一文说清OpenCL框架
背景
Read the fucking official documents!--By 鲁迅A picture is worth a thousand words.--By 高尔基
说明:
- 对不起,我竟然用了一个夺人眼球的标题;
- 我会尽量从一个程序员的角度来阐述
OpenCL,目标是浅显易懂,如果没有达到这个效果,就当我没说这话; - 子曾经曰过:不懂
Middleware的系统软件工程师,不是一个好码农;
1. 介绍

- OpenCL(Open Computing Language,开放计算语言):
从软件视角看,它是用于异构平台编程的框架;
从规范视角看,它是异构并行计算的行业标准,由Khronos Group来维护; - 异构平台包括了CPU、GPU、FPGA、DSP,以及最近几年流行的各类AI加速器等;
- OpenCL包含两部分:
1)用于编写运行在OpenCL device上的kernels的语言(基于C99);
2)OpenCL API,至于Runtime的实现交由各个厂家,比如Intel发布的opencl_runtime_16.1.2_x64_rh_6.4.0.37.tgz
以人工智能场景为例来理解一下,假如在某个AI芯片上跑人脸识别应用,CPU擅长控制,AI processor擅长计算,软件的flow就可以进行拆分,用CPU来负责控制视频流输入输出前后处理,AI processor来完成深度学习模型运算完成识别,这就是一个典型的异构处理场景,如果该AI芯片的SDK支持OpenCL,那么上层的软件就可以基于OpenCL进行开发了。
话不多说,看看OpenCL的架构吧。
2. OpenCL架构
OpenCL架构,可以从平台模型、内存模型、执行模型、编程模型四个角度来展开。
2.1 Platform Model
平台模型:硬件拓扑关系的抽象描述
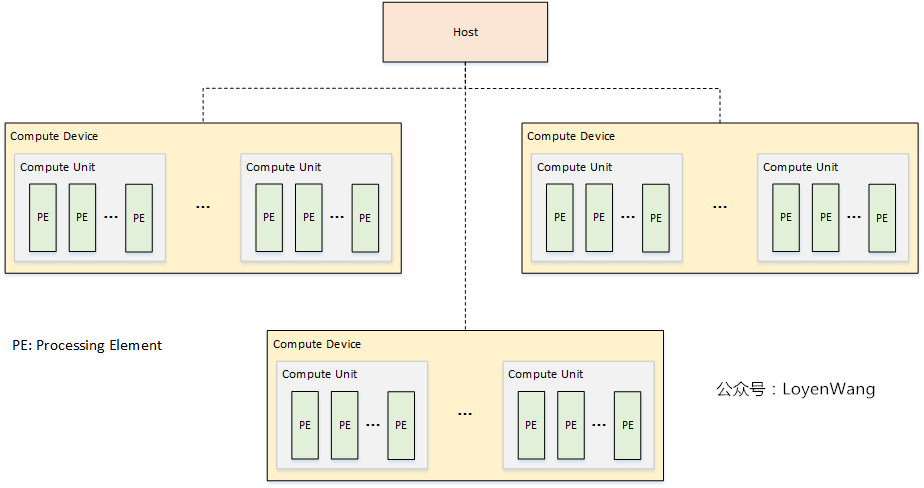
- 平台模型由一个Host连接一个或多个OpenCL Devices组成;
- OpenCL Device,可以划分成一个或多个计算单元
Compute Unit(CU); - CU可以进一步划分成一个或多个处理单元
Processing Unit(PE),最终的计算由PE来完成; - OpenCL应用程序分成两部分:host代码和device kernel代码,其中Host运行host代码,并将kernel代码以命令的方式提交到OpenCL devices,由OpenCL device来运行kernel代码;
2.2 Execution Model
执行模型:Host如何利用OpenCL Device的计算资源完成高效的计算处理过程
Context
OpenCL的Execution Model由两个不同的执行单元定义:1)运行在OpenCL设备上的kernel;2)运行在Host上的Host program;
其中,OpenCL使用Context代表kernel的执行环境:

Context包含以下资源:
- Devices:一个或多个OpenCL设备;
- Kernel Objects:OpenCL Device的执行函数及相关的参数值,通常定义在cl文件中;
- Program Objects:实现kernel的源代码和可执行程序,每个program可以包含多个kernel;
- Memory Objects:Host和OpenCL设备可见的变量,kernel执行时对其进行操作;
NDrange

- kernel是Execution Model的核心,放置在设备上执行,当kernel执行前,需要创建一个索引空间NDRange(一维/二维/三维);
- 执行kernel实例的称为work-item,work-item组织成work-group,work-group组织成NDRange,最终将NDRange映射到OpenCL Device的计算单元上;
有两种方式来找到work-item:
- 通过work-item的全局索引;
- 先查找到所在work-group的索引号,再根据局部索引号确定;
以一维为例:

- 上图中总共有四个work-group,每个work-group包含四个work-item,所以local_size的大小为4,而local_id都是从0开始重新计数;
- global_size代表总体的大小,也就是16个work-item,而global_id则是从0开始计数;
以二维为例:
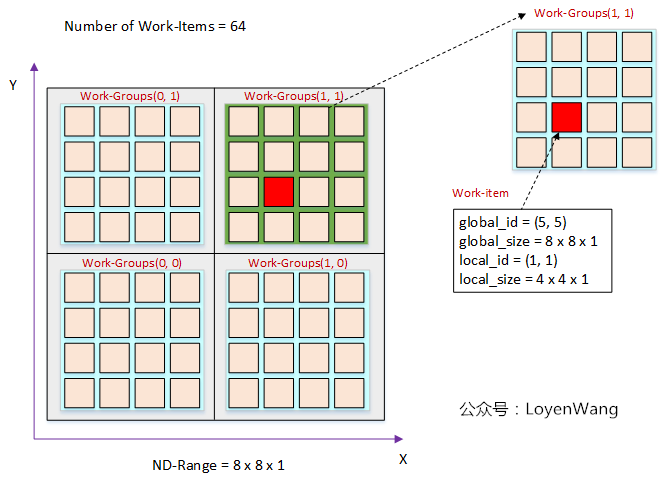
- 二维的计算方式与一维类似,也是结合global和local的size,可以得出global_id和local_id的大小,细节不表了;
三维的方式也类似,略去。
2.3 Memory Model
内存模型:Host和OpenCL Device怎么来看待数据
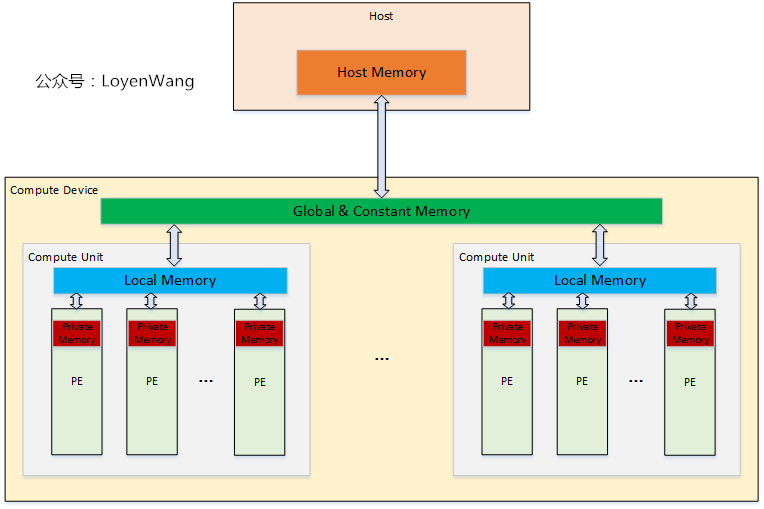
OpenCL的内存模型中,包含以下几类类型的内存:
- Host memory:Host端的内存,只能由Host直接访问;
- Global Memory:设备内存,可以由Host和OpenCL Device访问,允许Host的读写操作,也允许OpenCL Device中PE读写,Host负责该内存中Buffer的分配和释放;
- Constant Global Memory:设备内存,允许Host进行读写操作,而设备只能进行读操作,用于传输常量数据;
- Local Memory:单个CU中的本地内存,Host看不到该区域并无法对其操作,该区域允许内部的PE进行读写操作,也可以用于PE之间的共享,需要注意同步和并发问题;
- Private Memory:PE的私有内存,Host与PE之间都无法看到该区域;
2.4 Programming Model

