第一次个人编程作业
第一次个人编程作业
零、面向开源,春暖花开
问:如何从零开始造火箭?
答:去别的火箭厂搬个火箭。
看看搬来的代码是什么…………py文件,哦是用python写的。打开vscode,ctrl c+v,运行代码……
嗯?怎么报错了?没有python解释器?难道vscode不是自带python解释器的?原来vscode不是IDE,啊这……
下载好python解释器,修改环境变量,下载python插件,用了一个世纪的时间终于ok,运行代码!
嗯?第三方库不能用?
又是一个世纪过去……哦,原来python要用pip指令来安装库。
安装完第三方库,运行!
踩了若干个坑之后……
ohhhhhhhhhhhh!有结果了!
分析性能,性能怎么分析?pycharm好像可以,下载!
吃一堑长一智,选择好python解释器,下载好插件,ctrl c+v, 运行!
又踩了若干个坑(包括但不局限于内存测试、单元测试、用git将代码上传到github仓库)之后,本菜鸡终于完成了第一次编程作业,泪目。
一、计算模块接口的设计与实现过程
1.总体流程

实话实说,既然代码都是直接搬来的,在设计和实现方面我也没什么好说的(我爬_(°ω°」∠)_)。
代码的核心是使用向量空间模型(Vector Space Model, VSM)计算相似度。先用jieba分词器对读入的文本进行分词处理,然后使用TF-IDF算法进行文本特征选择,计算出文本的特征向量,最后对得到的特征向量用余弦相似度算法计算出两个文本的相似度。
2.计算模块
(1)分词处理
#使用jieba分词器对文本text1、text2进行分词
words1 = [word.word for word in pesg.cut(text1) if word.flag[0] not in ['u', 'x', 'w']]
words2 = [word.word for word in pesg.cut(text2) if word.flag[0] not in ['u', 'x', 'w']]
(2)使用TF-IDF算法计算文本的特征向量
(俺很想注释,但俺没看懂……)
def tfidf_rep(self, sents):
sent_list = []
df_dict = {}
tfidf_list = []
for sent in sents:
tmp = {}
for word in sent:
if word not in tmp:
tmp[word] = 1
else:
tmp[word] += 1
tmp = {word:word_count/sum(tmp.values()) for word, word_count in tmp.items()}
for word in set(sent):
if word not in df_dict:
df_dict[word] = 1
else:
df_dict[word] += 1
sent_list.append(tmp)
df_dict = {word :math.log(len(sents)/df+1) for word, df in df_dict.items()}
words = list(df_dict.keys())
for sent in sent_list:
tmp = []
for word in words:
tmp.append(sent.get(word, 0))
tfidf_list.append(tmp)
return tfidf_list
(3)使用余弦相似度算法计算相似度
def cosine_sim(self, vector1, vector2):
#向量1和向量2的内积
