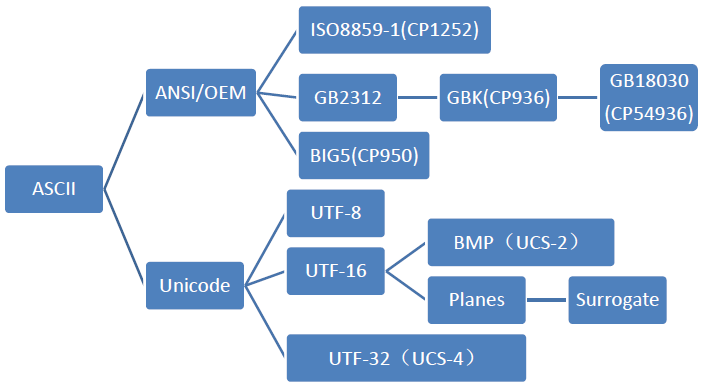
字符编码
字符集(Charcater Set 或 Charset):是一个系统支持的所有抽象字符的集合,也就是一系列字符的集合。字符是各种文字和符号的总称,包括各国家文字、标点符号、图形符号、数字等。常见的字符集有: ASCII 字符集、GB2312 字符集(主要用于处理中文汉字)、GBK 字符集(主要用于处理中文汉字)、Unicode 字符集等。
字符编码(Character Encoding):是一套法则,使用该法则能够对自然语言的字符的一个字符集(如字母表或音节表),与计算机能识别的二进制数字进行配对。即它能在符号集合与数字系统之间建立对应关系,是信息处理的一项基本技术。通常人们用符号集合(一般情况下就是文字)来表达信息,而计算机的信息处理系统则是以二进制的数字来存储和处理信息的。字符编码就是将符号转换为计算机能识别的二进制编码。
一般一个字符集等同于一个编码方式,如 ASCII、ISO 8859-1、GB2312、 GBK 等等都是如此。
一个字符集上也可以有多种编码方式,例如Unicode字符集上有 UTF-8、UTF-16、UTF-32 等编码方式。
(American Standard Code for Information Interchange,美国信息互换标准代码)
计算机内部,所有信息最终都是一个二进制值。每一个二进制位(bit)有0和1两种状态,因此八个二进制位就可以组合出256种状态,这被称为一个字节(byte)。也就是说,一个字节一共可以用来表示256种不同的状态,每一个状态对应一个符号,就是256个符号,从00000000到11111111。
上个世纪60年代,美国制定了一套字符编码,对英语字符与二进制位之间的关系,做了统一规定。这被称为 ASCII 码,一直沿用至今。
ASCII 码一共规定了128个字符的编码,比如空格SPACE是32(二进制00100000),大写的字母A是65(二进制01000001)。这128个符号(包括32个不能打印出来的控制符号),只占用了一个字节的后面7位,最前面的一位统一规定为0。
| Bin(二进制) | Oct(八进制) | Dec(十进制) | Hex(十六进制) | 缩写/字符 | 解释 |
|---|---|---|---|---|---|
| 0000 0000 | 00 | 0 | 0x00 | NUL(null) | 空字符 |
| 0000 0001 | 01 | 1 | 0x01 | SOH(start of headline) | 标题开始 |
| 0000 0010 | 02 | 2 | 0x02 | STX (start of text) | 正文开始 |
| 0000 0011 | 03 | 3 | 0x03 | ETX (end of text) | 正文结束 |
| 0000 0100 | 04 | 4 | 0x04 | EOT (end of transmission) | 传输结束 |
| 0000 0101 | 05 | 5 | 0x05 | ENQ (enquiry) | 请求 |
| 0000 0110 | 06 | 6 | 0x06 | ACK (acknowledge) | 收到通知 |
| 0000 0111 | 07 | 7 | 0x07 | BEL (bell) | 响铃 |
| 0000 1000 | 010 | 8 | 0x08 | BS (backspace) | 退格 |
| 0000 1001 | 011 | 9 | 0x09 | HT (horizontal tab) | 水平制表符 |
| 0000 1010 | 012 | 10 | 0x0A | LF (NL line feed, new line) | 换行键 |
| 0000 1011 | 013 | 11 | 0x0B | VT (vertical tab) | 垂直制表符 |
| 0000 1100 | 014 | 12 | 0x0C | FF (NP form feed, new page) | 换页键 |
| 0000 1101 | 015 | 13 | 0x0D | CR (carriage return) | 回车键 |
| 0000 1110 | 016 | 14 | 0x0E | SO (shift out) | 不用切换 |
| 0000 1111 | 017 | 15 | 0x0F | SI (shift in) | 启用切换 |
| 0001 0000 | 020 | 16 | 0x10 | DLE (data link escape) | 数据链路转义 |
| 0001 0001 | 021 | 17 | 0x11 | DC1 (device control 1) | 设备控制1 |
| 0001 0010 | 022 | 18 | 0x12 | DC2 (device control 2) | 设备控制2 |
| 0001 0011 | 023 | 19 | 0x13 | DC3 (device control 3) | 设备控制3 |
| 0001 0100 | 024 | 20 | 0x14 | DC4 (device control 4) | 设备控制4 |
| 0001 0101 | 025 | 21 | 0x15 | NAK (negative acknowledge) | 拒绝接收 |
| 0001 0110 | 026 | 22 | 0x16 | SYN (synchronous idle) | 同步空闲 |
| 0001 0111 | 027 | 23 | 0x17 | ETB (end of trans. block) | 结束传输块 |
| 0001 1000 | 030 | 24 | 0x18 | CAN (cancel) | 取消 |
| 0001 1001 | 031 | 25 | 0x19 | EM (end of medium) | 媒介结束 |
