【原创】Linux虚拟化KVM-Qemu分析(二)之ARMv8虚拟化
背景
Read the fucking source code!--By 鲁迅A picture is worth a thousand words.--By 高尔基
说明:
- KVM版本:5.9.1
- QEMU版本:5.0.0
- 工具:Source Insight 3.5, Visio
1. 概述
- KVM虚拟化离不开底层硬件的支持,本文将介绍ARMv8架构处理器对虚拟化的支持,包括内存虚拟化、中断虚拟化、I/O虚拟化等内容;
- ARM处理器主要用于移动终端领域,近年也逐渐往服务器领域靠拢,对虚拟化也有了较为完善的支持;
Hypervisor软件,涵盖的功能包括:内存管理、设备模拟、设备分配、异常处理、指令捕获、虚拟异常管理、中断控制器管理、调度、上下文切换、内存转换、多个虚拟地址空间管理等;- 本文描述的ARMv8虚拟化支持,对于理解
arch/arm64/kvm下的代码很重要,脱离硬件去看Architecture-Specific代码,那是耍流氓;
开始旅程!
2. ARMv8虚拟化
2.1 Exception Level
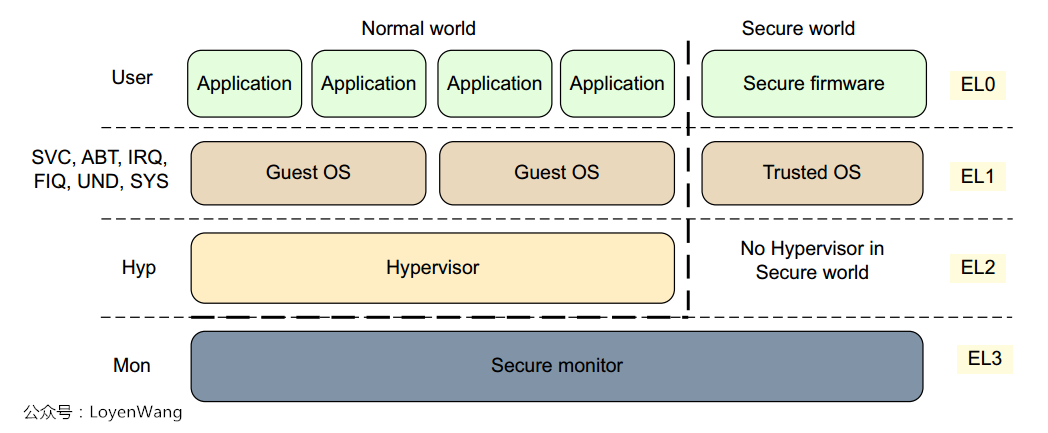
- ARMv7之前的架构,定义了一个处理器的异常处理模式,比如
USR, FIQ, IRQ, SVC, ABT, UND, SYS, HYP, MON等,各个异常模式所处的特权级不一样,比如USR模式的特权级就为PL0,对应为用户态程序运行; - 处理器的异常模式可以在特权级软件控制下进行主动切换,比如修改
CPSR寄存器,也可以被动进行异常模式切换,典型的比如中断来临时切换到IRQ模式;
ARMv7处理器的异常模式如下表所示:

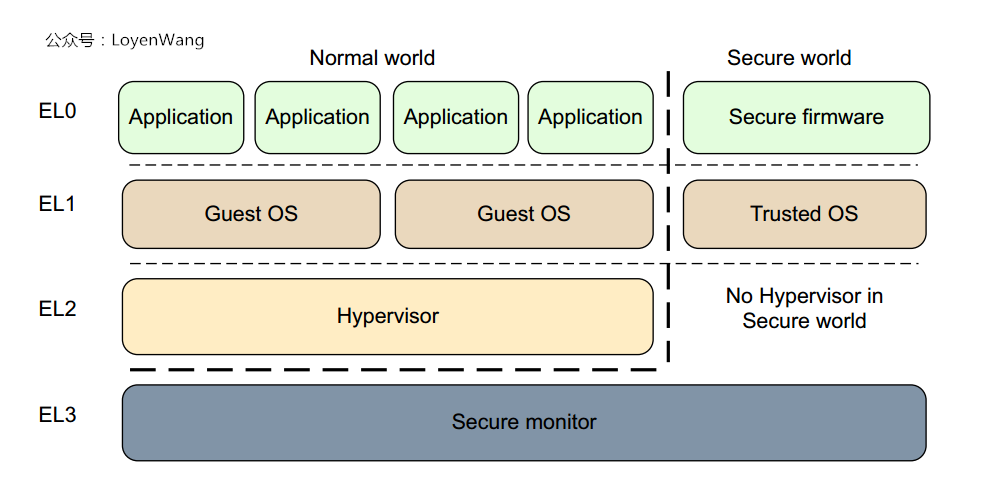
然鹅,到了ARMv8,Exception Level(EL)取代了特权级,其中处理器的异常模式与Exception Level的映射关系如下图:
- 当异常发生时,处理器将改变
Exception Level(相当于ARMv7中的处理器模式切换),来处理异常类型; - 图中可以看出
