清北学堂2022 CSP-S 突破营
Day1
搜索剪枝
什么是搜索剪枝
常用的搜索有
深搜,它的进程近似一颗树(通常叫
而剪枝就是一种生动的比喻:把不会产生答案的,或不必要的枝条“剪掉”。
剪枝的关键就在于剪枝的判断:什么枝该剪,什么枝不该剪,在什么地方减。
剪枝的原则:
正确性,准确性,高效性。
常用的剪枝有:可行性剪枝、最优性剪枝、记忆化搜索、搜索顺序剪枝。
可行性剪枝
1.可行性剪枝。
如果当前条件不合法就不再继续搜索,直接return。这是非常好理解的剪枝,搜索初学者都能轻松地掌握,而且也很好想。一般的搜索都会加上。
一般格式:
dfs(int x)
{
if(x>n)return;
if(!check1(x))return;
....
return;
}
2.最优性剪枝。
如果当前条件所创造出的答案必定比之前的答案大,那么剩下的搜索就毫无必要,甚至可以剪掉。
我们利用某个函数估计出此时条件下答案的‘下界’,将它与已经推出的答案相比,如果不比当前答案小,就可以剪掉。
一般实现:在搜索取和最大值时,如果后面的全部取最大仍然不比当前答案大就可以返回。
在搜和最小时同理,可以预处理后缀最大/最小和进行快速查询。
一般格式:
long long ans=INF;
... Dfs(int x,...)
{
if(x... && ...){ans=....;return ...;}
if(check2(x)>=ans)return ...; //最优性剪枝
for(int i=1;...;++i)
{
vis[...]=1;
dfs(...);
vis[...]=0;
}
}
3.记忆化搜索。
记忆化搜索其实很像动态规划(DP)。
它的关键是:如果对于相同情况下必定答案相同,就可以把这个情况的答案值存储下来,以后再次搜索到这种情况时就可以直接调用。
还有就是不能搜出环来,不能互相依赖。
一般格式:
long long ans=1919810;
... Dfs(int x,...)
{
if(x... && ...){ans=....;return ...;}
if(vis[x]!=0)return f[x];vis[x]=1;
for(int i=1;...;++i)
{
vis[...]=1;
dfs(...);
vis[...]=0;
f[x]=...;
}
}
4.搜索顺序剪枝
在一些迷宫题,网格题,或者其他搜索中可以贪心的题,搜索顺序显得十分重要。我经常听见有人说(我自己也说过):“从左边搜会T,从右边搜就A了”之类的语句。
其实在迷宫、网格类的题目中,以左上->右下为例,右下左上就明显比左上右下优秀。
在一些推断搜索题中,从已知信息最多的地方开始搜索显然更加优秀。
在一些题中,先搜某个值大的,再搜某个值小的(比如树的度数,产生答案的预计(A*)),速度明显会比乱搜更快。
搜索的复杂度明显讲不清,这种剪枝自然是能加就加。
Day2
数据结构:
1.链表
链表是一个用剪头穿起来的元素,所以修改和访问的复杂度是O(n),这么看起来数组比链表更强,那么为什么要用链表呢?链表何以方便的执行插入和删除 ,这是的时间复杂度是O(1)的,
2.单调队列
队列+栈 =单调队列,
eg.滑动的窗口
解法:
(1)线段树
(2)单调队列 O(n);
int q[N];
int head = 1,tail = 0;
void push (int i)
{
while(head <= tail && z[q[tail]] >= z[i]) tail --;
tail++;
q[tail] = i;
}
signed main()
{
cin >> n >> k;
for(int i=1;i<=n;i++) cin >> z[i];
for(int i=1;i<=n;i++) push(i);
cout << z[q[head]] << endl;
for(int i=k+1;i<=n;i++)
{
// 加入第i个数
push(i);
// 删除地i-k个数
if(q[head] == i - k) head+++;
cout << q[q[head]] << en
}
}
(3) 双指针
for(int l=1;r=1;l<=n;l++)
// O(n) 双指针
{
把 l - 1 从单调队列中删掉
while(r <= n && 当前最大值 - 当前最小值 <= k)
{
push(r);
r++;
}
Ans = max(Ans . r - l);
}
3.堆
(1)插入一个数
(2)询问最大值,删除最大值(以大根堆为例)
// 声名一个堆,默认是大根堆
priority_queue < int > heap ;
把插入进去的数变为相反数就能成为小根堆(差分约束也可以这样做)!,也可以用重载运算符,还有直接定义一个小根堆
那么该如何入手写堆呢?
struct dio
{
int n;//对中有几个元素
int z[N];// z[i]代表对中地i个数的最大值
int top()
{
return z[1];
}
void push()
{
n++;
z[n] = x;
int p = n;
while(p!=1)
{
if(z[p] >z[p/2])
swap(z[p],z[p/2])
else break;
}
void pop()
{
swap(z[1],z[n]);
n--;
int p = 1;
while(p*2<=n)// p还有左儿子
{
int pp = p*2;
// 保证有右儿子
if(pp+1 <= n && z[pp+1] > z[pp]) pp = pp+1;
if(z[p] < z[pp])
{
swap(z[p] ,z[pp]); p = pp;
}
else break;
}
}
}
1 2 3 4 5 6
用一个大根堆维护所有小于中位数的数
用一个小根堆维护所有大于中位数的数
然后就比较简单了,维护两个堆的值,每次询问都取出中间的值
时间复杂度
现在思考怎么把log去掉
技巧 :怎么去找一个题的思路?
看数据范围,思考能不能用奇怪数据范围做题:
逆向思维,正难则反
4.ST表
用不上,老师没讲
当然如果想看的话可以看我这篇博客link
5.线段树
相信大家都会,所以直接放code了
#include<bits/stdc++.h>
#define lson l,m,rt<<1
#define rson m+1,,r,rt<<1|1
const int N = 2e5+5;
using namespace std;
struct node{
int l,r,sum;// lr是这个节点的左端点和右端点,所维护的区间,sum是当前这段区间的和
node()
{
l = r = sum = 0 ;
}
}e[N];
int y[N];
node operator +(const node &l,const node &r)
{
node ans;
ans.l = l.l;
ans.r = r.r;
ans.sum = l.sum + r.sun;
return ans;
}
void uodate(int rt)
{
z[rt] = z[rt<<1] + z[rt<<1|1] ;
}
// 建树,当前节点编号为rt
void built(int l,int r,int rt)
{
if(l==r)
{
z[rt].l = z[rt].r = l;
z[rt].sum = y[l];
// 区间和等于的l个数
return ;
}
int m = l+r >> 1;
built(rson);
built(rson)
uodate(rt);//更新rt节点的值
}
贪心:
时间复杂度比较低,但是不一定是最优解,局部最优选择来得到最优解,
常见思路:
1.反悔贪心,按照贪心思路打,如果不行就回溯
eg.P1650田忌赛马
解析
1.先排序,然后不不断选择(也可dp,都比较简单1、开始也是先排序,可以使用sort快排;
2、然后将田忌最大的马与国王进行比较;
3、如果田忌最大的马大于国王,那么就胜场++;
4、如果田忌最大的马小于国王,那么就一定会输,所以用田忌最小的马输给国王最大的马;
6、如果田忌最大的马等于国王,那么就比较最小的马;
如果田忌最小的马大于国王,那么胜场++;
7、如果田忌最小的马小于国王,那么就输给国王;
8、如果田忌最小的马等于国王,就用田忌最小的马对国王最大的马,如果国王最大的马大,那么财产要减200;
还有动规的
1.思路
不妨用贪心思想来分析一下问题。因为田忌掌握有比赛的“主动权”,他总是根据齐王所出的马来分配自己的马,所以这里不妨认为齐王的出马顺序是按马的速度从高到低出的。由这样的假设,我们归纳出如下贪心策略:
如果田忌剩下的马中最强的马都赢不了齐王剩下的最强的马,那么应该用最差的一匹马去输给齐王最强的马。
如果田忌剩下的马中最强的马可以赢齐王剩下的最强的马,那就用这匹马去赢齐王剩下的最强的马。
如果田忌剩下的马中最强的马和齐王剩下的最强的马打平的话,可以选择打平或者用最差的马输掉比赛。
2.反例
光是打平的话,如果齐王马的速度分别是1 2 3,田忌马的速度也是1 2 3,每次选择打平的话,田忌一分钱也得不到,而如果选择先用速度为1的马输给速度为3的马的话,可以赢得200两黄金。
光是输掉的话,如果齐王马的速度分别是1 3,田忌马的速度分别是2 3,田忌一胜一负,仍然一分钱也拿不到。而如果先用速度为3的马去打平的话,可以赢得200两黄金
3.解决方案
通过上述的三种贪心策略,我们可以发现,如果齐王的马是按速度排序之后,从高到低被派出的话,田忌一定是将他马按速度排序之后,从两头取马去和齐王的马比赛。有了这个信息之后,动态规划的模型也就出来了!