| 0001 1010 | 032 | 26 | 0x1A | SUB (substitute) | 代替 |
| 0001 1011 | 033 | 27 | 0x1B | ESC (escape) | 换码(溢出) |
| 0001 1100 | 034 | 28 | 0x1C | FS (file separator) | 文件分隔符 |
| 0001 1101 | 035 | 29 | 0x1D | GS (group separator) | 分组符 |
| 0001 1110 | 036 | 30 | 0x1E | RS (record separator) | 记录分隔符 |
| 0001 1111 | 037 | 31 | 0x1F | US (unit separator) | 单元分隔符 |
| 0010 0000 | 040 | 32 | 0x20 | (space) | 空格 |
| 0010 0001 | 041 | 33 | 0x21 | ! | 叹号 |
| 0010 0010 | 042 | 34 | 0x22 | " | 双引号 |
| 0010 0011 | 043 | 35 | 0x23 | # | 井号 |
| 0010 0100 | 044 | 36 | 0x24 | $ | 美元符 |
| 0010 0101 | 045 | 37 | 0x25 | % | 百分号 |
| 0010 0110 | 046 | 38 | 0x26 | & | 和号 |
| 0010 0111 | 047 | 39 | 0x27 | ' | 闭单引号 |
| 0010 1000 | 050 | 40 | 0x28 | ( | 开括号 |
| 0010 1001 | 051 | 41 | 0x29 | ) | 闭括号 |
| 0010 1010 | 052 | 42 | 0x2A | * | 星号 |
| 0010 1011 | 053 | 43 | 0x2B | + | 加号 |
| 0010 1100 | 054 | 44 | 0x2C | , | 逗号 |
| 0010 1101 | 055 | 45 | 0x2D | - | 减号/破折号 |
| 0010 1110 | 056 | 46 | 0x2E | . | 句号 |
| 0010 1111 | 057 | 47 | 0x2F | / | 斜杠 |
| 0011 0000 | 060 | 48 | 0x30 | 0 | 字符0 |
| 0011 0001 | 061 | 49 | 0x31 | 1 | 字符1 |
| 0011 0010 | 062 | 50 | 0x32 | 2 | 字符2 |
| 0011 0011 | 063 | 51 | 0x33 | 3 | 字符3 |
| 0011 0100 | 064 | 52 | 0x34 | 4 | 字符4 |
| 0011 0101 | 065 | 53 | 0x35 | 5 | 字符5 |
| 0011 0110 | 066 | 54 | 0x36 | 6 | 字符6 |
| 0011 0111 | 067 | 55 | 0x37 | 7 | 字符7 |
| 0011 1000 | 070 | 56 | 0x38 | 8 | 字符8 |
| 0011 1001 | 071 | 57 | 0x39 | 9 | 字符9 |
| 0011 1010 | 072 | 58 | 0x3A | : | 冒号 |
| 0011 1011 | 073 | 59 | 0x3B | ; | 分号 |
| 0011 1100 | 074 | 60 | 0x3C | < | 小于 |
| 0011 1101 | 075 | 61 | 0x3D | = | 等号 |
| 0011 1110 | 076 | 62 | 0x3E | > | 大于 |
| 0011 1111 | 077 | 63 | 0x3F | ? | 问号 |
| 0100 0000 | 0100 | 64 | 0x40 | @ | 电子邮件符号 |
| 0100 0001 | 0101 | 65 | 0x41 | A | 大写字母A |
| 0100 0010 | 0102 | 66 | 0x42 | B | 大写字母B |
| 0100 0011 | 0103 | 67 | 0x43 | C | 大写字母C |
| 0100 0100 | 0104 | 68 | 0x44 | D | 大写字母D |
| 0100 0101 | 0105 | 69 | 0x45 | E | 大写字母E |
| 0100 0110 | 0106 | 70 | 0x46 | F | 大写字母F |
| 0100 0111 | 0107 | 71 | 0x47 | G | 大写字母G |
| 0100 1000 | 0110 | 72 | 0x48 | H | 大写字母H |
| 0100 1001 | 0111 | 73 | 0x49 | I | 大写字母I |
| 01001010 | 0112 | 74 | 0x4A | J | 大写字母J |
| 0100 1011 | 0113 | 75 | 0x4B | K | 大写字母K |
| 0100 1100 | 0114 | 76 | 0x4C | L | 大写字母L |
| 0100 1101 | 0115 | 77 | 0x4D | M | 大写字母M |
| 0100 1110 | 0116 | 78 | 0x4E | N | 大写字母N |
| 0100 1111 | 0117 | 79 | 0x4F | O | 大写字母O |
| 0101 0000 | 0120 | 80 | 0x50 | P | 大写字母P |
| 0101 0001 | 0121 | 81 | 0x51 | Q | 大写字母Q |
| 0101 0010 | 0122 | 82 | 0x52 | R | 大写字母R |
| 0101 0011 | 0123 | 83 | 0x53 | S | 大写字母S |
| 0101 0100 | 0124 | 84 | 0x54 | T | 大写字母T |
