
OO第三次博客作业
1 JML语言理论基础,应用工具链情况
1.1 理论基础
JML(Java Modeling Language)是用于对Java程序进行规格化设计的一种表示语言。JML是一种行为接口规格语言 (Behavior Interface Specification Language,BISL),基于Larch方法构建。BISL提供了对方法和类型的规格定义 手段。所谓接口即一个方法或类型外部可见的内容。JML主要由Leavens教授在Larch上的工作,并融入了Betrand Meyer, John Guttag等人关于Design by Contract的研究成果。近年来,JML持续受到关注,为严格的程序设计提供 了一套行之有效的方法。通过JML及其支持工具,不仅可以基于规格自动构造测试用例,并整合了SMT Solver等工具 以静态方式来检查代码实现对规格的满足情况。
一般而言,JML有两种主要的用法:
(1)开展规格化设计。这样交给代码实现人员的将不是可能带有内在模糊性的自然语言描述,而是逻辑严格的规格。
(2)针对已有的代码实现,书写其对应的规格,从而提高代码的可维护性。这在遗留代码的维护方面具有特别重要的意义。
1.2 应用工具链情况
OpenJML:是一个用于Java程序的程序验证工具,能够检查用Java建模语言注释的程序的规范。
JMLUnitNG:一款自动生成测试用例来测试代码正确性的工具。
JUnit:单元测试工具,我们需要自己针对代码设置规范化样例。可以比较有针对性地检验单个方法的正确性。