4.DP方程
设
状态转移方程如下:
其中
结果用最大的乘以200即可。
5.解释
为什么
因为你无论怎么样都是从前或者从后面取马,而
eg.分糖果
每个人有一个分数
问老师最少准备多少糖果
考虑到,分数最低的分配是不受任何限制的。
从分数低的开始分配。
按照分数排序。
然后
(如果还没分配
这样的复杂度是
是否存在复杂度为
注意到,对于
如果
否则
则左影响和右影响分开处理。
先从左向右扫,若
然后从右往左,若
复杂度为
启发式合并:
这个还不会,到时候再学
分治:
分治分治,分而治之,分支就是把一个大问题转化为好多子问题来做,最终合并得到答案
归并排序
快速幂
把数字差分为
二分查找:
注意
求最小值最大,或者是最大值最小的问题
三分
求一个单峰函数的极值
double S(double l,double r)
{
whiel(l+ept < r)
{
m1 = ( 2 * l + r) /3;
m2 = (l + 2 * r) / 3;
double f1 = F(n1) , f2 = F(m2);
if(f1<f2) l = f1;
else r = f2;
}
return l;
}
这个也是不会,之后再学
Day3
1.线段树:
修改操作(接昨天的代码)
struct node{
int l,r,sum,lazt;
void color(int v)
{
lazy += v;
sum += v * (r-l+1);
}
}z[N];
void push_up(int pos)
{
// 从模板一粘贴过来的
if(!tree[pos].lazy) return ;
tree[lson].lazy += tree[pos].lazy;
tree[rson].lazy += tree[pos].lazy;
tree[lson].sum += tree[lson].len * tree[pos].lazy;
tree[rson].sum += tree[rson].len * tree[pos].lazy;
tree[pos].lazy=0;
}
void modify(int l,int r,int rt,int nowl,int nowr,v)
{
// 区间+ v 操作
if(nowl <= l && r <= nowr)
{
z[rt].color(v);
// 给rt这个节点打一个+v的标记
return ;
}
int m = l+r>>1;
push_up(rt);
// push_up代表lazy下传,把标记告诉儿子
// 不管是询问还是修改,都要加上push_up,上一个代码没加
// 但是push_up一定要放在if括号之后,因为最后一层是不会被push_up的,有可能导致RE
if(nowl <= m) modify(lson,nowl,nowr,v);
if(m<mowr) modify(rson,nowl.nowr,v);
update(rt);//更新sum的值
}
做点段数题目思考:
1.维护什么东西
2.维护什么标记
3.左右儿子怎么合并
4.标记怎么影响索要维护的东西
ps:如果用了这种方式,那就只需要改变前面的代码就行了
斐波那契数列:(线段树版)
#define root 1,n,1
#define lson l,m,rt<<1
#define rson m+1,r,rt<<1|1
// 费波马切
//第一项是a 第二项是b x*a + y*b
f[1][0] = 1;f[1][1] = 0;//f[1] = 1*a+0*b
f[2][0] = 0;f[2][1] = 1;//f[2] = 0*a+1*b
//f[i][0] * a + f[i][1] * b 斐波那契数列第i项的值
for (int i=3;i<=n;i++)
{
f[i][0] = f[i-2][0] + f[i-1][0];
f[i][1] = f[i-2][1] + f[i-1][1];
}
//对f求前缀和 得到sum
斐波那契数列前i项的和=sum[i][0]*a+sum[i][1]*b
struct node//线段树上的节点信息
{
int l,r;//这个节点左端点和右端点 所维护的区间
int sum;//当前这段区间的和
int a,b;//这段区间第一个数被加上了a 第二个数被加上了b 但这件事没有告诉儿子们
node()
{
l=r=sum=0;
a=b=0;
}
void color(int a_,int b_)//当前区间第一个数+a_ 第二个数+b_
{
a += a_;
b += b_;
sum += ::sum[r-l+1][0] * a_ + ::sum[r-l+1][1] * b_;
}
}z[];
node operator+(const node &l,const node &r)//l左儿子 r右儿子
{
node ans;
ans.l = l.l;
ans.r = r.r;
ans.sum = l.sum + r.sum;
return ans;
}
void update(int rt)
{
z[rt] = z[rt<<1] + z[rt<<1|1];
}
void push_col(int rt)
{
if (z[rt].col)
{
z[rt<<1].color(z[rt].col);
z[rt<<1|1].color(z[rt].col);
z[rt].col=0;
}
}
void build(int l,int r,int rt)//建树 当前线段树节点编号为rt 并且当前区间为l~r
{
if (l==r)//到最底层
{
z[rt].l = z[rt].r = l;
z[rt].sum = y[l];//这段区间的和就等于第l个数
return;
}
int m=(l+r)>>1;//(l+r)/2
//左儿子所对应的区间 [l,m] 右儿子所对应的区间 [m+1,r]
build(lson);//build(l,m,rt*2)
build(rson);//build(m+1,r,rt*2+1)
update(rt);//更新rt这个节点的值
}
node query(int l,int r,int rt,int nowl,int nowr)
//当前线段树节点所对应的区间是l~r
//当前线段树节点编号是rt
//询问的区间是nowl~nowr
{
if (nowl <= l && r <= nowr) return z[rt];
push_col(rt);//把标记告诉儿子
int m=(l+r)>>1;
if (nowl <= m)//询问区间和左儿子有交集
{
if (m < nowr) return query(lson,nowl,nowr) + query(rson,nowl,nowr);//和右儿子有交集
else return query(lson,nowl,nowr);//只和左儿子有交集
}
else return query(rson,nowl,nowr);//只和右儿子有交集
}
void modify(int l,int r,int rt,int nowl,int nowr,int v)
//当前线段树节点为l,r,rt
//修改的区间为nowl~nowr
//修改的操作为区间+v
{
if (nowl <= l && r <= nowr)
{
z[rt].color(v);//给rt这个节点打一个+v的标记
return;
}
push_col(rt);//把标记告诉儿子
int m=(l+r)>>1;
if (nowl<=m) modify(lson,nowl,nowr,v);
if (m<nowr) modify(rson,nowl,nowr,v);
update(rt);
}
build(root);
int l,r;
node ans = query(root,l,r);

例题:
找出k个数相乘,求所有方案的综合,
struct 中维护一个

这里就是
例题:
给你N个数
直接从左到右直接扫一编,记录一下到现在为止的最大值?O(n)暴力过
GSS4:
给定N个数M此操作:
1.将[l,r]开根下取整
2.询问[l,r]的和
提示重点:开跟下取整后变成1之后就不会变了(差不多开跟10次就是1了)
维护:这段区间的和,这段区间的最大值。
1.maxv == 1 ,那就直接return
2.maxv !=1 暴力修改做儿子和右儿子,然后再看看maxv,复杂度(10nlogn)

做做 GSS Qtree Cot 系列的题目
例题: [BZOJ 3333]:
长度为N的序列,每次给出一个位置i,令所有操作在i之后前数值不超过i的数重排列并放回,询问每次操作后逆序对的个数,N<=50000;
找一个和排序等价的写法来替代排序找逆序对
和GSS4方法一样,因为一个点移动过之后逆序对数量就变为0了,后面的修改也不会改变0。加完之后如果找最小值那就把这个点改为 INF
哈希
求最长回文子串:
枚举回文的中心位置,二分回文串的长度,通过哈希判断向前走和向后走是否一样(manacher也可以做,下课查)
这段没听,下午补上笔记吧

动态规划
前向转移,后向转移,状态与状态图
前向转移:每次得到的状态更新后面,思考难度比较低
后向转移:对于每个状态美剧前去然后计算出它的值
基本原理:
1.最优性原理
作为整个过程的最优策略,它满足:相对前面决策所形成的状态而言,余下的子策略必然构成“最优子策略”。
2.无后效性原理
给定某一阶段的状态,则在这一阶段以后过程的发展不受这阶段以前各段状态的影响,所有各阶段都确定时,整个过程也就确定了。这个性质意味着过程的历史只能通过当前的状态去影响它的未来的发展,这个性质称为无后效性。
转移方向:转入与转出两种
转移方法:for循环和记忆化搜索两种
for循环 也可以写转出的表达式
时间复杂度:状态复杂度*转移复杂度(优化角度)
