
特征工程处理
1、不均衡样本的处理方法即评价指标
当样本中正负样本相差悬殊时,单纯使用某一分类器分类或者准使用确率作为评价指标将使得模型在预测时不再work
因此会做一些处理,包括:
正样本>>负样本,且样本数量较大,则采用下采样或者欠采样,对小样本过采样,对大样本欠采样
正样本<<负样本,且样本数量不大,则可以
(1)尝试采集更多的数据
(2)过采样(比如图像里的旋转、镜像之类的)
(3)修改loss function
此外还有:
对小类错分进行加权惩罚:
分治,将大样本分到L个聚类中,每一类与小样本训练得到一分类器,L个分类器取平均或者投票
分层:
1、数值型的离散化
将连续的数值划分为多个区间,比如让座问题,判断一个人的年龄小于6岁或者大于60岁,让座,这时只用一个公式不能满足两头的情况,因为函数是单调的
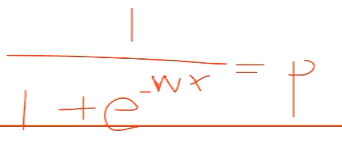 ,因此将一列的年龄值分为3列,分别为区间0-6岁,6-60岁和60岁+,在把新的每一列当成一个特征去学习参数。
,因此将一列的年龄值分为3列,分别为区间0-6岁,6-60岁和60岁+,在把新的每一列当成一个特征去学习参数。
离散化,分箱或者分桶,树模型不需要离散化,像逻辑回归神经网络之类的需要离散化
padans里面的cut和qcut
2、类别型数据的处理
(1)one-hot编码
(2)哑变量
(3)Hash与聚类处理
归一化对行做处理,标准化对列做处理
(4)统计每个类别变量下各个target比例,转成数值型
3、文本类型数据处理
(1)词袋模型,不包含顺序信息,比如李雷喜欢韩梅梅跟韩梅梅喜欢李雷,表达不出来
(2)n-gram模型,处了词的信息还包含了顺序信息,比如 'Welcome to beijing' ---> 'Welcom', 'to', 'beijing', 'Welcom to', 'to beijing',2-gram两两相连
(3)TF-IDF,上述模型只统计频次,没能把词的重要性表达出来,一个词的重要程度随着在文档中出现的频率增加而增大,随着词在整个语料库中出现的次数的增
加而降低
(4)Word2Vec,与n-gram不同,将句子映射成稠密的向量
4、特征选择和降维
特征选择是去掉原来的特征向量中和结果关系不大的特征
(1)过滤型:评估单个特征跟结果之间的相关程度,如Pearson相关度、互信息等,缺点是没有考虑到特征之间的关联作用,有可能将有用的信息提出掉。
sklearn中的SelectKBest
(2)包裹型:典型的有递归特征删除法,sklearn中的RFE

(3)嵌入型:一般使用L1正则化+LR/Linear SVR。L1正则化会得到稀疏解,那些不重要的特征被丢弃,天然的具有特征选择功能
降维是做特征的计算组合成新的特征,PCA或者SVD一定程度上可以解决高纬度问题
5、

 浙公网安备 33010602011771号
浙公网安备 33010602011771号