Go数据结构
Go-数据结构
参考整理:1. 链表: 深入理解container/list&LRU缓存的实现 - Mohuishou (lailin.xyz)
(提醒:马上要离校,最近在整理本地电脑的笔记,很多东西可能写的有些久,忘记参考链接是否全,若是文章有所问题,请及时评论。)
1、链表: 深入理解container/list 和 LRU缓存的实现
序
- Go 数据结构与算法系列文章,本系列文章主要会包括常见的数据结构与算法实现,同时会包括 Go 标准库代码的分析理解,讲到对应章节的时候优先学习分析 Go 的源码实现,例如 slice、list、sort 等,然后可能会有一些常见的案例实现,同时这也是 极客时间-数据结构与算法之美 的课程笔记
- 本文代码仓库: https://github.com/mohuishou/go-algorithm 🌟🌟🌟🌟🌟
什么是链表?
单链表
- 链表通过指针将零散的内存数据联系在一起
- 如下图所示,包含两个结构,一个是数据 data,另外一个是下一个节点的内存地址
- 最后一个节点指向 NULL

循环链表
- 和单链表的区别就是,将尾节点指向的头结点,将整个链表组成了一个环状
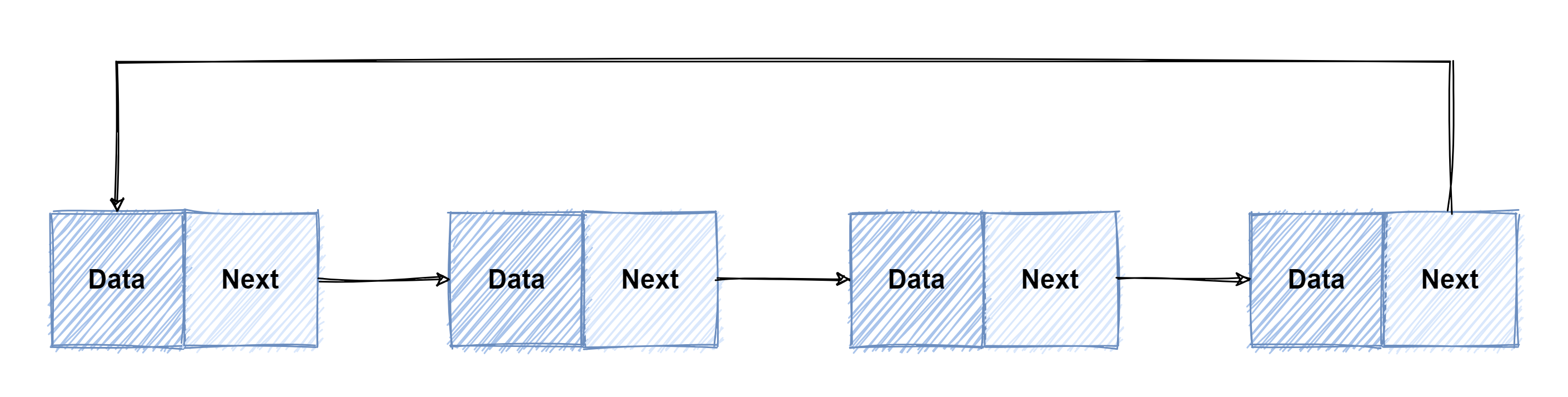
双向链表
- 和在单链表的基础之上添加了一个指向上一个节点的指针,这样我们知道任意一个节点就可以同时知道他们的上下两个节点
- 这是实际使用的时候最常用的

和数组对比
| 链表 | 数组 | |
|---|---|---|
| 查找某个元素 | O(n) | O(1) |
| 删除或者添加一个元素 | O(1) | O(n) |
标准库 Container/list 的实现
结构体定义
// Element 用于表示链表当中的节点
type Element struct {
// next, prev 分别表示上个节点和下个节点
next, prev *Element
// 表示节点所在的元素
list *List
// 节点所保存的数据,也就是上面图中的 data
Value interface{}
}
// List 这是一个双向链表
// List 的零值是一个空链表
type List struct {
// 根节点,List 其实是一个双向循环链表,root, root.prev 是尾节点, 尾节点的下一个节点指向 root
// 根节点是一个哨兵节点,是为了用来简化节点操作使用的
root Element
// 链表的长度,不包括哨兵节点,也就是根节点
len int
}
看到这里我下意识的会有两个问题:
- 为什么在
Element当中会持有一个List结构? - 为什么需要一个单独的
List结构体,直接要一个Root节点不就完事了么?
方法集
Remove(e *Element) interface{} // 删除一个节点
PushFront(v interface{}) *Element // 将值插入到链表头部
PushBack(v interface{}) *Element // 将值插入到链表尾部
InsertBefore(v interface{}, mark *Element) *Element // 在 mark 节点之前插入值
InsertAfter(v interface{}, mark *Element) *Element // 在 mark 节点之后插入值
MoveToFront(e *Element) // 将节点 e 移动至链表头部
MoveToBack(e *Element) // 将节点 e 移动至链表尾部
MoveBefore(e, mark *Element) // 将节点 e 移动到 mark 节点之前
MoveAfter(e, mark *Element) // 将节点 e 移动到 mark 节点之后
PushBackList(other *List) // 将链表 other 连接到当前链表之后
PushFrontList(other *List) // 将链表 other 连接到当前链表之前
看了暴露的方法集之后我们看一下这里面核心的几个方法,上诉暴露的方法实质上都是通过调用下面的方法实现的
insert
// 将节点 e 插入 at 之后
func (l *List) insert(e, at *Element) *Element {
// 假设 at.next 为 nt
// 1. 将节点 e 的上一个节点指向 at
e.prev = at
// 2. 将节点 e 的下一个节点指向 nt
e.next = at.next
// 3. 这个时候 e.prev.next == at.next
// 其实就是本来 at --> nt,修改为 at --> e
e.prev.next = e
// 4. e.next.prev == nt.prev
// 本来 at <--- nt,修改为 e <--- nt
e.next.prev = e
e.list = l
l.len++
return e
}
remove
// remove removes e from its list, decrements l.len, and returns e.
func (l *List) remove(e *Element) *Element {
e.prev.next = e.next
e.next.prev = e.prev
// 这里为了避免内存泄漏的操作可以学习
e.next = nil // avoid memory leaks
e.prev = nil // avoid memory leaks
e.list = nil
l.len--
return e
}
move
// move moves e to next to at and returns e.
func (l *List) move(e, at *Element) *Element {
if e == at {
return e
}
// 先把当前节点从原来的位置移除
e.prev.next = e.next
e.next.prev = e.prev
// 再将当前节点 e 插入到 at 节点之后
e.prev = at
e.next = at.next
e.prev.next = e
e.next.prev = e
return e
}
两个问题
我们在看一下最开始的两个问题
1. 为什么在 Element 当中会持有一个 List 结构?
- 查看上方的 move 方法我们就可以知道,list 提供了将节点移动到某个节点之后的方法,通过 e.List 进行对比我们就可以知道需要移动的节点是不是属于当前这个链表了,这也是
MoveToFront等方法的实现方式
func (l *List) MoveToFront(e *Element) {
if e.list != l || l.root.next == e {
return
}
// see comment in List.Remove about initialization of l
l.move(e, &l.root)
}
2. 为什么需要一个单独的 List 结构体,直接要一个 Root 节点不就完事了么?