cos1 = np.sum(vector1 * vector2)
#求向量1与向量1的内积,再开方
cos21 = np.sqrt(sum(vector1 ** 2))
#求向量2与向量2的内积,再开方
cos22 = np.sqrt(sum(vector2 ** 2))
#计算相似度
similarity = cos1 / float(cos21 * cos22)
return similarity
3.运行结果
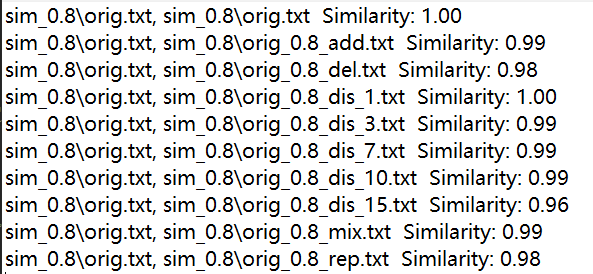
测试结果显示,文本相似度都非常高emmmmm
因为在基于VSM的算法中,文本的内部结构对于相似度计算的影响不大,所以所有测试样例中的乱序现象不会降低相似度的计算结果。另外,算法较为简陋,没有对停用词和标点进行处理,或许也是文本相似度结果这么高的原因。(也是性能改进的方向)
4.性能测试
(1)时间
使用pycharm自带的性能测试工具Profile对代码进行分析:
统计图如下:
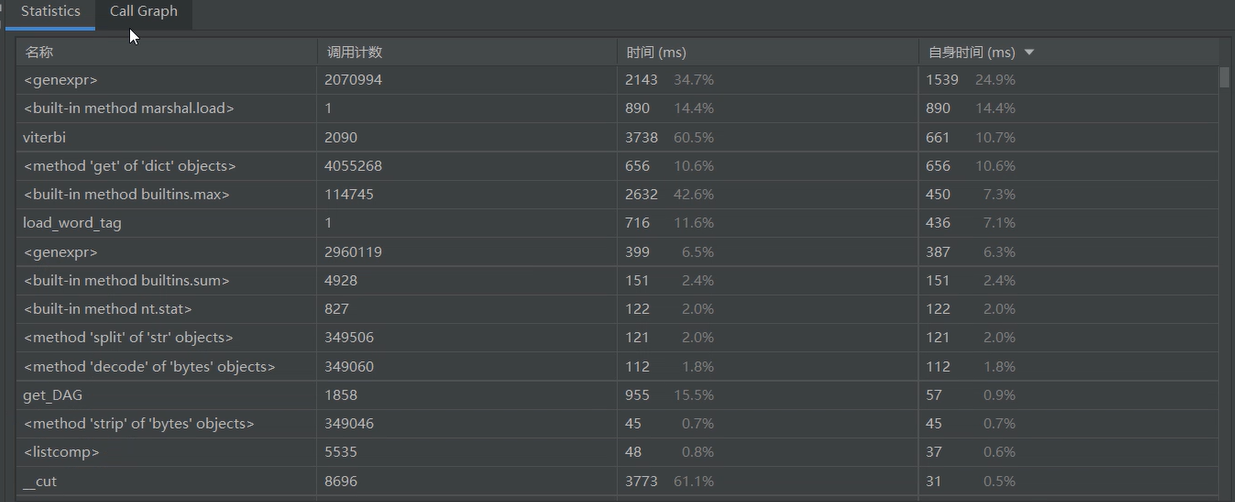
函数调用图如下:
最耗时的函数及其耗时:

main函数耗时竟然高达6秒Orz,或许可以通过消去标点或者优化代码等方法来提速吧(瞎猜Orz)
(2)空间
大佬们用的内存分析工具我暂时用不来,使用如下两行代码来分析内存的使用以及消耗的CPU时间(虽说上面已经在时间方面进行了测试,但是既然知道了这个方法,不如也用一下)
# 性能分析
print(u'当前进程的内存使用:%.4f MB' % (psutil.Process(os.getpid()).memory_info().rss / 1024 / 1024) )
print(u'当前进程的使用的CPU时间:%.4f s' % (psutil.Process(os.getpid()).cpu_times().user) )
运行结果如下:

很奇怪,为什么这里显示的时间就比profile分析出来的时间少多了,或许是因为这里计算的是进程占用的CPU时间而不是实际时间?
(3)代码覆盖率
使用coverage来进行测试:

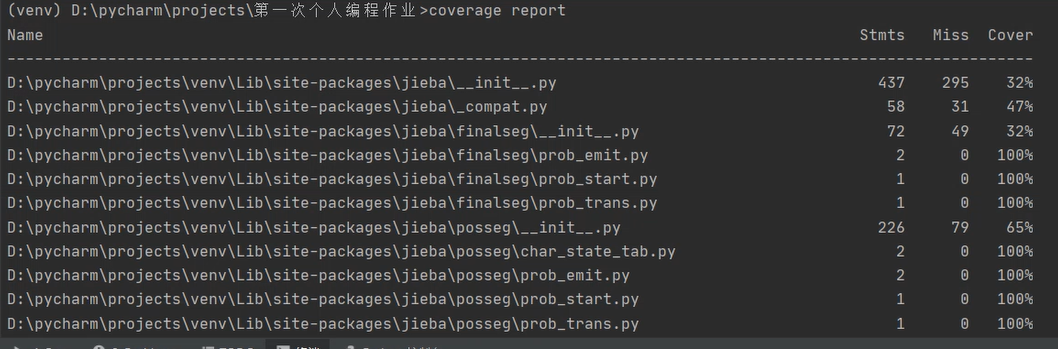

结果中列出了许多项,可以看到最后一行的main.py,其覆盖率为100% 。
二、计算模块接口部分的性能改进
前面已经说过,可以从去除停用词和标点、优化代码等方面来改进性能。由于种种原因(人太菜Orz,花在写代码方面的时间太少,用在解决各种小问题的时间太多),暂未改进。
三、计算模块部分单元测试展示
单元测试中使用的测试数据全部是测试组提供的样例数据。先亮出单元测试的结果:

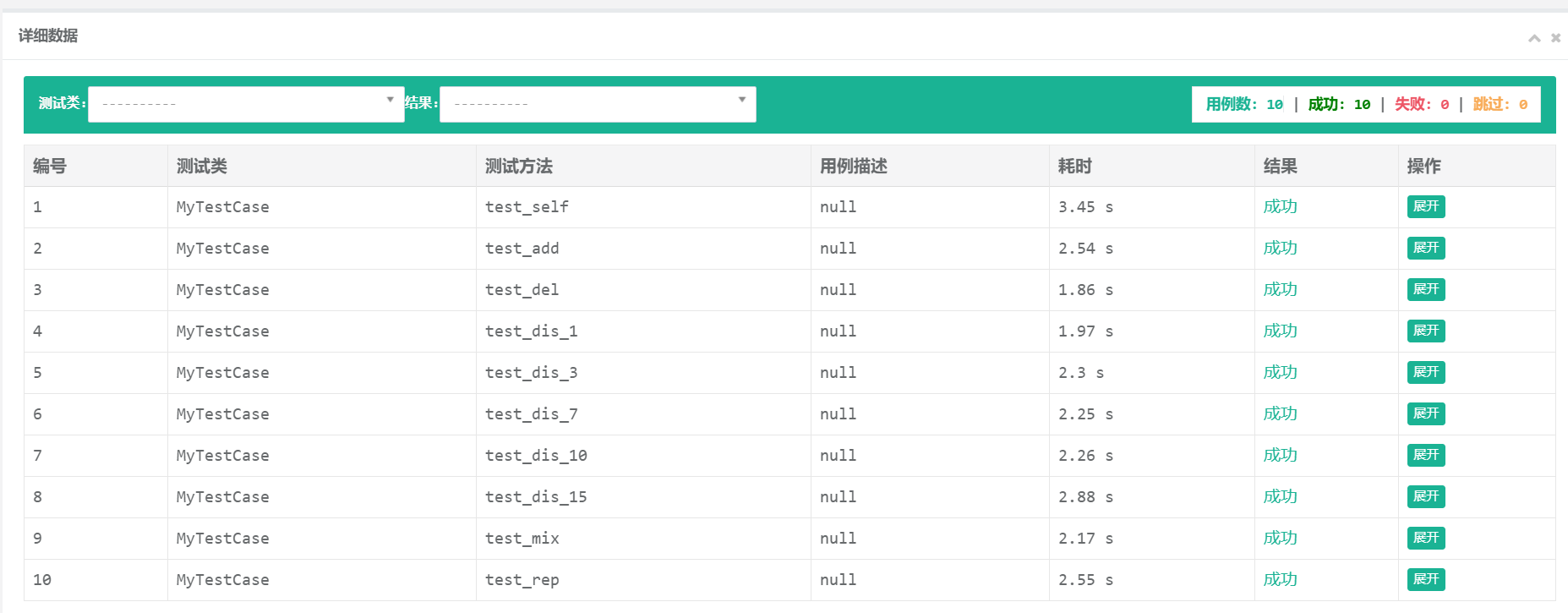
先前曾进行过测试,耗时一栏在8s左右,人都傻了。之后又进行了一次单元测试,测试结果的耗时在2s左右,猜测是因为计算机上的进程太多,导致单元测试用的时间较长。
单元测试代码
这里使用的是python自带的标准单元测试库——unittest库。看了大佬的博客后,我选择使用BeautifulReport报告库,可以生成html格式的测试结果报告。
Unittest-测试运行:查看测试结果
单元测试内部函数test_inside:
#!/usr/bin/env python3
# coding: utf-8
import jieba.posseg as pesg
import math
import numpy as np
import sys
import os
class SimVsm:
'''比较相似度'''
def distance(self, text1, text2):