| 0101 0101 | 0125 | 85 | 0x55 | U | 大写字母U |
| 0101 0110 | 0126 | 86 | 0x56 | V | 大写字母V |
| 0101 0111 | 0127 | 87 | 0x57 | W | 大写字母W |
| 0101 1000 | 0130 | 88 | 0x58 | X | 大写字母X |
| 0101 1001 | 0131 | 89 | 0x59 | Y | 大写字母Y |
| 0101 1010 | 0132 | 90 | 0x5A | Z | 大写字母Z |
| 0101 1011 | 0133 | 91 | 0x5B | [ | 开方括号 |
| 0101 1100 | 0134 | 92 | 0x5C | \ | 反斜杠 |
| 0101 1101 | 0135 | 93 | 0x5D | ] | 闭方括号 |
| 0101 1110 | 0136 | 94 | 0x5E | ^ | 脱字符 |
| 0101 1111 | 0137 | 95 | 0x5F | _ | 下划线 |
| 0110 0000 | 0140 | 96 | 0x60 | ` | 开单引号 |
| 0110 0001 | 0141 | 97 | 0x61 | a | 小写字母a |
| 0110 0010 | 0142 | 98 | 0x62 | b | 小写字母b |
| 0110 0011 | 0143 | 99 | 0x63 | c | 小写字母c |
| 0110 0100 | 0144 | 100 | 0x64 | d | 小写字母d |
| 0110 0101 | 0145 | 101 | 0x65 | e | 小写字母e |
| 0110 0110 | 0146 | 102 | 0x66 | f | 小写字母f |
| 0110 0111 | 0147 | 103 | 0x67 | g | 小写字母g |
| 0110 1000 | 0150 | 104 | 0x68 | h | 小写字母h |
| 0110 1001 | 0151 | 105 | 0x69 | i | 小写字母i |
| 0110 1010 | 0152 | 106 | 0x6A | j | 小写字母j |
| 0110 1011 | 0153 | 107 | 0x6B | k | 小写字母k |
| 0110 1100 | 0154 | 108 | 0x6C | l | 小写字母l |
| 0110 1101 | 0155 | 109 | 0x6D | m | 小写字母m |
| 0110 1110 | 0156 | 110 | 0x6E | n | 小写字母n |
| 0110 1111 | 0157 | 111 | 0x6F | o | 小写字母o |
| 0111 0000 | 0160 | 112 | 0x70 | p | 小写字母p |
| 0111 0001 | 0161 | 113 | 0x71 | q | 小写字母q |
| 0111 0010 | 0162 | 114 | 0x72 | r | 小写字母r |
| 0111 0011 | 0163 | 115 | 0x73 | s | 小写字母s |
| 0111 0100 | 0164 | 116 | 0x74 | t | 小写字母t |
| 0111 0101 | 0165 | 117 | 0x75 | u | 小写字母u |
| 0111 0110 | 0166 | 118 | 0x76 | v | 小写字母v |
| 0111 0111 | 0167 | 119 | 0x77 | w | 小写字母w |
| 0111 1000 | 0170 | 120 | 0x78 | x | 小写字母x |
| 0111 1001 | 0171 | 121 | 0x79 | y | 小写字母y |
| 0111 1010 | 0172 | 122 | 0x7A | z | 小写字母z |
| 0111 1011 | 0173 | 123 | 0x7B | { | 开花括号 |
| 0111 1100 | 0174 | 124 | 0x7C | | | 垂线 |
| 0111 1101 | 0175 | 125 | 0x7D | } | 闭花括号 |
| 0111 1110 | 0176 | 126 | 0x7E | ~ | 波浪号 |
| 0111 1111 | 0177 | 127 | 0x7F | DEL (delete) | 删除 |
ANSI 编码 (本地化)
ANSI全称(American National Standard Institite)美国国家标准学会(美国的一个非营利组织),首先ANSI不是指的一种特定的编码,而是不同地区扩展编码方式的统称,各个国家和地区所独立制定的兼容ASCII但互相不兼容的字符编码,微软统称为ANSI编码
英语用128个符号编码就够了,但是用来表示其他语言,128个符号是不够的。比如,在法语中,字母上方有注音符号,它就无法用 ASCII 码表示。于是,一些欧洲国家就决定,利用字节中闲置的最高位编入新的符号。比如,法语中的é的编码为130(二进制10000010)。这样一来,这些欧洲国家使用的编码体系,可以表示最多256个符号。
为使计算机支持更多语言,通常使用 0x80~0xFF 范围的 2 个字节来表示 1 个字符。比如:汉字 ‘中’ 在中文操作系统中,使用 [0xD6,0xD0] 这两个字节存储。 不同的国家和地区制定了不同的标准,由此产生了 GB2312, BIG5, JIS 等各自的编码标准。这些使用 2 个字节来代表一个字符的各种汉字延伸编码方式,称为 ANSI 编码。在简体中文系统下,ANSI 编码代表 GB2312 编码,在日文操作系统下,ANSI 编码代表 JIS 编码。 不同 ANSI 编码之间互不兼容,当信息在国际间交流时,无法将属于两种语言的文字,存储在同一段 ANSI 编码的文本中。
ISO 8859-1