- 在编程模型中,有两部分代码需要编写:一部分是Host端,一部分是OpenCL Device端;
- 编程过程中,核心是要维护一个Context,代表了整个Kernel执行的环境;
- 从cl源代码中创建Program对象并编译,在运行时创建Kernel对象以及内存对象,设置好相关的参数和输入之后,就可以将Kernel送入到队列中执行,也就是Launch kernel的流程;
- 最终等待运算结束,获取计算结果即可;
3. 编程流程
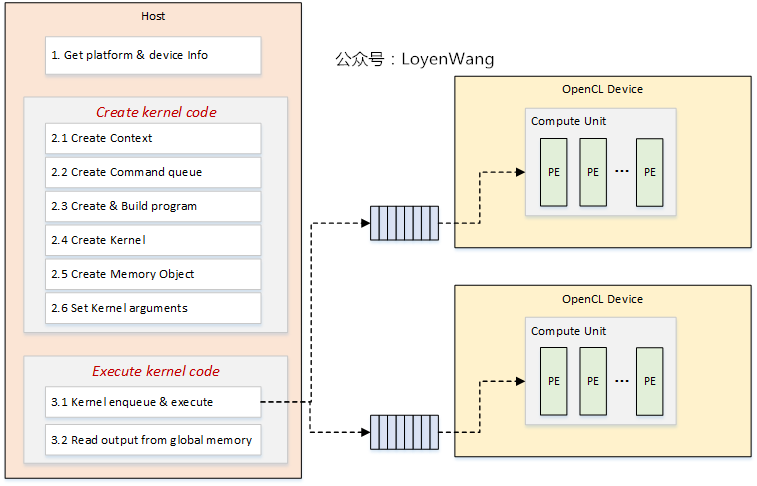
- 上图为一个OpenCL应用开发涉及的基本过程;
下边来一个实际的代码测试跑跑,Talk is cheap, show me the code!
4. 示例代码
- 测试环境:Ubuntu16.04,安装Intel CPU OpenCL SDK(
opencl_runtime_16.1.2_x64_rh_6.4.0.37.tgz); - 为了简化流程,示例代码都不做容错处理,仅保留关键的操作;
- 整个代码的功能是完成向量的加法操作;
4.1 Host端程序
#include <iostream>
#include <fstream>
#include <sstream>
#include <CL/cl.h>
const int DATA_SIZE = 10;
int main(void)
{
/* 1. get platform & device information */
cl_uint num_platforms;
cl_platform_id first_platform_id;
clGetPlatformIDs(1, &first_platform_id, &num_platforms);
/* 2. create context */
cl_int err_num;
cl_context context = nullptr;
cl_context_properties context_prop[] = {
CL_CONTEXT_PLATFORM,
(cl_context_properties)first_platform_id,
0
};
context = clCreateContextFromType(context_prop, CL_DEVICE_TYPE_CPU, nullptr, nullptr, &err_num);
/* 3. create command queue */
cl_command_queue command_queue;
cl_device_id *devices;
size_t device_buffer_size = -1;
clGetContextInfo(context, CL_CONTEXT_DEVICES, 0, nullptr, &device_buffer_size);
devices = new cl_device_id[device_buffer_size / sizeof(cl_device_id)];
clGetContextInfo(context, CL_CONTEXT_DEVICES, device_buffer_size, devices, nullptr);
command_queue = clCreateCommandQueueWithProperties(context, devices[0], nullptr, nullptr);
delete [] devices;
/* 4. create program */
std::ifstream kernel_file("vector_add.cl", std::ios::in);
std::ostringstream oss;
oss << kernel_file.rdbuf();
std::string srcStdStr = oss.str();
const char *srcStr = srcStdStr.c_str();
cl_program program;
program = clCreateProgramWithSource(context, 1, (const char **)&srcStr, nullptr, nullptr);
/* 5. build program */
clBuildProgram(program, 0, nullptr, nullptr, nullptr, nullptr);
/* 6. create kernel */
cl_kernel kernel;
kernel = clCreateKernel(program, "vector_add", nullptr);
/* 7. set input data && create memory object */
float output[DATA_SIZE];