- 看之前的
List的结构我们可以发现,在结构体中包含了一个len,这样可以避免需要取长度的时候每次都需要从头到尾遍历一遍
如何实现一个并发安全的 Container/list?
接下来,我们使用 go test -race . 测试是否存在并发安全的问题
标准库包
func TestList(t *testing.T) {
l := list.New()
wg := sync.WaitGroup{}
wg.Add(1)
go func() {
for i := 0; i < 10; i++ {
l.PushBack(i)
}
wg.Done()
}()
l.PushBack(11)
wg.Wait()
}
测试结果如下,可以明显的看到存在并发问题
go test -v -timeout 1s -race -run ^TestList$ ./...
=== RUN TestList
==================
WARNING: DATA RACE
Read at 0x00c00006e330 by goroutine 8:
container/list.(*List).lazyInit()
/usr/local/go/src/container/list/list.go:86 +0xb2
稍作改造
// List 链表
type List struct {
*list.List
mu sync.Mutex
}
// New 新建链表
func New() *List {
return &List{List: list.New()}
}
// PushBack 像链表尾部插入值
func (l *List) PushBack(v interface{}) {
// 加锁
l.mu.Lock()
defer l.mu.Unlock()
l.List.PushBack(v)
}
问题解决
go test -v -timeout 1s -race -run ^TestList_PushBack$ ./...
=== RUN TestList_PushBack
--- PASS: TestList_PushBack (0.00s)
PASS
ok github.com/mohuishou/go-algorithm/01_list/list (cached)
如何实现一个 LRU 缓存?
LRU: Least Recently Used 最近最少使用策略
这里为了训练一下代码,就没有直接使用标准库的包了
package lru
import (
"fmt"
)
// Node 链表的节点
type Node struct {
prev, next *Node
list *LRU
key string
value interface{}
}
// LRU 缓存
type LRU struct {
root *Node // 根节点
cap int // 当前缓存容量
len int // 缓存的长度
}
// NewLRU NewLRU
func NewLRU(cap int) *LRU {
l := &LRU{
root: &Node{},
cap: cap,
}
l.root.prev = l.root
l.root.next = l.root
l.root.list = l
return l
}
// Get 获取缓存数据
// 如果获取到数据,就把这个节点移动到链表头部
// 如果没有获取到,就返回nil
func (l *LRU) Get(key string) interface{} {
defer l.debug()
n := l.get(key)
if n == nil {
return nil
}
return n.value
}
func (l *LRU) get(key string) *Node {
for n := l.root.next; n != l.root; n = n.next {
if n.key == key {
n.prev.next = n.next
n.next.prev = n.prev
n.next = l.root.next
l.root.next.prev = n
l.root.next = n
n.prev = l.root
return n
}
}
return nil
}
// Put 写入缓存数据
// 如果 key 已经存在,那么更新值
// 如果 key 不存在,那么插入到第一个节点
// 当缓存容量满了的时候,会自动删除最后的数据
func (l *LRU) Put(key string, value interface{}) {
defer l.debug()
n := l.get(key)
if n != nil {
n.value = value
return
}
// 缓存满了
if l.len == l.cap {
last := l.root.prev
last.prev.next = l.root
l.root.prev = last.prev
last.list = nil
last.prev = nil
last.next = nil
l.len--
}
node := &Node{key: key, value: value}
head := l.root.next
head.prev = node
node.next = head
node.prev = l.root
l.root.next = node
l.len++
node.list = l
}
// debug for debug
func (l *LRU) debug() {
fmt.Println("lru len: ", l.len)
fmt.Println("lru cap: ", l.cap)
for n := l.root.next; n != l.root; n = n.next {
fmt.Printf("%s:%v -> ", n.key, n.value)
}
fmt.Println()
fmt.Println()
}
单元测试
package lru
import (
"testing"
"github.com/stretchr/testify/assert"
)
func TestNewLRU(t *testing.T) {
l := NewLRU(3)
assert.Equal(t, l.Get(""), nil)
l.Put("1", 1)
l.Put("2", 2)
l.Put("3", 3)
assert.Equal(t, 3, l.Get("3"))
assert.Equal(t, 1, l.Get("1"))
l.Put("4", 4)
assert.Equal(t, nil, l.Get("2"))
l.Put("3", 31)
assert.Equal(t, 31, l.Get("3"))
}
Question
- 前面讲到的 通过 Element 节点中的 List 结构来判断节点是否属于当前链表的方式,在某些情况下会出现
bug你发现了么? - LRU 缓存可以参考 leetcode 进行测试,146. LRU 缓存机制,文中的 LRU 缓存实现有许多值得优化的地方,你认为有哪些可以优化的地方?
2、数组上:深入理解slice
上期答案
Q: 通过 Element 节点中的 List 结构来判断节点是否属于当前链表的方式,在某些情况下会出现 bug
l := list.List{}
e := l.PushBack(10)
l = list.List{}
l.Remove(e)
fmt.Println("list len: ", l.Len())
Copy
接着看下面之前,先想一想,你觉得这段代码会输出什么?
这个问题来自: https://github.com/golang/go/issues/39014
这段代码会输出 -1,但是我们期望的不应该是输出 0 么?
我们来看看发生了什么?

- 当我们执行完
l.PushBack(10)这段代码直接,就如左图所示了,节点 e 指向了链表 l,链表 l 的值的长度是 1 - 但是当我们执行完
l = list.List{}我们重置了链表 l 的值,并没有修改他的地址,所以 e 还是指向的链表 l,当执行Remove方法的时候,e 的链表和当前执行的 l 的地址判断是可以对应的上的,但是实际上链表的值已经发生了变化,链表的长度已经不为 1 的,并且新的链表的根节点也没有指向 e - 所以最后得到的长度才是 -1
- 最后细心的同学应该已经发现,这里其实还可能存在内存泄漏的问题,元素 e -> root(0x2) 其实已经没有用到了
什么是数组?
