在本文的结尾。
1、文档说明
这次从网上找了三篇文档,都是关于新任证监会主席易会满“首秀”的。前两篇都是偏事实性的新闻报道,第三篇是侠客岛的评论文章,之所以找三篇是为了进行对比。每个篇报道都保存为了一篇txt文档,一共3篇txt文档。
文档的原网页:
1、https://baijiahao.baidu.com/s?id=1626615436040775944&wfr=spider&for=pc
2、https://baijiahao.baidu.com/s?id=1626670136476331971&wfr=spider&for=pc
3、http://finance.sina.com.cn/roll/2019-02-28/doc-ihrfqzka9798377.shtml
2、实战内容
第一步是对分词、清洗文本并生成3-gram:使用hanlp对每篇文档进行分词,根据词性和运用正则表达式,过滤停用词和特殊符号,然后对每篇文档都生成3-gram的集合。
第二步是计算TF-IDF矩阵,提取各篇文档的top30的3-gram关键词,并生成3张词云图:这里用到sklearn来计算TF-IDF矩阵,然后用wordcloud库画词云图进行可视化。
第三步是计算三篇文档的文本相似度:将各篇文档的关键词合并为一个词汇表,统计各篇文档相对于该关键词词汇表的词频矩阵,然后两两计算文档的余弦距离。
下图来自于阮一峰的博客,介绍了计算文本相似度的流程:

看起来比较简单是不是?其实还是涉及到了很多小技巧,一起来看看吧!
这里先放出完整的代码,代码的说明比较简洁,先大致看看就行,下面会把代码拆成一段一段来说明详细说明我做这个任务的过程。
代码、文档和词云图可去我github主页下载:https://github.com/DengYangyong/TF-IDF_txt_similarity
import re,os,gc from jpype import * import numpy as np from itertools import chain from sklearn.feature_extraction.text import CountVectorizer from sklearn.feature_extraction.text import TfidfTransformer import matplotlib.pyplot as plt from wordcloud import WordCloud from scipy.spatial.distance import pdist #正则表达式用于去掉特殊符号 pattern=re.compile(u'[0-9a-zA-Z\u4E00-\u9FA5]') pattern1 = re.compile(r'[0-9]') # 调用hanlp之前的准备工作 root_path="/home/dyy/Action_in_nlp" djclass_path="-Djava.class.path="+root_path+os.sep+"hanlp"+os.sep+"hanlp-1.7.1.jar:"+root_path+os.sep+"hanlp" startJVM(getDefaultJVMPath(),djclass_path,"-Xms1g","-Xmx1g") Tokenizer = JClass('com.hankcs.hanlp.tokenizer.StandardTokenizer') # 用hanlp进行分词和根据词性去掉停用词 def tokenizer_hanlp(sentence): drop_pos_set=set(['xu','xx','y','yg','wh','wky','wkz','wp','ws','wyy','wyz','wb','u','ud','ude1','ude2','ude3','udeng','udh']) segs = [(word_pos_item.toString().split('/')[0],word_pos_item.toString().split('/')[1]) for word_pos_item in Tokenizer.segment(sentence)] seg_filter = [word_pos_pair[0] for word_pos_pair in segs if len(word_pos_pair)==2 and word_pos_pair[0]!=' ' and word_pos_pair[1] not in drop_pos_set] return seg_filter # 生成3-gram def list_3_ngram(sentence, n=3, m=2): if len(sentence) < n: n = len(sentence) temp=[sentence[i - k:i] for k in range(m, n + 1) for i in range(k, len(sentence) + 1) ] return [item for item in temp if len(''.join(item).strip())>0 and len(pattern1.findall(''.join(item).strip()))==0] # 绘制词云图 def pictures(text_list): for i,text in enumerate(text_list): text = " ".join(text) wc = WordCloud(font_path='/home/dyy/Downloads/font163/simhei.ttf', background_color='white', width=1000, height=600, max_font_size=50, min_font_size=10, mask=plt.imread('cow.jpg'), max_words=1000 ) wc.generate(text) wc.to_file(str(i)+'.png') plt.figure('The'+str(i)+'picture') plt.imshow(wc) plt.axis('off') plt.show() if __name__=="__main__": #读取文本并进行分词 c_root = os.getcwd()+os.sep+"cnews"+os.sep # news_list = [] for file in os.listdir(c_root): fp = open(c_root+file,'r',encoding="utf8") news_list.append(list(fp.readlines())
