linux文件系统初探--Day5
鸽了两天,下次还敢。😛
Day5的任务主要是学习dentry的相关知识。
dentry
还是先来看材料中总结的一些dentry基本要点:
- dentry存储在dcache中,dentry让内核可以根据文件路径名快速的找到相应的inode,不必做复杂的字符串匹配;
- 文件名的各个部分(父目录、父目录的父目录等等)组成一个dentry的分层结构;
- 由于硬链接的存在,一个文件inode可以对应多个dentry。
Day5中的samplefs中dentry操作的一些特点:
- 与大部分的文件系统不同,samplefs没有保存negative dentries,表示当前dentry对应的inode是NULL,已经被删除或者路径被修改;
- 如果文件系统通过其他机制(例如,网络或群集文件系统中的其他节点)导出相同的数据,则通常会导出d_revalidate,暂时不太懂;
- 不区分大小写。
dentry结构
当VFS和文件系统实现读取一个目录项的数据之后,就创建一个dentry实例缓存找到的数据。需要注意的是,只有最常用的文件和目录对应的目录项才保存在内存中,理论上可以为所有的文件系统对象生成dentry,但是内存空间和性能原因限制这样做。下面是dentry的结构,在dcache.h中:
struct dentry {
/* RCU lookup touched fields */
unsigned int d_flags; /* protected by d_lock */
seqcount_t d_seq; /* per dentry seqlock */
struct hlist_bl_node d_hash; /* lookup hash list */
struct dentry *d_parent; /* parent directory */
struct qstr d_name;
struct inode *d_inode; /* Where the name belongs to - NULL is
* negative */
unsigned char d_iname[DNAME_INLINE_LEN]; /* small names */
/* Ref lookup also touches following */
struct lockref d_lockref; /* per-dentry lock and refcount */
const struct dentry_operations *d_op;
struct super_block *d_sb; /* The root of the dentry tree */
unsigned long d_time; /* used by d_revalidate */
void *d_fsdata; /* fs-specific data */
union {
struct list_head d_lru; /* LRU list */
wait_queue_head_t *d_wait; /* in-lookup ones only */
};
struct list_head d_child; /* child of parent list */
struct list_head d_subdirs; /* our children */
/*
* d_alias and d_rcu can share memory
*/
union {
struct hlist_node d_alias; /* inode alias list */
struct hlist_bl_node d_in_lookup_hash; /* only for in-lookup ones */
struct rcu_head d_rcu;
} d_u;
} __randomize_layout;
dentry的主要用途是建立文件名与对应inode的映射,dentry中主要使用三个成员完成这个功能:
- d_inode:指向关联的inode,如果d_inode为NULL,表示dentry是negative的,即inode被删除或文件路径已被改变;
- d_name:指向文件名称,qstr(quick string)是一个保存字符串和字符串hash值的结构体,这里只存储绝对路径的最后一个分量;
- d_iname:当文件名长度较短时,指向文件名称,加速访问。
DNAME_NAME_LEN根据字长以及是否配置SMP确定具体的数值,尝试使dentry在64字节的cache行上对齐(这将在较大的行中提供合理的cache行占用空间,而不会增加较大的内存占用)。
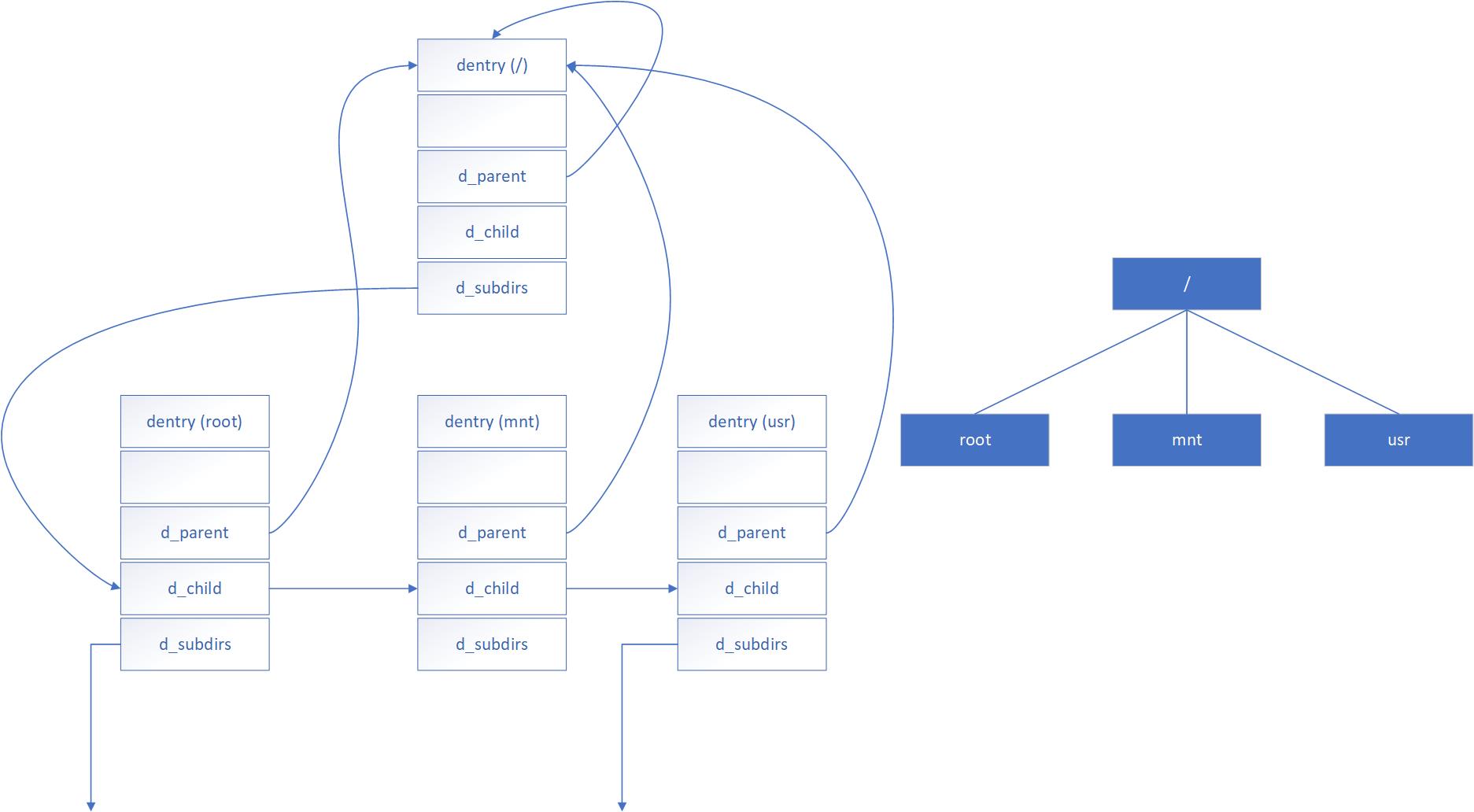
上图是dentry网络组织的一个示意图,其中d_subdirs指向子目录或文件的链表,d_parent指向当前dentry的父目录的dentry实例,根目录的d_parent指向本身的dentry实例,子节点的d_child充当链表元素。
所有的dentry活动实例都保存在一个hash表中,在fs/dcache.c中的dentry_hashtable实现,还有一个链表用来保存那些unused的dentry,指d_count为零,但是d_inode指向的inode仍有效。
关于缓存的组织可以参看LKD_VFS那篇博客。
dentry操作
dentry_operations定义如下:
struct dentry_operations {
int (*d_revalidate)(struct dentry *, unsigned int);
int (*d_weak_revalidate)(struct dentry *, unsigned int);
