因子分解机(FM)
1. FM算法
FM(Factor Machine,因子分解机)算法是一种基于矩阵分解的机器学习算法,为了解决大规模稀疏数据中的特征组合问题。FM算法是推荐领域被验证效果较好的推荐算法之一,在电商、广告、直播等推荐领域有广泛应用。
2. FM算法优势
特征组合:通过对两两特征组合,引入交叉项特征。
解决维数灾难:通过引入隐向量,实现对特征的参数估计。
3. FM表达式
对于度为2的因子分解机FM的模型为:
 其中,参数
其中,参数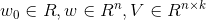 。
。  表示的是两个大小为
表示的是两个大小为 的向量
的向量 和向量
和向量 的点积:
的点积:
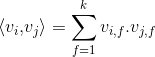
其中,表示的是系数矩阵 的第
的第 维向量,且
维向量,且 称为超参数。在因子分解机FM模型中,前面两部分是传统的线性模型,最后一部分将两个互异特征分量之间的交叉关系考虑进来。
称为超参数。在因子分解机FM模型中,前面两部分是传统的线性模型,最后一部分将两个互异特征分量之间的交叉关系考虑进来。
因子分解机也可以推广到高阶的形式,即将更多互异特征分量之间的相互关系考虑进来。
4. 交叉项

算法核心为交叉项计算,可以明显降低模型时间复杂度,现在模型的复杂度为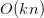 。
。
5. 求解问题
FM算法主要可以处理三类问题:回归问题、二分类问题、排序。
5.1 回归问题
在回归问题中,直接使用 作为最终的预测结果。在回归问题中使用最小均方误差作为优化标准,即
作为最终的预测结果。在回归问题中使用最小均方误差作为优化标准,即

其中, 表示样本的个数。
表示样本的个数。
5.2 二分类问题
在二分类问题中使用Logitloss作为优化标准,即

其中, 表示的是阶跃函数Sigmoid,其数学表达式为:
表示的是阶跃函数Sigmoid,其数学表达式为:

6. FM&SVM
SVM的二元特征交叉参数是独立的,而FM的二元特征交叉参数是两个维的向量,交叉参数并不独立,两者相互影响。
FM可以在原始形式下进行优化学习,而基于核的非线性SVM通常需要在对偶形式下优化学习。
FM的模型预测与训练样本独立,而SVM则与训练样本有关(支持向量)。
7. 交叉项核心代码
1 v = normalvariate(0, 0.2) * ones((n, k)) #初始化隐向量 2 inter_1 = dataMatrix[x] * v 3 inter_2 = multiply(dataMatrix[x], dataMatrix[x]) * multiply(v, v) #multiply对应元素相乘 4 interaction = sum(multiply(inter_1, inter_1) - inter_2) / 2. #完成交叉项 5 p = w_0 + dataMatrix[x] * w + interaction #计算预测的输出
Time : 2019-10-14 09:39:44

 浙公网安备 33010602011771号
浙公网安备 33010602011771号