news_list = [''.join([''.join(pattern.findall(sentence)) for sentence in text ]) for text in news_list] copus=[tokenizer_hanlp(line.strip()) for line in news_list] # 生成3-gram doc=[] if len(copus)>1: for list_copus in copus: doc.extend([' '.join(['_'.join(i) for i in list_3_ngram(list_copus,n=3, m=2)])]) # 计算词频和IF-IDF ,得到词汇表及其索引 vectorizer =CountVectorizer() transformer=TfidfTransformer() freq=vectorizer.fit_transform(doc) tfidf=transformer.fit_transform(freq) #tfidf_dic=vectorizer.get_feature_names() tfidf_dic=vectorizer.vocabulary_ tfidf_dic=dict(zip(tfidf_dic.values(),tfidf_dic.keys())) #得到每篇文档TOP30的关键词。 index_keyword =[] for i, tfidf_i in enumerate(tfidf.toarray()): index_keyword.append([(j,value) for j, value in enumerate(tfidf_i)]) index_keyword = [sorted(i,key=lambda x:x[1],reverse=True) for i in index_keyword] index_keyword = [[j[0] for j in i] for i in index_keyword] list_keyword= [] for i in index_keyword: list_keyword.append([tfidf_dic[j] for j in i]) list_keyword = [i[:30] for i in list_keyword] # 画词云图 pictures(list_keyword) # 合并得到关键词词汇表 set_keyword = list(chain.from_iterable(list_keyword)) set_keyword = sorted(set(set_keyword),key=set_keyword.index) # 统计各篇文档相对于关键词词汇表的词频矩阵 freq_keyword = np.zeros(shape=(3,len(set_keyword))) for i,txt in enumerate(doc): for word in txt.split(): if word in set_keyword: freq_keyword[i,set_keyword.index(word)] += 1 #计算文档之间的余弦距离 cos_12 = 1-pdist(np.vstack([freq_keyword[0],freq_keyword[1]]),'cosine') cos_13 = 1-pdist(np.vstack([freq_keyword[0],freq_keyword[2]]),'cosine') cos_23 = 1-pdist(np.vstack([freq_keyword[1],freq_keyword[2]]),'cosine') print([cos_12,cos_13,cos_23])
fp.close()
shutdownJVM()
一、文本的分词、清洗和生成3-gram
首先导入需要的各种库。
import re,os,gc # 导入gc 是因为这是使用hanlp的依赖 from jpype import * # 这是为了使用hanlp而导入的包,因为hanlp是用java写的。 import numpy as np from itertools import chain # 这个方法可以将[[1,2],[3,4]] 展开成[1,2,3,4],比较好用。 from sklearn.feature_extraction.text import CountVectorizer # 统计各篇文档的词频用 from sklearn.feature_extraction.text import TfidfTransformer # 计算各篇文档的TF-IDF矩阵用 import matplotlib.pyplot as plt # 用来展示词云图 from wordcloud import WordCloud # 用来做词云图 from scipy.spatial.distance import pdist # 用来计算余弦距离
三篇文档都保存为了txt文档,在cnews这个目录下。于是从主函数开始读取三篇文档,每篇文档的内容都放在一个列表中,所以列表有三个元素。列表的第一行对应第三个网页,第三行对应第一个网页的内容。
第二列的内容大致是,['证券日报\n', '02-2808:25\n', '\n', '易会满首秀“施政理念” 聚焦“市场化”\n', '\n', '■董文\n', '\n', '昨天,证监会主席易会...],本身也是一个列表,元素为txt文档中的每一行文本。
if __name__=="__main__": c_root = os.getcwd()+os.sep+"cnews"+os.sep # 文档所在的路径 news_list = [] for file in os.listdir(c_root): fp = open(c_root+file,'r',encoding="utf8") news_list.append(list(fp.readlines())) # 每篇文档放在一个列表中, 读取的时候顺序倒了,第一列是上面第三个网页,第三列是第一个网页。 # 第二列的内容news_list[1] :['证券日报\n', '02-2808:25\n', '\n', '易会满首秀“施政理念” 聚焦“市场化”\n', '\n', '■董文\n', '\n', '昨天,证监会主席易会...]
