LLM的使用
Prompt
什么是Prompt呢?
Prompt(提示)是用户提供的文本输入,用于指导模型的输出。
一些常用的 prompting 技巧:
- 上下文(in-context learning)学习方式:
- Zero-shot零样本:给出目标指令提示
- Few-shot 少样本(找相似):提供任务范例提示
- 主要功能:
- 针对特定任务的输入-输出格式约束
- 提供上下文,缩小知识搜索空间
- CoT (Chain of Thought,思维链-推理):模拟人类的思考过程,将多步骤推理问题分解成一系列中间问题(中间推理步骤),进而实现问题分解和逐步求解。
- 最初版是X博主发表论文和帖子里说原有提示词加一句“Let's think step by step” ,就可以显著提高模型结果准确性。自此CoT成为大模型最具代表性和研究的领域/技术之一。
- 22年CoT发展:CoT -> Manucal Cot(人为书写中间过程) -> Auto Cot(自动化输出中间推理过程),可以直接把具体步骤写出来。
- 比如现在流程的ChatGPT-o1和DeepSeek-R1,让模型先输出思考过程,再给结果。
图:常规LLMs vs 推理性LLMs
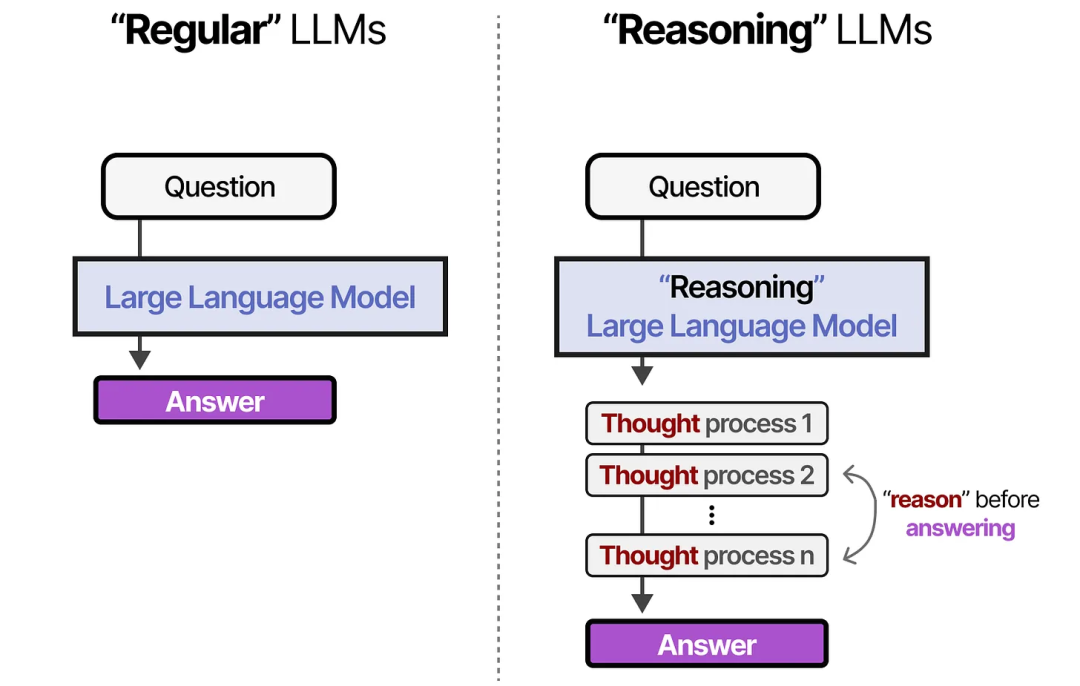
推理型模型则会使用更多的 tokens,通过系统性的思考过程 推导出答案。这一思路的核心在于:要 LLM 花费更多计算资源来生成更好的答案。
换句话说,与其让模型直接把所有“算力”都投入到“一次性生成最终答案”,不如在生成答案之前先产生一些中间思考或辅助信息(tokens),再在此基础上输出答案。
这样会带来更高质量、更准确的结果,尽管过程看似生成的文本更多、消耗的算力更大,但实际却更高效,因为减少了错误或浅层回答的概率,从而节省了后续反复验证或修改的成本。
DeepSeek使用
DeepSeek 平台API接口文档:https://platform.deepseek.com/api_keys
简单实现Demo:
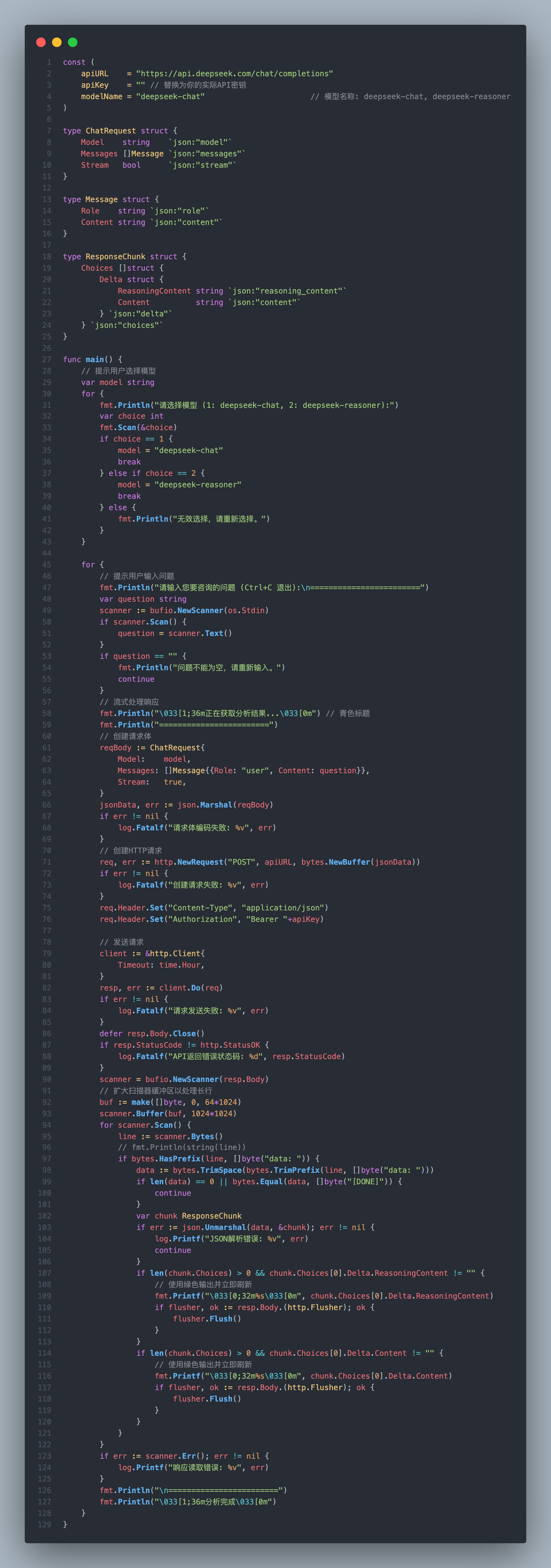
deepseek-chat 模型为 DeepSeek-V3,常规的LLMs。
deepseek-reasoner 是 DeepSeek 推出的推理模型 DeepSeek-R1。
运行case 1:

运行case2:


 浙公网安备 33010602011771号
浙公网安备 33010602011771号