float input_x[DATA_SIZE];
float input_y[DATA_SIZE];
for (int i = 0; i < DATA_SIZE; i++) {
input_x[i] = (float)i;
input_y[i] = (float)(2 * i);
}
cl_mem mem_object_x;
cl_mem mem_object_y;
cl_mem mem_object_output;
mem_object_x = clCreateBuffer(context, CL_MEM_READ_ONLY | CL_MEM_COPY_HOST_PTR, sizeof(float) * DATA_SIZE, input_x, nullptr);
mem_object_y = clCreateBuffer(context, CL_MEM_READ_ONLY | CL_MEM_COPY_HOST_PTR, sizeof(float) * DATA_SIZE, input_y, nullptr);
mem_object_output = clCreateBuffer(context, CL_MEM_READ_WRITE, sizeof(float) * DATA_SIZE, nullptr, nullptr);
/* 8. set kernel argument */
clSetKernelArg(kernel, 0, sizeof(cl_mem), &mem_object_x);
clSetKernelArg(kernel, 1, sizeof(cl_mem), &mem_object_y);
clSetKernelArg(kernel, 2, sizeof(cl_mem), &mem_object_output);
/* 9. send kernel to execute */
size_t globalWorkSize[1] = {DATA_SIZE};
size_t localWorkSize[1] = {1};
clEnqueueNDRangeKernel(command_queue, kernel, 1, nullptr, globalWorkSize, localWorkSize, 0, nullptr, nullptr);
/* 10. read data from output */
clEnqueueReadBuffer(command_queue, mem_object_output, CL_TRUE, 0, DATA_SIZE * sizeof(float), output, 0, nullptr, nullptr);
for (int i = 0; i < DATA_SIZE; i++) {
std::cout << output[i] << " ";
}
std::cout << std::endl;
/* 11. clean up */
clRetainMemObject(mem_object_x);
clRetainMemObject(mem_object_y);
clRetainMemObject(mem_object_output);
clReleaseCommandQueue(command_queue);
clReleaseKernel(kernel);
clReleaseProgram(program);
clReleaseContext(context);
return 0;
}
4.2 OpenCL Kernel函数
- 在Host程序中,创建program对象时会去读取kernel的源代码,本示例源代码位于:
vector_add.cl文件中
内容如下:
__kernel void vector_add(__global const float *input_x,
__global const float *input_y,
__global float *output)
{
int gid = get_global_id(0);
output[gid] = input_x[gid] + input_y[gid];
}
4.3 输出

参考
The OpenCL Specification
欢迎关注公众号,不定期分享技术文章

作者:LoyenWang
出处:https://www.cnblogs.com/LoyenWang/
公众号:LoyenWang
版权:本文版权归作者和博客园共有
转载:欢迎转载,但未经作者同意,必须保留此段声明;必须在文章中给出原文连接;否则必究法律责任
出处:https://www.cnblogs.com/LoyenWang/
公众号:LoyenWang
版权:本文版权归作者和博客园共有
转载:欢迎转载,但未经作者同意,必须保留此段声明;必须在文章中给出原文连接;否则必究法律责任