从第二列元素可见,读入的文本中有大量的数字,换行符和其他特殊字符,需要清洗掉。而且,为了后续处理方便,要把列表中的每行文本拼接起来。
定义了两个正则表达式,然后这里用到了第一个正则表达式,去掉除数字、字母和中文以外的其他字符。第二个正则表达式在后面才用于去掉数字。这里先不去掉数字,在生成3-gram时再去掉,一会就知道为什么了。
最后得到的结果是 ['解局易会满...', '证券日报...', '信息量巨大易会满首秀直面科创板...'] 这样的列表,即每篇文档被弄成了一整个字符串,列表中有三个字符串。
pattern=re.compile(u'[0-9a-zA-Z\u4E00-\u9FA5]') pattern1 = re.compile(r'[0-9]') if __name__=="__main__": news_list = [''.join([''.join(pattern.findall(sentence)) for sentence in text]) for text in news_list] # news_list[1] : '证券日报02280825易会满首秀施政理念聚焦市场化董文昨天证监会主席易会满...' # 看起来有点复杂哈,慢慢看,用了两个列表循环,对于每篇文档中的每行文本,用正则表达式去除非字母数字和中文的内容 # 然后把每行的内容拼接起来,用了两次join。 # news_list 的元素是三篇文档,['解局易会满...','证券日报...','信息量巨大...']。
好,接下来用hanlp进行分词,首先配置好调用hanlp的路径,导入Tokenizer这个类。看起来复杂,都是套路,这个在后面的安装和使用中会简单介绍一下。
root_path="/home/dyy/Action_in_nlp" djclass_path="-Djava.class.path="+root_path+os.sep+"hanlp"+os.sep+"hanlp-1.7.1.jar:"+root_path+os.sep+"hanlp" startJVM(getDefaultJVMPath(),djclass_path,"-Xms1g","-Xmx1g")
Tokenizer = JClass('com.hankcs.hanlp.tokenizer.StandardTokenizer')
然后开始分词,为了看起来简洁,定义了一个分词函数,然后在主函数部分引用。
这里通过词性标注来进行分词和过滤停用词。为什么要搞得这么麻烦,jieba直接分词不就得了吗?我认为通过这种方法可以根据自己的需要更灵活地去掉自己不想要的词,即通过词性来去掉。
drop_pos_set是停用词词性表,每个词性代表的意思可以看中科院计算所的词性标注集,网页在这里:http://ictclas.nlpir.org/nlpir/html/readme.htm
下一步再把[词, 词性]中的词取出来,就得到了分词结果。
def tokenizer_hanlp(sentence): drop_pos_set=set(['xu','xx','y','yg','wh','wky','wkz','wp','ws','wyy','wyz','wb','u','ud','ude1','ude2','ude3','udeng','udh']) segs = [(word_pos_item.toString().split('/')[0],word_pos_item.toString().split('/')[1]) for word_pos_item in Tokenizer.segment(sentence)] seg_filter = [word_pos_pair[0] for word_pos_pair in segs if len(word_pos_pair)==2 and word_pos_pair[0]!=' ' and word_pos_pair[1] not in drop_pos_set] return seg_filter # drop_pos_set: 是一些停用词的词性列表,这是通过词性来过滤停用词的一种思路,非常有意思。词性的意思可看计算所词性标注集。 # segs : 这段非常长,其实word_pos_item 就是类似 '证监会/n' 这样的一个词与词性的pair,不过不是字符串,所以要toString()转为字符串后,用'/'来拆开。 # segs的输出:[('解局', 'nr'), ('易会满', 'nr'), ('首', 'q'), ('秀', 'ag'), ('今天', 't'), ('27', 'm'), ('日', 'b'),...] # seg_filter: 这段更长,耐心点兄弟,就是segs的每个元素如果长度大于2,且词性不是停用词的词性,就把词取出来。 # seg_filter的输出为:['解局', '易会满', '首', '秀', '今天', '27', '日', '下午', '新任', '证监会', '主席', '易会满',...] if __name__=='__main__': copus=[tokenizer_hanlp(line.strip()) for line in news_list]
