



到了浙大读博才刚开始学习深度学习,所以现在是个蠢蠢(纯纯)的小白,这篇blog用来记录学习过程中使用到的工具和简单知识吧
DL概念篇:
1、U-Net: 带有skip connection的encoder-decoder网络
2、2.1概念:encoder-decoder:encoder使用convolution,将输入映射成特征向量,作为输入数据提取出的特征,结果是input的分辨率下降但特征增加。decoder只用于训练阶段,使用deconvolution,它根据提取的特征重构原始数据,结果是output与input的形状相同。更易理解的概念是:In a CNN, an encoder-decoder network typically looks like this (a CNN encoder and a CNN decoder):This is a network to perform semantic segmentation of an image. The left half of the network maps raw image pixels to a rich representation of a collection of feature vectors. The right half of the network takes these features, produces an output and maps the output back into the “raw” format (in this case, image pixels)。这一结构2006年由Hinton发表在Science上https://science.sciencemag.org/content/313/5786/504
2.2:性质:
-
- encoder提取特征,decoder重构原始数据且只用于训练阶段。
- 自动编码器(Auto-Encoders,AE)用于特征提取和数据降维。最简单的AE包括三个部分:输入层→隐含层→输出层。
- 训练时,encoder和decoder一起训练,没有为每个数据设置标签,是一种无监督学习的方法,训练目标是最小化重构误差,即让重构向量与原始输入向量之间的误差最小化。事实上,它是将输入数据也作为标签值使用:
min 1/2/l Σ(i = 1→l) ||xi - gθ'(hθ(xi))||22
其中,l表示训练样本数,θ和θ'分别表示encoder和decoder要确定的参数。解码器近似于编码器的反函数,但这只是一种不严格的类比,编码器一般不是一对一的映射,所以不存在反函数。
-
- 训练可以采用反向传播算法和梯度下降法完成
- 训练完成后,只是用encoder而不是用decoder,编码器的输出结果被进一步使用。AE本身不完成分类或者其他任务,他只学习得到了输入数据的一个特征表示或者对数据的降维。为了完成分类任务,可以在它后端加上一个分类器,以自动编码器的输出作为特征向量。
- 去噪自动编码器(Denoising AE),稀疏自动编码器,收缩自动编码器和多层编码器这里不做详细介绍,可查阅雷明的《机器学习与应用》第14章。
2.3: encoder-decoder与skip connection:
两个问题值得思考:
1)仅用decoder是否可以从encoder提取的特征中重构细节?
答:对于只有少数convolution层的浅层网络,deconvolution能够重构细节。但是,当网络加深,或者网络
使用max pooling等运算时,deconvolution不能很好得重构细节。这可能是因为在卷积过程中,丢失了大量细节。
2)网络是否越深越好?
答:不是。网络加深将导致梯度消失的问题,并且很难训练。
Skip connection可以解决以上两个问题。
3、skip connection:低层特征图与相对应的高层特征图整合为新的张量,并进行后续的计算和处理。即输入与相应输出的信息直连,它建立在encoder-decoder的架构中。