Hypervisor运行在EL2,而Guest OS运行在EL1,可以通过HVC (Hypervisor Call)指令向Hypervisor请求服务,响应虚拟化请求时就涉及到了Exception Level的切换;
2.2 Stage 2 translation
Stage 2转换与内存虚拟化息息相关,这部分内容不仅包括常规的内存映射访问,还包含了基于内存映射的I/O(MMIO)访问,以及系统内存管理单元(SMMUs)控制下的内存访问。
2.2.1 内存映射
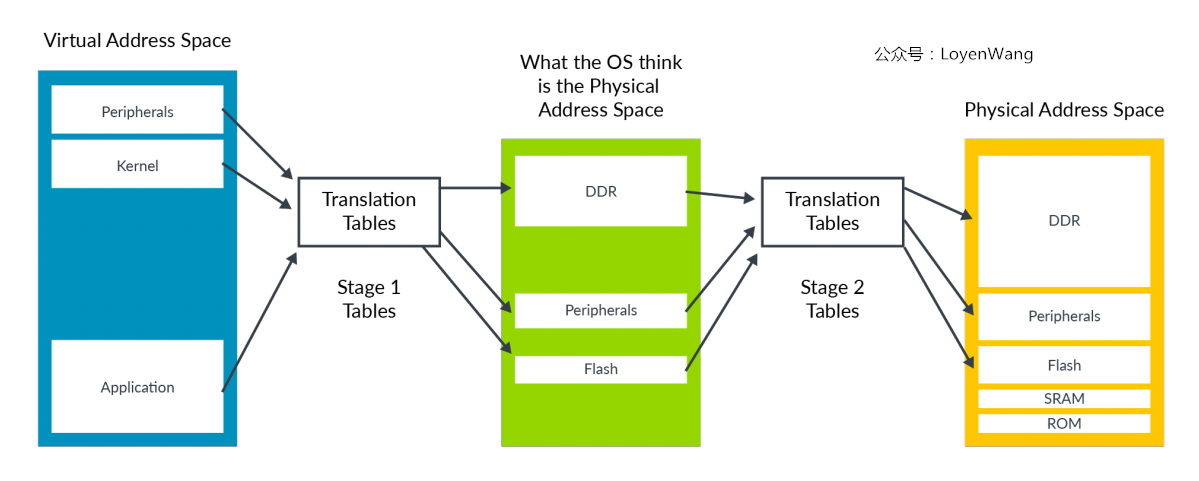
OS在访问物理内存前,需要先建立页表来维护虚拟地址到物理地址的映射关系,看过之前内存管理分析的同学应该熟悉下边这张图,这个可以认为是Stage 1转换:

- 当有了虚拟机时,情况就不太一样了,比如Qemu运行在Linux系统之上时,它只是Linux系统的一个用户进程,
Guest OS所认为自己访问的物理地址,其实是Linux的用户进程虚拟地址,到最终的物理地址还需要进一步的映射; Hypervisor可以通过Stage 2转换来控制虚拟机的内存视图,控制虚拟机是否可以访问某块物理内存,进而达到隔离的目的;
-
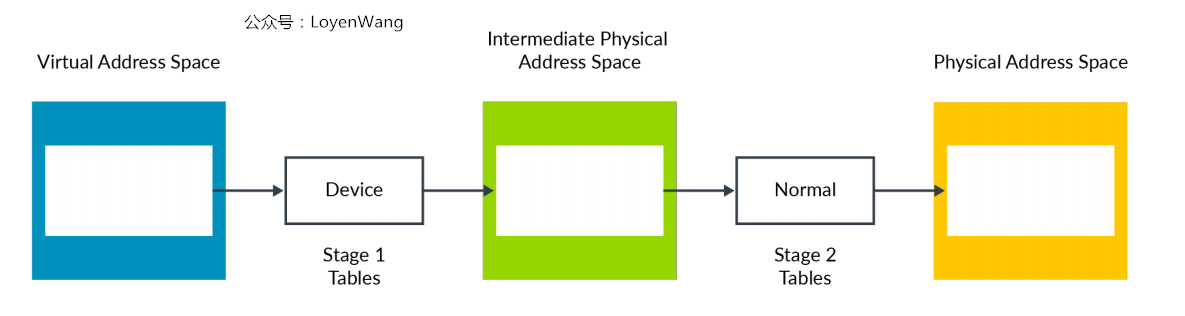
整个地址的映射分成了两个阶段:
Stage 1: VA(Virutal Address) -> IPA(Intermediate Physical Address),操作系统控制Stage 1转换;Stage 2: IPA(Intermediate Physical Address) -> PA(Physical Address),Hypervisor控制Stage 2转换;
-
Stage 2转换与Stage 1转换机制很类似,不同点在于Stage 2转换时判断内存类型是normal还是device时,是存放进页表信息里了,而不是通过MAIR_ELx寄存器来判断; -
每个虚拟机(VM,Virtual Machine)都会分配一个
VMID,用于标识TLB entry所属的VM,允许在TLB中同时存在多个不同VM的转换; -
操作系统会给应用程序分配一个
ASID(Address Space Identifier),也可以用于标识TLB entry,属于同一个应用程序的TLB entry都有相同的ASID,不同的应用程序可以共享同一块TLB缓存。每个VM都有自己的ASID空间,通常会结合VMID和ASID来同时使用; -