words1 = [word.word for word in pesg.cut(text1) if word.flag[0] not in ['u', 'x', 'w']]
words2 = [word.word for word in pesg.cut(text2) if word.flag[0] not in ['u', 'x', 'w']]
tfidf_reps = self.tfidf_rep([words1, words2])
return self.cosine_sim(np.array(tfidf_reps[0]), np.array(tfidf_reps[1]))
'''对句子进行tfidf向量表示'''
def tfidf_rep(self, sents):
sent_list = []
df_dict = {}
tfidf_list = []
for sent in sents:
tmp = {}
for word in sent:
if word not in tmp:
tmp[word] = 1
else:
tmp[word] += 1
tmp = {word:word_count/sum(tmp.values()) for word, word_count in tmp.items()}
for word in set(sent):
if word not in df_dict:
df_dict[word] = 1
else:
df_dict[word] += 1
sent_list.append(tmp)
df_dict = {word :math.log(len(sents)/df+1) for word, df in df_dict.items()}
words = list(df_dict.keys())
for sent in sent_list:
tmp = []
for word in words:
tmp.append(sent.get(word, 0))
tfidf_list.append(tmp)
return tfidf_list
'''余弦相似度计算相似度'''
def cosine_sim(self, vector1, vector2):
cos1 = np.sum(vector1 * vector2)
cos21 = np.sqrt(sum(vector1 ** 2))
cos22 = np.sqrt(sum(vector2 ** 2))
similarity = cos1 / float(cos21 * cos22)
return similarity
def test(s_position, d_position, ans_position):
f1 = open(s_position, "rt", encoding = 'UTF-8')
f2 = open(d_position, "rt", encoding = 'UTF-8')
f3 = open(ans_position, "a+", encoding = 'UTF-8')
txt1 = f1.read()
txt2 = f2.read()
simer = SimVsm()
sim = simer.distance(txt1, txt2)
print('查重结果为%.2f'%sim)
f3.write("sim_0.8\orig.txt, ")
f3.write(d_position)
f3.write(str(" Similarity: %.2f"%sim)+'\n')
f1.close()
f2.close()
f3.close()
单元测试函数test_vsm:
import unittest
import test_inside