- 数组大家应该都非常属性我们来简单的回顾一下
- 数组是一个具有连续的内存空间和相同类型的数据的数据结构
- 我们随机访问任意一个下标的数据的时间复杂度都是 O(1)
- 但是正是由于这种特性,导致它插入和删除元素的效率比较低,是 O(n)

Go 中的数组
func main() {
// 初始化数组
var arr = [3]int{1, 2, 3}
// 查找元素
fmt.Printf("arr[1]: %d\n", arr[1])
// 删除元素
remove(&arr, 2)
// remove(&arr, 3) // will panic
fmt.Println(arr)
}
// 删除数组 arr 的某个元素
// index 为需要删除的索引
// 从需要删除的元素开始,依次将后面的元素往前移动一位即可
// 然后将最后一位修改为该类型的默认值
func remove(arr *[3]int, index int) {
if index >= len(arr) {
log.Panicf("%d remove out range arr", index)
}
for i := index; i < len(arr)-1; i++ {
arr[i] = arr[i+1]
}
arr[len(arr)-1] = 0
}
Q: 为什么我们在 remove 函数当中的参数使用的是指针
这是因为在 go 中参数的传递都是值传递,如果不用指针的话,那么就会复制一份数据到函数中,这样就无法做到删除的作用
// 在函数 main 中
fmt.Printf("main: %p --> %+v\n", &arr, arr)
p(arr)
p2(&arr)
func p(arr [3]int) {
fmt.Printf("p: %p --> %+v\n", &arr, arr)
}
func p2(arr *[3]int) {
fmt.Printf("p2: %p --> %+v\n", arr, arr)
}
输出:
main: 0xc0000c2000 --> [1 2 0]
p: 0xc0000c2080 --> [1 2 0]
p2: 0xc0000c2000 --> &[1 2 0]
通过上面的例子我们就可以发现,在函数 p 中我们直接传递的数组,最后打印的变量地址是和 main 中不同的,就印证了我们之前的说法
在实际使用过程中,我们其实是很少使用到固定长度的数组的,而是使用可以自动扩容的 slice,接下来我们就深入的看一下 slice 当中的一些细节
深入理解 Slice
使用
基础使用
// 初始化
s1 := make([]int, 2)
fmt.Printf("s1(%p): %v, len: %d, cap: %d\n", &s1, s1, len(s1), cap(s1))
// s1(0xc00000c080): [0 0], len: 2, cap: 2
// 赋值
s1[0] = 1
s1[1] = 2
fmt.Printf("s1(%p): %v, len: %d, cap: %d\n", &s1, s1, len(s1), cap(s1))
// s1(0xc00000c080): [1 2], len: 2, cap: 2
// 扩容
s1 = append(s1, 3)
fmt.Printf("s1(%p): %v, len: %d, cap: %d\n", &s1, s1, len(s1), cap(s1))
// s1(0xc00000c080): [1 2 3], len: 3, cap: 4
// 删除元素
s1 = append(s1[:1], s1[2:]...)
fmt.Printf("s1(%p): %v, len: %d, cap: %d\n", &s1, s1, len(s1), cap(s1))
// s1(0xc00000c080): [1 3], len: 2, cap: 4
- 可以发现,通过 append 之后 s1 的容量和长度都发生了变化,说明完成了自动扩容
- 删除元素之后我们的长度发生了变化,但是容量还是原本不变
常见坑
// 复制一个 slice
s2 := s1[:2]
fmt.Printf("s2(%p): %v, len: %d, cap: %d\n", &s2, s2, len(s2), cap(s2))
// s2(0xc00000c120): [1 3], len: 2, cap: 4
s1[0] = 10 // 这里可以发现,s1[0] s2[0] 都被修改为了 10
fmt.Printf("s1(%p): %v, len: %d, cap: %d\n", &s1, s1, len(s1), cap(s1))
// s1(0xc00000c080): [10 3], len: 2, cap: 4
fmt.Printf("s2(%p): %v, len: %d, cap: %d\n", &s2, s2, len(s2), cap(s2))
// s2(0xc00000c120): [10 3], len: 2, cap: 4
s1 = append(s1, 5, 6, 7, 8)
s1[0] = 11 // 这里可以发现,s1[0] 被修改为了 11, s2[0] 还是10
fmt.Printf("s1(%p): %v, len: %d, cap: %d\n", &s1, s1, len(s1), cap(s1))
// s1(0xc00011c020): [11 3 5 6 7 8], len: 6, cap: 8
fmt.Printf("s2(%p): %v, len: %d, cap: %d\n", &s2, s2, len(s2), cap(s2))
// s2(0xc00011c0c0): [10 3], len: 2, cap: 4
- 这是一个常见的例子,我们从 s1 复制了一个 s2
- 修改 s1 的第一个元素之后,s2 的一个元素也被修改了
- 但是我们触发了 s1 的自动扩容之后,s2 的第一个元素就不会随着 s1 的修改而变化了
- 这也是当函数的参数是 slice 时我们不允许直接修改,如果需要修改需要返回这个 slice 的原因,因为函数的参数也是值的复制
func sliceChange(s []int) {
// 不允许直接这么操作
s[0] = 1
}
结构
大家如果使用过一段时间 golang 应该知道 slice 的底层结构其实是一个 struct
https://github.com/golang/go/blob/go1.15/src/runtime/slice.go
type slice struct {
array unsafe.Pointer
len int
cap int
}

- 如图所示我们可以发现,slice 的底层结构是一个结构体
- 它包含了一个指向一个数组的指针,数据实际上存储在这个指针指向的数组上
- len 表示当前 slice 使用到的长度
- cap 表示当前 slice 的容量,同时也是底层数组 array 的长度
- 这也就回答了我们上面的发现的现象,在复制 slice 的时候,slice 中数组的指针也被复制了,在出发扩容逻辑之前,两个 slice 指向的是相同的数组,出发扩容逻辑之后指向的就是不同的数组了
- 同时因为结构体中 array 是一个指针所以在 slice 作为参数传递的时候,这个指针也会被复制一份,所以也会有相同的问题
创建
// 创建一个 slice
// et: 数据的类型
// len: slice 长度
// cap: slice 容量
// 返回一个指针
func makeslice(et *_type, len, cap int) unsafe.Pointer {
// 通过 cap 计算当前类型的 slice 需要的内存容量以及是否超出最大容量
mem, overflow := math.MulUintptr(et.size, uintptr(cap))
// 异常情况判断
if overflow || mem > maxAlloc || len < 0 || len > cap {
// 通过 len 计算当前类型的 slice 需要的内存容量以及是否超出最大容量
// 如果是 len 超过限制则抛出 len 的相关异常,否则抛出 cap 异常
mem, overflow := math.MulUintptr(et.size, uintptr(len))
if overflow || mem > maxAlloc || len < 0 {
panicmakeslicelen()
}
panicmakeslicecap()
}
return mallocgc(mem, et, true)
}
还有一个 64 位的
- 64 位对比默认的只是进行了一下数据格式转换,但是这个转换的对比还是很有意思的
- 如果是在 64 位的机器上,那么 int == int64 的
- 如果是在 32 位的机器上,那么 int == int32,如果 int64(int(len64)) != len64,那么就说明这个长度超出了当前机器的内存位数,直接抛出异常错误就好了
func makeslice64(et *_type, len64, cap64 int64) unsafe.Pointer {
len := int(len64)
if int64(len) != len64 {
panicmakeslicelen()
}
cap := int(cap64)
if int64(cap) != cap64 {
panicmakeslicecap()
}
return makeslice(et, len, cap)
}
扩容
// 当 append 需要扩容的时候会调用这个函数
// et 是当前 slice 的类型
// old 是原有的 slice
// cap 是满足扩容所需的最小容量
func growslice(et *_type, old slice, cap int) slice {
// ... 一些校验逻辑,略过
// 下面这个就是扩容算法
newcap := old.cap
doublecap := newcap + newcap
if cap > doublecap {
newcap = cap
} else {
if old.len < 1024 {
newcap = doublecap
} else {
// Check 0 < newcap to detect overflow
// and prevent an infinite loop.
for 0 < newcap && newcap < cap {
newcap += newcap / 4
}
// Set newcap to the requested cap when
// the newcap calculation overflowed.
if newcap <= 0 {
newcap = cap
}
}
}
// 下面去计算新的数组所需要的内存
// 通过 old.len, cap, 以及 newcap 计算
var overflow bool
var lenmem, newlenmem, capmem uintptr
// Specialize for common values of et.size.
// For 1 we don't need any division/multiplication.
// For sys.PtrSize, compiler will optimize division/multiplication into a shift by a constant.