Stage 1和Stage 2的转换页表中,都包含了属性的相关设备,比如访问权限,存储类型等,在两级转换的过程中,MMU会整合成一个最终的也有效值,选择限制更严格的属性,如下图:
- 图中的
Device属性限制更严格,则选择Device类型; Hypervisor如果想要改变默认整合行为,可以通过寄存器HCR_EL2(Hypervisor Configuration Register)来配置,比如设置Non-cacheable,Write-Back Cacheable等特性;
2.2.2 MMIO(Memory-Mapped Input/Output)
Guest OS认为的物理地址空间,实际是IPA地址空间,就像真实物理机中一样,IPA的地址空间,也分成内存地址空间和I/O地址空间:
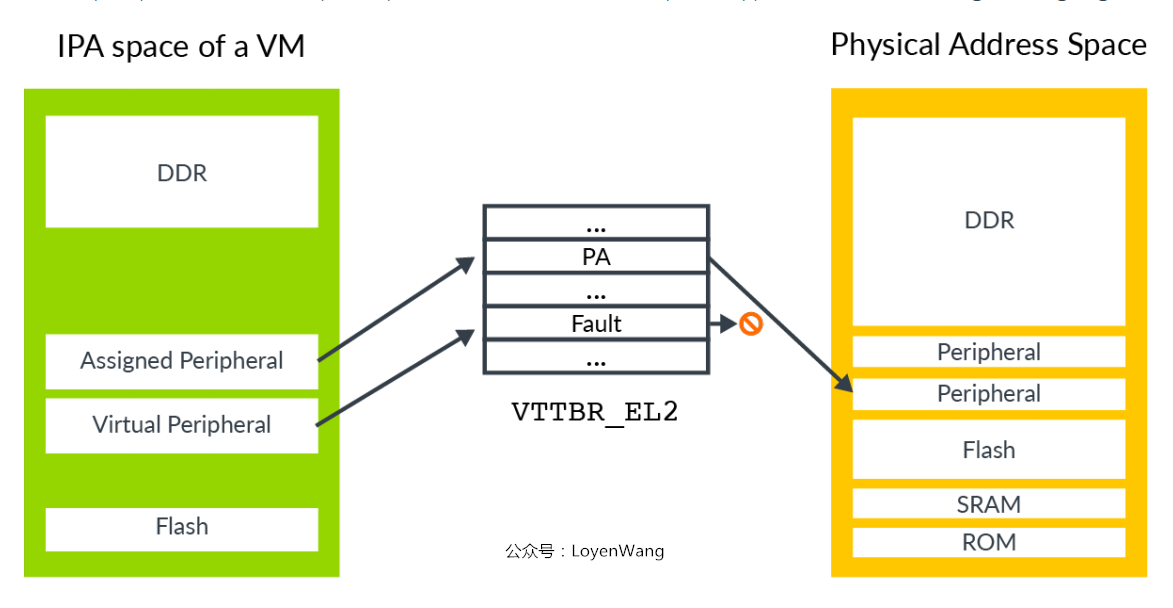
- 访问外设有两种情况:1)直通访问真实的外设;2)触发
fault,Hypervisor通过软件来模拟; VTTBR_EL2:Virtualization Translation Table Base Register,虚拟转换表基地址寄存器,存放Stage 2转换的页表;- 为了模拟外设,
Hypervisor需要知道访问的是哪个外设以及访问的寄存器,读访问还是写访问,访问长度是多少,使用哪些寄存器来传送数据等。Stage 2转换有一个专门的Hypervisor IPA Fault Address Register, EL2(HPFAR_EL2)寄存器,用于捕获Stage 2转换过程中的fault;
软件模拟外设的示例流程如下:

- 1)虚拟机VM中的软件尝试访问串口设备;
- 2)访问时
Stage 2转换被block住,并触发abort异常路由到EL2。异常处理程序查询ESR_EL2(Exception Syndrome Register)寄存器关于异常的信息,如访问长度、目标寄存器,Load/Store操作等,异常处理程序还会查询HPFAR_EL2寄存器,获取abort的IPA地址; - 3)