转入转出优缺点:
转出
优点:顺向思维,思考难度低。一般采用记忆化搜索编写,类似于写搜索,不易错。适合树、图等不规则转移图
缺点:转出的状态是未知的,也就意味着转移的负责度难以优化
转入
优点:一般for循环编写,代码简洁。转移图有规律,可以通过前缀和、线段树等多种方法优化转移。适合序列等规则转移图
缺点:需要注意边界等特殊位置,容易出错
动态规划关键在于设计状态,多看几遍边界是不是又特殊情况等等
[NOIP2016换教室(期望dp)]([P1850 NOIP2016 提高组] 换教室 - 洛谷 | 计算机科学教育新生态 (luogu.com.cn))
状态设计的一些技巧:
1. 从搜索角度思考问题:需要知道什么条件才能继续搜下去,如何将他们简化为动态规划的状态
2.*增加维数:当我们发现一个状态表示的并不能充分地表示出所有的特征或不满足最优子结构时,我们可以通过增加状态的维数来满足要求。
3.*交换状态与最优值:由于最优值的规模往往没有太多的限制,所以在某些情况下,我们交换最优值与某一位状态记录的内容,而缩小规模
4. 对部分问题进行Dp:直接对原问题Dp求出答案可能比较困难。可以仅有Dp求出原问题答案的一部分信息,然后用其他办法或另外的Dp求出答案。
5. 可行转最优:一些可行性dp问题(一些dp设计出来dp值只有true或者false),很多时候可以省去状态的一维,转化成最优性dp(就是dp值是存一个数字最大最小值之类),可以优化复杂度。
6. 合并本质相同的状态:有一些问题,问题会有多个需要在状态中记录的信息,而这些信息本质都是类似的我们可以合并状态,优化复杂度。
记忆化搜索
常规动态规划是从dfs转移过来,就是从他相邻的状态转移过来,但是找到的不一定定时最优解,时间复杂度可能是较多吧,记忆化搜索是通法。
线性动态规划
最典型的特征就是状态都在一条线上,并且位置固定,问题一般都规定只能从前往后取状态,解决的办法是根据前面的状态特征,选取最优状态作为决策进行转移。
设前 i 个点的最优值,研究前 i-1 个点与前 i 个点的最优值
利用第i个点决策转移,如下图。
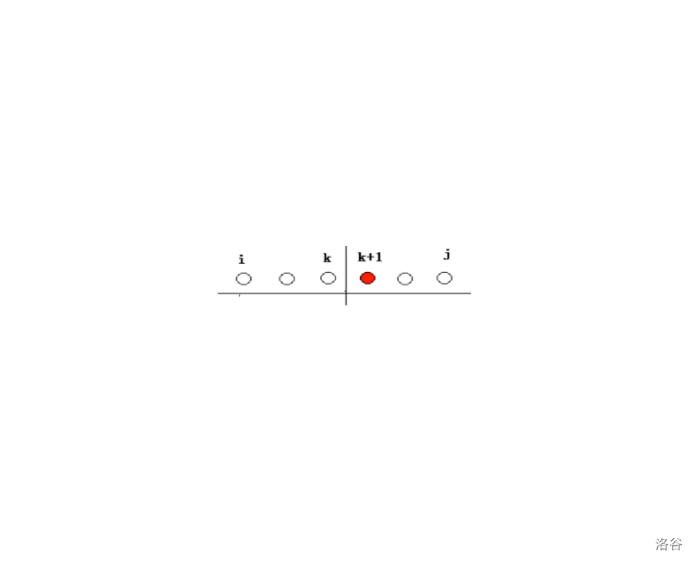
状态转移方程一般可写成:

eg.最长公共子序列
给出两个字符串S1,S2,求两个传最长贡藕给你子串的长度:

暴力:
在状态中找一个优化:k必须要删掉,地推顺序,先i后j,计算
列题:
求长度为
提示:一种递归生成排列的方式 -- 假设已有长度为n的排列,长度为n + 1的所有排列为把n + 1插入到长度为n的每个排列的每一个位置
解:取
假设其插入到倒数第x位,有
暴力求解的时间复杂度:状态数是O(NK),转移时O(N),总复杂度就是
区间dp
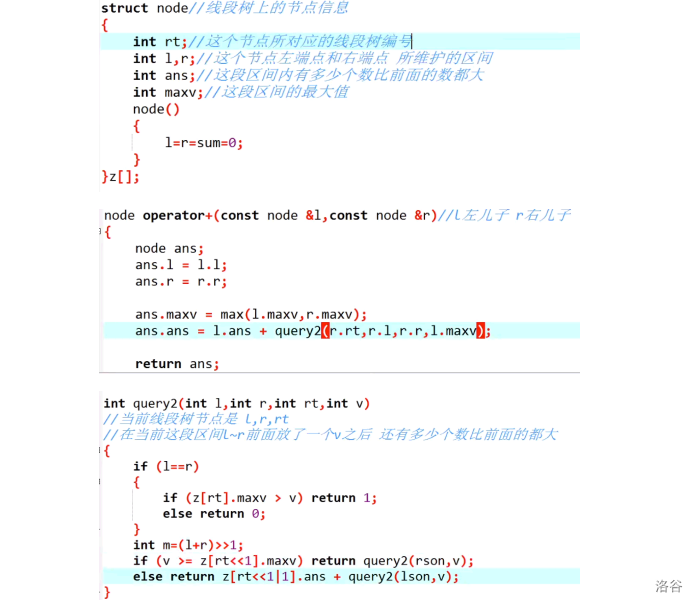
该类问题的基本特征是能将问题分解 成为两两 合并的 形式。解决方法是对整个问题设最优值,枚举合并点,将问题分解成为左右两个部分,最后将左右两个部分的最优值进行合并得到原问题的最优值。有点类似分治的解题思想。
设前 i 到 j 的最优值,枚举剖分(合并)点,将 (i,j) 分成左右两区间,分别求左右两边最优值,如下图。
状态转移方程的一般形式如下:
F(i,j)=Max{F(i,k)+F(k+1,j)+ 决策, k 为划分点
[P2051中国象棋]([P1850 NOIP2016 提高组] 换教室 - 洛谷 | 计算机科学教育新生态 (luogu.com.cn))
在
炮的攻击方式与中国象棋相同。
棋盘上区间dp问题
我们首先发现一点,它的任意一列进行交换是不会对题目产生影响的。
本质就是将不同列进行合并
coed
#include<cstdio>
#include<cstring>
#include<cmath>
#include<cctype>
#include<cstring>
#define mod 9999973
#define int long long
#define R register
using namespace std;
inline void in(int &x)
{
int f=1;x=0;char s=getchar();
while(!isdigit(s)){if(s=='-')f=-1;s=getchar();}
while(isdigit(s)){x=x*10+s-'0';s=getchar();}
x*=f;
}
int n,m,ans;
int f[108][108][108];
inline int C(int x)
{
return ((x*(x-1))/2)%mod;
}
signed main()
{
in(n),in(m);
f[0][0][0]=1;
for(R int i=1;i<=n;i++)
{
for(R int j=0;j<=m;j++)
{
for(R int k=0;k<=m-j;k++)
{
f[i][j][k]=f[i-1][j][k];
if(k>=1)(f[i][j][k]+=f[i-1][j+1][k-1]*(j+1));
if(j>=1)(f[i][j][k]+=f[i-1][j-1][k]*(m-j-k+1));
if(k>=2)(f[i][j][k]+=f[i-1][j+2][k-2]*(((j+2)*(j+1))/2));
if(k>=1)(f[i][j][k]+=f[i-1][j][k-1]*j*(m-j-k+1));
if(j>=2)(f[i][j][k]+=f[i-1][j-2][k]*C(m-j-k+2));
f[i][j][k]%=mod;
}
}
}
for(R int i=0;i<=m;i++)
for(R int j=0;j<=m;j++)
(ans+=f[n][i][j])%=mod;
printf("%lld",(ans+mod)%mod);
}
背包动态规划
通常采用
有的时候可以翻着看,比如果卖出背包,那就就可以看错空间-=v,机制-=p;
如果说某一维他的空间太高,那就可以转化掉
树形dp
大多数是书上套一个背包。
例题:[P2458 [SDOI2006]保安站岗]([P2458 SDOI2006]保安站岗 - 洛谷 | 计算机科学教育新生态 (luogu.com.cn))
一个有N个区域的树结构上需要安排若干个警卫;
每个区域安排警卫所需要的费用是不同的;
每个区域的警卫都可以望见其相邻的区域,只要一个区域被一个警卫望见或者是安排有警卫,这个区域就是安全的;
任务:在确保所有区域都是安全的情况下,找到安排警卫的最小费用;
分析
对于每个点 i ,都有 3 种状态分别为:
要么在父亲结点安排警卫,即被父亲看到
要么在儿子结点安排警卫,即被儿子看到
要么安排警卫
对于 i
i 被父亲看到,这时****i 没有安排警卫, i 的儿子要么安排警卫,要么被它的后代看到。
i 被儿子看到,即 i 的某个儿子安排了警卫,其他儿子需要安排警卫或者被它的后代看到。
i 安排了警卫, i **的儿子可能还需要安排警卫,这样可能有更便易的方式照顾到它的后代;所以 ** i 的儿子结点被 **i ** 看到,可能安排警卫,可能被它的后代看到。
保安站岗的code// 这个之后还要在理解一下
#include<bits/stdc++.h>
#define int long long
using namespace std;
const int N=2e5+5;
const int M=5e4+1;
const int INF=0x3f3f3f3f;
int c,x,n,m,y,minn,Ans;
int dp[M][3],b[N],head[N];
struct node{
int v,next;
}e[N];
void add(int u,int v)
{
c++;
e[c].v=v;
e[c].next=head[u];
head[u]=c;
}
void dfs(int u,int f)
{
// cout<<1<<endl;
int minn=INF;
for(int i=head[u];i;i=e[i].next)
{
int v=e[i].v;
if(v!=f)
{
dfs(v,u);
dp[u][0]+=min(dp[v][0],min(dp[v][1],dp[v][2]));
dp[u][1]+=min(dp[v][0],dp[v][1]);
dp[u][2]+=min(dp[v][0],dp[v][1]);
if(dp[v][0]<dp[v][1]) minn=0;
else minn=min(minn,dp[v][0]-dp[v][1]);
}
}
dp[u][0]+=b[u];
dp[u][1]+=minn;
// cout<<2<<endl;
}
signed main()
{
cin>>n;
for(int i=1;i<=n;i++)
{
cin>>x;
cin>>b[x];
cin>>m;
for(int i=1;i<=m;i++)
{
cin>>y;
add(x,y);
add(y,x);
}
}
dfs(1,0);
// cout<<"sadklf";
cout<<min(dp[1][0],dp[1][1]);
return 0;
}
例题: 最长上升子序列
用单调栈求最长上升子序列

概率与期望动态规划(一点不会)
如果X是一个离散的随机变量,输出值为
全概率公式:
假设${B n | n = 1,2,3,…}$ 是一个概率空间的有限或者可数无限的分割,且每个集合$B n$是一个可测集合,则对任意事件A有全概率公式 $P(A)$ = $\displaystyle \sum_{n} P(A|B_n) P(B_n)$
其中
联赛阶段可以这么理解
[P4316 期望dp经典例题](P4316 绿豆蛙的归宿 - 洛谷 | 计算机科学教育新生态 (luogu.com.cn))
