前端HTML5几种存储方式的总结
接下来要好好总结一些知识,秋招来啦。。。虽然有好多知识都不大会,但是还是要努力一下,运气这种东西,谁知道呢~
总体情况

if(window.localStorage){
alert('This browser supports localStorage');
}else{
alert('This browser does NOT support localStorage');
}
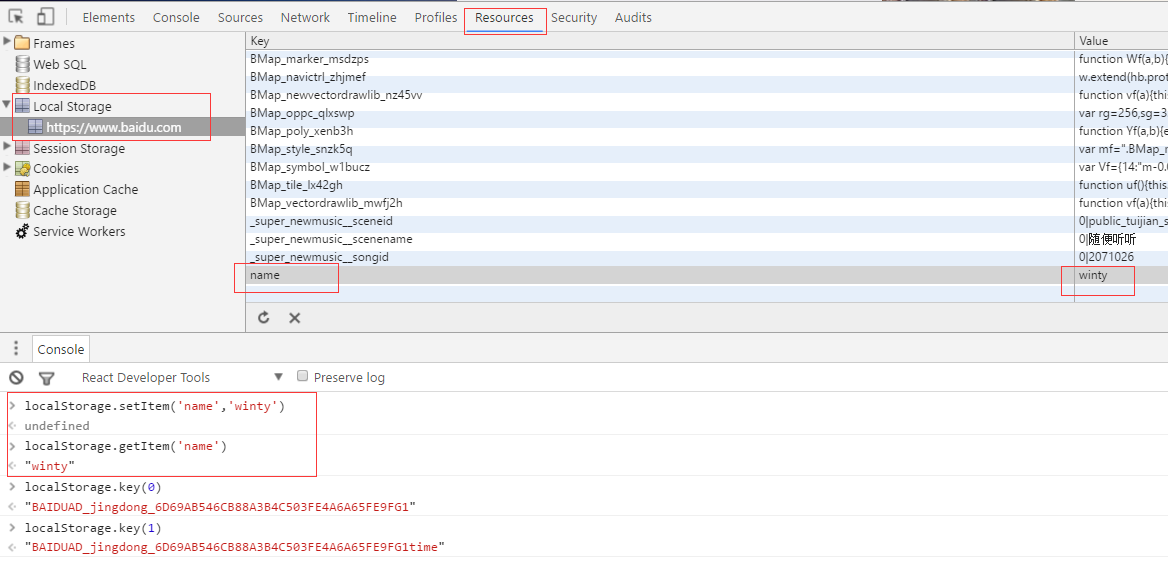
getItem //取记录
setIten//设置记录
removeItem//移除记录
key//取key所对应的值
clear//清除记录
存储的内容:
数组,图片,json,样式,脚本。。。(只要是能序列化成字符串的内容都可以存储)
<!DOCTYPE HTML> <html manifest="demo.appcache"> ... </html>
Manifest 文件:
manifest 文件是简单的文本文件,它告知浏览器被缓存的内容(以及不缓存的内容)。
manifest 文件可分为三个部分:
①CACHE MANIFEST - 在此标题下列出的文件将在首次下载后进行缓存
②NETWORK - 在此标题下列出的文件需要与服务器的连接,且不会被缓存
③FALLBACK - 在此标题下列出的文件规定当页面无法访问时的回退页面(比如 404 页面)
完整demo:
CACHE MANIFEST # 2016-07-24 v1.0.0 /theme.css /main.js NETWORK: login.jsp FALLBACK: /html/ /offline.html
服务器上:manifest文件需要配置正确的MIME-type,即 "text/cache-manifest"。
如Tomcat:
<mime-mapping>
<extension>manifest</extension>
<mime-type>text/cache-manifest</mime-type>
</mime-mapping>
常用API:
核心是applicationCache对象,有个status属性,表示应用缓存的当前状态:
0(UNCACHED) : 无缓存, 即没有与页面相关的应用缓存
1(IDLE) : 闲置,即应用缓存未得到更新
2 (CHECKING) : 检查中,即正在下载描述文件并检查更新
3 (DOWNLOADING) : 下载中,即应用缓存正在下载描述文件中指定的资源
4 (UPDATEREADY) : 更新完成,所有资源都已下载完毕
5 (IDLE) : 废弃,即应用缓存的描述文件已经不存在了,因此页面无法再访问应用缓存
相关的事件:
表示应用缓存状态的改变:
checking : 在浏览器为应用缓存查找更新时触发
error : 在检查更新或下载资源期间发送错误时触发
noupdate : 在检查描述文件发现文件无变化时触发
downloading : 在开始下载应用缓存资源时触发
progress:在文件下载应用缓存的过程中持续不断地下载地触发
updateready : 在页面新的应用缓存下载完毕触发
cached : 在应用缓存完整可用时触发
Application Cache的三个优势:
① 离线浏览
② 提升页面载入速度
③ 降低服务器压力
注意事项:
1. 浏览器对缓存数据的容量限制可能不太一样(某些浏览器设置的限制是每个站点 5MB)
2. 如果manifest文件,或者内部列举的某一个文件不能正常下载,整个更新过程将视为失败,浏览器继续全部使用老的缓存
3. 引用manifest的html必须与manifest文件同源,在同一个域下
4. 浏览器会自动缓存引用manifest文件的HTML文件,这就导致如果改了HTML内容,也需要更新版本才能做到更新。
5. manifest文件中CACHE则与NETWORK,FALLBACK的位置顺序没有关系,如果是隐式声明需要在最前面
6. FALLBACK中的资源必须和manifest文件同源
