文本离散表示(一):词袋模型(bag of words)
一、文本表示
文本表示的意思是把字词处理成向量或矩阵,以便计算机能进行处理。文本表示是自然语言处理的开始环节。
文本表示按照细粒度划分,一般可分为字级别、词语级别和句子级别的文本表示。字级别(char level)的如把“邓紫棋实在太可爱了,我想养一只”这句话拆成一个个的字:{邓,紫,棋,实,在,太,可,爱,了,我,想,养,一,只},然后把每个字用一个向量表示,那么这句话就转化为了由14个向量组成的矩阵。
文本表示分为离散表示和分布式表示。离散表示的代表就是词袋模型,one-hot(也叫独热编码)、TF-IDF、n-gram都可以看作是词袋模型。分布式表示也叫做词嵌入(word embedding),经典模型是word2vec,还包括后来的Glove、ELMO、GPT和最近很火的BERT。
这篇文章介绍一下文本的离散表示。
二、词袋模型
假如现在有1000篇新闻文档,把这些文档拆成一个个的字,去重后得到3000个字,然后把这3000个字作为字典,进行文本表示的模型,叫做词袋模型。这种模型的特点是字典中的字没有特定的顺序,句子的总体结构也被舍弃了。下面分别介绍词袋模型中的one-hot、TF-IDF和n-gram文本表示方法。
(一)one-hot
看一个简单的例子。有两句话“邓紫棋太可爱了,我爱邓紫棋”,“我要看邓紫棋的演唱会”,把这两句话拆成一个个的字,整理得到14个不重复的字,这14个字决定了在文本表示时向量的长度为14。
下面这个表格的第一行是这两句话构成的一个词袋(或者说字典),有14个字。要对两句话进行数值表示,那么先构造一个2×14的零矩阵,然后找到第一句话中每个字在字典中出现的位置,把该位置的0替换为1,第二句话也这样处理。只管字出现了没有(出现了就填入1,不然就是0),而不管这个字在句子中出现了几次。
下面表格中的二、三行就是这两句话的one-hot表示。
|
邓 |
紫 |
棋 |
太 |
可 |
爱 |
了 |
我 |
要 |
看 |
的 |
演 |
唱 |
会 |
|
1 |
1 |
1 |
1 |
1 |
1 |
1 |
1 |
0 |
0 |
0 |
0 |
0 |
0 |
|
1 |
1 |
1 |
0 |
0 |
0 |
0 |
1 |
1 |
1 |
1 |
1 |
1 |
1 |
第一个问题是数据稀疏和维度灾难。数据稀疏也就是向量的大部分元素为0,如果词袋中的字词达数百万个,那么由每篇文档转换成的向量的维度是数百万维,由于每篇文档去重后字数较少,因此向量中大部分的元素是0。而且对数百万维的向量进行计算是一件比较蛋疼的事。
但是这样进行文本表示有几个问题。可见,尽管两个句子的长度不一样,但是one-hot编码后长度都一样了,方便进行矩阵运算。
第二个问题是没有考虑句中字的顺序性,假定字之间相互独立。这意味着意思不同的句子可能得到一样的向量。比如“我太可爱了,邓紫棋爱我”,“邓紫棋要看我的演唱会”,得到的one-hot编码和上面两句话的是一样的。
第三个问题是没有考虑字的相对重要性。这种表示只管字出现没有,而不管出现的频率,但显然一个字出现的次数越多,一般而言越重要(除了一些没有实际意义的停用词)。
接下来用TF-IDF来解决字的相对重要性问题。
(二)TF-IDF
TF-IDF用来评估字词对于文档集合中某一篇文档的重要程度。字词的重要性与它在某篇文档中出现的次数成正比,与它在所有文档中出现的次数成反比。TF-IDF的计算公式为:
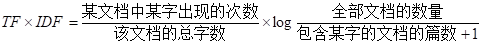
下面一步步来理解。
1 TF——词频
TF(term frequency),即词频,用来衡量字在一篇文档中的重要性,计算公式为:

首先统计字典中每个字在句子中出现的频率:
|