给出张
绿豆蛙从起点出发,走向终点。 到达每一个顶点时,如果该节点有
记忆化搜索:
#include<iostream>
#include<cstring>
#include<cstdio>
#include<cstdlib>
#include<cmath>
#include<algorithm>
#include<vector>
#define ll long long
#define inf 1000000000
using namespace std;
ll read()
{
ll x=0,f=1;char ch=getchar();
while(ch<'0'||ch>'9'){if(ch=='-')f=-1;ch=getchar();}
while(ch>='0'&&ch<='9'){x=x*10+ch-'0';ch=getchar();}
return x*f;
}
int n,m,cnt;
int last[100005],out[100005];
double f[100005];
bool vis[100005];
struct edge{
int to,next,v;
}e[200005];
void insert(int u,int v,int w)
{
e[++cnt].to=v;e[cnt].next=last[u];last[u]=cnt;e[cnt].v=w;
}
void dfs(int x)
{
if(!vis[x])vis[x]=1;
else return;
for(int i=last[x];i;i=e[i].next)
{
dfs(e[i].to);
f[x]+=e[i].v+f[e[i].to];
}
if(out[x])f[x]/=out[x];
}
int main()
{
n=read();m=read();
for(int i=1;i<=m;i++)
{
int u=read(),v=read(),w=read();
insert(u,v,w);
out[u]++;
}
dfs(1);
printf("%.2lf",f[1]);
return 0;
}
Day4
动态规划
记忆化搜索:
我们一般写的动态规划是bfs模式的,即一个点从与它相邻的点转移过来
如果用深搜写动态规划,就可以说是记忆化
基本思路:
对于每个状态,存储该状态返回信息
以后再到该状态,直接调用存储信息即可
[飞扬的小鸟] [乌龟棋] [合唱队]
状压dp
状态压缩动态规划
一般以
要注意用好位运算,这样可以加速
联赛考的一般比较基础
一般用记忆化搜索实现(便于理解和编写)
一般以f[i][S]为状态,S为一个二进制数(当然也可以是三进制四进制数,不过这时候建议处理前先把S拆成数组)要注意用好位运算,这样可以加速联赛考的一般比较基础一般用记忆化搜索实现(便于理解和编写)
常用位运算
1、!!(s & (1 << i)) :判断第 i 位是否是 1;
2、s |= 1<<i:把第 i 位设置成 1
3、s &= ~(1<<i) :把第 i 位设置成 0;
4、s ^= 1<<i:把第 i 位的值取反
5、s & = s - 1:把一个数字 s 二进制下最靠右的第一个 1 去掉
6、for (s0 = s; s0; s0 = (s0 - 1) & s); :依次枚举 s 的子集
不太熟时,可以把数分解后再处理
Day 5
图论:
最短路
多源最短路
一.定义:若干个点到其他点的最短路
当且仅当k在i到j的最短路上,取等
二.算法:
1.本质:
2.
3.初始化:若
for(int k=1;k<=n,k++) // 注意k要放在最外层的循环
for(int i=1;i<=n;i++)
for(int j=1;j<=n;j++)
if(r[i][j]>r[i][k]+r[j][k])
r[i][j]=r[j][i]=r[i][k]+r[j][k];
单源最短路
一.定义:一个点到其它点的最短路
二.算法
贪心求最短点,改用松弛求其他点,如此反复
朴素时间复杂度:
堆优化
// Dijkstra
void dijkstra(int n,int s){
for(int i=1;i<=n;i++){
int x;//x标记当前最短w的点
int min_dis=INF;//记录当前最小距离
for(int y=1;y<=n;y++){
if(!vis[y] && min_dis>=dis[y]){
x=y;
min_dis=dis[x];
}
}
vis[x]=true;
for(int y=1;y<=n;y++)
dis[y]=min(dis[y],dis[x]+G[x][y]);
}
}
// SPFA
int dis[N];
bool vis[N];
void SPFA(int S) {
memset(vis, false, sizeof(vis));
memset(dis, INF, sizeof(dis));
dis[S] = 0;
queue<int> Q;
Q.push(S);
while (!Q.empty()) {
int x = Q.front();
Q.pop();
vis[x] = false;
for (int i = head[x]; i != -1; i = edge[i].next) {
int to = edge[i].to;
if (dis[to] > dis[x] + edge[i].dis) {
dis[to] = dis[x] + edge[i].dis;
if (!vis[to]) {
vis[to] = true;
Q.push(to);
}
}
}
}
}
总结
1.判断多源还是单源最短路
2.如果是单源最短路,看看边权是不是为负,非负可以用
差分约束
例题:[P3275]
来一个小插曲:探寻输出的时间
#include<bits/stdc++.h>
using namespace std;
int main()
{
freopen("out","w",stdout);
for(int i=1;i<=1000000;i++)
{
//cout << i << endl; // 4.121s
//printf("%d\n",i); // 3.384s
// cout << i << "\n"; // 0.4446s
}
return 0;
}
生成树
定义:从
其中边权和最小的就是最小生成树
最小生成树算法
贪心选最短边,已经在一个并查集里的不选
[CF1253F]
建一个超级起点,然后枚举到每个充电点,这样就能找到i点的最短充电距离了,
dis[i]代表i点的最短充电距离
已经到i了,容量为c,剩余电量为x
推出:
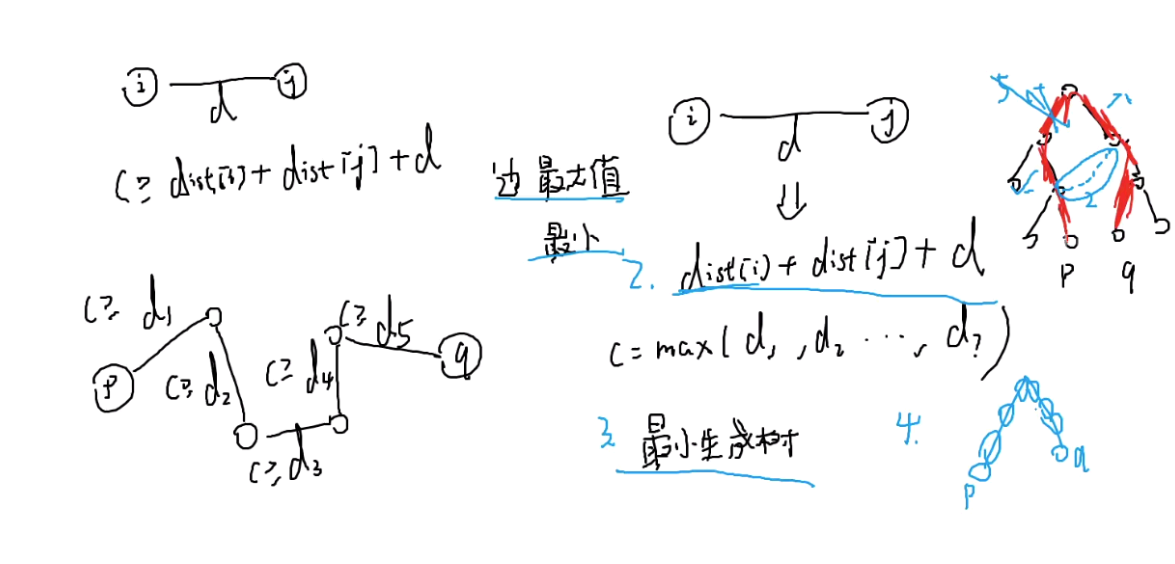
要让经过的边最大值最小:最小生成树
LCA 最近公共祖先
code LCA
#include<cstdio>
#include<vector>
#include<cmath>
#define int long long
const int N = 1e6+5;
const int M = 30;
const int INF = 0x3f3f3f3f;
using namespace std;
int u,v,n,m,s,Ans;
int deep[N],f[N][M];
vector<int>G[N];
inline void dfs(int dep,int x)
{
for(int i=1;i<=log2(deep[x]);i++)
f[x][i] = f[f[x][i-1]][i-1];
for(int i=0;i<G[x].size();i++)
{
int v = G[x][i];
if(deep[v]) continue;
deep[v] = dep+1;
f[v][0] = x;
dfs(dep+1,v);
}
}
inline int LCA(int x,int y)
{
if(deep[y] > deep[x]) swap(x , y);
while(deep[x] > deep[y])
{
int k = log2(deep[x] - deep[y]);
x = f[x][k];
}
/*
for(int i = 18;i>=0;i--)
{
if(deep[f[x][i]] >= deep[y])
x = f[x][i];
}
// 也可以用这个替代上面
*/
if(x==y) return x;
for(int i=log2(deep[x]);i>=0;i--)
if(f[x][i]!=f[y][i]) x = f[x][i] , y = f[y][i];
// 也可以在这里补一步 x = f[x][0],return x;,其实和下面的return一样
return f[x][0];
}
signed main()
{
scanf("%d%d%d",&n,&m,&s);
for(int i=1;i<n;i++)
{
scanf("%d%d",&u,&v);
G[u].push_back(v);
G[v].push_back(u);
}
deep[s] = 1;f[s][0] = 0;
dfs(1,s);
for(int i=1;i<=m;i++)
{
scanf("%d%d",&u,&v);
printf("%d\n",LCA(u,v));
}
return 0;
}
老师谷id : Cyrushcy
[NOIP 2013货车运输]
[P3280 SCOI2013摩托车交易]
例题
N个点M条边的图求次小生成树;
与最小生成树只有一条边的区别
两种边:树边,非树边
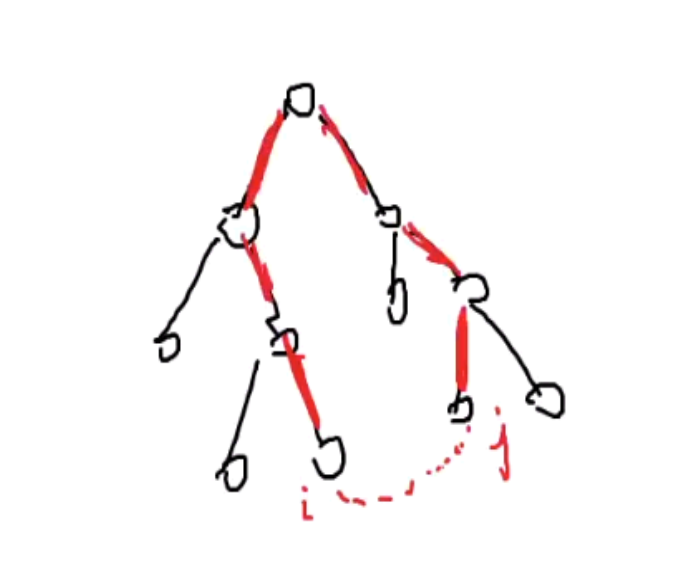
找到最大的边来替换掉它,枚举每条非树边来询问,
如果把数据分为增大怎么办?