int (*d_hash)(const struct dentry *, struct qstr *);
int (*d_compare)(const struct dentry *,
unsigned int, const char *, const struct qstr *);
int (*d_delete)(const struct dentry *);
int (*d_init)(struct dentry *);
void (*d_release)(struct dentry *);
void (*d_prune)(struct dentry *);
void (*d_iput)(struct dentry *, struct inode *);
char *(*d_dname)(struct dentry *, char *, int);
struct vfsmount *(*d_automount)(struct path *);
int (*d_manage)(const struct path *, bool);
struct dentry *(*d_real)(struct dentry *, const struct inode *);
} ____cacheline_aligned;
需要指出的是,大多数文件系统并未实现这些函数,在内核中,对于这些实现为NULL的函数,会自动替换为VFS的默认实现(dcache.c)。下面分别解释这几个接口:
- d_iput:从一个unused的dentry中释放inode;
- 在d_count为0时,调用d_delete;
- 删除最后一个dentry实例后,调用d_release;
- d_hash计算hash值;
- d_compare比较两个dentry的文件名,文件系统可以替换其实现,满足个性化的需求;
- d_revalidate对于那些网络文件系统来说十分重要,用来检查内存中各个dentry对象构成的结构是否仍然有效。用来保证网络文件系统一致性,因此本地文件系统一般来说不会出现这样的需求。
标准函数
内核提供了一些标准函数,简化了dentry对象的处理。这里只讲述一些常见函数的效果:
- dget:每当内核的某个部分需要使用一个dentry实例时,调用dget,会将dentry的d_count加一;
- dput:dget的对偶函数,调用会使引用计数减1;
- d_drop:将一个dentry从dentry_hashtable中移除;
- d_delete:在确认dentry对象仍在dentry_hashtable中后,使用__d_drop将其移除,一般在dput之前使用,保证dput删除了dentry对象。
还有一些比较复杂的辅助函数,可以查看其文档和相关资料。
源码分析
这部分的代码原本应该是在2.4左右的内核版本下实现的,今天的部分代码都比较简单,修改成当前版本内核使用的API即可。全部源码如下:
/*
* fs/samplefs/super.c
*
* Copyright (C) International Business Machines Corp., 2006, 2007
* Author(s): Steve French (sfrench@us.ibm.com)
*
* Sample File System
*
* Primitive example to show how to create a Linux filesystem module
*
* superblock related and misc. functions
*
* This library is free software; you can redistribute it and/or modify
* it under the terms of the GNU Lesser General Public License as published
* by the Free Software Foundation; either version 2.1 of the License, or
* (at your option) any later version.
*
* This library is distributed in the hope that it will be useful,
* but WITHOUT ANY WARRANTY; without even the implied warranty of
* MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See
* the GNU Lesser General Public License for more details.
*
* You should have received a copy of the GNU Lesser General Public License
* along with this library; if not, write to the Free Software
* Foundation, Inc., 59 Temple Place, Suite 330, Boston, MA 02111-1307 USA
*/
#include <linux/module.h>
#include <linux/fs.h>
#include <linux/pagemap.h>
#include <linux/version.h>
#include <linux/nls.h>
#include <linux/proc_fs.h>
#include <linux/slab.h>
#include <linux/ktime.h>
#include <linux/timekeeping.h>
#include <linux/seq_file.h>
