【NQG】Paragraph-level Neural Question Generation with Maxout Pointer and Gated Self-attention Networks论文笔记
这篇文章主要处理了在问题生成(Question Generation,QG)中,长文本(多为段落)在seq2seq模型中表现不佳的问题。长文本在生成高质量问题方面不可或缺。
1. Introduction
QG可以让对话系统更积极主动,也可以生成更多的问题来丰富QA(Question Answering)系统,同时在教育领域的阅读理解方面也有应用。
QG主要分为rule-based和neural approach:
-
rule-based:可以看作是一个fill-and-rank模型,提取目的句子的相关实体,填入人工编写的模板中,再根据rank方法选择一个或几个最合适的。优点是很流畅,缺点是很依赖人工模板,很难做到open-domain。
-
neural approach:一般是改良的seq2seq模型。传统的encoder-decoder框架。
这篇文章针对的是answer-aware问题,即生成问题的答案显式得出现在给定文本的一部分或者几部分中。
针对段落生成的主要难点在于如何处理段落中的信息,即如何挑选出适合于生成问题的信息。
本文主要提出了一个改进的seq2seq模型,加入了maxout pointer机制和gated self-attention encoder。在之后的研究中可以通过加入更多feature或者policy gradient等强化学习的方式提升模型性能。
2. Model
2.1 question definition
其中\(\overline Q\)代表生成的问题,\(P\)代表整个段落,\(A\)代表已知的答案。\(P\),\(A\)以及\(\overline Q\)中的单词均来自于词典。
2.2 Passage and Answer Encoding
本文中使用了双向RNN来进行encode。
- Answer Tagging:
在上式中,\({u_t}\)表示RNN的hidden state,\({e_t}\)表示word embedding,\({m_t}\)表示这个词是否在answer中。\([{e_t},{m_t}]\)表示把这两个向量拼接起来。因为我们要生成跟答案相关的问题,所以这种思路也是比较自然的。
-
Gated Self-Attention:
这里的大部分思想与Gated Self-Matching Networks for Reading Comprehension and Question Answering这篇文章中关于gated attention-based以及self matching的论述类似。
门控自注意力机制主要解决以下问题:
-
聚合段落信息
-
嵌入(embed)段落内部的依赖关系,在每一时间步中优化P和A的嵌入表示。
主要步骤如下:
- 计算self matching
其中,\({a^s}_t\)是段落中所有encode的单词对当前\(t\)时刻所对应单词的之间的依赖关系的系数,注意,\(U\)表示从1到最后时刻所有的hidden state组成的矩阵,即表示passage-answer;\({s_t}\)表示段落中所有encode的单词对当前\(t\)时刻所对应单词的之间的依赖关系,也是self matching的表示。
【个人理解】:这里类似于self-attention,主要目的是刻画段落中不同单词对于生成问题的重要性(相关性),越相关的值越大,否则越小。
- 计算gated attention
其中,\({f_t}\)表示新的包含self matching信息的passage-answer表示,\({g_t}\)表示一个可学习的门控单元,最后,\({\hat u_t}\)表示新的passage-answer表示,用来喂给decoder。
【个人理解】:gated attention可以专注于answer与当前段落之间的关系。
2.3 Decoding with Attention and Maxout Pointer
使用RNN
注意此处的\(y_t\)不作为最后的输出,还要经过一系列操作。
- Attention:
用Attention得到一个新的decoder state
- Copy Mechanism:
\(F{D_t}^{gen}\)表示在t时刻生成新单词的final distrubution,\(F{D_t}^{copy}\)表示在t时刻copy单词的final distrubution。
这里的\({{\hat y}_t}\)表示在index,相应的代表gen词表中或者copy词表(所有input的单词)中的单词index。
- Maxout Pointer:
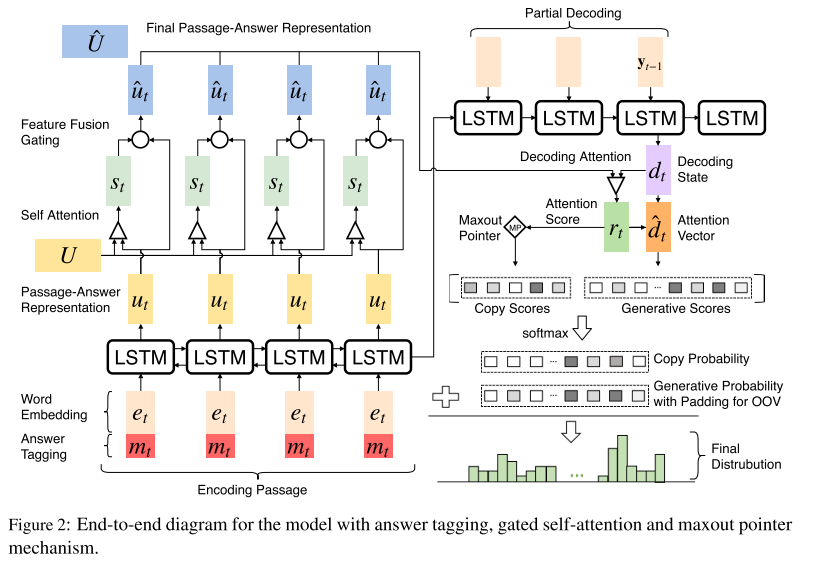
注意:encoder部分的下标有误,不应全为\(t\),应从\({u_1}\)递增至\({u_M}\)
PS:gated attention,self matching以及copy mechanism的解释还没有搞清楚,仅仅知道怎么处理。