# 输出结果为:[['解局', '易会满', '首', '秀', '今天', '27', '日', '下午', '新任',],[],[]
接下来,生成3-gram并去掉数字。这里说明三点:
一是这里的3-gram并不包含单个词(如解局),而是2个词或3个词成一个单元,词之间用下划线连接起来(如 解局_易会满,新任_证监会_主席),这是为了克服计算单个词的TF-IDF的问题,即会忽略词的前后信息。
理论上3-gram是会包含单个词,但这里我还是把单个词去掉。
二是数字在这里去掉,举个例子就明白了,比如[今天, 2, 月, 27, 日, 下午],如果先去掉数字再3-grm,就会有[今天_月,月_日] 这种单元,明显是没有意义的,应该把[2,月], [27, 日] 整个去掉。 所以在生成3-gram时连同数字的前后词一起去掉。
去掉数字用到了上面pattern1这个正则表达式。
三是每个单元之间用空格连接起来:''解局_易会满 易会满_首 首_秀',这是方便下面输入到sklearn中进行计算。这就类似于英文句子'The cat is so cute',单词之间用空格隔开。
doc的结果是:['解局_易会满 易会满_首 首_秀 秀_今天 日_下午...', '...', '...'],有三个元素,每个元素是一篇文档的3-grm连成的字符串。
def list_3_ngram(sentence, n=3, m=2): if len(sentence) < n: n = len(sentence) temp=[sentence[i - k:i] for k in range(m, n + 1) for i in range(k, len(sentence) + 1) ] return [item for item in temp if len(''.join(item).strip())>0 and len(pattern1.findall(''.join(item).strip()))==0] # temp: [['解局', '易会满'], ['易会满', '首'], ['首', '秀'], ['秀', '今天'], ['今天', '27'], ['27', '日'], ['日', '下午']...['最后', '是', '敬畏'], ['是', '敬畏', '风险']] # 这里用到pattern1这个正则表达式去掉数字,包含了数字的3-gram,就过滤掉,['今天', '27'], ['27', '日'] 就被整个过滤掉了。 if __name__==__main__": doc=[] if len(copus)>1: for list_copus in copus: doc.extend([' '.join(['_'.join(i) for i in list_3_ngram(list_copus,n=3, m=2)])]) # doc[0] 的结果为: '解局_易会满 易会满_首 首_秀 秀_今天 日_下午 下午_新任 新任_证监会...' # n如果取4就是4元语法模型,m=1时可以把单个词也取到。
二、计算TF-IDF矩阵和提取关键词
根据上面3-gram的输出doc,去求词频和TF-IDF矩阵。sklearn的计算原理是把3篇文档的3-gram去重后,得到8519个词汇,做成一个词汇表,基于这个词汇表计算词频和TF-IDF。
freq.toarray()和 tfidf.toarray() 分别可以得到词频矩阵和TF-IDF矩阵。
有了每篇文档的词频和TF-IDF矩阵,是不是可以直接求余弦距离,得出文本相似度了呢?还不行,想想看,这个矩阵太大了,数据过于稀疏,会对结果造成不好的影响。
要基于关键词词汇表计算词频矩阵,开头的那张图里已经写明白了。在提取关键词之前,先做准备工作,得到含8519个词汇的词汇表和每个词的索引。
词汇表和索引是这样的:{7257: '解局_易会满', 5137: '易会满_首', 8451: '首_秀', 6516: '秀_今天',..},这里是键值反转之后的词汇表,是为后面根据索引得到关键词而准备的。