Hypervisor通过ESR_EL2和HPFAR_EL2里的相关信息对相关虚拟外围设备进行模拟,完成后通过ERET指令返回给vCPU,从发生异常的下一条指令继续运行;
2.2.3 SMMUs(System Memory Management Units)
访问内存的另外一种case就是DMA控制器。
非虚拟化下DMA控制器的工作情况如下:
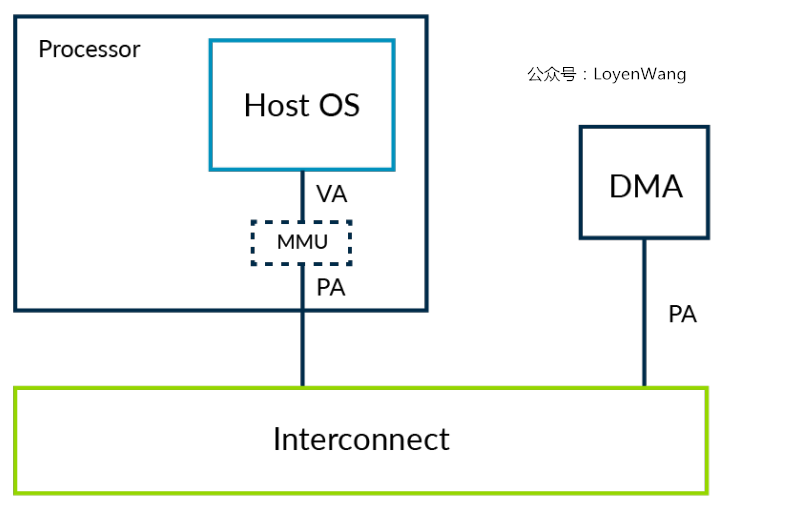
- DMA控制器由内核的驱动程序来控制,能确保操作系统层面的内存的保护不会被破坏,用户程序无法通过DMA去访问被限制的区域;
虚拟化下DMA控制器,VM中的驱动直接与DMA控制器交互会出现什么问题呢?如下图:
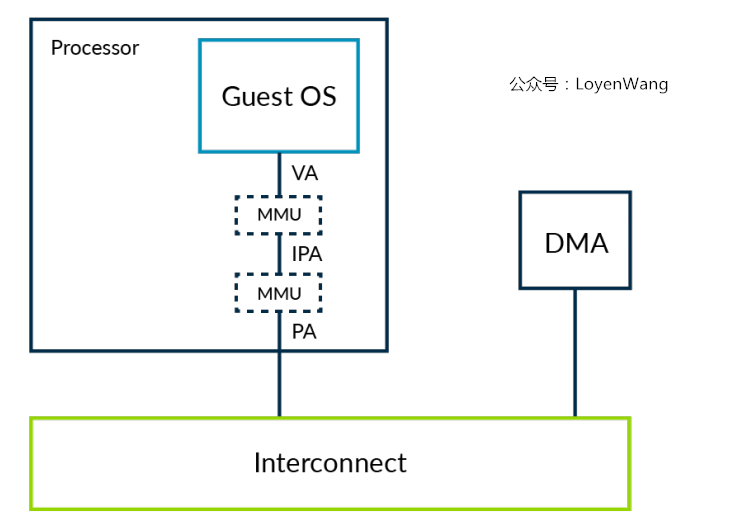
- DMA控制器不受
Stage 2转换的约束,会破坏VM的隔离性; - Guest OS以为的物理地址是IPA地址,而DMA看到的地址是真实的物理地址,两者的视角不一致,为了解决这个问题,需要捕获每次VM与DMA控制器的交互,并提供转换,当内存出现碎片化时,这个处理低效且容易引入问题;
SMMUs可以用于解决这个问题:
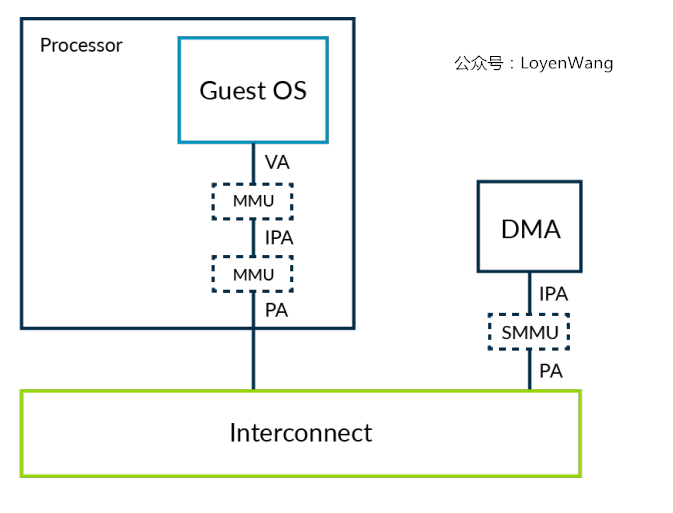
SMMU也叫IOMMU,对IO部件提供MMU功能,虚拟化只是SMMU的一个应用;Hypervisor可以负责对SMMU进行编程,以便让上层的控制器和虚拟机VM以同一个视角对待内存,同时也保持了隔离性;
2.3 Trapping and emulation of Instructions
Hypervisor也需要具备捕获(trap)和模拟指令的能力,比如当VM中的软件需要配置底层处理器来进行功耗管理或者缓存一致性操作时,为了不破坏隔离性,Hypervisor就需要捕获操作并进行模拟,以便不影响其他的VM。如果设置了捕获某个操作时,当该操作被执行时会向更高一级的Exception Level触发异常(比如Hypervisor为EL2),从而在相应的异常处理中完成模拟。
例子来了:
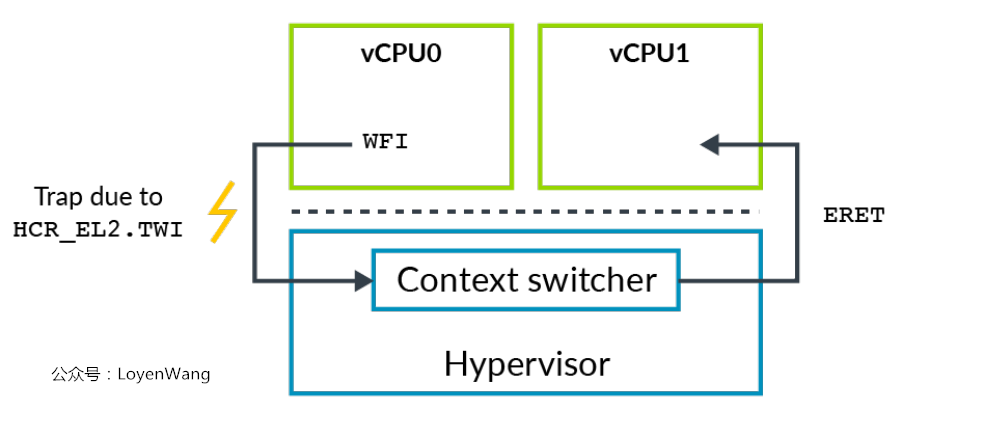
- 在ARM处理器中执行