// For powers of 2, use a variable shift.
switch {
case et.size == 1:
lenmem = uintptr(old.len)
newlenmem = uintptr(cap)
capmem = roundupsize(uintptr(newcap))
overflow = uintptr(newcap) > maxAlloc
newcap = int(capmem)
// ... 有好几个分支,看一个类似的就可以了
}
// 检查是不是超过内存限制
if overflow || capmem > maxAlloc {
panic(errorString("growslice: cap out of range"))
}
// 分配内存
var p unsafe.Pointer
if et.ptrdata == 0 {
p = mallocgc(capmem, nil, false)
// The append() that calls growslice is going to overwrite from old.len to cap (which will be the new length).
// Only clear the part that will not be overwritten.
memclrNoHeapPointers(add(p, newlenmem), capmem-newlenmem)
} else {
// Note: can't use rawmem (which avoids zeroing of memory), because then GC can scan uninitialized memory.
p = mallocgc(capmem, et, true)
if lenmem > 0 && writeBarrier.enabled {
// Only shade the pointers in old.array since we know the destination slice p
// only contains nil pointers because it has been cleared during alloc.
bulkBarrierPreWriteSrcOnly(uintptr(p), uintptr(old.array), lenmem-et.size+et.ptrdata)
}
}
// 将原本的数组复制到新数组上
memmove(p, old.array, lenmem)
return slice{p, old.len, newcap}
}
我们重点看一下扩容的算法,可以发现有三种逻辑
- 如果需要的最小容量比两倍原有容量大,那么就取需要的容量
- 如果原有 slice 长度小于 1024 那么每次就扩容为原来的两倍
- 如果原 slice 大于等于 1024 那么每次扩容就扩为原来的 1.25 倍
newcap := old.cap
doublecap := newcap + newcap
if cap > doublecap {
newcap = cap
} else {
if old.len < 1024 {
newcap = doublecap
} else {
// Check 0 < newcap to detect overflow
// and prevent an infinite loop.
for 0 < newcap && newcap < cap {
newcap += newcap / 4
}
// Set newcap to the requested cap when
// the newcap calculation overflowed.
if newcap <= 0 {
newcap = cap
}
}
}
空 Slice
我们先看一下 Slice 初始化的方式
var s1 []int
s2 := make([]uint, 0)
s3 := []int{}
// fmt.Printf("%p: %v, len: %d, cap: %d\n", s1, s1, len(s1), cap(s1))
// 0x0: [], len: 0, cap: 0
// 0x587450: [], len: 0, cap: 0
// 0x587450: [], len: 0, cap: 0
- tips:
%p打印 slice 会打印 slice 底层指向的数组的地址 - 我们可以发现,第一种方式进行初始化,出现的也就是 slice 的零值,底层的数组指针是一个 nil