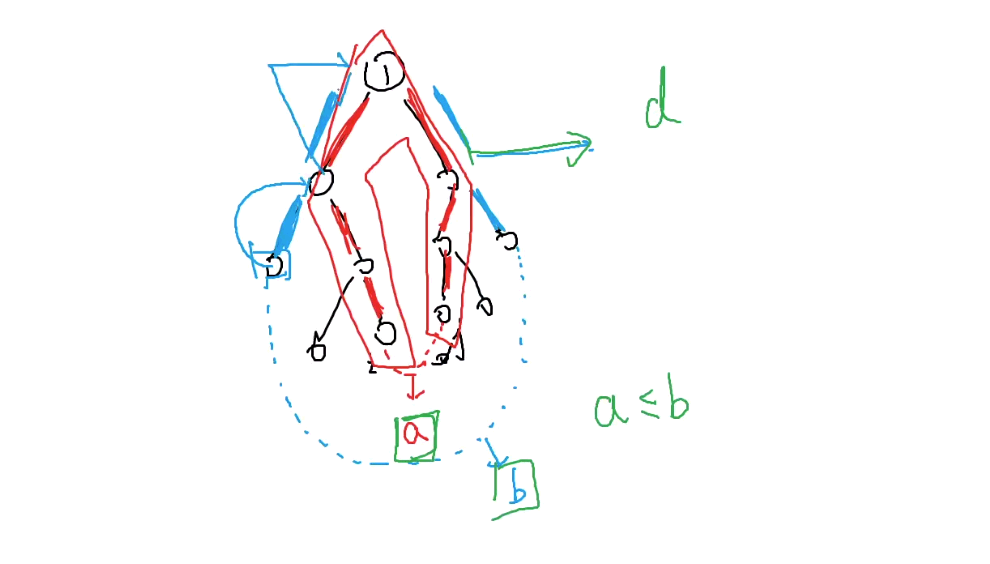
直接把这6个点加入一个并查集,然后一个一个进行比大小修改就行了,这样虽说是一个暴力,但是也是时间复杂度最小的
[CF160D]与它相似
图论难点:如何建图;
最短路的变数较少,和动态规划一样,把状态看作点,转移看做边,就相当于最短路问题了。
二分图
树一定是二分图,那么该如何判断一张图是不是二分图?
长度为奇数的图不是二分图
匹配:匈牙利算法:
每次都尝试匹配,通过不断回溯来找到最优的
cin >> n >> m >> k;// 左边m人,右边n人,一共k条边
for(int i=1;i<=k;i++)
{
int p1,p2;
cin >> p1 >> p2
match[p1][p2] = true;// 代表左边p1和右边篇
可以匹配
}
int result[i]//代表右边第i个人和左边地result[i]个人可以匹配
use[i]//代表右边第i个人在这一轮中有没有人向他请求匹配
bool dfs(int i)// 返回是否匹配成功
{
for(int j=1;j<=m;j++)
{
if(match[i][j]&&!use[j])
{
use[j] = true;
if(!result[j]||dfs(result[j]))
{
result[j] = i;
return true;
}
}
}
return false;
}
for(int i=1;i<=n;i++)// 让左边第i个人去尝试匹配
{
memset(use,0,sizeof uss);
if(dfs(i)) Ans ++ ;
//如果左边第i个人匹配成功,那么Ans++
}
时间复杂度
思考怎么优化:如果用边表村可以匹配的边的话,时间复杂度可以将为
[vijos多米诺骨牌] 这个经典例题
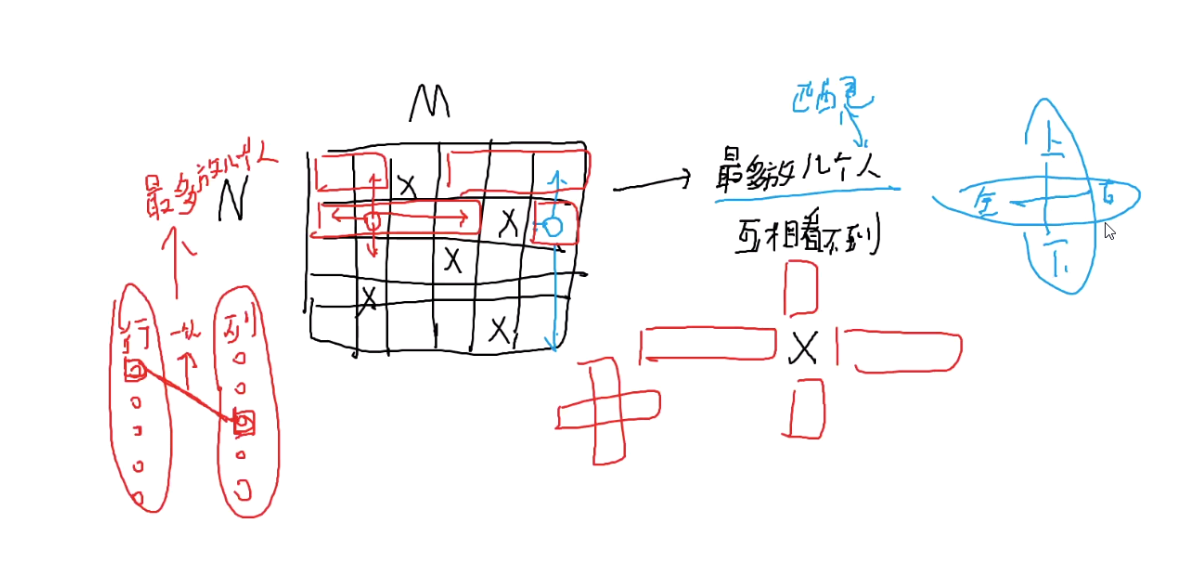
把放个左右上下两边分为4框,行和列进行匹配
进阶版:[piece it together]
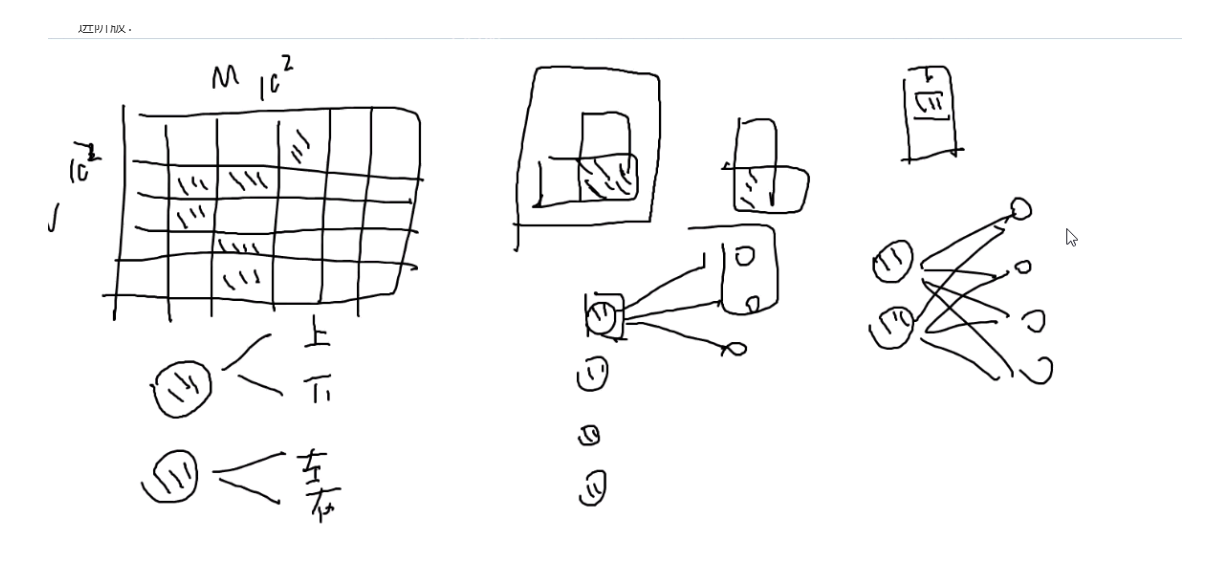
分别于上下左右分别匹配
Day 6
图论
二分图
补图:把原来没边的边给加上
最大独立集=m+n-最大匹配数量
最大团:使得选出来的点都有边
例题:
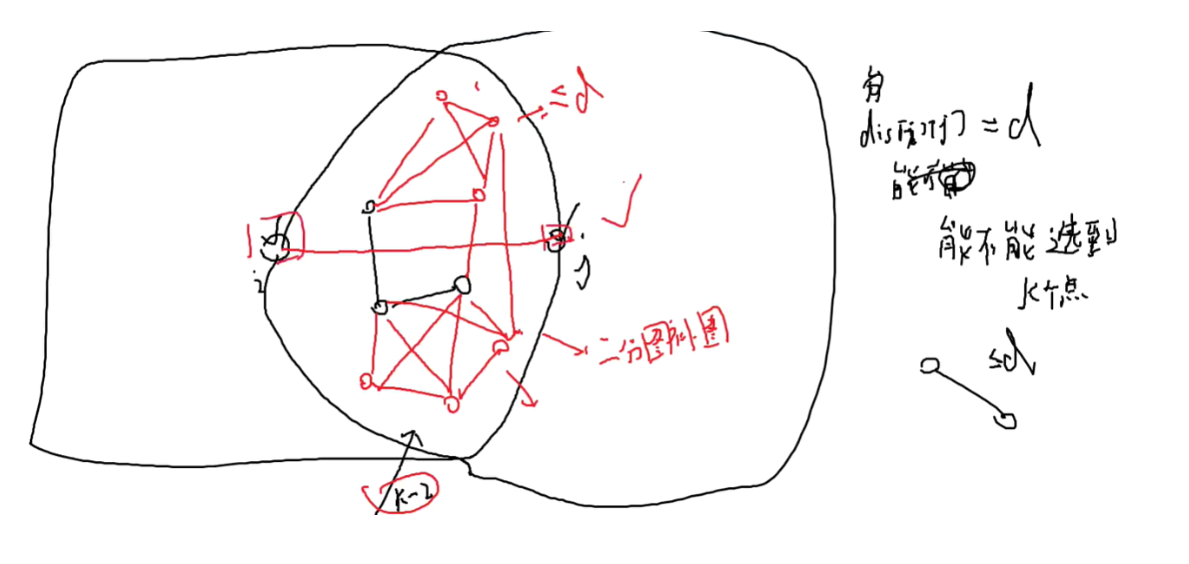
强连通分量
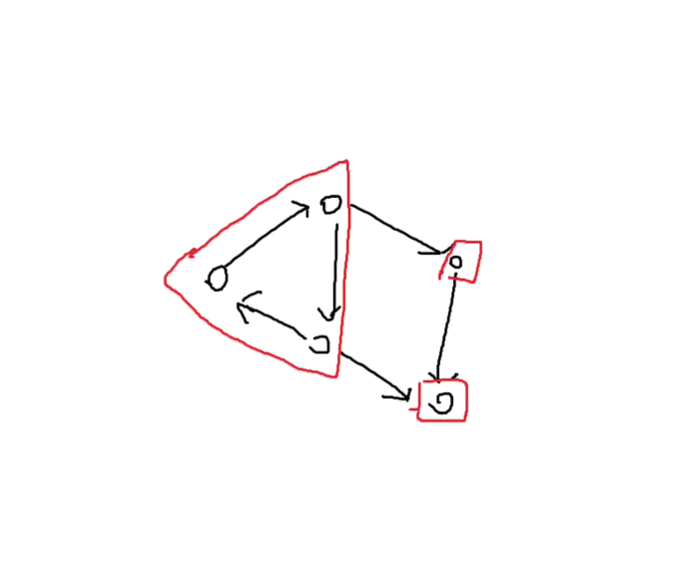
这张图一共有三个强联通分量,每个点也算一个强连通分量
Tarjan算法
本质:dfs过程
搜索的过程一定是一棵树
边类型:
1.回边:连到自己祖先的边,这样的边一定能产生环
2.横叉边:不连到自己祖先的边,不可能组成环,因为是按照dfs序便历的,但是可以用来扩大已有的环
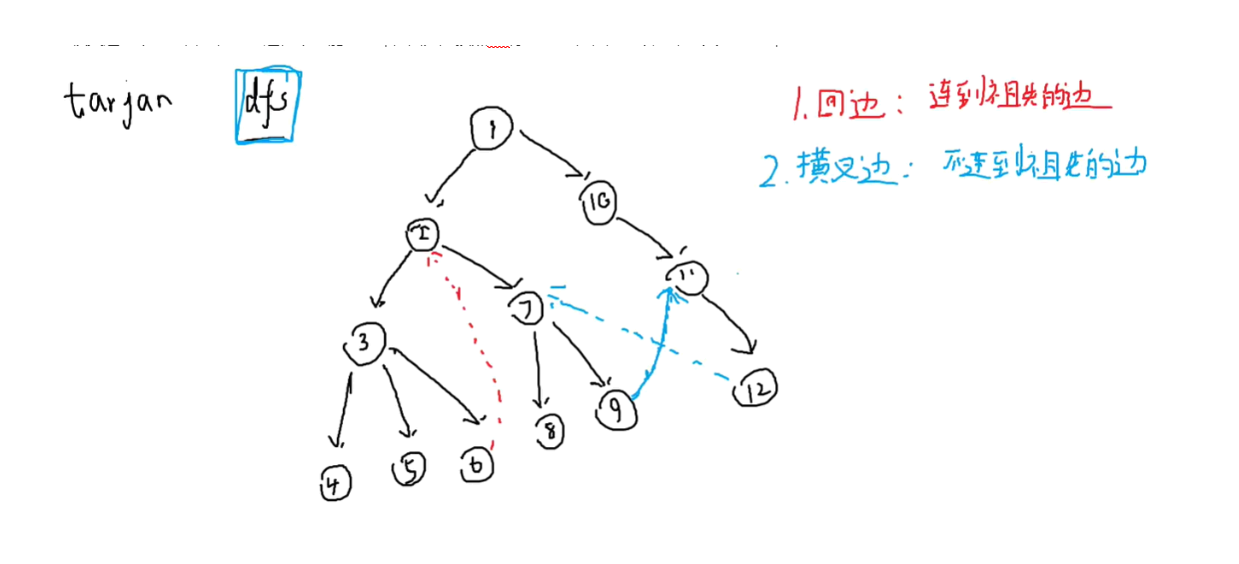
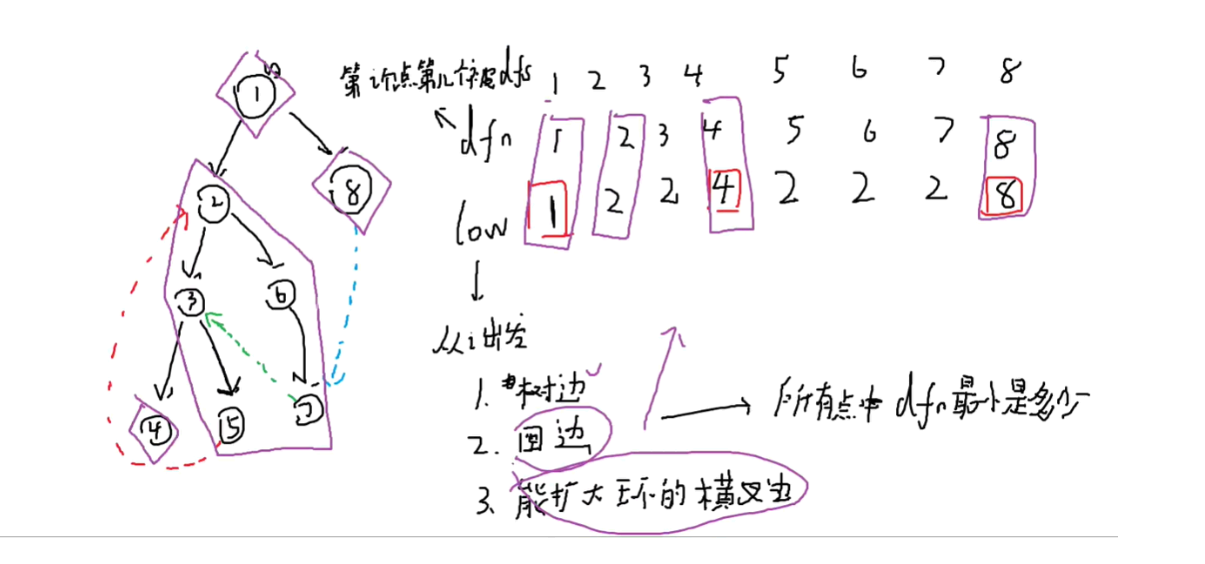
从第
栈中存储的是还没有存储强连通分量的点
缩点 code