WFI(wait for interrupt)命令,可以让CPU处于一个低功耗的状态; HCR_EL2(Hypervisor Control Register),当该寄存器的TWI==1时,vCPU执行WFI指令会触发EL2异常,从而Hypervisor可以对其进行模拟,将任务调度到另外一个vCPU即可;
捕获(traps)的另一个作用是可以用于向Guest OS呈现寄存器的虚拟值,如下:

ID_AA64MMFR0_EL1寄存器用于查询处理器对内存系统相关特性的支持,系统可能在启动阶段会读取该寄存器,Hypervisor可以向Guest OS呈现一个不同的虚拟值;- 当vCPU读取该寄存器时,触发异常,
Hypervisor在trap_handler中进行处理,设置一个虚拟值,并最终返回给vCPU; - 通过
trap来虚拟化一个操作需要大量的计算,包括触发异常、捕获,模拟、返回等一系列操作,像ID_AA64MMFR0_EL1寄存器访问并不频繁,这种方式问题不大。但是当需要频繁访问的寄存器,比如MIDR_EL1和MPIDR_EL1等,出于性能的考虑,应该避免陷入到Hypervisor中进行模拟处理,可以通过其他机制,比如提供VPIDR_EL2和VMIDR_EL2寄存器,在进入VM前就设置好该值,当读取MIDR_EL1和MPIDR_EL1时,硬件就返回VPIDR_EL2和VMIDR_EL2的值,避免了陷入处理;
2.4 Virtualizing exceptions
Hypervisor对虚拟中断的处理比较复杂,Hypervisor本身需要机制来在EL2处理中断,还需要机制来将外设的中断信号发送到目标虚拟机VM(或vCPU)上,为了使能这些机制,ARM体系架构包含了对虚拟中断的支持(vIRQs,vFIQs,vSErrors);- 处理器只有在EL0/EL1执行状态下,才能收到虚拟中断,在EL2/EL3状态下不能收到虚拟中断;
Hypervisor通过设置HCR_EL2寄存器来控制向EL0/EL1发送虚拟中断,比如为了使能vIRQ,需要设置HCR_EL2.IMO,设置后便会将物理中断发送至EL2,然后使能将虚拟中断发送至EL1;
有两种方式可以产生虚拟中断:1)在处理器内部控制HCR_EL2寄存器;2)通过GIC中断控制器(v2版本以上);其中方式一使用比较简单,但是它只提供了产生中断的方式,需要Hypervisor来模拟VM中的中断控制器,通过捕获然后模拟的方式,会带来overhead,当然不是一个最优解。
