



背景:因为项目需要,希望制作一个由平面、反光材质的照片组成的数据集,如木质纹理的桌面、门面, 平坦的瓷砖地板、墙面,反光的金属表面等等。但是找不到能满足需求的数据集,所以制作了自己的数据集
方法:首先po出原文链接:https://www.pyimagesearch.com/2017/12/04/how-to-create-a-deep-learning-dataset-using-google-images/
- 在谷歌图片中搜索想要下载的图片,这里仅限谷歌浏览器,国内可以通过GHelper插件使用谷歌,读者可以自行百度,如何安装GHelper
- 如下,
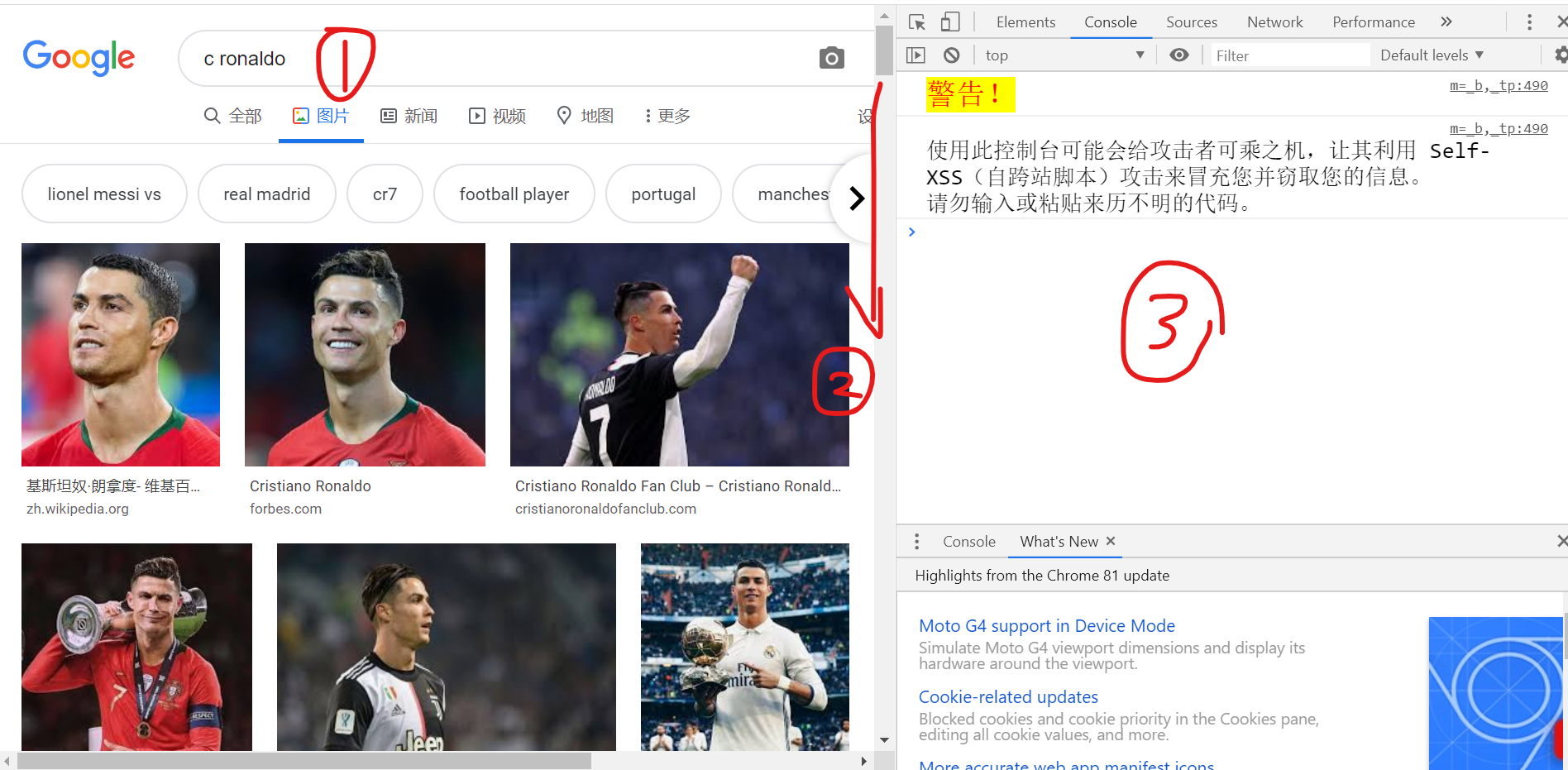
- 1、先在谷歌图片中搜索"C Ronaldo",
- 2、滚动页面,直到加载完所有你想下载的图片
- 3、使用“ctrl + shift + j”调出JavaScript控制台
- 4、将下面的代码复制到控制台,随即出现一个名为‘urls.txt’的下载页面,选择合适的位置下载即可
-
/** * simulate a right-click event so we can grab the image URL using the * context menu alleviating the need to navigate to another page * * attributed to @jmiserez: http://pyimg.co/9qe7y * * @param {object} element DOM Element * * @return {void} */ function simulateRightClick( element ) { var event1 = new MouseEvent( 'mousedown', { bubbles: true, cancelable: false, view: window, button: 2, buttons: 2, clientX: element.getBoundingClientRect().x, clientY: element.getBoundingClientRect().y } ); element.dispatchEvent( event1 ); var event2 = new MouseEvent( 'mouseup', { bubbles: true, cancelable: false, view: window, button: 2, buttons: 0, clientX: element.getBoundingClientRect().x, clientY: element.getBoundingClientRect().y } ); element.dispatchEvent( event2 ); var event3 = new MouseEvent( 'contextmenu', { bubbles: true, cancelable: false, view: window, button: 2, buttons: 0, clientX: element.getBoundingClientRect().x, clientY: element.getBoundingClientRect().y } ); element.dispatchEvent( event3 ); } /** * grabs a URL Parameter from a query string because Google Images * stores the full image URL in a query parameter * * @param {string} queryString The Query String * @param {string} key The key to grab a value for * * @return {string} value */ function getURLParam( queryString, key ) { var vars = queryString.replace( /^\?/, '' ).split( '&' ); for ( let i = 0; i < vars.length; i++ ) { let pair = vars[ i ].split( '=' ); if ( pair[0] == key ) { return pair[1]; } } return false; } /** * Generate and automatically download a txt file from the URL contents * * @param {string} contents The contents to download * * @return {void} */ function createDownload( contents ) { var hiddenElement = document.createElement( 'a' ); hiddenElement.href = 'data:attachment/text,' + encodeURI( contents ); hiddenElement.target = '_blank'; hiddenElement.download = 'urls.txt'; hiddenElement.click(); } /** * grab all URLs va a Promise that resolves once all URLs have been * acquired * * @return {object} Promise object */ function grabUrls() { var urls = []; return new Promise( function( resolve, reject ) { var count = document.querySelectorAll( '.isv-r a:first-of-type' ).length, index = 0; Array.prototype.forEach.call( document.querySelectorAll( '.isv-r a:first-of-type' ), function( element ) { // using the right click menu Google will generate the // full-size URL; won't work in Internet Explorer // (http://pyimg.co/byukr) simulateRightClick( element.querySelector( ':scope img' ) ); // Wait for it to appear on the <a> element var interval = setInterval( function() { if ( element.href.trim() !