2 JMLUnitNG部署验证
按照讨论区的教程,部署openJML + JMLUniting,对如下代码进行学习性测试:
package demo;
public class Demo1 {
/*@ assignable \nothing;
@ ensures \result == a + b + c;
@*/
public static int add(int a,int b,int c) {
return a + b +c;
}
public static void main(String[] args) {
add(-2147483648,2147483647,0);
}
}
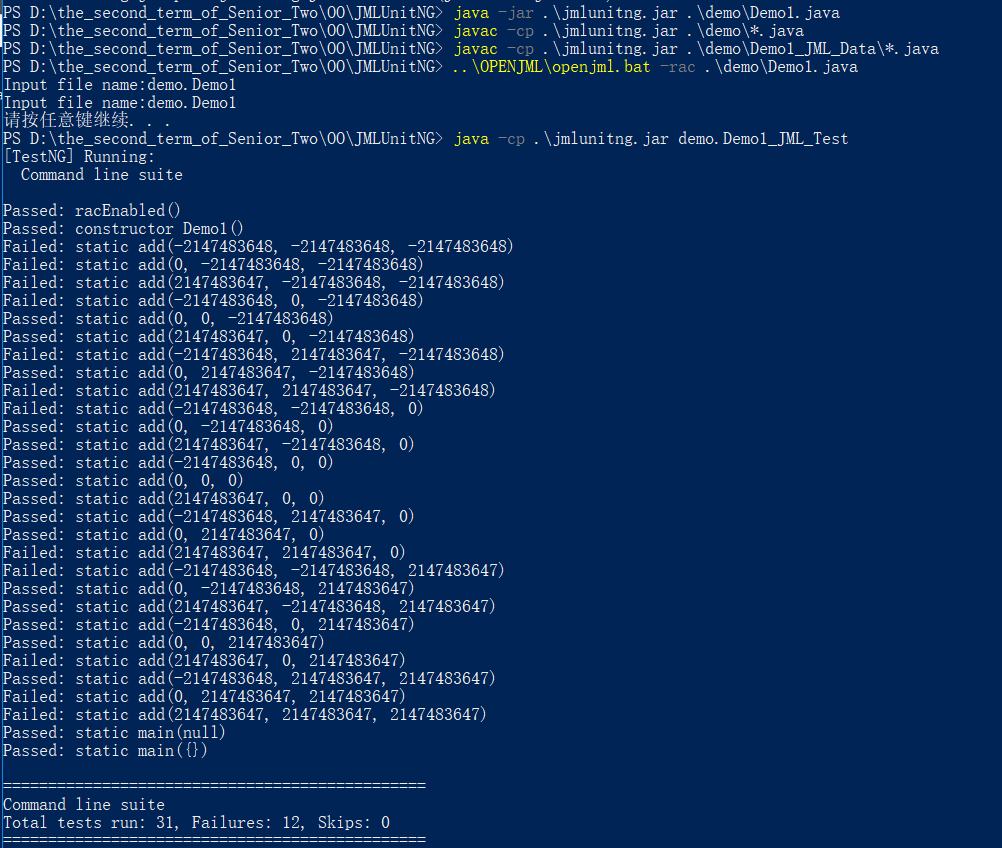
结果如下:
![]()
三次作业层层加价,每次作业都是在原有基础上进行迭代,因此,每次作业都继承上一次作业的祖传代码,在此基础上新增方法,并根据情况小规模优化实现过程,将两代作业相对友好的融合到一起。
3.1 第一次作业
整体思路 本次作业主要实现增,删,查找三类指令,由于有CPU运行时间的限制,且增,删指令数量有限,因此需要在增,删过程中完成查询表的构造,为后续的大量查找指令赢得效率。哈希查找的使用可以降低本次作业的查找的时间开销。