- 第二种和第三种的底层指针都有一个值,不过没有实际分配内存
- 这三种方式初始化出来的 cap、和 len 的长度都是 0
规范技巧
-
slice 作为参数时,不要直接存储它的引用,而是通过
copy复制一份
- 原因请查看上文,Slice 的结构
- 示例:Uber Go 规范: nil-是一个有效的-slice
-
要检查切片是否为空,请始终使用
len(s) == 0而非
nil- 原因请查看上文,Slice 初始化
- 示例:Uber Go 规范: 在边界处拷贝-Slices-和-Maps
Question
- 在讲解 slice 初始化的过程中,为什么
s2,s3打印的数组指针都是0x587450? - 请查看下面一段代码,会输出什么,为什么?
- A: 5 8 B: 8 8 C: 5 5 D: 5 6
package main
import (
"fmt"
)
func main() {
s := []int{1, 2}
s = append(s, 3, 4, 5)
fmt.Println(len(s), cap(s))
}
3、数组下:使用gdb调试go代码
问题回顾
本文章主要是为了回答上一篇文章的问题,并且介绍一下在这个过程中以及后续都会使用到的调试工具 gdb
- 请查看下面一段代码,会输出什么,为什么?
- A: 5 8 B: 8 8 C: 5 5 D: 5 6
package main
import (
"fmt"
)
func main() {
s := []int{1, 2}
s = append(s, 3, 4, 5)
fmt.Println(len(s), cap(s))
}
- 在讲解 slice 初始化的过程中,为什么
s2,s3打印的数组指针都是0x587450?
slice 扩容算法是否遗漏了什么?
首先我们回顾一下上一篇文章当中讲到的 slice 扩容的 算法:
- 如果需要的最小容量比两倍原有容量大,那么就取需要的容量
- 如果原有 slice 长度小于 1024 那么每次就扩容为原来的两倍
- 如果原 slice 大于等于 1024 那么每次扩容就扩为原来的 1.25 倍
按照这个逻辑进行套用:
s初始化时len=2s = append(s, 3, 4, 5)此时需要的最小容量为5 > 2*2- 按照这个逻辑最后的答案应该是
C: 5 5 - 但是如果大家运行过这段代码应该会知道这个答案是
D: 5 6为什么呢?这个逻辑和我们之前了解到的不太一样啊
接下来我们就使用 gdb 调试一下看看结果
使用 GDB 调试 Golang 代码
调试 go 程序我们常用的调试工具其实是 dlv 这个工具非常好用,并且可以很好的和 VS Code Goland 等 IDE 进行结合,但是它无法调试 runtime 的代码,这个时候就要使用上 gdb 了,如果大家不需要调试 runtime 的代码的话还是建议使用 dlv
安装
brew install gdb # for mac
如果是 linux 使用自带的包管理工具进行安装即可
注意安装完成之后需要在 home 目录上添加相关配置
vim ~/.gdbinit
# 输入下面
add-auto-load-safe-path $GOROOT/src/runtime/runtime-gdb.py # 这里将 $GOROOT 替换为你的 GO 安装目录
如果你是 mac 首次安装 gdb 需要给 gdb 签名,可以参考: https://gist.github.com/hlissner/898b7dfc0a3b63824a70e15cd0180154
编译代码
-
我们使用
-gcflags=all="-N -l"禁用内联优化方便后面调试 -
在 mac 上如果不加
-ldflags='-compressdwarf=false'在 gdb 调试的时候可能会提示
No symbol table is loaded. Use the "file" command.- 这是因为为了减少二进制大小会默认压缩 DWARF 调试信息,这个在 mac 和 windows 上部分工具不支持,linux 一般没有这个问题
- 加上
-ldflags='-compressdwarf=false'这个标志可以禁用压缩方便调试
go build -o bin/03_q1_slice_cap -gcflags=all="-N -l" -ldflags='-compressdwarf=false' 02_array/03_q1_slice_cap/main.go
进入 GDB 调试窗口