from BeautifulReport import BeautifulReport
class MyTestCase(unittest.TestCase):
def setUp(self):
print("开始单元测试:")
def tearDown(self):
print("测试结束")
def test_self(self):
print("正在载入orig.txt")
test_inside.test('sim_0.8\orig.txt', 'sim_0.8\orig.txt', 'ans.txt')
def test_add(self):
print("正在载入orig_0.8_add.txt")
test_inside.test('sim_0.8\orig.txt', 'sim_0.8\orig_0.8_add.txt', 'ans.txt')
def test_del(self):
print("正在载入orig_0.8_del.txt")
test_inside.test('sim_0.8\orig.txt', 'sim_0.8\orig_0.8_del.txt', 'ans.txt')
def test_dis_1(self):
print("正在载入orig_0.8_dis_1.txt")
test_inside.test('sim_0.8\orig.txt', 'sim_0.8\orig_0.8_dis_1.txt', 'ans.txt')
def test_dis_3(self):
print("正在载入orig_0.8_dis_3.txt")
test_inside.test('sim_0.8\orig.txt', 'sim_0.8\orig_0.8_dis_3.txt', 'ans.txt')
def test_dis_7(self):
print("正在载入orig_0.8_dis_7.txt")
test_inside.test('sim_0.8\orig.txt', 'sim_0.8\orig_0.8_dis_7.txt', 'ans.txt')
def test_dis_10(self):
print("正在载入orig_0.8_dis_10.txt")
test_inside.test('sim_0.8\orig.txt', 'sim_0.8\orig_0.8_dis_10.txt', 'ans.txt')
def test_dis_15(self):
print("正在载入orig_0.8_dis_15.txt")
test_inside.test('sim_0.8\orig.txt', 'sim_0.8\orig_0.8_dis_15.txt', 'ans.txt')
def test_mix(self):
print("正在载入orig_0.8_mix.txt")
test_inside.test('sim_0.8\orig.txt', 'sim_0.8\orig_0.8_mix.txt', 'ans.txt')
def test_rep(self):
print("正在载入orig_0.8_rep.txt")
test_inside.test('sim_0.8\orig.txt', 'sim_0.8\orig_0.8_rep.txt', 'ans.txt')
if __name__ == '__main__':
#unittest.main()
suite = unittest.TestSuite()
suite.addTest(MyTestCase('test_self'))
suite.addTest(MyTestCase('test_add'))