实现过程 使用一种高效的数据结构尽量降低查询的复杂度,是本次作业需要重点考虑的问题,本次作业复杂度容易过高的地方主要有两个方面:1.MyPathContainer.java中查询路径的方法getPathById(),getPathId(),查询是否包含路径的方法containsPathId(),containsPath(),这可以在增,删指令中使用HashMap进行存储,将查询复杂度变为O(1);2.MyPath.java``和``MyPathContainer.java``中的getDistinctNodeCount()`方法,对于前者,使用HashSet保存每一条路径的不重复节点信息即可解决问题,对于后者,就需要在每次增,删指令时使用HashMap记录出不重复节点数和出现次数。
作业框架 本次作业类图和类关联情况如下:
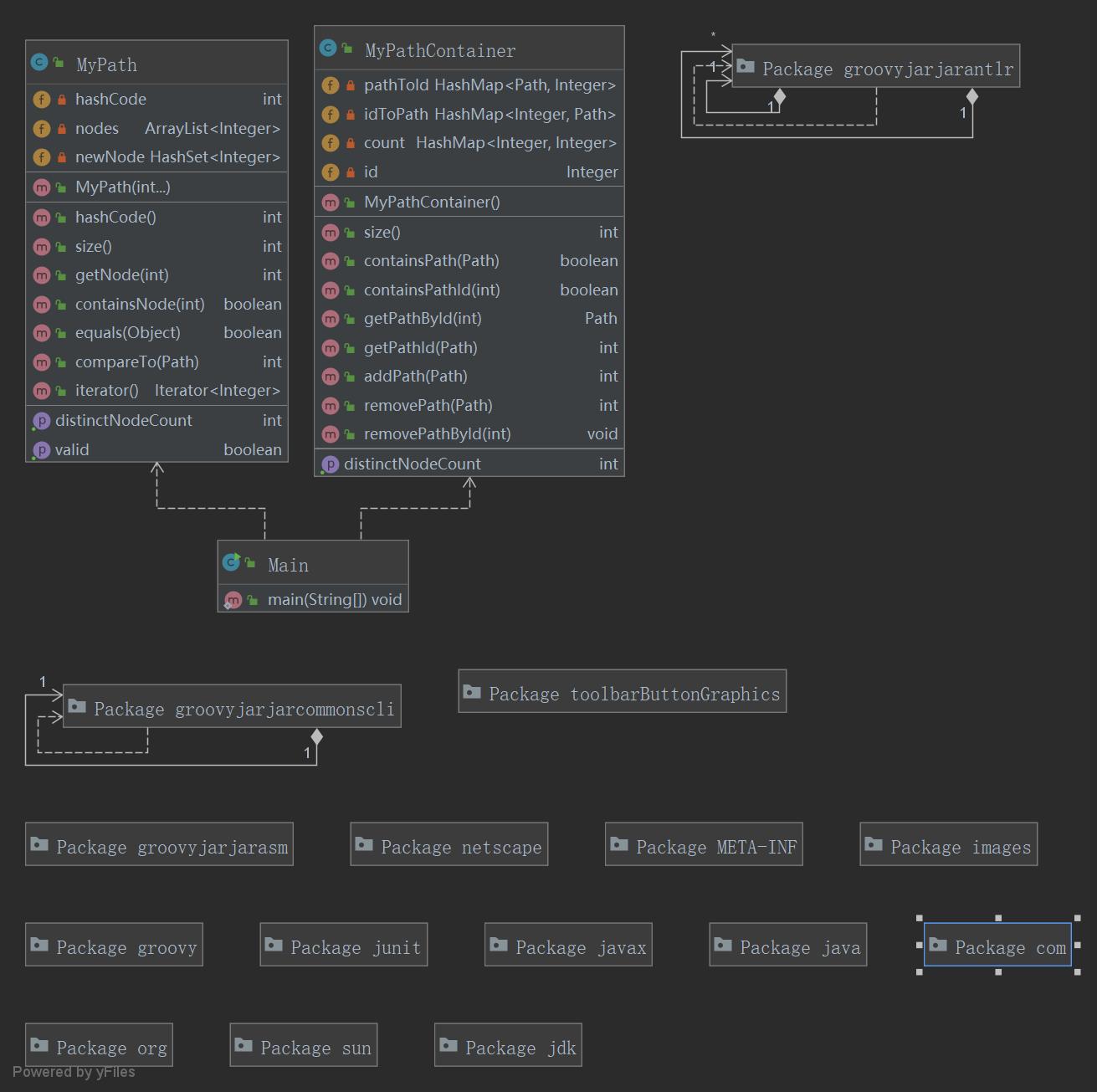
3.2 第二次作业
整体思路 本次作业在上一次作业的基础上,将第一次作业中零散的路径连接成图,还增加了查询两个节点是否连通和求取两个节点之间的最短路径的要求。本次作业的本质是无向图的操作,比较成熟的算法有迪杰斯特拉,弗洛伊德等算法,我考虑使用弗洛伊德算法进行处理。同时,对于上次作业中不变的部分,可以原封不动地继承过来,继续完成新功能即可。
实现过程 在网上查看了很多关于图的处理的算法,使用弗洛伊德算法主要包含以下几个步骤:1.节点映射和初始化邻接矩阵:首先每条路径的节点映射到0-250的范围之内,这时就可以构造邻接矩阵,将矩阵初始化为对角线为0其余为INF,再将每一条路径的边信息存入邻接矩阵中;2.使用算法:弗洛伊德标志性的三层for循环算法计算得到即可;如此一来,每次的查询过程就变得极其容易,直接根据节点信息到邻接矩阵中查询即可。