ISO 8859-1,正式编号为ISO/IEC 8859-1:1998,又称Latin-1或“
Big5
Big5是使用繁体中文社群中最常用的电脑汉字字符集标准,共收录13,060个汉字
GB/T 2312
GB/T 2312是中华人民共和国国家标准简体中文字符集,全称《信息交换用汉字编码字符集·基本集》,通常简称GB,由中国国家标准总局发布。GB/T 2312编码通行于中国大陆;新加坡等地也采用此编码。中国大陆几乎所有的中文系统和国际化的软件都支持GB/T 2312。GB类汉字编码为双字节编码,对汉字进行了“分区”处理。
最早的GB编码方案是GB2312,收录的汉字不足一万个,基本能满足日常使用需求,但不包含一些生僻字,因此后来又在GB2312基础上进行了扩展。
在GB2312基础上扩展的编码方案称之为GBK(K为“扩展”的拼音首字母),后来又在GBK的基础上进一步扩展,称之为GB18030,加入了一些国内少数民族的文字,一些生僻字被编到了4个字节。
包括GB2312、GBK、GB18030在内的GB系列编码方案每扩展一次都完全保留之前版本的编码,所以每个新版本都向下兼容。
这里要指出的是,虽然都用多个字节表示一个字符,但是GB类的汉字编码与后文的Unicode编码方案的UTF-8、UTF-16、UTF-32等字符编码方式CEF是毫无关系的。
编码
GB2312编码为了避免与ASCII字符编码(0~127)相冲突,规定表示一个汉字的编码(即汉字内码)的字节其值必须大于127(即字节的最高位为1),并且必须是两个大于127的字节连在一起来共同表示一个汉字(GB2312为双字节编码),前一字节称为高字节,后一字节称为低字节;而一个字节的值若小于等于127(即字节的最高位为0),自然是仍表示一个原来的ASCII字符(ASCII为单字节编码)。
因此,可以认为GB2312是对ASCII的中文扩展(即GB2312完全直接兼容ASCII),正如EASCII是对ASCII的欧洲文字扩展一样。
目前世界上除ASCII之外的其它通行的字符编码方案,基本上都兼容ASCII,但相互之间除了兼容ASCII字符的部分之外却并不兼容。
整个GB2312字符集分成94个区,每区有94个位,每个区位上只有一个字符,即每区含有94个汉字或符号,用所在的区和位来对字符进行编码(实际上就是码点值、码点编号、字符编号),因此称为区位码(或许叫“区位号”更为恰当)。换言之,GB2312将包括汉字在内的所有字符编入一个94*94的二维表,行就是“区”、列就是“位”,每个字符由区、位唯一定位,其对应的区、位编号合并就是区位码。
GB2312字符集中:
1)01~09区(682个):特殊符号、数字、英文字符、制表符等,包括拉丁字母、希腊字母、日文平假名及片假名字母、俄语西里尔字母等在内的682个全角字符;
2)10~15区:空区,留待扩展;
3)16~55区(3755个):常用汉字(也称一级汉字),按拼音排序;
4)56~87区(3008个):非常用汉字(也称二级汉字),按部首/笔画排序;
5)88~94区:空区,留待扩展。
比如“万”字在45区82位,所以“万”字的区位码是:45 82(注意,GB类汉字编码为双字节编码,因此,45相当于高位字节,82相当于低位字节)。由于ASCII码只用了一个字节中的低7位,所以,这个首位(最高位)上的“1”就可以作为识别汉字编码的标志,计算机在处理到首位是“1”的编码时就把它理解为汉字,在处理到首位是“0”的编码时就把它理解为ASCII字符。
标码中是分别将区位码中的“区”和“位”各自加上32(20H)的(避免与ASCII字符中0~32的不可显示字符和空格字符相冲突),因为GB2312是DBCS双字节字符集,因此国标码属于双字节码。
这样我们可以算出“万”字的国标码十进制为:(45+32,82+32) = (77,114),十六进制为:(4D,72),二进制为:(0100 1101,0111 0010)。
为避免与ASCII码冲突,规定国标码中的每个字节的最高位都从0换成1,即相当于每个字节都再加上128(十六进制为80,即80H;二进制为1000 0000)
77 + 128 = 205(二进制为1100 1101,十六进制为CD)
114+ 128 = 242(二进制为1111 0010,十六进制为F2)
测试:
在记事本中输入“万”,编码方式选择”ANSI“,使用UltraEdit十六进制查看文件内容

UNICODE(国际化)
为了使国际间信息交流更加方便,国际组织制定了 UNICODE 字符集,为各种语言中的每一个字符设定了统一并且唯一的数字编号,以满足跨语言、跨平台进行文本转换、处理的要求。UNICODE 常见的有三种编码方式:UTF-8(1 个字节表示)、UTF-16((2 个字节表示))、UTF-32(4 个字节表示)。
Unicode 是一个很大的集合,现在的规模可以容纳100多万个符号。每个符号的编码都不一样,比如,U+0639表示阿拉伯字母Ain,U+0041表示英语的大写字母A,U+4E25表示汉字严。具体的符号对应表,可以查询
但这里就有两个严重的问题,第一个问题是,如何才能区别 Unicode 和 ASCII ?计算机怎么知道三个字节表示一个符号,而不是分别表示三个符号呢?第二个问题是,我们已经知道,英文字母只用一个字节表示就够了,如果 Unicode 统一规定,每个符号用三个或四个字节表示,那么每个英文字母前都必然有二到三个字节是0,这对于存储来说是极大的浪费,文本文件的大小会因此大出二三倍,这是无法接受的。
utf-8
UTF-8全称:8bit Unicode Transformation Format,8比特Unicode通用转换格式。UTF-8是一种针对Unicode的可变长度字符编码。可以表示Unicode标准中的任何一个字符,且其编码中的第一个字节仍然与ASCII兼容。
UTF-8是一种变长的编码方式,可以使用1~6个字节对Unicode字符集进行编码,编码规则如下:
-
对于单字节的符号, 字节的第一位设为0, 后面7位为这个符号的unicode码. 因此对于 英语字母, UTF-8编码和ASCII码是相同的.