#include<bits/stdc++.h>
#define int long long
using namespace std;
const int N=2e5+5;
int low[N],dfn[N],t;;
int n,m,cnt1,cnt2,head[N][2],Num[N],Size[N],Stc[N],vis[N],a[N],sc,tot,In[N],f[N];
struct node{
int u,v,next;
}e[N][2];
inline char readchar() {static char buf[100000], *p1 = buf, *p2 = buf; return p1 == p2 && (p2 = (p1 = buf) + fread(buf, 1, 100000, stdin), p1 == p2) ? EOF : *p1++;}
inline int read() {int res = 0, f = 0; char ch = readchar(); for(; !isdigit(ch); ch = readchar()) if(ch == '-')f = 1; for(; isdigit(ch); ch = readchar()) res = (res << 1) + (res << 3) + (ch ^ '0'); return f ? -res : res;}
// 以上是快读
queue<int>q;
void add1(int u,int v)
{
cnt1++;
e[cnt1][0].u=u;
e[cnt1][0].v=v;
e[cnt1][0].next=head[u][0];
head[u][0]=cnt1;
}
void add2(int u,int v)
{
cnt2++;
e[cnt2][1].u=u;
e[cnt2][1].v=v;
e[cnt2][1].next=head[u][1];
head[u][1]=cnt2;
}
// add 添加操作
void Tarjan(int u)
{
low[u] = dfn[u] = ++tot;
Stc[++sc] = u;
vis[u] = 1;// 标记一下是不是在栈中
for(int i=head[u][0] ; i ; i=e[i][0].next)
{
int v=e[i][0].v;
if(!dfn[v])
{
tarjan(v);
low[u] = min(low[u] , low[v]);
}
else if(vis[v]) low[u] = min(low[u] , dfn[v]);
// else if(vis[i]) low[u] = min(low[u] , dfn[v]);
/*
其实两种写法都不对,但是只能这样写
因为我们不关心dfn值是多少,只要不能与low值就行了
只需要判断low与dfn的区别就行了
*/
// 如果是在栈中,说明不是回插边,说明是可以被更新的
}
// 这里是缩点
//一般配和上面强连通分量使用
if(dfn[u] == low[u])
{
int Top = Stc[sc--];