让我们来看看GIC吧,看过之前中断子系统系列文章的同学,应该见过下图:
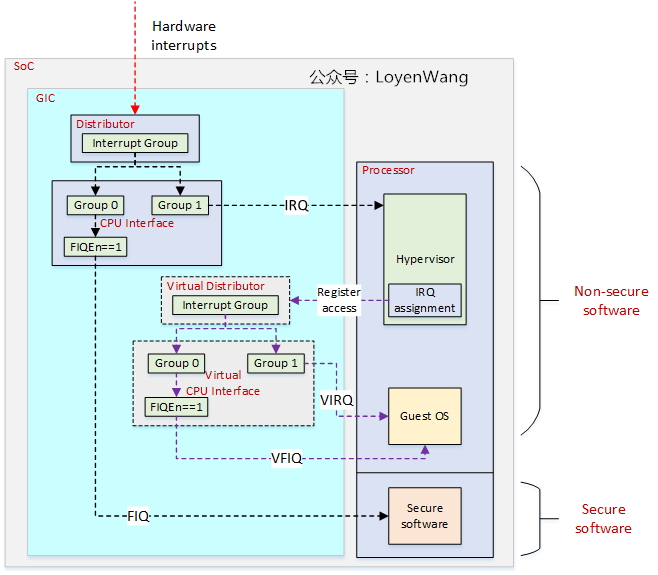
Hypervisor可以将GIC中的Virtual CPU Interface映射到VM中,从而允许VM中的软件直接与GIC进行通信,Hypervisor只需要进行配置即可,这样可以减少虚拟中断的overhead;
来个虚拟中断的例子吧:
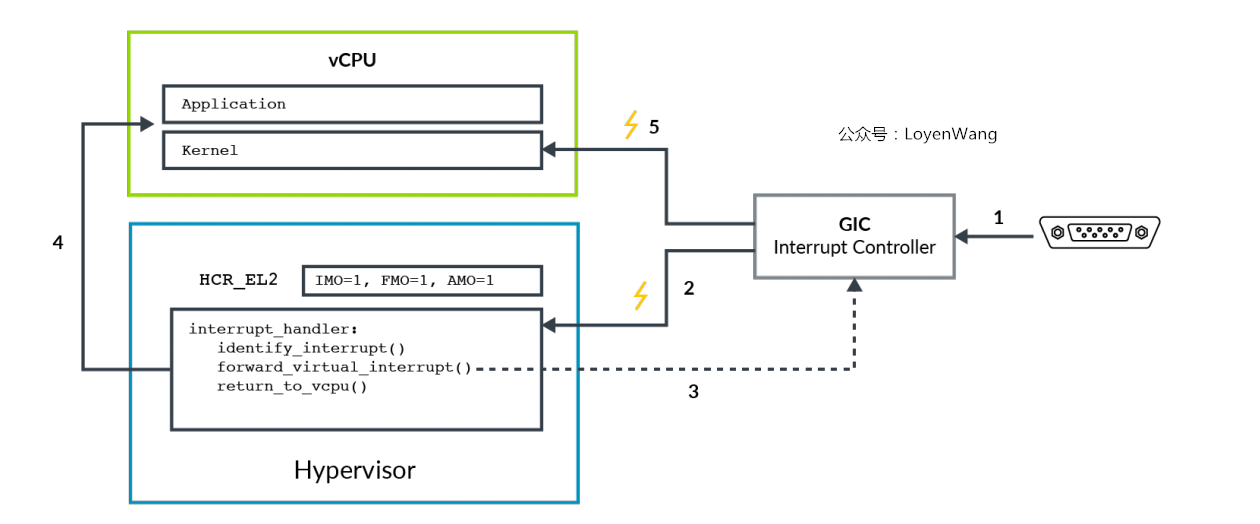
- 外设触发中断信号到GIC;
- GIC产生物理中断
IRQ或者FIQ信号,如果设置了HCR_EL2.IMO/FMO,中断信号将被路由到Hypervisor,Hypervisor会检查中断信号转发给哪个vCPU; Hypervisor设置GIC,将该物理中断信号以虚拟中断的形式发送给某个vCPU,如果此时处理器运行在EL2,中断信号会被忽略;Hypervisor将控制权返回给vCPU;- 处理器运行在EL0/EL1时,虚拟中断会被接受和处理
- ARMv8处理器中断屏蔽由
PSTATE中的比特位来控制(比如PSTATE.I),虚拟化时比特位的作用有些不一样,比如设置HCR_EL2.IMO时,表明物理IRQ路由到EL2,并且对EL0/EL1开启vIRQs,因此,当运行在EL0/EL1时,PSTATE.I比特位针对的是虚拟vIRQs而不是物理的pIRQs。
2.5 Virtualizing the Generic Timers
先来看一下SoC的内部:
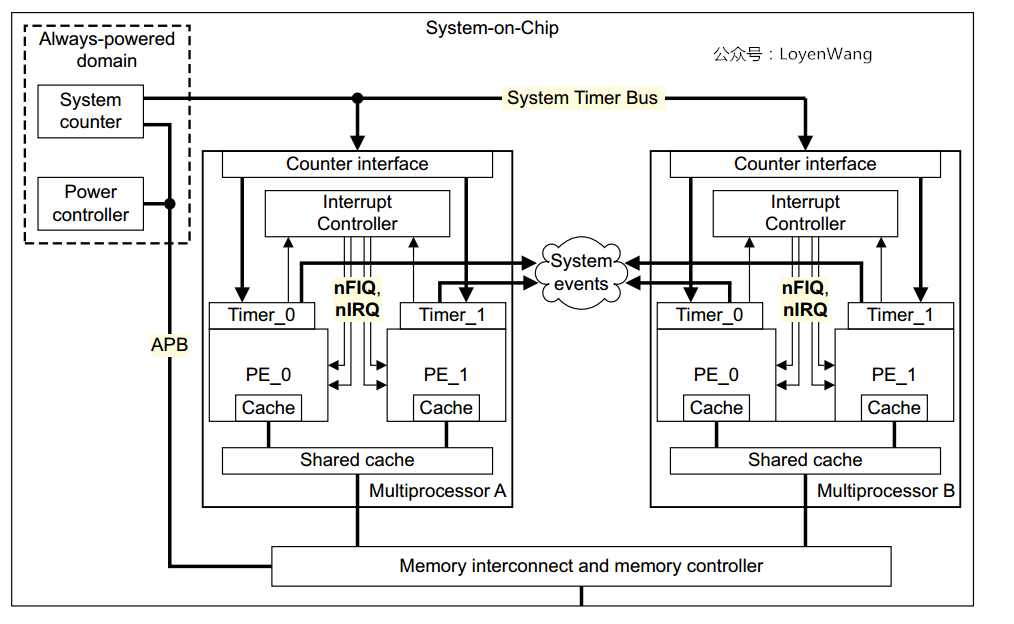
简化之后是这样的:

- ARM体系架构每个处理器都包含了一组通用定时器,从图中可以看到两个模块:
Comparators和Counter Module,当Comparators的值小于等于系统的count值时便会产生中断,我们都知道在操作系统中timer的中断就是系统的脉搏了;
下图展示虚拟化系统中运行的vCPU的时序:
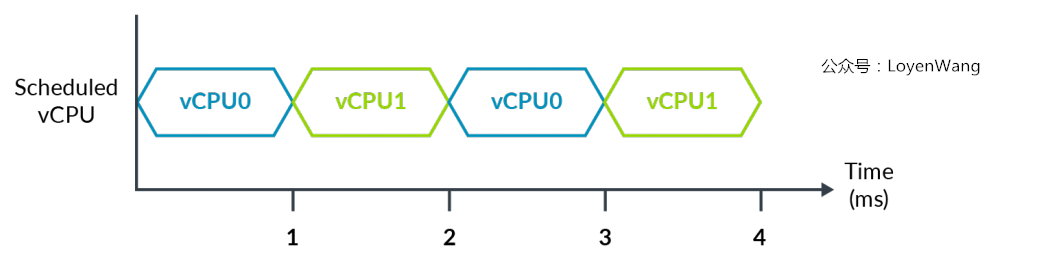
- 物理时间4ms,每个
vCPU运行2ms,如果设置vCPU0在T=0之后的3ms后产生中断,那希望是物理时间的3ms后(也就是vCPU0的虚拟时间2ms)产生中断,还是虚拟时间3ms后产生中断?ARM体系结构支持这两种设置; - 运行在