-
对于n字节的符号(n>1), 第一个字节的前n位都设为1, 第n+1位设为0, 后面字节的前 两位一律设为10. 剩下的没有提及的二进制位, 全部为这个符号的unicode码.
| n | Unicode符号范围 | UTF-8编码方式 |
|---|---|---|
| 1 | 0000 0000 - 0000 007F | 0xxxxxxx |
| 2 | 0000 0080 - 0000 07FF | 110xxxxx 10xxxxxx |
| 3 | 0000 0800 - 0000 FFFF | 1110xxxx 10xxxxxx 10xxxxxx |
| 4 | 0001 0000 - 0010 FFFF | 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx |
| 5 | 0020 0000 - 03FF FFFF | 111110xx 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx |
| 6 | 0400 0000 - 7FFF FFFF | 1111110x 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx |
注:早先的规定是,utf-8可以到6个字节。但是,这已经废除了,目前规定是只支持4个字节,大于U+001FFFFF的符号utf-8不再支持
解读 UTF-8 编码非常简单。如果一个字节的第一位是0,则这个字节单独就是一个字符;如果第一位是1,则连续有多少个1,就表示当前字符占用多少个字节。
优点
-
支持多种语言,如中文简体,中文繁体,英语等外国语种
-
大多数的编程语言都支持UTF8,如C++,python,java
-
完全兼容ASCII编码
缺点
-
UTF-8 使用变长的编码方式,很难确定字符串的长度,如“你好world”,使用strlen函数计算的字符串长度并不是7
-
UTF8使用变长的编码方式,在索引查找等操作的时间复杂度更高(每个字符所占的字节数不相同).
编码
中文编码: 你 好 世 界 unicode: 4F60 597D 4E16 754C
"你"占三个字节:1110xxxx 10xxxxxx 10xxxxxx 4F60:0100 1111 0110 0000 utf-8:11100100 10111101 10100000 ->E4 BD A0
"好"占三个字节:1110xxxx 10xxxxxx 10xxxxxx 597D:0101 1001 0111 1101 utf-8:11100101 10100101 10111101 ->E5 A5 BD
解码
-
将十六进制转为二进制
-
根据二进制前面“1”的数量的确定字节数
-
取消二进制的前缀,将剩下的bit合成新的二进制数据
-
将新的二进制数据转为十六进制,查找unicode码表确定对应字符
utf-16
Unicode字符集目前定义了包括1个基本平面BMP和16个增补平面SP在内的共17个平面。
每个平面的码点数量为2^16=65536个,因此17个平面的码点总数为共65536 X 17=1114112个。其中,基本平面码点为65536个(码点编号范围为0x0000~0xFFFF),增补平面码点为1114112-65536=65536*16=1048576个(码点编号范围为0x10000~0x10FFFF),基本平面所包含的字符(英文,常用的简体中文)一般可以满足我们的需要。
遇到特殊字符怎么办?