vis[Top] = 0;//弹栈去除
Size[++t] += a[Top];// Size表示这个强连通分量的长度
Num[Top] = t;// Num代表这个点是哪个强连通分量
while(Top != u)
{
Top = Stc[sc--];
vis[Top] = 0;
Size[t] +=a[Top];
Num[Top] = t;
}
}
}
void Topsort()// 拓扑排序
{
for(int i=1;i<=t;i++)
{
// 入读为0的点放在前面
if(!In[i])
{
q.push(i);
f[i] = Size[i];
}
}
while(!q.empty())
{
int u=q.front();
q.pop();
for(int i=head[u][1] ; i ; i=e[i][1].next)
{
int v=e[i][1].v;
f[v] = max (f[v] , f[u]+Size[v]);
if(!--In[v]) q.push(v);
// 拓扑排序的时候顺便dp求出最大值
}
}
int Ans=-0x7fffffff;
for(int i=1;i<=t;i++)
Ans = max (Ans, f[i]); //找到最大值然后输出
cout<<Ans;
}
signed main()
{
n=read();m=read();
for(int i=1;i<=n;i++)
a[i]=read();
for(int i=1,u,v;i<=m;i++)
{
u=read();v=read();
add1(u,v);
}
// 调用的时候要枚举所有的点,保证所有的点都被搜到
for(int i=1;i<=n;i++)
if(!dfn[i]) tarjan(i);
for(int i=1;i<=cnt1;i++)
{
int x=Num[e[i][0].u];//找到两个点分别输出那个强连通分量
int y=Num[e[i][0].v];
if(x!=y)
{
add2(x,y);// 如果说不在同一点
In[y]++;// 那就放进去,并且入度+1
}
}
Topsort();
return 0;
}
Tarjan第一类问题
1.强连通分量
2.缩点
3.拓扑排序
4.dp
eg.[P2423洛谷朋友圈]
缩点之后就是有向无环图
Tarjan第二类问题
2 sat问题
把题目给的关系转换成图,把要取的值连成一个图,表示这个图里要一起取,如果矛盾的话就是一个点既要取这个又要那个导致不可能完成
有x个数,有
就是把两个关联的东西连起来(比如 x && y==1 那就链接 x的1和y的1和x的0和y的0连接起来,按照这个连图)。如果有的点的0/1在同一连通分量里那就说明是不可能同时满足的所以就是无解的。
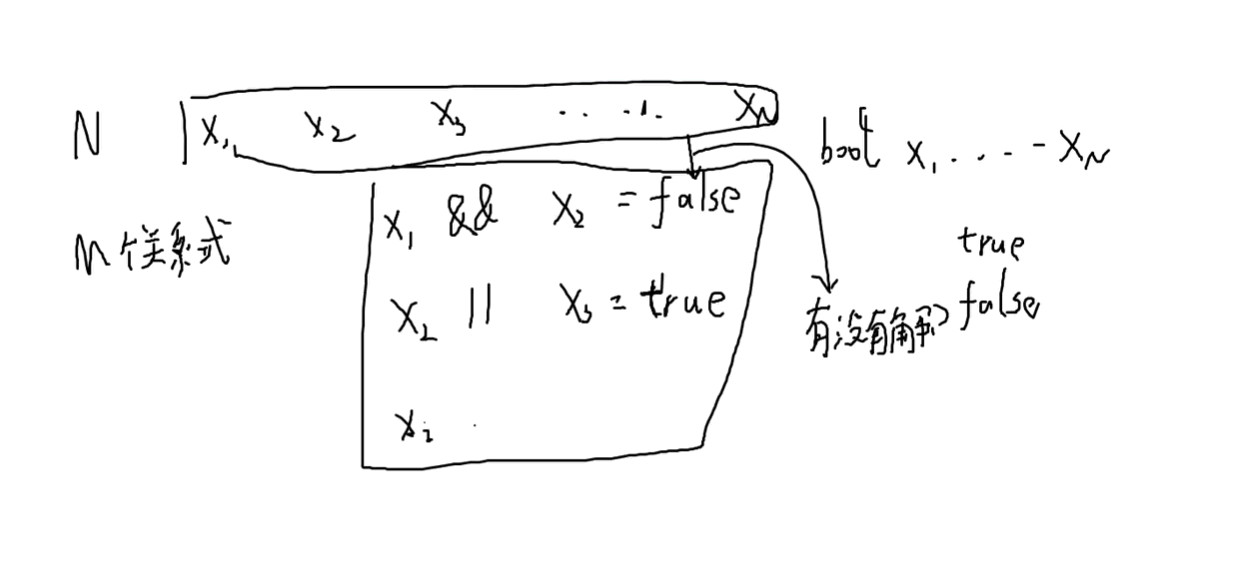
思考如何建边:
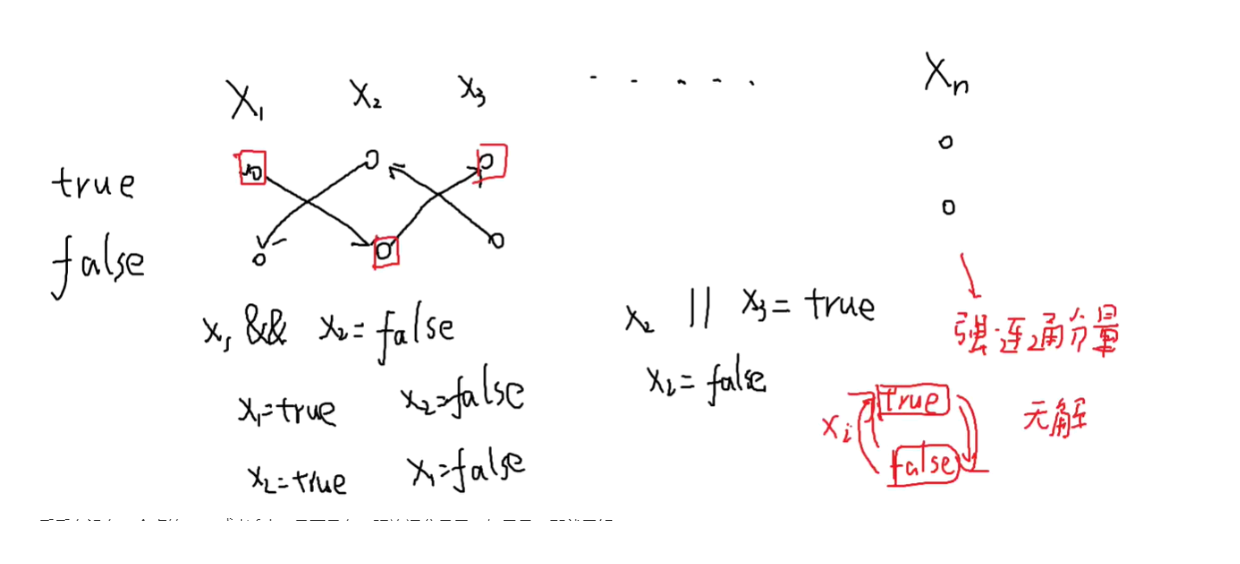
看看有没有一个点的true 或者 false 是不是在一强连通分量里,如果是,那就无解
网络流