连接时机:在传入激活函数之前。
连接方式:将encoder的输出与decoder相应层的输出相加,再传入激活函数,计算decoder该层的输出
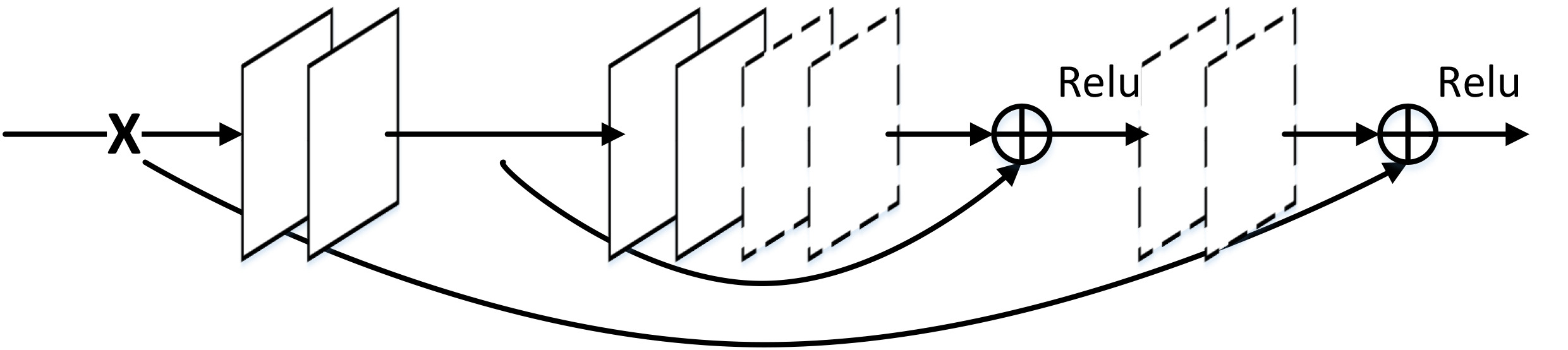
优势有2:1)前向传播细节。有助于重构清晰图像;2)后向传播梯度,有助于找到更好的局部最小值。
下图展示使用skip connection和不使用skip connection的网络对去噪的影响
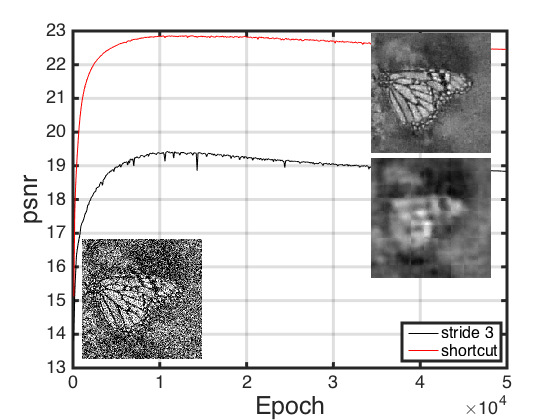
Analysis on skip connections: Recovering image details using deconvolution and skip connections;
For many image translation problems, there is a great deal of low-level information shared between the input and output, and it would be desirable to shuttle this information directly across the net.
Specifically, we add skip connections between each layer i and layer n − i, where n is the total number of layers. Each skip connection simply concatenates all channels at layer i with those at layer n − i.
-- Image-to-Image Translation with Conditional Adversarial Networks
skip connections mainly has two benefits: (1) passing image detail forwardly, which helps recovering clean images and (2) passing gradient backwardly, which helps finding better local minimum.
-- Image Restoration Using Very Deep Convolutional Encoder-Decoder Networks with Symmetric Skip Connections
下面抛出三张图有助于理解:
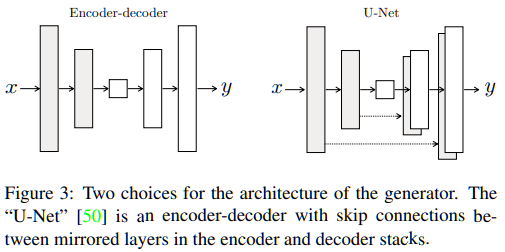
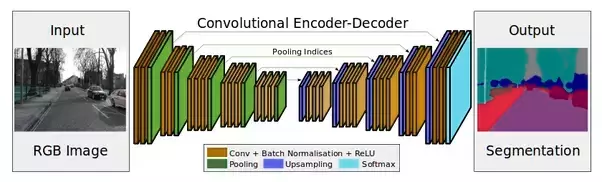
图1. U-Net的结构 图2. Encoder-Decoder的结构 图3. U-Net:带有Skip Connection的Encoder-Decoder网络
4、End-to-End:
概念:从网络一端输入Raw Data,网络另一端输出预期的结果,中间过程像一个黑盒,具体怎么操作我们不知道,也干预不了。
优势:方便。不需要人工提取海量数据的特征。这篇知乎回答很好了说明了YJangoAI专家在提取海量信息特征中付出的努力。
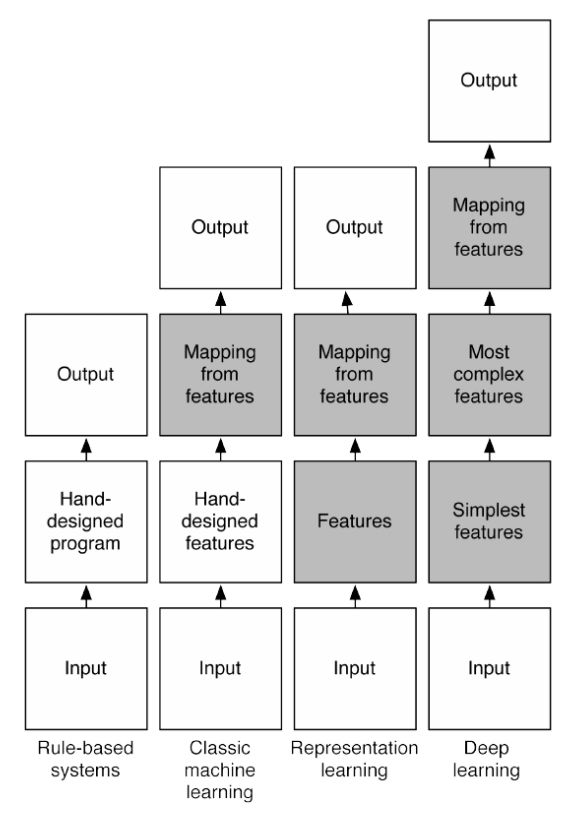
图4. 一图看懂end-to-end的deep learning的结构(第四列)
5、感受野(Receptive field)
感受野在深度学习中是一个非常重要的概念:卷积神经网络中,一个特征图内的一个像素所对应的原始输入图像的像素个数:
The receptive field is defined as the region in the input space that a particular CNN’s feature is looking at (i.e. be affected by). —— Dang Ha The Hien