-tui表示同时显示代码窗口
gdb -tui ./bin/03_q1_slice_cap
如下图所示,回车几次之后出现 Loading Go Runtime support. 就说明正常了
常用调试命令
b 文件名:行数打断点info b当前的断点情况r运行程序知道断点处c继续执行到下一个断点s单步执行,如果有调用函数则进入函数,注意和 n 的区别n单步执行,如果有调用的函数不会进入函数内部until退出循环until:行号执行到指定行info locals当前堆栈的所有变量info args打印参数info goroutines查看所有的 goroutine 及其 IDhelp帮助q退出
调试
知道如何操作之后,我们开始干活
- 首先给 append 函数打一个断点
b main.go:11 - 然后执行到断点处
r - 如下图所示,单步运行进入到
slice的扩容函数中s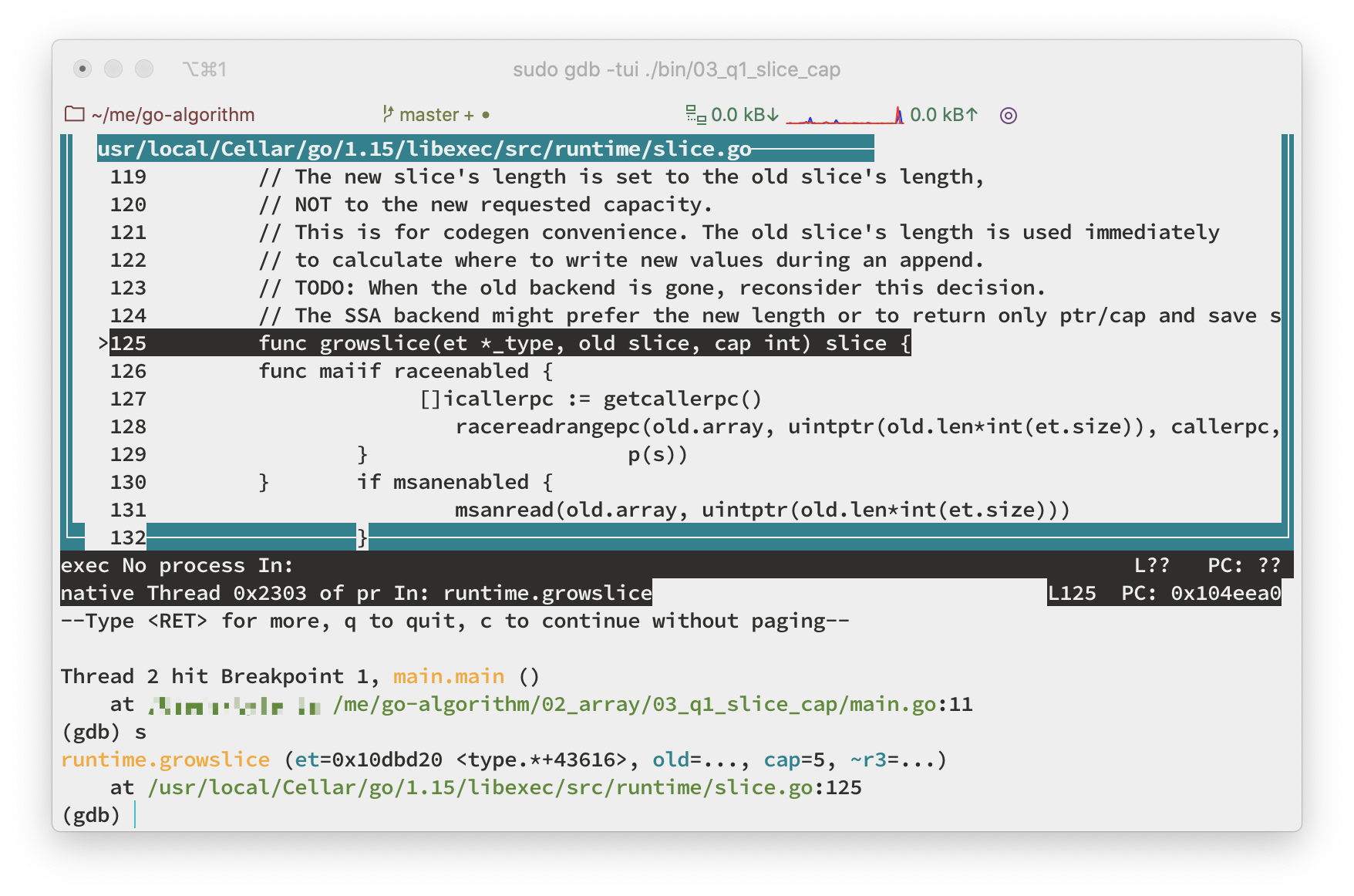
- 接下来我们使用
n一直单步执行到扩容算法结束,使用info locals打印变量。我们可以发现这个时候计算出的newcap和我们最初预计的一样是 5,那哪里出了问题呢?我们继续使用n接着看
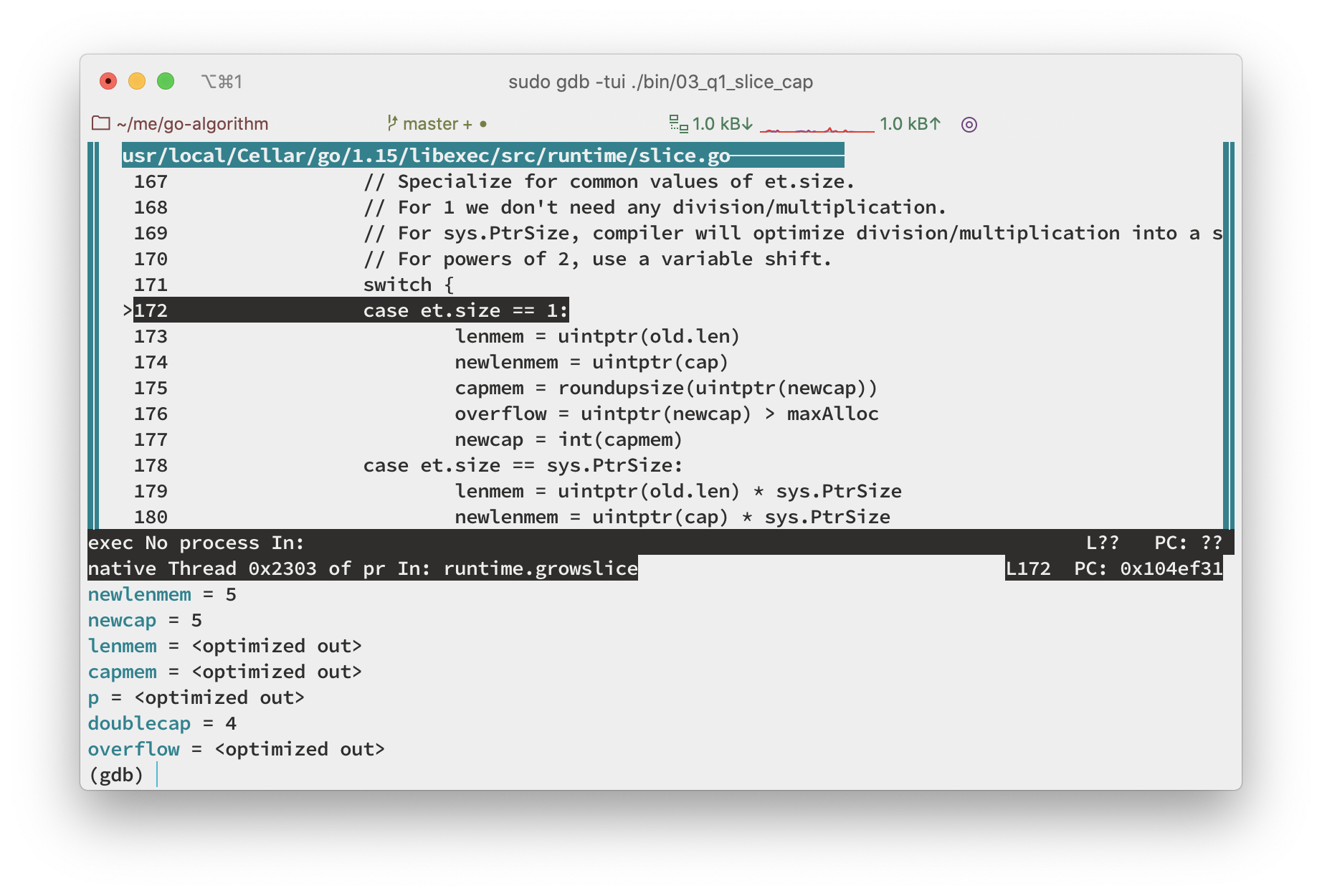
- 如下图所示,执行到这里我们发现,
newcap被重新赋值了,并且这个时候capmem=48PtrSize=8所以最后的出来了newcap等于 6
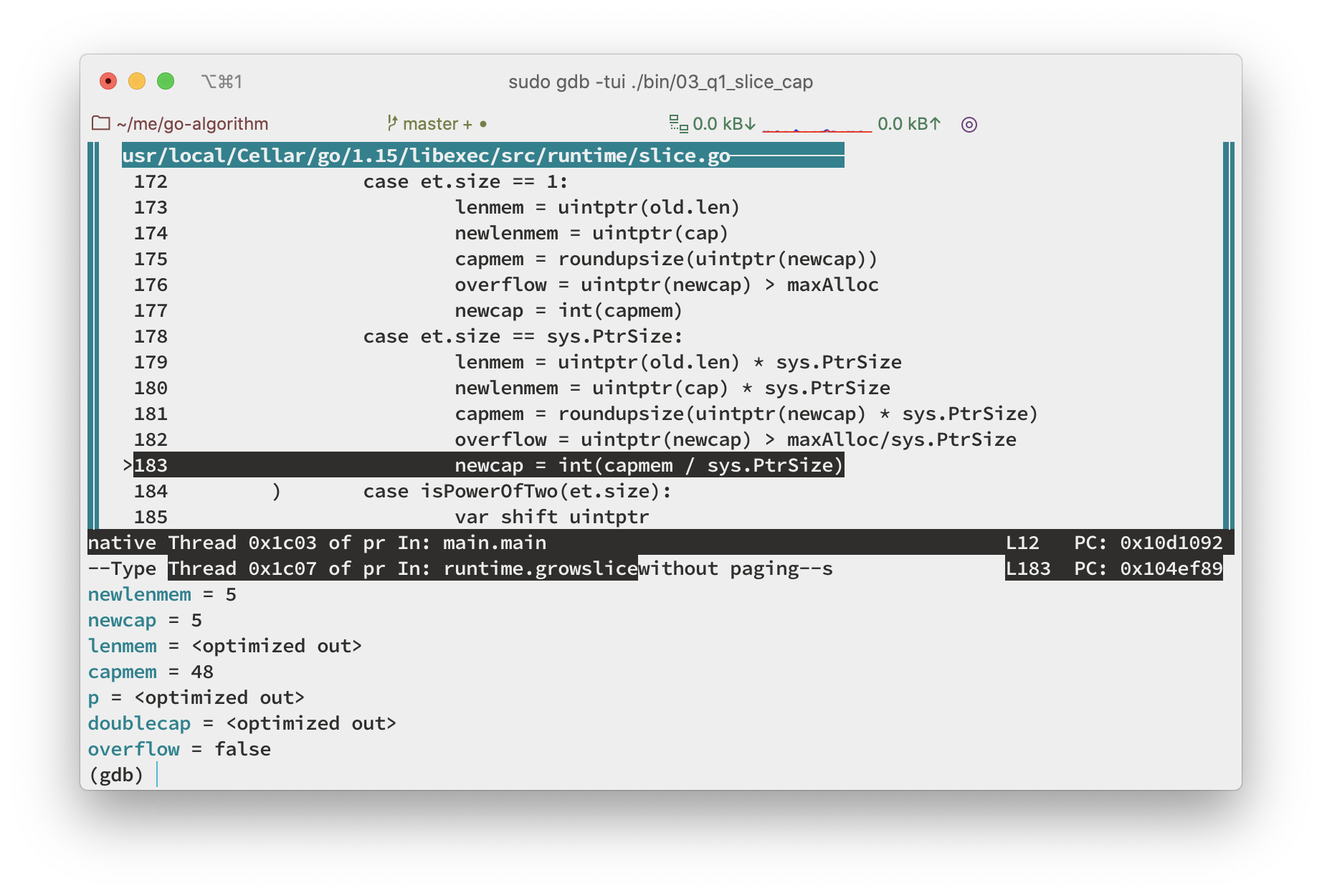
image.png
知道问题出现在哪里之后我们可以再来看一下源代码,有一个内存对齐的函数
// Returns size of the memory block that mallocgc will allocate if you ask for the size.
func roundupsize(size uintptr) uintptr {
if size < _MaxSmallSize {
if size <= smallSizeMax-8 {
return uintptr(class_to_size[size_to_class8[divRoundUp(size, smallSizeDiv)]])
} else {
return uintptr(class_to_size[size_to_class128[divRoundUp(size-smallSizeMax, largeSizeDiv)]])
}
}
if size+_PageSize < size {
return size
}
return alignUp(size, _PageSize)
}
const (
_MaxSmallSize = 32768
smallSizeDiv = 8
smallSizeMax = 1024
largeSizeDiv = 128
_NumSizeClasses = 67
_PageShift = 13
)
var class_to_size = [_NumSizeClasses]uint16{0, 8, 16, 32, 48, 64, 80, 96, 112, ...}
var class_to_allocnpages = [_NumSizeClasses]uint8{0, 1, 1, 1, 1, 1, 1, 1, ...}
可以发现我们之前在计算 capmem 的时候传入的 capmem = roundupsize(uintptr(newcap) * sys.PtrSize) 值是 5*8=40 最后对齐出的结果就是 48 了
总结
slice 扩容算法
- 如果需要的最小容量比两倍原有容量大,那么就取需要的容量
- 如果原有 slice 长度小于 1024 那么每次就扩容为原来的两倍
- 如果原 slice 大于等于 1024 那么每次扩容就扩为原来的 1.25 倍
- 除此之外扩容容量计算完成之后,还会进行一次内存对齐操作
搜索 slice 扩容策略很多都会说第 2、3 点但是没有说 1, 4 点就会造成一些困惑
GDB 调试
- mac 下安装使用 gdb 比较麻烦,建议使用 linux
- 一般情况下我们还是建议使用 dlv 进行调试,如果有 runtime 库的调试需求可以使用 gdb
- 学习了 gdb 的安装以及基本使用方式,你之前有类似的经历么?一般会在什么情况下使用 gdb 进行调试
问题 2 解答: 在讲解 slice 初始化的过程中,为什么 s2 , s3 打印的数组指针都是 0x587450 ?