suite.addTest(MyTestCase('test_del'))
suite.addTest(MyTestCase('test_dis_1'))
suite.addTest(MyTestCase('test_dis_3'))
suite.addTest(MyTestCase('test_dis_7'))
suite.addTest(MyTestCase('test_dis_10'))
suite.addTest(MyTestCase('test_dis_15'))
suite.addTest(MyTestCase('test_mix'))
suite.addTest(MyTestCase('test_rep'))
runner = BeautifulReport(suite)
runner.report\
(
description = "论文查重单元测试报告", #报告描述
filename = 'sim_vsm.html', #生成的报告文件名
log_path = '.' #报告路径
)
测试覆盖率
使用coverage来进行测试:
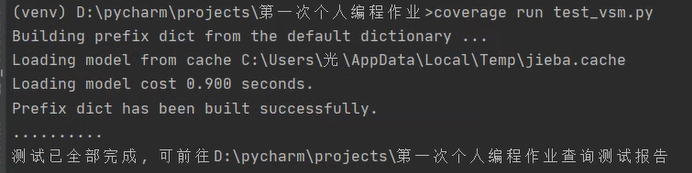
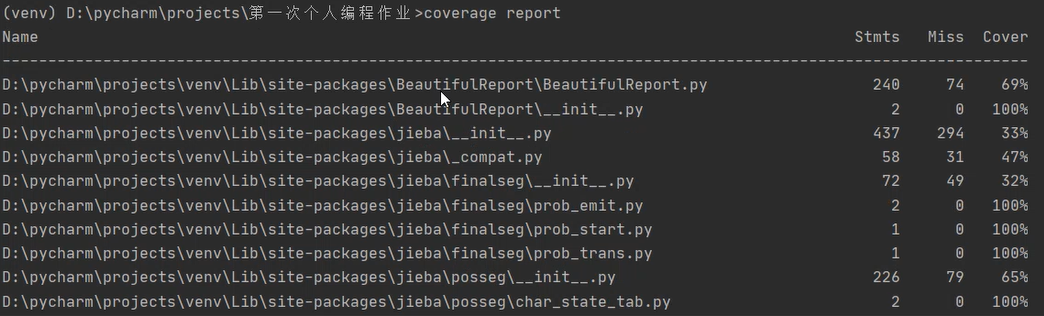

结果中列出了许多项,可以看到最后两行的test_inside.py和test_vsm.py,其覆盖率都为100% 。
四、计算模块部分异常处理
经过一番百度+看了大佬的博客后,发现计算模块可能出现异常的情况:空文本、无汉字文本等。
具体异常处理模块暂无Orz
五、PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 60 | 70 |
| · Estimate | · 估计这个任务需要多少时间 | 60 | 60 |
| Development | 开发 | 240 | 180 |
| · Analysis | · 需求分析 (包括学习新技术) | 900 | 1500 |
| · Design Spec | · 生成设计文档 | 60 | 50 |
| · Design Review | · 设计复审 | 30 | 20 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 30 | 20 |
| · Design | · 具体设计 | 240 | 180 |
| · Coding | · 具体编码 | 300 | 360 |
| · Code Review | · 代码复审 | 60 | 75 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 180 | 150 |
| Reporting | 报告 | 45 | 30 |
| · Test Report | · 测试报告 | 30 | 60 |
| · Size Measurement | · 计算工作量 | 30 | 15 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 60 | 90 |
| · 合计 | 2295 | 2860 |
六、总结
一次从零开始的编程体验,从一开始vscode都不会用,到最后勉强完成作业,尽管惨不忍睹,但还是学到了不少东西。程序成功运行时我天真地以为作业就快要完成了,但实事告诉我,这才完成了一小部分。性能测试、单元测试、异常处理、性能优化等等都是要面对的事。路漫漫其修远兮,吾将上下而求索。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号