摘自知乎 https://zhuanlan.zhihu.com/p/31004121
Locations in higher layers correspond to the locations in the image they are path-connected to, which are called their receptive fields.——“Fully Convolutional Networks for Semantic Segmentation”
关键信息提取:感受野指输入图像上的区域;这个区域的大小由特定卷积层上的特征决定。
举例说明:比如下图(该图为了方便,将二维简化为一维),这个三层的神经卷积神经网络,每一层卷积核的 ,
,那么最上层特征所对应的感受野就为如图所示的7x7。
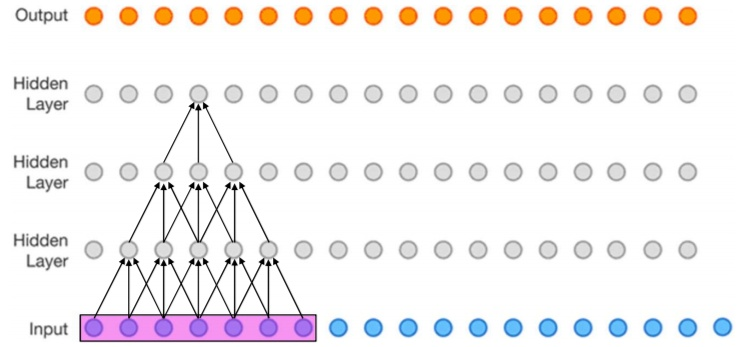
图5. 一图看懂感受野
6、转置卷积(我要大些,再大些)
可视化请访问:https://github.com/vdumoulin/conv_arithmetic/blob/master/README.md
在U-Net中,包括encoder-decoder和skip connection。encoder使得空间分辨率降低,特征数增加,decoder使得空间分辨率增大,特征数减小,skip connection用于连接对应分辨率特征图的信息。
问题:如何上采样?即让瓶颈层的bottle-neck layer的分辨率变大呢?这里介绍转置卷积操作:
- 首先从二维卷积操作讲起,直接上图吧,更多关于padding、stride的图可以查看上面的链接:
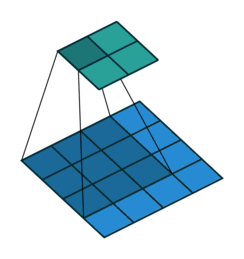
- 由于卷积操作是线性运算,于是可以写成矩阵相乘的形式:设有一个4 x 4的图像X,3 x 3的卷积核K:

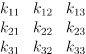
- 首先将图像和卷积核都转换为矩阵形式。图像按行拼接形成列向量x:
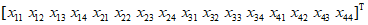
为了与卷积操作相适应,将卷积核进行如下展开形成矩阵C:

显然这个矩阵的数据是有冗余,卷积核中有些元素在这个矩阵中出现多次,这是因为卷积核要做用于图像的多个位置。这样可以将卷积运算转换成矩阵乘法:

在反向传播时已知梯度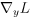 ,要得到
,要得到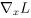 ,这种复合函数的求导公式为:
,这种复合函数的求导公式为:

这就是卷积矩阵的转置与传入的误差项的乘积。由此得到结论:正向传播时,卷积层是用卷积矩阵C与图像向量x相乘;反向传播时,是用卷积矩阵的转置与传入的误差向量相乘,将误差项传播到前一层。
- 反卷积也称为转置卷积,它的操作刚好和这个过程相反,正向传播时左乘
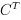 ,反向传播时左乘矩阵C。这里的反卷积和信号处理里的反卷积是两个不同的概念,它只能得到和原始输出图像尺寸相同的图像,并不是卷积运算的逆运算。
,反向传播时左乘矩阵C。这里的反卷积和信号处理里的反卷积是两个不同的概念,它只能得到和原始输出图像尺寸相同的图像,并不是卷积运算的逆运算。 - 反卷积运算有一些实际的用途:包括卷积网络可视化;全卷积网络中的上采样操作。
- 反卷积运算通过对卷积运算得到的输出图像y左乘卷积矩阵的转置
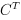 ,可以得到和原始图像尺寸x相同的图像。
,可以得到和原始图像尺寸x相同的图像。 - 使用skip connection是为了将上采样后的信息做进一步优化.
DL工具类:
1、ImageNet: 这里有一篇很好的知乎回答,能够有效解决问题。需要注意:1、先注册才能下载图片;2、注册必须使用.edu后缀的邮件;3、点击下载图片以后,先要提交申请,并不是即时下载。
2、CNN中各层级的作用和意义,可以参见这篇文档:https://github.com/zergtant/pytorch-handbook/blob/master/chapter2/2.4-cnn.ipynb。这里仅对dropout层和全连接层做笔记:
Dropout(随机失活)层:
dropout是2014年Hinton提出防止过拟合而采用的trick,增强了模型的泛化能力,它是指在深度学习网络的训练过程中,按照一定的概率将一部分神经网络单元暂时从网络中丢弃,相当于从原始的网络中找到一个更瘦的网络,简言之,随即将一部分网络的传播掐断,听起来不靠谱,但是效果很好。原文链接。
全连接层:
一般作为最后的输出层使用,卷积的作用是提取图像中的特征,最后的全连接层就是要通过这些特征进行计算,输出最终结果,无论是分类还是回归。
我们的特征都是用矩阵表示的,所以在传入全连接层之前还需要对特征进行压扁,将这些特征变成一维的向量,如果要进行分类的话,就使用softmax作为输出,如果要使用回归的话就使用linear即可。
3、python运行出现“No module named 'cv2'”的情况,解决方法:
安装OpenCv2,使用清华镜像‘ -i https://pypi.tuna.tsinghua.edu.cn/simple’
输入“pip install opencv-python -i https://pypi.tuna.tsinghua.edu.cn/simple”解决
4、安装Pytorch
进入pytorch的官网,在“get start”选项卡下,选择电脑配置,可以使用pip 并用清华镜像安装。
Pytorch 语法篇:
1、pytorch生成随机数:
1)均匀分布: torch.rand(*size, out = None) 返回一个张量
包含区间(0, 1)的均匀分布中抽取的一组随机数。张量形状由参数size决定
2)标准正态分布:torch.randn(*sizes,out = None)返回一个张量
包含了从标准正态分布(均值为0,方差为1,即高斯白噪声)中抽取的一组随机数。张量形状由参数size决定
3)离散正态分布: torch.normal(means, std, out = None)返回一个张量
返回一个张量,包含了从指定均值means和标准差std的离散正态分布中抽取的一组随机数。
标准差std是一个张量,包含每个输出元素相关的正态分布标准差。
例子:torch.normal(mean=0.5, std=torch.arange(1, 6))
-0.1505
-1.2949
-4.4880
-0.5697
-0.8996
[torch.FloatTensor of size 5]
4) 线性间距向量:torch.linspace(start, end, steps=100, out=None)返回一个张量
包含在start和end之间均匀间隔的step个点
2、训练样本数,样本通道数,单通道高和宽:
Pytorch中,torch.nn只支持小批量输入,而不支持单个样本。例如nn.Conv2d()接受4dTensor的输入与输出。这个4d tensor的size() = tensor([batchsize, channel, height, width]),下面对每一个值给出解释
batchsize:批大小(批尺寸),表示每一次训练的样本数目。
必要性:平衡内存效率与内存容量的关系
分类:全批次(一次将所有样本传入网络进行训练);mini batch(一个适当个数的训练样本数。选定一个batch的大小后,将会以batch的大小将数据输入深度学习的网络中,然后计算这个batch的所有样本的平均损失,即代价函数是所有样本的平均);
随机(batchsize = 1 的情况,暂时不懂20191214)
channel:单个训练样本的通道数
height: 单个样本的高
width: 单个样本的宽