在讲解 makeslice 的时候我们有说到最后一步会调用 mallocgc 分配内存,看这个函数的源码我们就能发现,有一步判断,如果容量为 0 会返回一个固定的地址
if size == 0 {
return unsafe.Pointer(&zerobase)
}
4、栈上:如何实现一个计算器
栈
定义
栈是一种“操作受限”的线性表,后进者先出,先进者后出。
比较典型的例子就是我们在叠盘子的时候,叠的时候从下到上一个一个磊起来,取的时候,再从上到下一个一个的拿出来。
说到先入后出这种特性,在 Go 中你第一时间想到了什么?不知道是否和我的答案一样, defer

实现
存在两种实现方式,第一种是数组实现的顺序栈,第二种是链表链式栈
数组实现
数组实现我们直接使用了 slice ,并且借助 slice 实现了自动扩容
// Stack Stack
type Stack struct {
items []string
current int
}
// NewStack NewStack
func NewStack() *Stack {
return &Stack{
items: make([]string, 10),
current: 0,
}
}
// Push 入栈
func (s *Stack) Push(item string) {
s.current++
// 判断底层 slice 是否满了,如果满了就 append
if s.current == len(s.items) {
s.items = append(s.items, item)
return
}
s.items[s.current] = item
}
// Pop 出栈
func (s *Stack) Pop() string {
if s.current == 0 {
return ""
}
item := s.items[s.current]
s.current--
return item
}
链表实现
链式栈的实现我们利用双向循环链表,简化栈的插入操作
// node 节点
type node struct {
prev, next *node
value string
}
// Stack 链式栈
type Stack struct {
root *node
len int
}
// NewStack NewStack
func NewStack() *Stack {
n := &node{}
n.next = n
n.prev = n
return &Stack{root: n}
}
// Push 入栈
func (s *Stack) Push(item string) {
n := &node{value: item}
s.root.prev.next = n
n.prev = s.root.prev
n.next = s.root
s.root.prev = n
s.len++
}
// Pop 出栈
func (s *Stack) Pop() string {
item := s.root.prev
if item == s.root {
return ""
}
s.root.prev = item.prev
item.prev.next = s.root
// 避免内存泄漏
item.prev = nil
item.next = nil
s.len--
return item.value
}
典型问题
实现一个计算器
我们实现了支持+、-、*、/、(、) 的计算器,这也是leetcode#244的一种解法,并且我们这个实现更加复杂,原题只需要计算加减法
package calculation
import (
"fmt"
"strconv"
)
// 操作符的优先级
var operatorPriority = map[string]int{
"+": 0,
"-": 0,
"*": 1,
"/": 1,
"(": 2,
")": 2,
}
// Calculator 计算器
type Calculator struct {
nums *StackInt
operators *Stack
exp string
}
// NewCalculator NewCalculator
func NewCalculator(exp string) *Calculator {
return &Calculator{
nums: NewStackInt(),
operators: NewStack(),
exp: exp,
}
}
// Calculate 获取计算结果
func (c *Calculator) Calculate() int {
l := len(c.exp)
for i := 0; i < l; i++ {
switch e := (c.exp[i]); e {
case ' ':
continue
case '0', '1', '2', '3', '4', '5', '6', '7', '8', '9':
// 一直往后获取数字,如果下一个还是数字说明这一个数还不完整
j := i
for j < l && c.exp[j] <= '9' && c.exp[j] >= '0' {
j++
}
n, _ := strconv.Atoi(c.exp[i:j])
i = j - 1
c.nums.Push(n)
case '+', '-', '*', '/':
// 从计算符栈中获取栈顶元素,如果当前操作符的优先级低于栈顶元素的优先级
// 并且栈顶元素不为空,和括号
// 那么从数据栈中取两个数据和栈顶操作符进行计算
pre := c.operators.Pop()
for pre != "" && pre != "(" && operatorPriority[string(e)] <= operatorPriority[pre] {
c.nums.Push(c.calc(pre))
pre = c.operators.Pop()
}
if pre != "" {
c.operators.Push(pre)
}
c.operators.Push(string(e))
case '(':
c.operators.Push(string(e))
case ')':
// 碰到右括号之后就一直不断操作符栈中弹出元素,并且取两个数据进行计算
// 直到碰到左括号为止
for o := c.operators.Pop(); o != "(" && o != ""; o = c.operators.Pop() {
c.nums.Push(c.calc(o))
}
default:
panic("invalid exp")
}
}
// 最后如果不存在操作符,说明数据栈中的栈顶元素就是最后结果
o := c.operators.Pop()
if o == "" {
return c.nums.Pop()
}
// 如果存在,就把最后的数据进行计算后返回
return c.calc(o)
}
// calc 单次计算操作,o: 计算符
func (c *Calculator) calc(o string) int {
b := c.nums.Pop()
a := c.nums.Pop()
fmt.Printf("%d %s %d\n", a, o, b)
switch o {
case "+":
return a + b
case "-":
return a - b
case "*":
return a * b
case "/":
return a / b
}
return 0
}
// calculate 计算器,支持加减乘除
func calculate(s string) int {
return NewCalculator(s).Calculate()
}
5、栈下:深入理解defer
上篇文章中我们讲到栈的时候说到先入后出这种特性,在 Go 中第一时间想到的就是 defer 接下来我们就深入理解一下 defer
用法
下面先回顾一下基本的用法以及较为常见的坑,文末会给出输出结果,可以先想想会输出什么
基本用法 1: 延迟处理,资源清理
// 基本用法:延迟调用,清理资源
func f0() {
defer fmt.Println("clean")
fmt.Println("hello")
}
基本用法 2: 后进先出
// 基本用法1: 后进先出
func f1() {
defer fmt.Println("1")
defer fmt.Println("2")
fmt.Println("3")
}
基本用法 3: 异常恢复
// 基本用法2:异常恢复
func f2() {
defer func() {
if err := recover(); err != nil {
fmt.Printf("paniced: %+v \n", err)
}
}()
panic("test")
}
容易掉坑 1: 闭包变量
// 容易掉坑之,函数变量修改
func f3() (res int) {
defer func() {
res++
}()
return 0
}
容易掉坑 2: 参数传递
// 容易掉坑之,参数复制
func f4() (res int) {
defer func(res int) {
res++
}(res)
return 0
}
源码剖析
想要看源码,我们需要先找到源码的位置,我们可以直接执行 go tool compile -N -l -S main.go 获取汇编代码
// ....
0x00d8 00216 (main_2.go:6) PCDATA $1, $0
0x00d8 00216 (main_2.go:6) CALL runtime.deferprocStack(SB)
0x00dd 00221 (main_2.go:6) NOP
0x00e0 00224 (main_2.go:6) TESTL AX, AX
0x00e2 00226 (main_2.go:6) JNE 252
0x00e4 00228 (main_2.go:6) JMP 230
0x00e6 00230 (main_2.go:7) XCHGL AX, AX
0x00e7 00231 (main_2.go:7) CALL runtime.deferreturn(SB)
0x00ec 00236 (main_2.go:7) MOVQ 216(SP), BP
0x00f4 00244 (main_2.go:7) ADDQ $224, SP
0x00fb 00251 (main_2.go:7) RET
0x00fc 00252 (main_2.go:6) XCHGL AX, AX
0x00fd 00253 (main_2.go:6) NOP
0x0100 00256 (main_2.go:6) CALL runtime.deferreturn(SB)
我们可以看到主要是调用了 runtime.deferprocStack , runtime.deferreturn 这两个运行时的方法
defer 定义
type _defer struct {
siz int32 // 所有传入参数和返回值的总大小
started bool // defer 是否执行了
heap bool // 是否在堆上,这是 go1.13 新加的,划重点
sp uintptr // 函数栈指针寄存器,一般指向当前函数栈的栈顶
pc uintptr // 程序计数器,指向下一条需要执行的指令
fn *funcval // 指向传入的函数地址和参数
_panic *_panic // 指向 panic 链表
link *_defer // 指向 defer 链表
//...