if __name__="__main__" vectorizer =CountVectorizer() # 该类用来统计每篇文档中每个词语的词频 transformer=TfidfTransformer() #该类会统计每篇文档中每个词语的tf-idf权值 freq=vectorizer.fit_transform(doc) #freq.toarray() 可以得到词频矩阵,是3*8519的矩阵,因为3篇文档的3-gram词汇表一共得到了8519个词汇。 tfidf=transformer.fit_transform(freq) # tfidf.toarray() 可以得到tfidf 矩阵,是3* 8519的矩阵
# vectorizer.get_feature_names()可以得到这个词汇表。 tfidf_dic=vectorizer.vocabulary_ # 得到的是{'解局_易会满': 7257, '易会满_首': 5137, '首_秀': 8451, '秀_今天': 6516, ...} # 字典中的value表示的是这个词汇在语料库词汇表中对应的索引。 tfidf_dic=dict(zip(tfidf_dic.values(),tfidf_dic.keys())) # 得到:{7257: '解局_易会满', 5137: '易会满_首', 8451: '首_秀', 6516: '秀_今天',..},对上面的字典进行键值反转,方便下面根据索引取到词汇,取关键词。
下面这段代码是提取出每篇文档的TOP30关键词,因为都是自己造轮子,所以看起来比较复杂。大致的思路就是:得到每篇文档中每个词汇的在词汇表中对应的索引和TF-IDF值,形如(7557, 0.2459),然后按照TF-IDF值进行排序;得到排序后的索引列表后,根据索引在词汇表字典中取到相应的词,然后取前30个作为关键词。
得到的结果:[['资本_市场', '科创_板', '注册_制', '好_企业', ...],['资本_市场', '科创_板', '注册_制', '易会满_表示'...],['资本_市场', '科创_板', '上_表示', '新闻发布会_上_表示'...]], 可见资本市场,科创板,注册制是关键的一些词。
if __name__=="__main__": index_keyword =[] for i, tfidf_i in enumerate(tfidf.toarray()): index_keyword.append([(j,value) for j, value in enumerate(tfidf_i)]) # 这里有点复杂,先看输出:index_keyword[0] :[(118, 0.03470566583648118), (324, 0.03470566583648118), (576, 0.052058498754721766),..] # 上面是第一篇文本的每个词对应的索引及其TF-IDF值,索引和TF-IDF做成了一个元组,方便后面根据TF-IDF进行排序。 index_keyword = [sorted(i,key=lambda x:x[1],reverse=True) for i in index_keyword] #index_keyword得到: [[(7557, 0.2459727038614817), (6533, 0.16398180257432113), (6002, 0.10248862660895071),...],[...],[...]] , # 每篇文档的字的索引按TF-IDF值进行降序排列。 index_keyword = [[j[0] for j in i] for i in index_keyword] #把索引单独拎出来,[[7557, 6533, 6002, 3005, 5061, 576, 2627, 3524,...],[...],[...]] # 也就是说7557对应的词是第一篇文档中TF-IDF值最高的! list_keyword= [] for i in index_keyword: list_keyword.append([tfidf_dic[j] for j in i]) # 还记得上面那个反转的字典么,这里用来根据索引取关键词。 list_keyword = [i[:30] for i in list_keyword] # 这里对关键词列表取前30个元素,就能得到TOP30的关键词了。 # list_keyword :[['资本_市场', '科创_板', '注册_制', '好_企业', ...],['资本_市场', '科创_板', '注册_制', '易会满_表示'...],['资本_市场', '科创_板', '上_表示', '新闻发布会_上_表示'...]]