作业框架 本次作业类图和类关联情况如下:
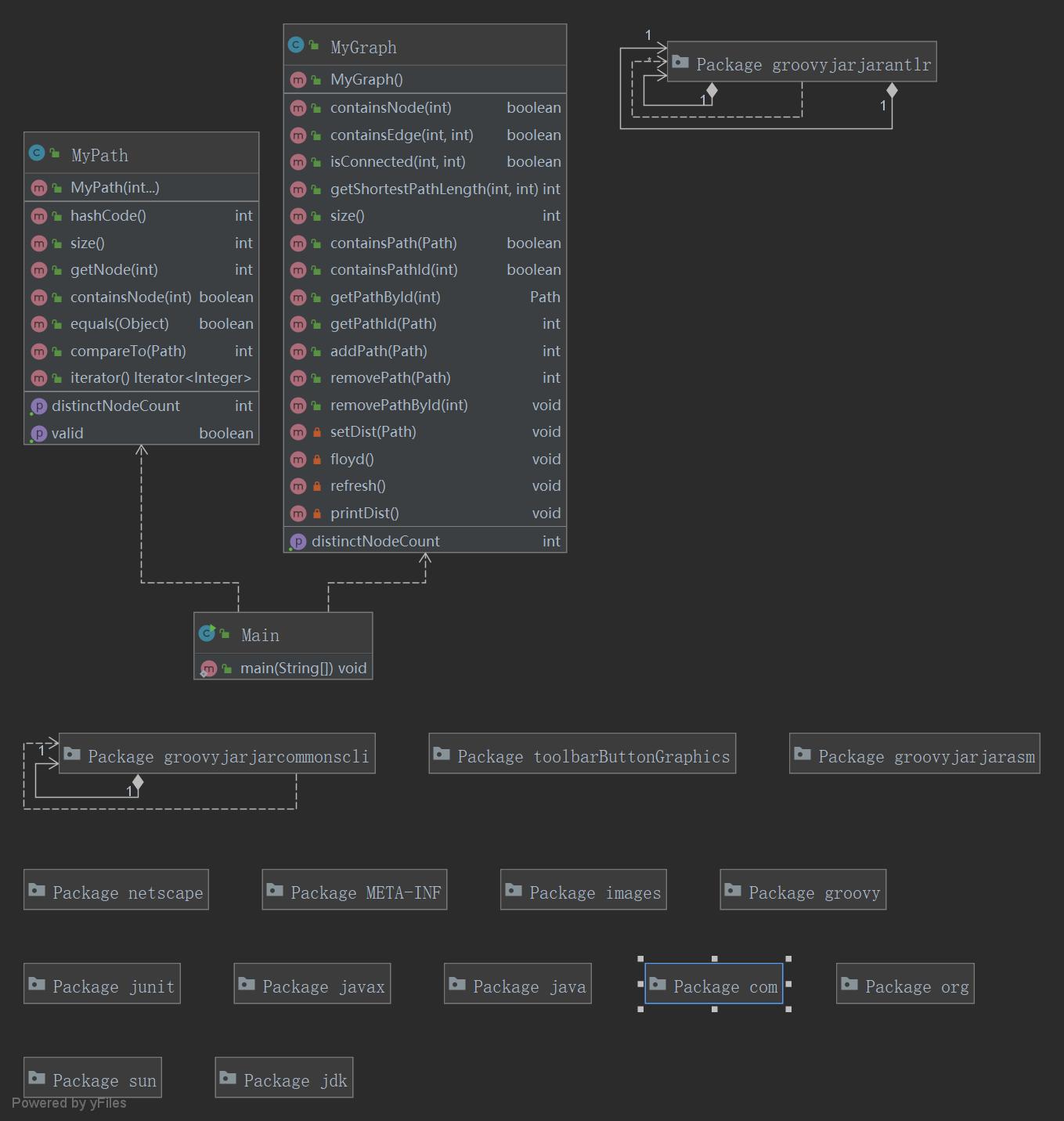
3.3 第三次作业
整体思路 本次作业在上一次作业的基础上,是上一次作业图的操作进阶版本,将图具体化为地铁线路图,需要根据经过的边数和换乘的次数来计算票价,不满意度,也需要求解换乘次数。考虑再次使用弗洛伊德算法,进行拆点根据换乘点和不换乘点的类型依次赋不同的权值。
实现过程 上一次的作业只需要将所有不重复节点映射到0-250的范围即可,本次作业由于有了换乘的需求,对于同站不同线的节点采用拆点方法处理,制作<点,线,,映射>的TreeMap,求解票价时:路径的边赋值1,同站不同线的节点之间赋值2;求解换乘次数时:路径的边赋值0,同站不同线的节点之间赋值1;求不满意度时:路径的边计算出其不满意度,同站不同线的节点之间赋值32;在应用弗洛伊德求解,在查询时候,根据节点信息,取出出发点和到达点映射的节点集合(由于拆点处理,若出发点或到达点处于换乘站时,该节点映射节点数>1),遍历所有对应的矩阵元素的值,取其最小值即为所求。
作业框架 本次作业类图和类关联情况如下:
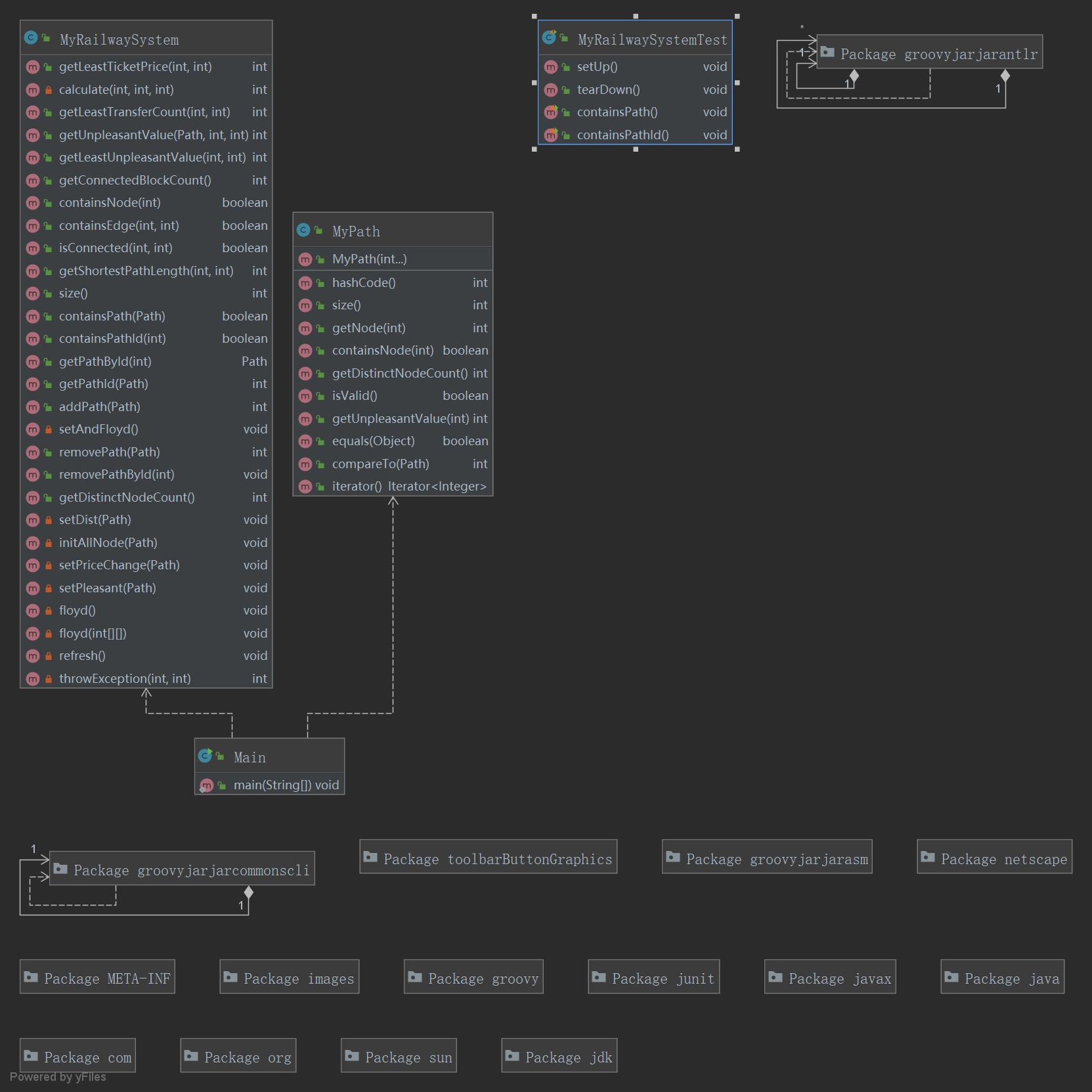
4 Bug分析和修复
4.1 第一次作业