3、Pytorch变换张量形状:
view(*args) → Tensor:返回一个有相同数据但大小不同的tensor。 调用:x = x.view(*shape)
1 >>> import torch 2 >>> x = torch.randn(1,2,3,4)# 生成4维张量tensor([batchsize, channel, height, width]) 3 >>> x 4 tensor([[[[-0.7298, -1.8570, 1.7195, 1.2817], 5 [-0.2610, -0.7315, -0.3917, 1.4104], 6 [-0.7941, 1.6163, 0.4595, 0.2690]], 7 8 [[-0.5323, -0.2535, -0.6921, 0.5795], 9 [ 1.4046, -0.5477, -1.4911, 1.2929], 10 [-0.4515, 1.0059, -0.9871, 0.6590]]]]) 11 >>> x = x.view(-1,2)#列数为2,行数计算出来 12 >>> x 13 tensor([[-0.7298, -1.8570], 14 [ 1.7195, 1.2817], 15 [-0.2610, -0.7315], 16 [-0.3917, 1.4104], 17 [-0.7941, 1.6163], 18 [ 0.4595, 0.2690], 19 [-0.5323, -0.2535], 20 [-0.6921, 0.5795], 21 [ 1.4046, -0.5477], 22 [-1.4911, 1.2929], 23 [-0.4515, 1.0059], 24 [-0.9871, 0.6590]]) 25 >>> x = torch.randn(1,2,3,4) 26 >>> x = x.view(2,-1)#行数为2,列数计算出来 27 >>> x 28 tensor([[ 0.9007, 1.8211, 0.9335, -1.4456, 0.0235, 0.6824, -0.0610, 0.6032, 29 0.2352, -1.3332, 0.3664, 1.1924], 30 [ 0.3642, 1.2124, 0.2298, -1.7909, -1.5619, -2.3198, -0.7123, -0.0062, 31 2.2308, -0.2013, 0.8443, 1.2638]]) 32 >>> x.view(-1)#只输入单个-1,输出一个行张量 33 tensor([ 0.9007, 1.8211, 0.9335, -1.4456, 0.0235, 0.6824, -0.0610, 0.6032, 34 0.2352, -1.3332, 0.3664, 1.1924, 0.3642, 1.2124, 0.2298, -1.7909, 35 -1.5619, -2.3198, -0.7123, -0.0062, 2.2308, -0.2013, 0.8443, 1.2638])
4、Epoch, Batch Size 和 Iteration
举个例子:将10kg的面粉使用面条加工机(每次只能处理2kg),加工成10kg的面条。首先得把10kg面粉分成5份2kg的面粉,然后放入机器加工,经过5次,可以将这10kg面粉首次加工成面条,但是现在的面条肯定不好吃,因为不劲道,于是把10kg面条又放进机器再加工一遍,还是每次只处理2kg,处理5次,现在感觉还行,但是不够完美;于是又重复了一遍:将10kg上次加工好的面条有放进机器,每次2kg,加工5次,最终成型了,完美了,结束了。那么到底重复加工几次呢?只有有经验的师傅才知道。
这就形象地说明:Epoch就是10斤面粉加工的次数(上面的3次);Batch Size就是每份的数量(上面的2kg),Iteration就是将10kg面粉加工完一次所使用的循环次数(上面的5次)。显然 1个epoch = BatchSize * Iteration
