
OO第四次博客作业
UML-Unified Modeling Language 统一建模语言,又称标准建模语言。是用来对软件密集系统进行可视化建模的一种语言。该语言直接提供针对性、分离的结构与行为描述手段,而且可以在后台把描述元素整合起来。
第四单元的两次作业就对UML模型文件进行解析,对其中的内容进行查询。
1 架构设计
1.1 第一次作业
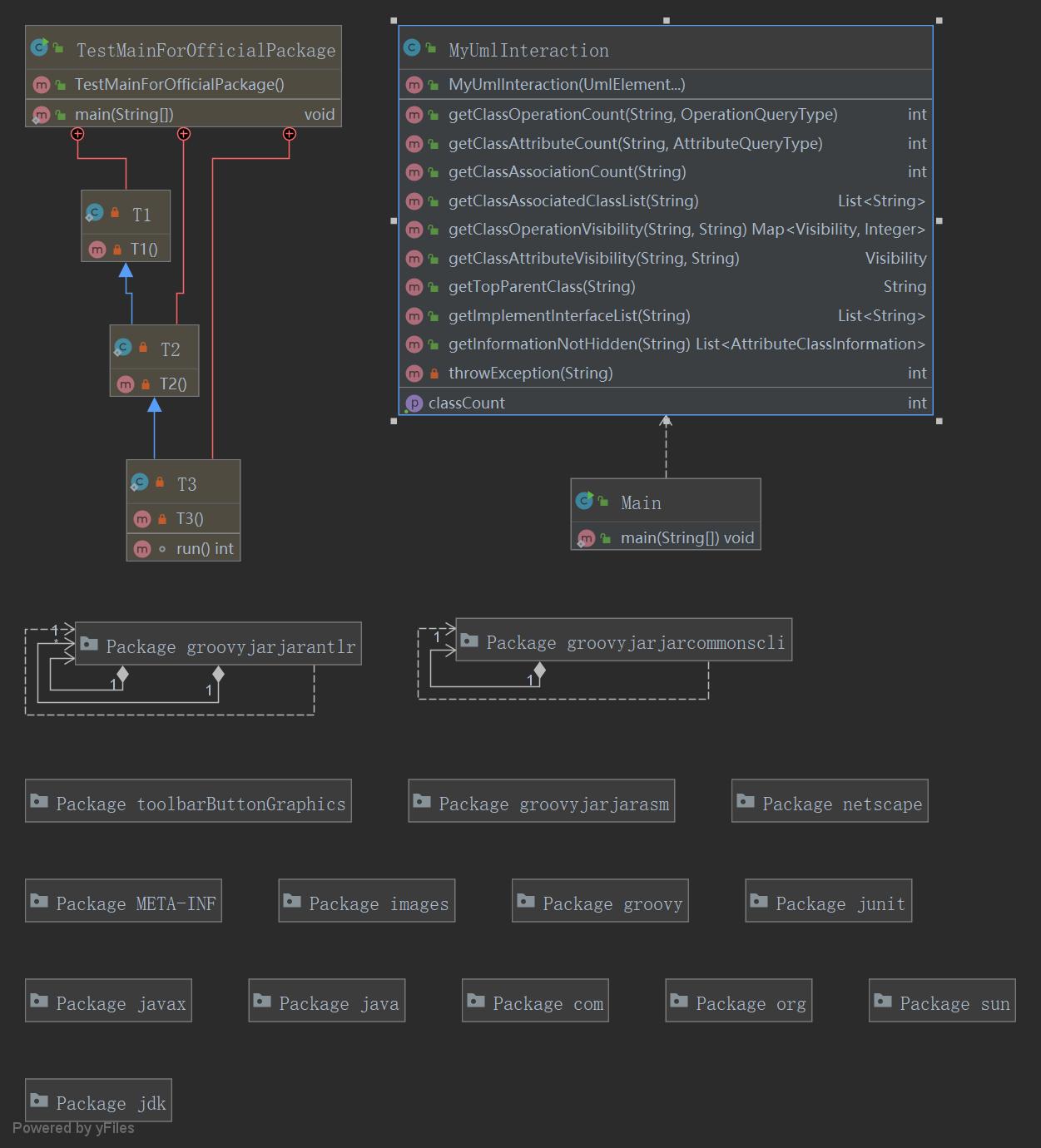
本次作业根据课程提供的Jar包,对类图进行解析提取有效信息,并给各类信息建立相应的容器,再对存储的信息进行查询操作。因此,在作业实现过程中通过需求即查询指令的输入和要求,来建立相应的类图信息存储容器。所以本次作业主要分为类图信息处理和指令操作实现两个部分。在架构设计上并没有过多的考量,在MyUmlInteraction.java中的构造方法里完成类图信息处理,随后的一系列方法中完成指令操作实现。结果就是这一个类臃肿无比,还逼近了500行的限制。本次作业的类结构关系图如下:
1.2 第二次作业
本次作业在上次作业的基础上,进一步要对UML顺序图和UML状态图进行解析,通过输入各种指令来查询顺序图,状态图中的信息,并且要对几个基本规则进行验证。
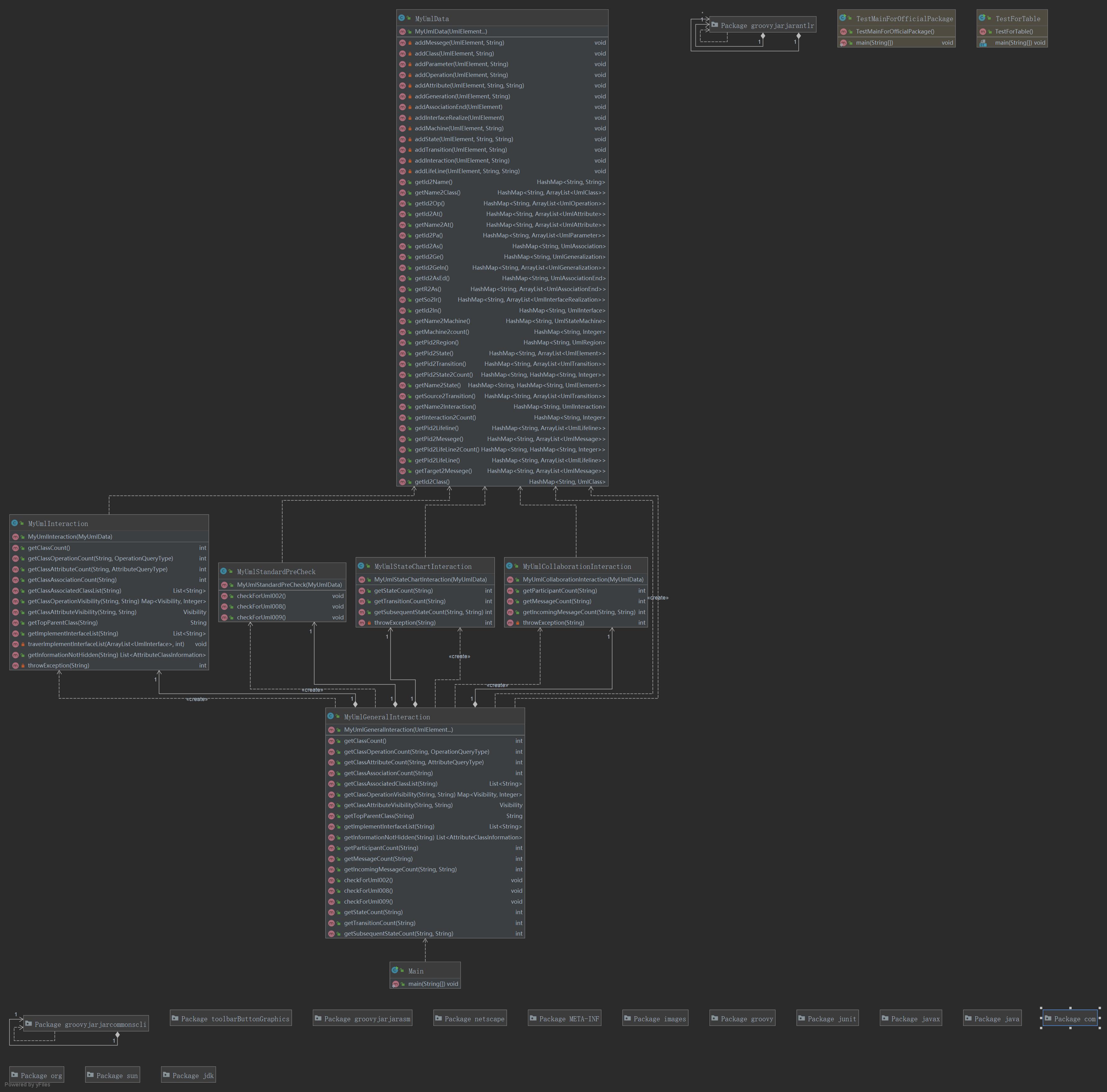
本次作业与上次作业同样要给各类信息建立对应的容器并对存储的信息进行查询操作,还要实现三个基本规则的检查。继承了上次作业的内容,但是上次臃肿无比的作业显然得进行重新设计结构,因此这次作业将数据处理独立出来,形成MyUmlData.java专职数据处理,上次作业中的类图信息处理放入MyUmlInteraction.java类中,新增顺序图信息处理MyUmlCollaborationInteraction.java类,状态图信息处理MyUmlStateChartInteraction.java类,基本规则检查MyUmlStandardPreCheck.java类,最后将所有的类整合到MyUmlGeneralInteraction.java中统一调用。这就将本次作业的代码摊薄到这一架构当中,各个类结构关系图如下:
2 架构演进
2.1 第一单元作业
第一次作业基本是面向过程的编程,根本没考虑接下来的作业的实现问题,因此基本是不可迭代开发的。第二次作业就立即推倒,当时就估计很有可能在第三次作业中增加括号嵌套的求导,这就会使得正则式匹配不再好使,因此毅然决定推倒重写,在第二次作业中不再使用正则式进行匹配;严格按照参考书,将匹配分为因子(Factor)项(Item)表达式(Expression)三级数据结构,最底层的因子又下辖幂函数,三角函数,常数的匹配方法,对应三级数据结构的就是对应三级数据结构的三级分析方法类,首先将几个三级分析类都要使用的方法扔进最顶层的分析方法类,三级分析类就直接继承到了该顶层类。第三次作业果然上了表达式的嵌套,有了第二次作业打下的结构基础和匹配基础储备,这就稍微容易,直接在上次的基础上进行写就完事。
2.2 第二单元作业
第一次作业是阉割版单电梯的调度问题,整体十分温和,这是一个典型的生产者-消费者模型,我又在《图解多线程》一书上查询了该模型的更为详细的的例子,就把电梯这一作业划分成为三部分:生产者——乘客请求,消费者——电梯运行,容器——乘客队列的数据结构。这样一来就分门别类地实现就好了。
第二次作业需要实现可以捎带的电梯,也就是可以在上楼或下楼的情况下就把上楼或下楼的乘客顺路一波带走。实现这一电梯,第一次作业的架构仍然适用,所不同的是,这次的电梯设计每个楼层都设计了相应的队列,分为上楼与下楼队列,很好的模拟了电梯上下楼捎带乘客的场景。但是其本质上仍然是生产者-消费者模型的使用。
第三次作业继续继承第二次作业,别问,问了就是无效作业。
2.3 第三单元作业
第一次作业本次作业主要实现增,删,查找三类指令,由于有CPU运行时间的限制,且增,删指令数量有限,因此需要在增,删过程中完成查询表的构造,为后续的大量查找指令赢得效率。哈希查找的使用可以降低本次作业的查找的时间开销。