== '' ) { clearInterval( interval ); // extract the full-size version of the image let googleUrl = element.href.replace( /.*(\?)/, '$1' ), fullImageUrl = decodeURIComponent( getURLParam( googleUrl, 'imgurl' ) ); if ( fullImageUrl !== 'false' ) { urls.push( fullImageUrl ); } // sometimes the URL returns a "false" string and // we still want to count those so our Promise // resolves index++; if ( index == ( count - 1 ) ) { resolve( urls ); } } }, 10 ); } ); } ); } /** * Call the main function to grab the URLs and initiate the download */ grabUrls().then( function( urls ) { urls = urls.join( '\n' ); createDownload( urls ); } );
- Python 爬取图片
- 新建一个“download_images.py”文件,并在虚拟环境下,安装你需要安装的包,并将下面的代码复制到你的“download_images.py”文件
-
# import the necessary packages from imutils import paths import argparse import requests import cv2 import os
# construct the argument parse and parse the arguments ap = argparse.ArgumentParser() ap.add_argument("-u", "--urls", required=True, help="path to file containing image URLs") # 设置刚刚保存的urls.txt路径 ap.add_argument("-o", "--output", required=True, help="path to output directory of images") # 设置图片保存的路径 args = vars(ap.parse_args()) # grab the list of URLs from the input file, then initialize the # total number of images downloaded thus far rows = open(args["urls"]).read().strip().split("\n") total = 0
# loop the URLs for url in rows: try: # try to download the image r = requests.get(url, timeout=60) # save the image to disk p = os.path.sep.join([args["output"], "{}.jpg".format( str(total).zfill(8))]) f = open(p, "wb") f.write(r.content) f.close() # update the counter print("[INFO] downloaded: {}".format(p)) total += 1 # handle if any exceptions are thrown during the download process except: print("[INFO] error downloading {}...skipping".format(p))
# loop over the image paths we just downloaded for imagePath in paths.list_images(args["output"]): # initialize if the image should be deleted or not delete = False # try to load the image try: image = cv2.imread(imagePath) # if the image is `None` then we could not properly load it # from disk, so delete it if image is None: delete = True # if OpenCV cannot load the image then the image is likely # corrupt so we should delete it except: print("Except") delete = True # check to see if the image should be deleted if delete: print("[INFO] deleting {}".format(imagePath)) os.remove(imagePath)
$ python download_images.py --urls urls.txt --output images/santa # 设置路径 [INFO] downloaded: images/santa/00000000.jpg [INFO] downloaded: images/santa/00000001.jpg [INFO] downloaded: images/santa/00000002.jpg [INFO] downloaded: images/santa/00000003.jpg ... [INFO] downloaded: images/santa/00000519.jpg [INFO] error downloading images/santa/00000519.jpg...skipping [INFO] downloaded: images/santa/00000520.jpg ... [INFO] deleting images/santa/00000211.jpg [INFO] deleting images/santa/00000199.jpg