#include "samplefs.h"
/* helpful if this is different than other fs */
#define SAMPLEFS_MAGIC 0x73616d70 /* "SAMP" */
unsigned int sample_parm = 0;
module_param(sample_parm, int, 0);
MODULE_PARM_DESC(sample_parm, "An example parm. Default: x Range: y to z");
static void
samplefs_put_super(struct super_block *sb)
{
struct samplefs_sb_info *sfs_sb;
sfs_sb = SFS_SB(sb);
if (sfs_sb == NULL) {
/* Empty superblock info passed to unmount */
return;
}
unload_nls(sfs_sb->local_nls);
/* FS-FILLIN your fs specific umount logic here */
kfree(sfs_sb);
return;
}
struct super_operations samplefs_super_ops = {
.statfs = simple_statfs,
.drop_inode = generic_delete_inode, /* Not needed, is the default */
.put_super = samplefs_put_super,
};
static void
samplefs_parse_mount_options(char *options, struct samplefs_sb_info *sfs_sb)
{
char *value;
char *data;
int size;
if (!options)
return;
printk(KERN_INFO "samplefs: parsing mount options %s\n", options);
while ((data = strsep(&options, ",")) != NULL) {
if (!*data)
continue;
if ((value = strchr(data, '=')) != NULL)
*value++ = '\0';
if (strncasecmp(data, "rsize", 5) == 0) {
if (value && *value) {
size = simple_strtoul(value, &value, 0);
if (size > 0) {
sfs_sb->rsize = size;
printk(KERN_INFO
"samplefs: rsize %d\n", size);
}
}
} else if (strncasecmp(data, "wsize", 5) == 0) {
if (value && *value) {
size = simple_strtoul(value, &value, 0);
if (size > 0) {
sfs_sb->wsize = size;
printk(KERN_INFO
"samplefs: wsize %d\n", size);
}
}
} else if ((strncasecmp(data, "nocase", 6) == 0) ||
(strncasecmp(data, "ignorecase", 10) == 0)) {
sfs_sb->flags |= SFS_MNT_CASE;
printk(KERN_INFO "samplefs: ignore case\n");
} else {
printk(KERN_WARNING "samplefs: bad mount option %s\n",
data);
}
}
}
static int sfs_ci_hash(const struct dentry *dentry, struct qstr *q)
{
struct nls_table *codepage = SFS_SB(dentry->d_inode->i_sb)->local_nls;
unsigned long hash;
int i;
// hash = init_name_hash(hash);
for (i = 0; i < q->len; i++)
hash = partial_name_hash(nls_tolower(codepage, q->name[i]),
hash);
q->hash = end_name_hash(hash);
return 0;
}
static int sfs_ci_compare(const struct dentry *dentry, unsigned int len,
const char *name, const struct qstr *a)
{
struct nls_table *codepage = SFS_SB(dentry->d_inode->i_sb)->local_nls;
if ((a->len == len) &&
(nls_strnicmp(codepage, a->name, name, len) == 0)) {
/*
* To preserve case, don't let an existing negative dentry's
* case take precedence. If a is not a negative dentry, this
* should have no side effects
*/
memcpy((unsigned char *)a->name, name, len);