}
deferprocStack
func deferprocStack(d *_defer) {
gp := getg() // 获取 g,判断是否在用户栈上
if gp.m.curg != gp {
// go code on the system stack can't defer
throw("defer on system stack")
}
// siz and fn are already set.
// The other fields are junk on entry to deferprocStack and
// are initialized here.
d.started = false
d.heap = false
d.openDefer = false
d.sp = getcallersp()
d.pc = getcallerpc()
d.framepc = 0
d.varp = 0
// The lines below implement:
// d.panic = nil
// d.fd = nil
// d.link = gp._defer // 这两个是将当前 defer 插入到链表头部,也就是defer为什么时候先入后出的原因
// gp._defer = d
// But without write barriers. The first three are writes to
// the stack so they don't need a write barrier, and furthermore
// are to uninitialized memory, so they must not use a write barrier.
// The fourth write does not require a write barrier because we
// explicitly mark all the defer structures, so we don't need to
// keep track of pointers to them with a write barrier.
*(*uintptr)(unsafe.Pointer(&d._panic)) = 0
*(*uintptr)(unsafe.Pointer(&d.fd)) = 0
*(*uintptr)(unsafe.Pointer(&d.link)) = uintptr(unsafe.Pointer(gp._defer))
*(*uintptr)(unsafe.Pointer(&gp._defer)) = uintptr(unsafe.Pointer(d))
return0()
// No code can go here - the C return register has
// been set and must not be clobbered.
}
注意这几行
说明这个 defer 不在堆上
d.heap = false
这两个是将当前 defer 插入到链表头部,也就是 defer 为什么时候先入后出的原因
// d.link = gp._defer
// gp._defer = d
deferreturn
func deferreturn(arg0 uintptr) {
gp := getg()
d := gp._defer
if d == nil {
return
}
sp := getcallersp()
if d.sp != sp {
return
}
if d.openDefer {
done := runOpenDeferFrame(gp, d)
if !done {
throw("unfinished open-coded defers in deferreturn")
}
gp._defer = d.link
freedefer(d)
return
}
switch d.siz {
case 0:
// Do nothing.
case sys.PtrSize:
*(*uintptr)(unsafe.Pointer(&arg0)) = *(*uintptr)(deferArgs(d))
default:
memmove(unsafe.Pointer(&arg0), deferArgs(d), uintptr(d.siz))
}
fn := d.fn
d.fn = nil
gp._defer = d.link
freedefer(d)
// If the defer function pointer is nil, force the seg fault to happen
// here rather than in jmpdefer. gentraceback() throws an error if it is
// called with a callback on an LR architecture and jmpdefer is on the
// stack, because the stack trace can be incorrect in that case - see
// issue #8153).
_ = fn.fn
jmpdefer(fn, uintptr(unsafe.Pointer(&arg0)))
}
如果函数中存在 defer 编译器就会自动在函数的最后插入一个 deferreturn
- 清空 defer 的调用信息
- freedefer 将 defer 对象放入到 defer 池中,后面可以复用
- 如果存在延迟函数就会调用 runtime·jmpdefer 方法跳转到对应的方法上去
- runtime·jmpdefer 方法会递归调用 deferreturn 一直执行到结束为止
deferproc
func deferproc(siz int32, fn *funcval) { // arguments of fn follow fn
gp := getg()
if gp.m.curg != gp {
// go code on the system stack can't defer
throw("defer on system stack")
}
// the arguments of fn are in a perilous state. The stack map
// for deferproc does not describe them. So we can't let garbage
// collection or stack copying trigger until we've copied them out
// to somewhere safe. The memmove below does that.
// Until the copy completes, we can only call nosplit routines.
sp := getcallersp()
argp := uintptr(unsafe.Pointer(&fn)) + unsafe.Sizeof(fn)
callerpc := getcallerpc()
d := newdefer(siz)
if d._panic != nil {
throw("deferproc: d.panic != nil after newdefer")
}
d.link = gp._defer
gp._defer = d
d.fn = fn
d.pc = callerpc
d.sp = sp
switch siz {
case 0:
// Do nothing.
case sys.PtrSize:
*(*uintptr)(deferArgs(d)) = *(*uintptr)(unsafe.Pointer(argp))
default:
memmove(deferArgs(d), unsafe.Pointer(argp), uintptr(siz))
}
// deferproc returns 0 normally.
// a deferred func that stops a panic
// makes the deferproc return 1.
// the code the compiler generates always
// checks the return value and jumps to the
// end of the function if deferproc returns != 0.
return0()
// No code can go here - the C return register has
// been set and must not be clobbered.
}
除了 deferprocStack 还有 deferproc 这个方法,那这个方法和之前的方法有什么区别呢?
主要的区别就是这个方法将 defer 分配在了堆上,看下方的 newdefer
func newdefer(siz int32) *_defer {
// ...
d.heap = true
return d
}
其他和 deferprocStack 类似这里就不赘述了
什么时候 defer 会在堆上什么时候会在栈上?
那问题来了如何判断 defer 在堆上还是在栈上呢?
https://github.com/golang/go/blob/master/src/cmd/compile/internal/gc/escape.go#L743
topLevelDefer := where != nil && where.Op == ODEFER && e.loopDepth == 1
if topLevelDefer {
// force stack allocation of defer record, unless
// open-coded defers are used (see ssa.go)
where.Esc = EscNever
}
d := callDefer
if n.Esc == EscNever {
d = callDeferStack
}
s.call(n.Left, d)
可以看到主要是在逃逸分析的时候,发现 e.loopDepth == 1 并且不是 open-coded defer 就会分配到栈上。
这也是为什么 go 1.13 之后 defer 性能提升的原因,所以切记不要在循环中使用 defer 不然优化也享受不到
我们来验证一下
func f6() {
for i := 0; i < 10; i++ {
defer func() {
fmt.Printf("f6: %d\n", i)
}()
}
}
看一下汇编结果
0x0073 00115 (main.go:67) CALL runtime.deferproc(SB)
0x0078 00120 (main.go:67) TESTL AX, AX
0x007a 00122 (main.go:67) JNE 151
0x007c 00124 (main.go:67) JMP 126
0x007e 00126 (main.go:66) PCDATA $1, $-1
0x007e 00126 (main.go:66) NOP
0x0080 00128 (main.go:66) JMP 130
0x0082 00130 (main.go:66) MOVQ "".&i+32(SP), AX
0x0087 00135 (main.go:66) MOVQ (AX), AX
0x008a 00138 (main.go:66) MOVQ "".&i+32(SP), CX
0x008f 00143 (main.go:66) INCQ AX
0x0092 00146 (main.go:66) MOVQ AX, (CX)
0x0095 00149 (main.go:66) JMP 68
0x0097 00151 (main.go:67) PCDATA $1, $0
0x0097 00151 (main.go:67) XCHGL AX, AX
0x0098 00152 (main.go:67) CALL runtime.deferreturn(SB)
可以发现在循环嵌套的场景下,的确调用的是 runtime.deferproc 方法,被分配到栈上了。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号