使用一种高效的数据结构尽量降低查询的复杂度,是本次作业需要重点考虑的问题,本次作业复杂度容易过高的地方主要有两个方面:1.MyPathContainer.java中查询路径的方法getPathById(),getPathId(),查询是否包含路径的方法containsPathId(),containsPath(),这可以在增,删指令中使用HashMap进行存储,将查询复杂度变为O(1);2.MyPath.java和MyPathContainer.java中的getDistinctNodeCount()方法,对于前者,使用HashSet保存每一条路径的不重复节点信息即可解决问题,对于后者,就需要在每次增,删指令时使用HashMap记录出不重复节点数和出现次数。
第二次作业本次作业在上一次作业的基础上,将第一次作业中零散的路径连接成图,还增加了查询两个节点是否连通和求取两个节点之间的最短路径的要求。本次作业的本质是无向图的操作,比较成熟的算法有迪杰斯特拉,弗洛伊德等算法,我考虑使用弗洛伊德算法进行处理。同时,对于上次作业中不变的部分,可以原封不动地继承过来,继续完成新功能即可。使用弗洛伊德算法主要包含以下几个步骤:1.节点映射和初始化邻接矩阵:首先每条路径的节点映射到0-250的范围之内,这时就可以构造邻接矩阵,将矩阵初始化为对角线为0其余为INF,再将每一条路径的边信息存入邻接矩阵中;2.使用算法:弗洛伊德标志性的三层for循环算法计算得到即可;如此一来,每次的查询过程就变得极其容易,直接根据节点信息到邻接矩阵中查询即可。
第三次作业是上一次作业图的操作进阶版本,将图具体化为地铁线路图,需要根据经过的边数和换乘的次数来计算票价,不满意度,也需要求解换乘次数。考虑再次使用弗洛伊德算法,进行拆点根据换乘点和不换乘点的类型依次赋不同的权值。上一次的作业只需要将所有不重复节点映射到0-250的范围即可,本次作业由于有了换乘的需求,对于同站不同线的节点采用拆点方法处理,制作<点,线,,映射>的TreeMap,求解票价时:路径的边赋值1,同站不同线的节点之间赋值2;求解换乘次数时:路径的边赋值0,同站不同线的节点之间赋值1;求不满意度时:路径的边计算出其不满意度,同站不同线的节点之间赋值32;在应用弗洛伊德求解,在查询时候,根据节点信息,取出出发点和到达点映射的节点集合(由于拆点处理,若出发点或到达点处于换乘站时,该节点映射节点数>1),遍历所有对应的矩阵元素的值,取其最小值即为所求。