return 0;
}
return 1;
}
/* No sense hanging on to negative dentries as they are only
in memory - we are not saving anything as we would for network
or disk filesystem */
static int sfs_delete_dentry(const struct dentry *dentry)
{
return 1;
}
static const struct dentry_operations sfs_ci_dentry_ops = {
/* .d_revalidate = xxxd_revalidate, Not needed for this type of fs */
.d_hash = sfs_ci_hash,
.d_compare = sfs_ci_compare,
.d_delete = sfs_delete_dentry,
};
/*
* Lookup the data, if the dentry didn't already exist, it must be
* negative. Set d_op to delete negative dentries to save memory
* (and since it does not help performance for in memory filesystem).
*/
static struct dentry *sfs_lookup(struct inode *dir, struct dentry *dentry, unsigned int len)
{
if (dentry->d_name.len > NAME_MAX)
return ERR_PTR(-ENAMETOOLONG);
dentry->d_op = &sfs_ci_dentry_ops;
d_add(dentry, NULL);
return NULL;
}
static struct inode_operations sfs_ci_inode_ops = {
.lookup = sfs_lookup,
};
static struct inode *samplefs_get_inode(struct super_block *sb, int mode, dev_t dev)
{
struct inode * inode = new_inode(sb);
struct timespec64 ts;
struct samplefs_sb_info * sfs_sb = SFS_SB(sb);
if (inode) {
inode->i_mode = mode;
inode->i_uid = current->cred->fsuid;
inode->i_gid = current->cred->fsgid;
inode->i_blocks = 0;
ktime_get_ts64(&ts);
inode->i_atime = inode->i_mtime = inode->i_ctime = ts;
printk(KERN_INFO "about to set inode ops\n");
switch (mode & S_IFMT) {
default:
init_special_inode(inode, mode, dev);
break;
/* We are ready to handle files yet */
case S_IFREG:
printk(KERN_INFO "file inode\n");
inode->i_op = &simple_dir_inode_operations;
break;
case S_IFDIR:
printk(KERN_INFO "directory inode sfs_sb: %p\n",sfs_sb);
if (sfs_sb->flags & SFS_MNT_CASE)
inode->i_op = &sfs_ci_inode_ops;
else
inode->i_op = &simple_dir_inode_operations;
/* link == 2 (for initial ".." and "." entries) */
inode->__i_nlink++;
break;
}
}
return inode;
}
static int samplefs_fill_super(struct super_block * sb, void * data, int silent)
{
struct inode * inode;
struct samplefs_sb_info * sfs_sb;
sb->s_maxbytes = MAX_LFS_FILESIZE; /* NB: may be too large for mem */
sb->s_blocksize = PAGE_SIZE;
sb->s_blocksize_bits = PAGE_SHIFT;
sb->s_magic = SAMPLEFS_MAGIC;
sb->s_op = &samplefs_super_ops;
sb->s_time_gran = 1; /* 1 nanosecond time granularity */
printk(KERN_INFO "samplefs: fill super\n");
#ifdef CONFIG_SAMPLEFS_DEBUG
printk(KERN_INFO "samplefs: about to alloc s_fs_info\n");
#endif