我们无法用16bits表示17个平面的所有字符,于是Unicode提出代理机制。具体而言,就是为了能以16bits编码17个平面的所有字符,Unicode设计引入了UTF-16编码方式,并且通过代理机制实现了扩展。
Unicode字符集基本平面BMP中的字符是直接映射关系,即这部分字符的字符编号与字符编码是等同的。
但Unicode字符集增补平面中的字符却不是直接映射关系,而是必须通过代理机制这一编码算法的转换,亦即这部分字符的字符编号与字符编码不是等同的。
基本平面内有一块特殊区域,为代理区,使用这块区域中的16bits来表示一个增补平面码点,这两个用来表示一个增补平面码点的特殊16位码元被称之为代理对(Surrogate Pair)。
UTF-16中,大部分汉字采用两个字节编码,少量不常用汉字采用四个字节编码。
UTF-16一方面使用变长码元序列的编码方式,每个字符编码为16位或32位,相较于定长码元序列的UTF-32算法更复杂(甚至比同样是变长码元序列的UTF-8也更为复杂,因为引入了独特的代理对这样的代理机制);另一方面仍然占用过多字节,比如ASCII字符也同样需要占用两个字节,相较于UTF-8更浪费空间和带宽。
基本平面中的代理对编码为增补平面字符的码元序列的具体算法如下:
1) 增补平面中的码点值(0x10000~0x10FFFF)减去0x10000可得到20位长的比特组(范围为0x00000~0xFFFFF)
2)将得到的20位长的比特组分拆为两部分:高位10比特和低位10比特;
3)20位长的比特组中的高位10比特(值的范围为0x000~0x3FF)加上0xD800,得到第一个代理码元即引导代理(值的范围是0xD800~0xDBFF);
4)20位长的比特组中的低位10比特(值范围也是0x000~0x3FF)加上0xDC00,得到第二个代理码元即尾随代理(值的范围是0xDC00~0xDFFF);
5)将引导代理与尾随代理按前后顺序组合在一起成为“代理对”,就得到了增补平面字符的码元序列。
优点
-
所有的基本平面字符(常用中英文)都用两个字节表示
-
索引计算相比utf8编码更快,性能更好.
缺点
当使用UTF16只表示ASCII字符会造成空间的浪费,一个ASCII字符也是有两个字节表示.
编码
例子1:
你好,世界(基本平面字符)
U+00 00 4f 60
U+00 00 59 7d
U+00 00 00 2c
U+00 00 4e 16
U+00 00 75 4c
例子2(特殊字符)
对汉字“𤭢”进行UTF16编码
-
查Unicode码表,确定该汉字的表示,为“U+24B62”
https://www.unicode.org/cgi-bin/GetUnihanData.pl?codepoint=%F0%A4%AD%A2 -
编码超过U+10000,减去0x10000得到14B62
-
转化14B62为二进制
HEXADECIMAL BINARY 1 0001 4 0100 B 1011 6 0110 2 0010 -
将20bits分为两部分,即高位代理(0001010010)和低位代理(1101100010)
-
高位代理加上“0xD800”,得到D852
D800 : 1101 1000 0000 0000
High : 0000 0000 0101 0010
= 1101 1000 0101 0010
= D852 -
低位代理加上“0xDC00”,得到DF62
DC00 : 1101 1100 0000 0000
low : 0000 0011 0110 0010
= 1101 1111 0110 0010
= DF62 -
得到最终UTF16编码为D852 DF62
解码
例子1(基本平面):
U+00 00 4f 60============>你
U+00 00 597d ============> 好
U+00 00 00 2c ============>,
U+00 00 4e 16 ============>世
U+00 00 75 4c============>界
例子2(特殊字符):
对\uD852\uDF62进行解码
-
将其转化为二进制
D852 : 1101 1000 0101 0010
DF62 : 1101 1111 0110 0010
-
高字节(D852)减去0XD800得到高位代理,然后乘上0x0400,得到“0x14800”
D852 : 1101 1000 0101 0010
D800 : 1101 1000 0000 0000
= 0000 0000 0101 0010
= 52
-
低字节减去0xDC00得到低位代理
DF62 : 1101 1111 0110 0010
DC00 : 1101 1100 0000 0000
= 0000 0011 0110 0010
= 362
-
将两个值加上 (0x14800 + 0x362)并且加上0x10000得到最终编码
0x14800 : 0001 0100 1000 0000 0000
0x362 : 0000 0000 0011 0110 0010
0x10000 : 0001 0000 0000 0000 0000
= 0010 0100 1011 0110 0010
= 24B62
最终编码为U+24B62
utf-32
UTF-32在UTF目前常用的三种编码方式(UTF-8、UTF-16、UTF-32)中最为简单的一种编码方式。UTF-32编码方式不使用任何编码算法,将每个Unicode字符码点值直接表示为一个32bits的序列(一一对应),因此,目前UTF-32是一种固定宽度的Unicode字符编码方式。