本次作业bug主要是性能bug,对于MyPathContainer.java中的getDistinctNodeCount()方法,在每次查询时使用两层for循环遍历所有路径的所有节点硬求解不重复节点信息,结果强测爆炸了三分之一。
在修复环节中,我在每次增,删环节就使用HashMap更新当前所有路径的不重复节点,完成修复。
4.2 第二次作业
本次作业bug:如路径1 2 2 3,CONTAINS_EDGE 2 2应为Yes,CONTAINS_EDGE 1 1应为No,由于读JML规格不认真,导致这一细节没有注意,在强测中没有涉及到这一点的考察得以全部通过,但在互测中被发现。
在修复环节中,我在每次遍历路径的时候,增加一个初始值全为false的布尔数组,判断每条边是否是自身到自身,是则赋值true,完成修复。
4.3 第三次作业
本次作业bug:1.在每次增,删操作时忘记刷新节点<点,线,映射>的TreeMap,导致只增加不删除,映射关系越积越多爆栈;2.采用拆点的邻接矩阵的弗洛伊德复杂度O(n^3),爆炸。
在修复环节中,第1点已经修复,第2点正在紧张刺激地重构算法中.......
5 心得体会
本单元初步了解了JML建模语言并能够根据该语言完成代码书写。JML建模语言对代码的功能进行了描述,能够得到清晰的设计思路,减少出现bug的可能性,JML设计使用上文中的工具构造测试数据测试代码,尤其是鸡蛋数据构造测试,能够及时发现bug,简化debug的工作。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号