sb->s_fs_info = kzalloc(sizeof(struct samplefs_sb_info),GFP_KERNEL);
sfs_sb = SFS_SB(sb);
if (!sfs_sb) {
return -ENOMEM;
}
inode = samplefs_get_inode(sb, S_IFDIR | 0755, 0);
if (!inode) {
kfree(sfs_sb);
return -ENOMEM;
}
printk(KERN_INFO "samplefs: about to alloc root inode\n");
sb->s_root = d_make_root(inode);
if (!sb->s_root) {
iput(inode);
kfree(sfs_sb);
return -ENOMEM;
}
/* below not needed for many fs - but an example of per fs sb data */
sfs_sb->local_nls = load_nls_default();
samplefs_parse_mount_options(data, sfs_sb);
/* FS-FILLIN your filesystem specific mount logic/checks here */
return 0;
}
struct dentry *samplefs_mount(struct file_system_type *fs_type,
int flags, const char *dev_name, void *data)
{
return mount_nodev(fs_type, flags, data, samplefs_fill_super);
}
static struct file_system_type samplefs_fs_type = {
.owner = THIS_MODULE,
.name = "samplefs",
.mount = samplefs_mount,
.kill_sb = kill_anon_super,
/* .fs_flags */
};
#ifdef CONFIG_PROC_FS
static struct proc_dir_entry *proc_fs_samplefs;
static int samplefs_debug_open(struct seq_file *file, void *v)
{
seq_printf(file, "===================Debug Info====================\n");
return 0;
}
static int samplefs_proc_open(struct inode *inode, struct file *file)
{
return single_open(file, samplefs_debug_open, NULL);
}
static const struct file_operations samplefs_proc_fops = {
.owner = THIS_MODULE,
.read = seq_read,
.llseek = seq_lseek,
//.write = seq_write,
.open = samplefs_proc_open,
.release = seq_release,
};
void
sfs_proc_init(void)
{
proc_fs_samplefs = proc_mkdir("fs/samplefs", NULL);
if (proc_fs_samplefs == NULL)
return;
proc_create("DebugData", 0, proc_fs_samplefs, &samplefs_proc_fops);
}
void
sfs_proc_clean(void)
{
if (proc_fs_samplefs == NULL)
return;
remove_proc_entry("DebugData", proc_fs_samplefs);
remove_proc_entry("fs/samplefs", NULL);
}
#endif /* CONFIG_PROC_FS */
static int __init init_samplefs_fs(void)
{
printk(KERN_INFO "init samplefs\n");
#ifdef CONFIG_PROC_FS
sfs_proc_init();
#endif
/* some filesystems pass optional parms at load time */
if (sample_parm > 256) {
printk(KERN_ERR "sample_parm %d too large, reset to 10\n",
sample_parm);
sample_parm = 10;
}
return register_filesystem(&samplefs_fs_type);
}
static void __exit exit_samplefs_fs(void)
{
printk(KERN_INFO "unloading samplefs\n");
#ifdef CONFIG_PROC_FS
sfs_proc_clean();
#endif
unregister_filesystem(&samplefs_fs_type);
}
module_init(init_samplefs_fs)
module_exit(exit_samplefs_fs)
MODULE_LICENSE("GPL");
参考资料
linux2.4内核 path_walk流程简析
《深入Linux内核架构》--第八章 8.3 目录项缓存