由于UTF-32在三大UTF编码方式中,既不是最早推出的编码方式(最早推出的是UTF-16),也不是最优设计的编码方式(公认为最优设计的是UTF-8),因此在实践中使用得最少,目前几乎已处于淘汰状态。
优点
和unicode码表一一对应,同时为固定长度的编码,索引查找操作消耗的计算机少,时间复杂度为常数级
缺点
浪费空间
编码:
没有编码计算,直接映射即可
例子:
你好,世界
U+00 00 4f 60
U+00 00 59 7d
U+00 00 00 2c
U+00 00 4e 16
U+00 00 75 4c
解码:
不需要解码计算,直接映射即可
例子:
U+00 00 4f 60============>你
U+00 00 597d ============> 好
U+00 00 00 2c ============>,
U+00 00 4e 16 ============>世
U+00 00 75 4c============>界
UCS编码
在建立世界统一的字符编码时,有两个机构,一个为国际标准化组织(ISO),制定了一份“通用字符集”(Universal Character Set,简称UCS),并最终制定了ISO 10646标准,一个为统一码联盟,开发了Unicode标准(The Unicode Standard),它们合并双方的工作成果,并为创立一个单一编码表而协同工作,不过由于Unicode这一名字比较好记,因而它使用更为广泛。
UCS-4
ISO 10646标准为“通用字符集”(UCS)定义了一种31位的编码形式(即UCS-4),其编码固定占用4个字节,编码空间为0x00000000~0x7FFFFFFF,所以UTF-32和UCS4能表示的字符是相同的。
UCS-2
ISO 10646标准为“通用字符集”(UCS)定义了一种16位的编码形式(即UCS-2),其编码固定占用2个字节,它包含65536个编码空间,UTF-16可看成是UCS-2的父集。在没有辅助平面字符(surrogate code points)前,UTF-16与UCS-2所指的是同一的意思。但当引入辅助平面字符后,就称为UTF-16了。现在若有软件声称自己支持UCS-2编码,那其实是暗指它不能支持在UTF-16中超过2字节的字集。对于小于0x10000的UCS码,UTF-16编码就等于UCS码。
字节序大端小端
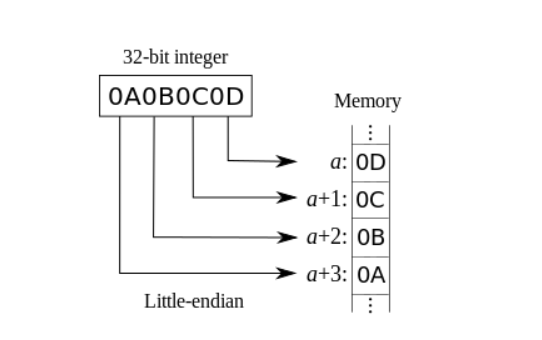
小端序Little-Endian
就是低位字节(即小端字节、尾端字节)存放在内存的低地址,而高位字节(即大端字节、头端字节)存放在内存的高地址。
这是最符合人的直觉思维的字节序(但却不符合人的读写习惯),因为从人的第一观感来说,低位字节的值小,对应放在内存地址也小的地方,也即内存中的低位地址;反之,高位字节的值大,对应放在内存地址大的地方,也即内存中的高位地址。
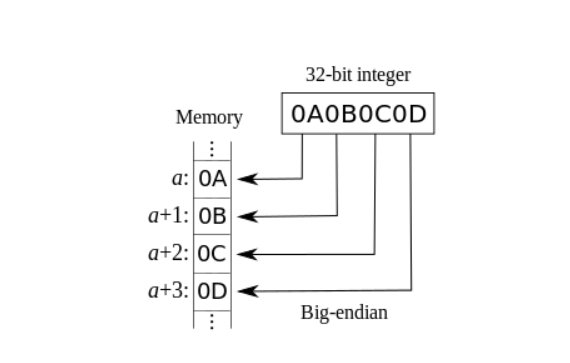
大端序Big-Endian
就是高位字节(即大端字节、头端字节)存放在内存的低地址,低位字节(即小端字节、尾端字节)存放在内存的高地址。
这是最符合人平时的读写习惯的字节序(但却不符合人的直觉思维),因为不用像在Little-EndIan中还需考虑字节的高位、低位与内存的高地址、低地址的对应关系,只需把数值按照人通常的书写习惯,从高位到低位的顺序直接在内存中从左到右或从上到下(下图中就是从上到下)按照由低到高的内存地址,一个字节一个字节地填充进去。
| Bytes | Encoding Form |
|---|---|
| 00 00 FE FF | UTF-32, big-endian |
| FF FE 00 00 | UTF-32, little-endian |
| FE FF | UTF-16, big-endian |
| FF FE | UTF-16, little-endian |
| EF BB BF | UTF-8 |
utf8Bom
为什么有utf8Bom
一般软件确定文本文件编码方式的方法有如下三种:
-
检测文件头标识;
-
提示用户手动选择;
-
根据一定的规则自行推断。
有Bom表示编码方式为utf-8
当你在简体中文版的Windows记事本里新建一个文件,输入“联通”两个汉字之后,保存为一个txt文件。然后关闭,再次打开该txt文件后,你会发现刚才输入并保存的“联通”两个汉字竟然莫名其妙地消失了,取而代之的是几个乱码。
在这种编码方式下,该文本文件仅仅保存了“联通”两个汉字的GB内码的四个字节,如下所示(左边为十六进制,右边为二进制)。
c1 1100 0001 aa 1010 1010 cd 1100 1101 a8 1010 1000
当用记事本再次打开该文本文件时,由于没有BOM,记事本又没有提供显式地提示用户手动选择编码方式的功能,于是就只能隐式地按其推断规则自行推断,推断的结果就是被误认为了这是一个UTF-8编码方式的文件。
为什么会推断错误呢?又为什么会将其编码方式错误地推断为UTF-8呢?
注意,“联通”两个汉字的GB内码,其第一第二个字节的起始部分分别是“110”和“10”,第三第四个字节的起始部分也分别是“110”和“10”,这刚好符合了UTF-8编码方式里的两码元序列的编码算法规则.