vCPU上的软件可以同时访问两种时钟:EL1物理时钟和EL1虚拟时钟;
EL1物理时钟和EL1虚拟时钟:
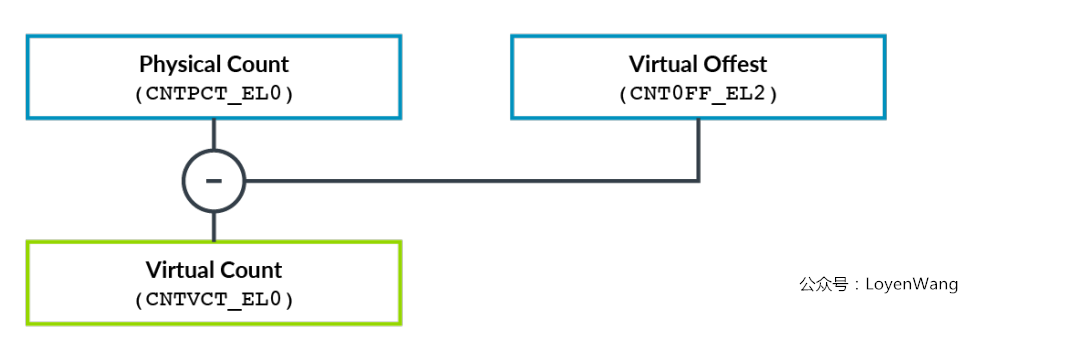
EL1物理时钟与系统计数器模块直接比较,使用的是wall-clock时间;EL1虚拟时钟与虚拟计数器比较,而虚拟计数器是在物理计数器上减去一个偏移;Hypervisor负责为当前调度运行的vCPU指定对应的偏移,这种方式使得虚拟时间只会覆盖vCPU实际运行的那部分时间;
来一张示例图:
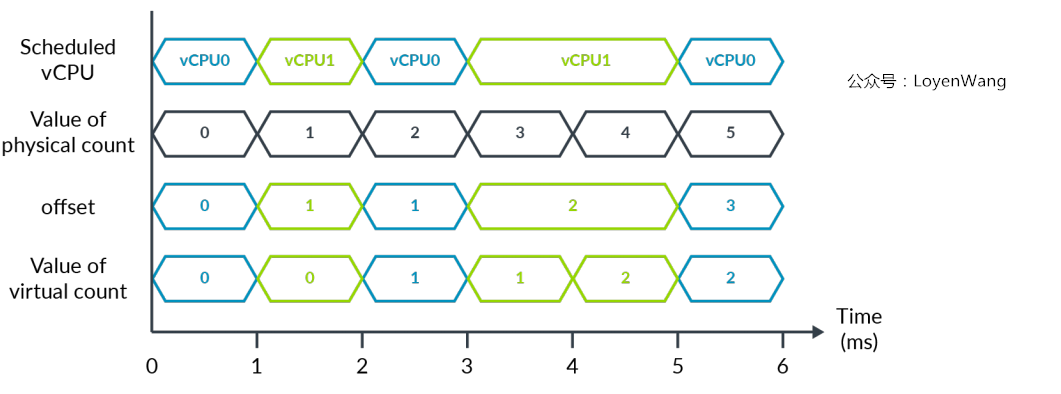
- 6ms的时间段里,每个
vCPU运行3ms,Hypervisor可以使用偏移寄存器来将vCPU的时间调整为其实际的运行时间;
2.6 Virtualization Host Extensions(VHE)
- 先抛出一个问题:通常
Host OS的内核都运行在EL1,而控制虚拟化的代码运行在EL2,这就意味着传统的上下文切换,这个显然是比较低效的; VHE用于支持type-2的Hypervisor,这种扩展可以让内核直接跑在EL2,减少host和guest之间共享的系统寄存器数量,同时也减少虚拟化的overhead;
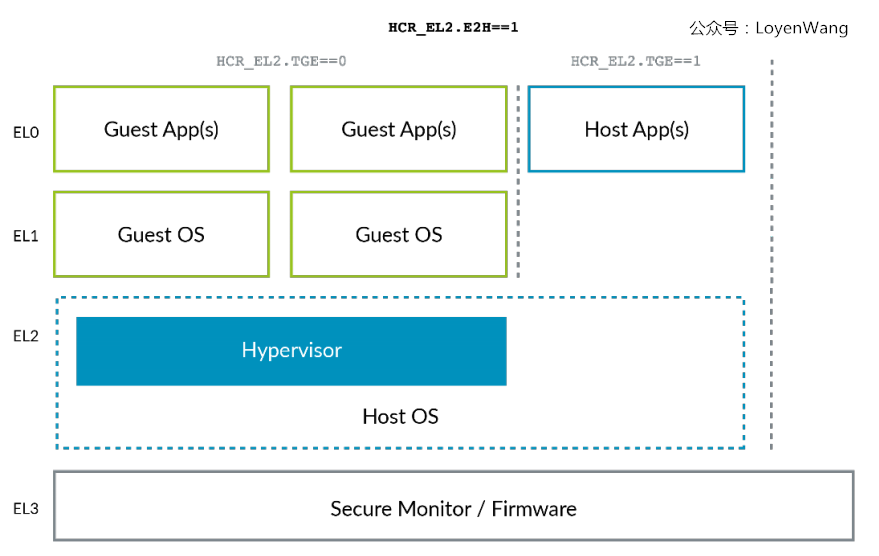
VHE由系统寄存器HCR_EL2的E2H和TGE两个比特位来控制,如下图:
VHE的引入,需要考虑虚拟地址空间的问题,如下图:
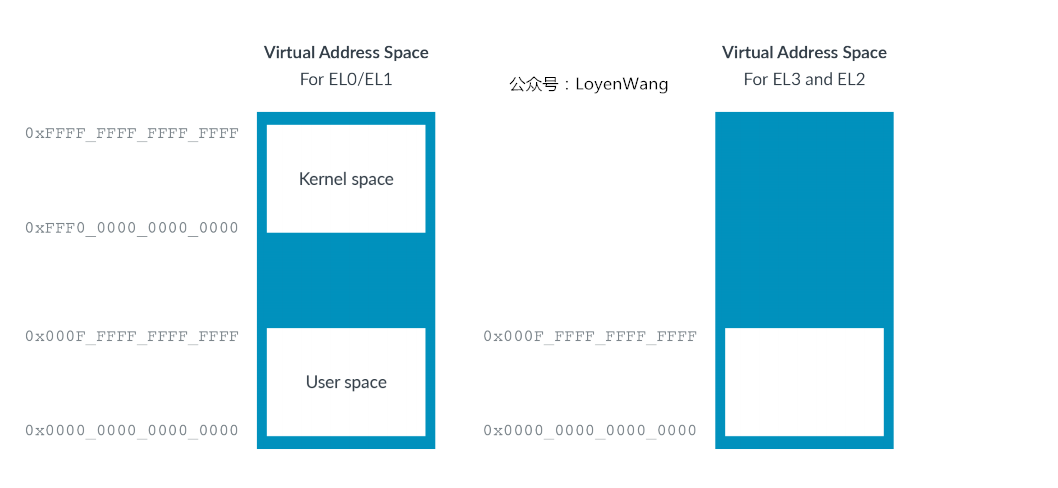
- 我们在内存子系统分析时提到过虚拟地址空间的问题,分为用户地址空间(
EL0)和内核地址空间(EL1),两者的区域不一致,而在EL2只有一个虚拟地址空间区域,这是因为Hypervisor不支持应用程序,因此也就不需要分成内核空间和用户空间了; EL0/EL1虚拟地址空间也同时支持ASID(Address Space Identifiers),而EL2不支持,原因也是Hypervisor不需要支持应用程序;
从上两点可以看出,为了支持Host OS能运行在EL2,需要添加一个地址空间区域,以及支持ASID,设置HCR_EL2.E2H的寄存器位可以解决这个问题,如下图:
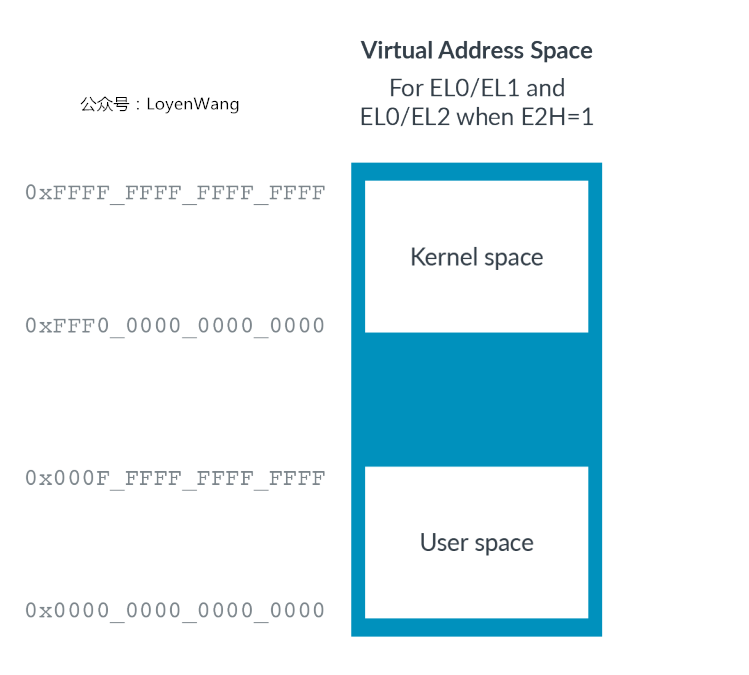
Host OS运行在EL2需要解决的另一个问题就是寄存器访问重定向,在内核中需要访问EL1的寄存器,比如TTBR0_EL1,而当内核运行在EL2时,不需要修改内核代码,可以通过寄存器的设置来控制访问流,如下图:

- 重定向访问寄存器引入一个新的问题,
Hypervisor在某些情况下需要访问真正的EL1寄存器,ARM架构引入了一套新的别名机制,以_EL12/_EL02结尾,如下图,可以在ECH==1的EL2访问TTBR0_EL1:

Host OS运行在EL2还需要考虑异常处理的问题,前边提到过HCR_EL2.IMO/FMO/AMO的比特位可以用来控制物理异常路由到EL1/EL2。当运行在EL0且TGE==1时,所有物理异常都会被路由到EL2(除了SCR_EL3控制的),这是因为Host Apps运行在EL0,而Host OS运行在EL2。
2.7 总结
- 本文涉及到内存虚拟化(stage 2转换),I/O虚拟化(包含了SMMU,中断等),中断虚拟化,以及指令
trap and emulation等内容; - 基本的套路就是请求虚拟化服务时,路由到
EL2去处理,如果有硬件支持的则硬件负责处理,否则可以通过软件进行模拟; - 尽管本文还没涉及到代码分析,但是已经大概扫了一遍了,大体的轮廓已经了然于胸了,说了可能不信,我现在都有点小兴奋了;
参考
《ArmV8-A virtualization.pdf》
《vm-support-ARM-may6-2019.pdf》
《aarch64_virtualization_100942_0100_en.pdf》
《ARM Cortex-A Series Programmer's Guide for ARMv8-A》
arm64: Virtualization Host Extension support
欢迎关注个人公众号,不定期更新技术文章。

出处:https://www.cnblogs.com/LoyenWang/
公众号:LoyenWang
版权:本文版权归作者和博客园共有
转载:欢迎转载,但未经作者同意,必须保留此段声明;必须在文章中给出原文连接;否则必究法律责任