2.4 第四单元作业
本单元作业分析见“1 架构设计。
3 测试演进
第一单元的表达式作业测试比较零散,一般想到哪一个坑点就测试哪里,测试比较迷,所以第一单元总是会有各种bug在强测中爆出来。
第二单元的多线程作业测试主要是基本功能的测试,基本功能不出问题后进行一些边界情况的测试,所以第二单元的作业测试比第一单元全面。
第三单元的图作业的测试首先是每一条查找指令的基础测试,其次是性能测试问题,算法的使用不当导致的性能bug是测试也解决不了的,必须在设计阶段就认真考虑。
第四单元的UML作业测试在写完每一条操作指令后就相应测试功能,最后全部写完以后再用全面的测试进行测试,但是第一次作业细节把控不当,在细节上有一些小问题,测试也不够充分。第二次作业测试方法与第一次一致,但测试较为全面,全面测试指令功能与基本规则,从测试角度讲这次作业测试是充分的,但是由于时间问题,权衡风险后,带着check008的一个已知bug交上去。
4 课程回顾
学完OO整个课程,才能理解吴际老师所说OO是一门“昆仑课程”,各单元作业难度逐渐增大,在每次感觉自己快不行的时候休息一周,进行回蓝回血。其中的历次作业有的如履平地,有的(几乎所有)如攀高峰。在学习过程中,收获了抗压能力,刷夜工作能力,架构设计以及性能指标的重要性,面向对象的设计方法。
5 课程建议
1. 建议通知发布更加规范,尽量避免再出现某些时候同学们信息获取出现问题导致的互相不理解和双方的麻烦。
2. 建议加强理论课与上机的衔接,虽然回头看上机内容确实不难,但是一下子要消化早上课上内容学以致用比较困难,上机如果多增加对课上知识的迁移引导和解释(比如例题+题目)应该会更好。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号