第一篇的关键词: ['资本_市场', '科创_板', '注册_制', '好_企业', '易会满_今天', '个_敬畏', '四_个_敬畏', '市场_上', '市场_违法', '市场_违法_违规', '成本_过', '成本_过_低', ...] 第二篇的关键词: ['资本_市场', '科创_板', '注册_制', '易会满_表示', '市场化_改革', '必须_敬畏', '设立_科创', '设立_科创_板', '试点_注册', '试点_注册_制',...] 第三篇的关键词: ['资本_市场', '科创_板', '上_表示', '新闻发布会_上_表示', '易会满_在', '在_新闻发布会', '在_新闻发布会_上', '易会满_在_新闻发布会', '新闻发布会_上',...]
为了更形象,用词云图进行可视化。这里定义了一个函数,用来生成词云图,一共生成了三张词云图,背景图片是一头牛。
def pictures(text_list): for i,text in enumerate(text_list): text = " ".join(text) # 这里注意要用空格把关键词连接起来 wc = WordCloud(font_path='/home/dyy/Downloads/font163/simhei.ttf', #字体路径 background_color='white', #背景颜色 width=1000, height=600, max_font_size=50, #字体大小 min_font_size=10, mask=plt.imread('cow.jpg'), #背景图片,是一头牛 max_words=1000 ) wc.generate(text) wc.to_file(str(i)+'.png') #图片保存 # 显示图片 plt.figure('The'+str(i)+'picture') #图片显示的名字 plt.imshow(wc) plt.axis('off') #关闭坐标 plt.show() if __name__=="__main__": pictures(list_keyword)
背景图片以及词云图如下:


三、基于关键词统计词频和计算余弦距离
终于要进行文本相似度分析啦!这一步先把3篇文档的关键词合并成一个集合,去掉重复后得到74个关键词,构成一个词汇表。然后得到3篇文档相对于这个词汇表的词频矩阵。
if __name__=='__main__': #去重复并保持顺序。 set_keyword = list(chain.from_iterable(list_keyword)) # 把3个列表中的各30个关键词合成一个列表,一共90个关键词,有重复的。 set_keyword = sorted(set(set_keyword),key=set_keyword.index) #用集合这种格式来去除重复,然后保持原来的顺序,不打乱,实际得到74个关键词。 #得到 ['资本_市场', '科创_板', '注册_制', '好_企业', '易会满_今天', '个_敬畏', '四_个_敬畏', '市场_上', '市场_违法', '市场_违法_违规',...] freq_keyword = np.zeros(shape=(3,len(set_keyword))) # 构造一个元素为0的词频矩阵,3*74维。 for i,txt in enumerate(doc): for word in txt.split(): # i为0时,txt为'解局_易会满 易会满_首 首_秀 秀_今天 日_下午 下午_新任 新任_证监会...' if word in set_keyword: # 第一个word为 '解局_易会满' freq_keyword[i,set_keyword.index(word)] += 1 # 如果word在词汇表中,那么相应的位置就加1。 # freq_keyword[0] 为:array([24., 16., 10., 5., 4., 3., 3., 3., 3., 3., 3., 3., 3.,...])