7. 更新完版本后,必须刷新一次才会启动新版本(会出现重刷一次页面的情况),需要添加监听版本事件。
8. 站点中的其他页面即使没有设置manifest属性,请求的资源如果在缓存中也从缓存中访问
9. 当manifest文件发生改变时,资源请求本身也会触发更新
离线缓存与传统浏览器缓存区别:
1. 离线缓存是针对整个应用,浏览器缓存是单个文件
2. 离线缓存断网了还是可以打开页面,浏览器缓存不行
3. 离线缓存可以主动通知浏览器更新资源
核心方法:
①openDatabase:这个方法使用现有的数据库或者新建的数据库创建一个数据库对象。
②transaction:这个方法让我们能够控制一个事务,以及基于这种情况执行提交或者回滚。
③executeSql:这个方法用于执行实际的 SQL 查询。
打开数据库:
var db = openDatabase('mydb', '1.0', 'Test DB', 2 * 1024 * 1024,fn);
//openDatabase() 方法对应的五个参数分别为:数据库名称、版本号、描述文本、数据库大小、创建回调
执行查询操作:
var db = openDatabase('mydb', '1.0', 'Test DB', 2 * 1024 * 1024);
db.transaction(function (tx) {
tx.executeSql('CREATE TABLE IF NOT EXISTS WIN (id unique, name)');
});
插入数据:
var db = openDatabase('mydb', '1.0', 'Test DB', 2 * 1024 * 1024);
db.transaction(function (tx) {
tx.executeSql('CREATE TABLE IF NOT EXISTS WIN (id unique, name)');
tx.executeSql('INSERT INTO WIN (id, name) VALUES (1, "winty")');
tx.executeSql('INSERT INTO WIN (id, name) VALUES (2, "LuckyWinty")');
});
读取数据:
db.transaction(function (tx) {
tx.executeSql('SELECT * FROM WIN', [], function (tx, results) {
var len = results.rows.length, i;
msg = "<p>查询记录条数: " + len + "</p>";
document.querySelector('#status').innerHTML += msg;
for (i = 0; i < len; i++){
alert(results.rows.item(i).name );
}
}, null);
});
由这些操作可以看出,基本上都是用SQL语句进行数据库的相关操作,如果你会MySQL的话,这个应该比较容易用。
function closeDB(db){
db.close();
}
function deleteDB(name){
indexedDB.deleteDatabase(name);
}
数据存储:
indexedDB中没有表的概念,而是objectStore,一个数据库中可以包含多个objectStore,objectStore是一个灵活的数据结构,可以存放多种类型数据。也就是说一个objectStore相当于一张表,里面存储的每条数据和一个键相关联。
我们可以使用每条记录中的某个指定字段作为键值(keyPath),也可以使用自动生成的递增数字作为键值(keyGenerator),也可以不指定。选择键的类型不同,objectStore可以存储的数据结构也有差异。
这个就有点复杂了。看这里的教程:
1.http://www.cnblogs.com/dolphinX/p/3415761.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号