让我们按照UTF-8的编码算法规则,将第一个字节的前缀码110去掉,得到“00001”,将第二个字节的前缀码10去掉,得到“101010”,将两者组合在一起,得到“00001101010”,再去掉多余的前导的0,就得到了“0110 1010"(十六进制为6A),这正好是Unicode字符集里的U+006A,也就是小写字母“j”的码点值。第二个字母类似。
Windows里的软件在采用非ANSI编码时,即便对于根本不存在字节序问题的UTF-8编码默认也会添加BOM
主要因为Windows系统有大量普通用户使用,在必须兼容传统ANSI编码的情况下,从用户体验角度考虑而没有采用显式地要求用户手动选择字符编码方式的做法,因此特别依赖于通过BOM来防止隐式地自行推断字符编码方式而出错。
VS中Unicode字符集和多字节字符集区别
测试
1 查看英文和汉字的十六进制编码
2 C++程序输出中文与英文
查看cmd窗口的编码方式
点击cmd窗口左上角,点击属性
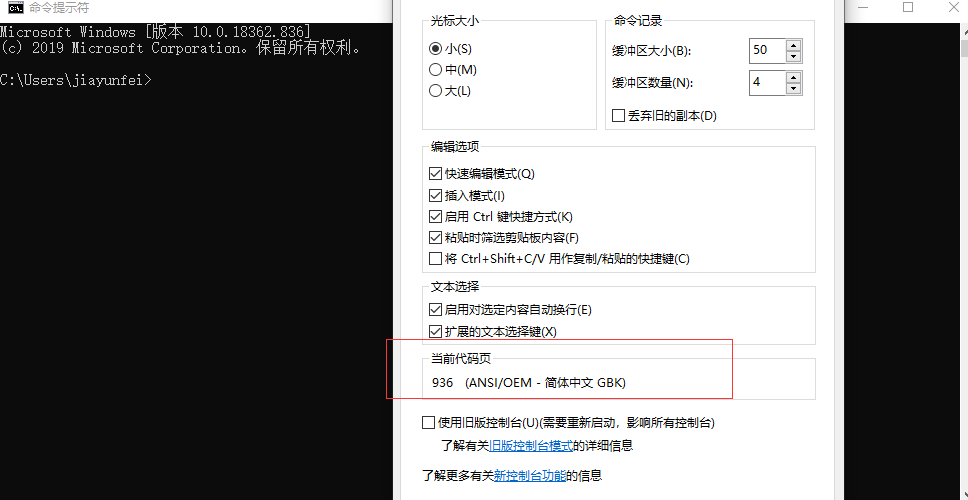
改变cmd窗口的编码方式
-
在main函数中增加语句:system("chcp 65001");
-
手动启动一个控制台程序,启动之后设置编码为utf8
命令:chcp 65001
VS设置默认字符串编码为utf-8
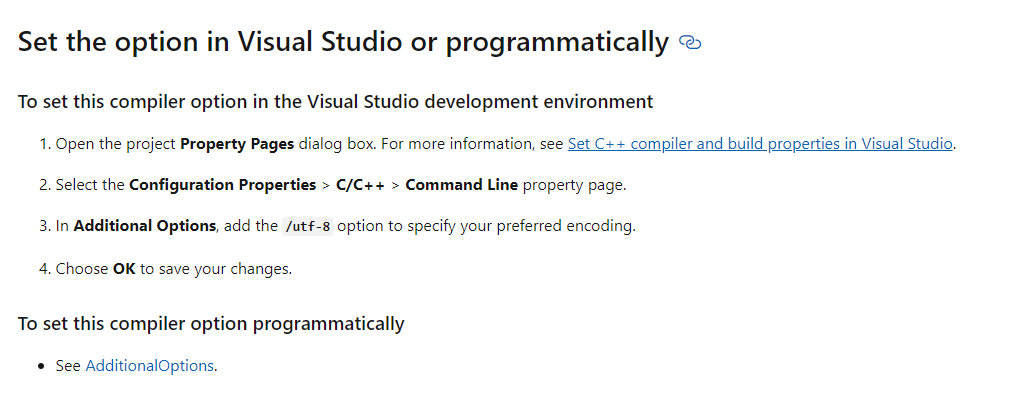
3 QString编码转化
QString基础单元是QChar,储存的是utf-16字符。即,内部统一编码为unicode
-
fromutf8()
-
toutf8()
-
converttounicode函数
https://woboq.com/blog/utf-8-processing-using-simd.html
4 文件写入
5 json序列化粗体
参考资料
https://sf-zhou.github.io/programming/chinese_encoding.html
https://wiki.jikexueyuan.com/project/visual-studio/14.html
https://convertcodes.com/utf16-encode-decode-convert-string/
https://sf-zhou.github.io/programming/chinese_unicode_encoding_table.htm
http://www.unicode.org/cgi-bin/GetUnihanData.pl?codepoint=%E4%BD%A0
https://woboq.com/blog/utf-8-processing-using-simd.html
http://tools.jb51.net/table/gb2312

 浙公网安备 33010602011771号
浙公网安备 33010602011771号