得到词频矩阵后,再两两计算余弦距离。对照我们的词频矩阵, Ai表示第一篇文章第i 个词的词频,Bi表示第二篇文章第i个词的词频。这里调用了scipy的包来计算。
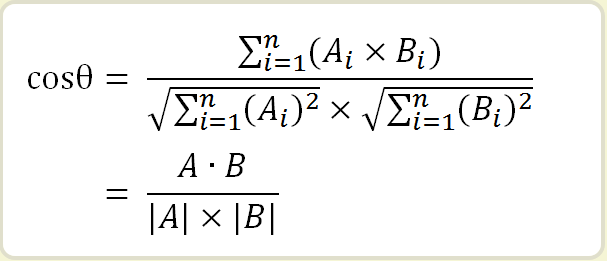
最后得到的余弦距离是第1/2,1/3,2/3 篇文档的余弦相似度为[0.83047182,0.7130633,0.81106869],看来侠客岛的那篇文章(列表第一行,网页第三篇)和第二篇文档(网页第二篇)的相似度最高,和第一个网页上的文档相似度最低。
到此,这个小任务就完成了。
if __name__=='__main__': cos_12 = 1-pdist(np.vstack([freq_keyword[0],freq_keyword[1]]),'cosine') # 计算第1和第2篇文章的余弦距离 cos_13 = 1-pdist(np.vstack([freq_keyword[0],freq_keyword[2]]),'cosine') # 计算第1和第3篇文章的余弦距离 cos_23 = 1-pdist(np.vstack([freq_keyword[1],freq_keyword[2]]),'cosine') # 计算第2和第3篇文章的余弦距离 print([cos_12,cos_13,cos_23])
fp.close()
shutdownJVM()
# 得到余弦距离:[array([0.83047182]), array([0.7130633]), array([0.81106869])]
四、hanlp的安装
hanlp是个java工具包,是上海外国语大学日本文化经济学院的小哥哥凭一己之力写出来的,工具包里词性标注、命名实体识别、自动摘要,HMM、CRF、textrank,等很多功能和算法都有,非常佩服,向小哥哥致敬!
hanlp提供了python的接口,我看很多安装教程是直接:pip install pyhanlp,然后开始用。我用的是另外一种安装和调用的方法,貌似网上相关的教程不多见,我这种调用方式应该是直接调用java的包,可能速度更快。当然这是我猜的,这个我也不太懂。
1、Hanlp环境安装
我的操作系统是:ubuntu18.04
(1)安装Java和Visual C++: 我装的是Java 1.8和Visual C++ 2015,
(2)安裝Jpype:conda install -c conda-forge jpype1
(3)测试是否按照成功
from jpype import * startJVM(getDefaultJVMPath(), "-ea") java.lang.System.out.println("Hello World") shutdownJVM()
2、Hanlp安装
(1)下载hanlp.jar包: https://github.com/hankcs/HanLP
(2)下载data.zip:https://github.com/hankcs/HanLP/releases中http://hanlp.linrunsoft.com/release/data-for-1.7.0.zip后解压数据包。
(3)配置文件:修改示例配置文件: hanlp.properties,配置文件的作用是告诉HanLP数据包的位置,只需修改第一行: root=usr/home/HanLP/,比如data目录是
/Users/hankcs/Documents/data,那么root=/Users/hankcs/Documents/
3、Hanlp调用
调用之前先输入以下的代码,给hanlp分配调用的路径,然后整个程序都运行完后,用 shutdownJVM() 来关闭。
from jpype import *
root_path="/home/dyy/Action_in_nlp" djclass_path="-Djava.class.path="+root_path+os.sep+"hanlp"+os.sep+"hanlp-1.7.1.jar:"+root_path+os.sep+"hanlp"
#注意,在ubuntu系统中“1.7.1.jar” 与后面的路径之间用冒号隔开: ,windows则用分号;来隔开。 startJVM(getDefaultJVMPath(),djclass_path,"-Xms1g","-Xmx1g")
shutdownJVM() # 注意,在代码的结尾把JVM关闭。
参考资料:
1、TF-IDF 文本相似性分析:
https://blog.csdn.net/worryabout/article/details/79792880
http://www.ruanyifeng.com/blog/2013/03/cosine_similarity.html
http://www.ruanyifeng.com/blog/2013/03/cosine_similarity.html
2、计算所词性标记集:
http://ictclas.nlpir.org/nlpir/html/readme.htm
3、词云图:
https://www.cnblogs.com/derek1184405959/p/9440526.html
4、计算距离:
https://www.cnblogs.com/denny402/p/7028832.html
5、某培训班的代码,感谢老师!