邓 |
紫 |
棋 |
太 |
可 |
爱 |
了 |
我 |
要 |
看 |
的 |
演 |
唱 |
会 |
|
2 |
2 |
2 |
1 |
1 |
2 |
1 |
1 |
0 |
0 |
0 |
0 |
0 |
0 |
|
1 |
1 |
1 |
0 |
0 |
0 |
0 |
1 |
1 |
1 |
1 |
1 |
1 |
1 |
为了防止数值过大,将其归一化,其中下表的二、三行构成的就是TF值矩阵。可以看到,第一句话中“邓、紫、棋、爱”这4个字对应的值更大,在第一句中更重要。
|
邓 |
紫 |
棋 |
太 |
可 |
爱 |
了 |
我 |
要 |
看 |
的 |
演 |
唱 |
会 |
|
0.14 |
0.14 |
0.14 |
0.07 |
0.07 |
0.14 |
0.07 |
0.07 |
0 |
0 |
0 |
0 |
0 |
0 |
|
0.07 |
0.07 |
0.07 |
0 |
0 |
0 |
0 |
0.07 |
0.07 |
0.07 |
0.07 |
0.07 |
0.07 |
0.07 |
2 IDF——逆文档频率
IDF((inverse document frequency),叫做逆文档频率,衡量某个字在所有文档集合中的常见程度。当包含某个字的文档的篇数越多时,这个字也就烂大街了,重要性越低。计算公式为:

计算出来的IDF矩阵如下表。值为负或0,因为这个例子比较极端,只有两句话,所以得到了这个极端的结果。“邓、紫、棋、我”这四个字由于在两句话中都出现了,所以得到的IDF值较小。
|
邓 |
紫 |
棋 |
太 |
可 |
爱 |
了 |
我 |
要 |
看 |
的 |
演 |
唱 |
会 |
|
-0.41 |
-0.41 |
-0.41 |
0 |
0 |
0 |
0 |
-0.41 |
0 |
0 |
0 |
0 |
0 |
0 |
最后得到TF-IDF = TF × IDF,这里就不再计算了。
TF-IDF的思想比较简单,但是却非常实用。然而这种方法还是存在着数据稀疏的问题,也没有考虑字的前后信息。
(三)n-gram
上面词袋模型的两种表示方法假设字与字之间是相互独立的,没有考虑它们之间的顺序。于是引入n-gram(n元语法)的概念。n-gram是从一个句子中提取n个连续的字的集合,可以获取到字的前后信息。一般2-gram或者3-gram比较常见。
比如“邓紫棋太可爱了,我爱邓紫棋”,“我要看邓紫棋的演唱会”这两个句子,分解为2-gram词汇表:
{邓,邓紫,紫,紫棋,棋,棋太,太,太可,可,可爱,爱,爱了,了,了我,我,我爱,爱邓,我要,要,要看,看邓,棋的,的,的演,演,演唱,唱会,会}
于是原来只有14个字的1-gram字典(就是一个字一个字进行划分的方法)就成了28个元素的2-gram词汇表,词表的维度增加了一倍。
结合one-hot,对两个句子进行编码得到:
[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,0]
[1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,1]
也可以结合TF-IDF来得到文本表示,这里不再计算。
这种表示方法的好处是可以获取更丰富的特征,提取字的前后信息,考虑了字之间的顺序性。
但是问题也是显而易见的,这种方法没有解决数据稀疏和词表维度过高的问题,而且随着n的增大,词表维度会变得更高。
三、总结
文本的离散表示存在着数据稀疏、向量维度过高、字词之间的关系无法度量的问题,适用于浅层的机器学习模型,不适用于深度学习模型。
参考资料:
1、《Python深度学习》
2、https://www.cnblogs.com/lianyingteng/p/7755545.html