爆搜代码
vectoe<edge> z[];
int dfs(int p,int f) // 代表当前六了f的水到p点
{
if(p==t) return f;
int Ans = 0;
for(int i=0;i<z[p].size();i++)
{
int q = z[p][i].e;
int g = z[p][i].f;
if(g>0)
{
int flow = dfs(q,min(g,f));
Ans += flow;
z[p][i].f -= flow;
f -=flow;
}
}
return Ans;
}
但是爆搜有缺陷:
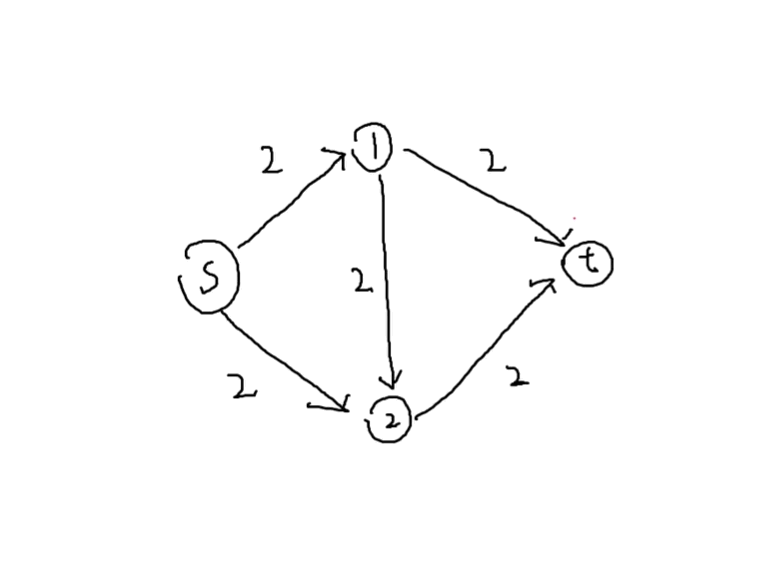
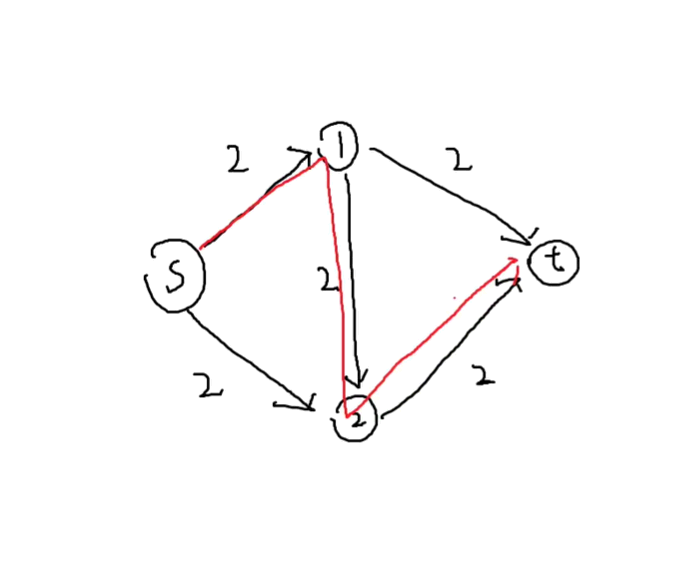
如果说第一次搜索没搜堆的话,那就搜索出来的答案是不对的,那么该怎么解决这个问题呢?
给每一条边建一条反向边
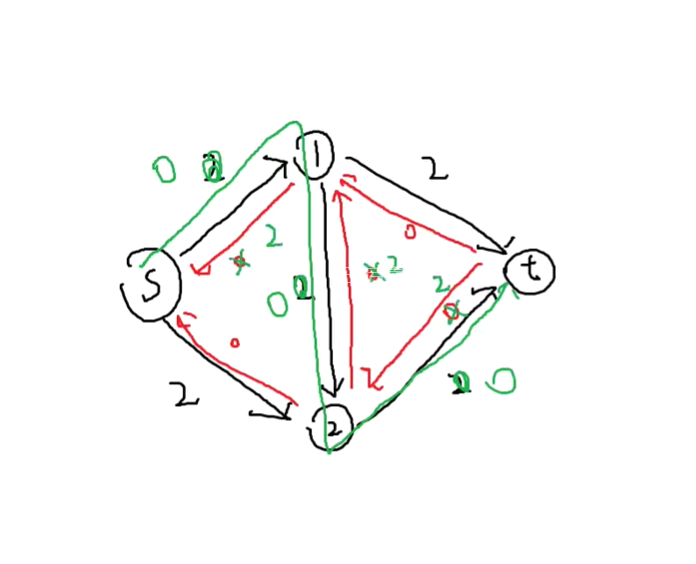
那就再反向边上在加上减去的数字
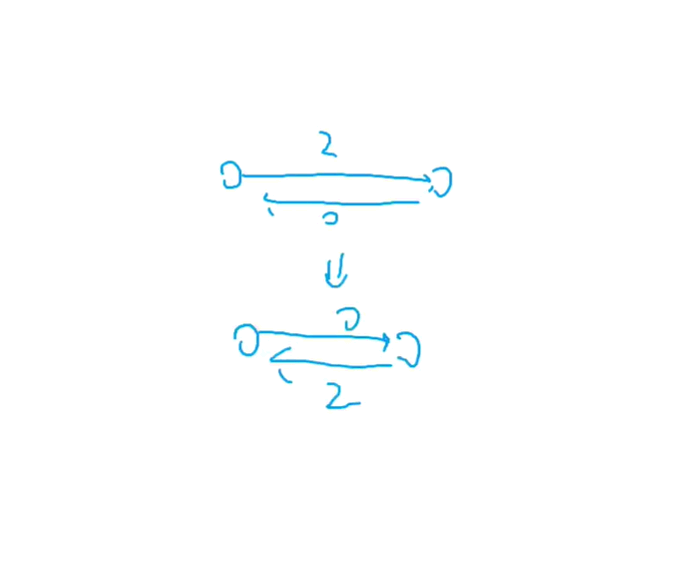
就是说可以在这个位置回退
正确性无人证明
dinic算法:
为了避免死循环,给每个点标记一个深度,你只能从深度小的走到深度大的,那就不可能环了
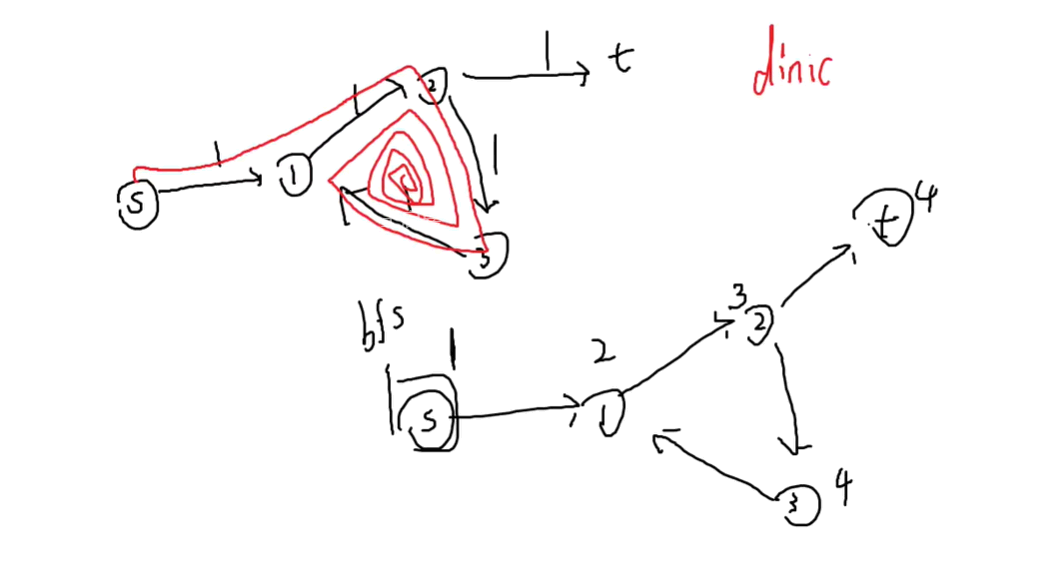
EK 算法:
不用学,考试了也不会,但是程序放在后面仅供参考
dinic code
#include<bits/stdc++.h>//Dinic
#define int long long
const int N=2e5+5;
const int INF=0x7fffffff;
using namespace std;
int n,m,be,en,c=1,head[N],cur[N],dep[N];
struct node{
int v,w,next;
}e[N];
void add(int u,int v,int w)
{
c++;
e[c].v=v;
e[c].next=head[u];
e[c].w=w;
head[u]=c;
}
int BFS()
{
memset(dep,0,sizeof dep);
dep[be]=1;
queue<int >q;
q.push(be);
while(!q.empty())
{
int now=q.front();q.pop();
for(int i=head[now];i;i=e[i].next)
{
int v=e[i].v,w=e[i].w;
if(!dep[v] and w>0)
{
dep[v]=dep[now]+1;
q.push(v);
if(v==en) return 1;
}
}
}
return 0;
}
int DFS(int k,int mf)
{
if(k==en) return mf;
int sum=0;
//
for(int i=cur[k];i;i=e[i].next)
{
cur[k]=i;
int v=e[i].v,w=e[i].w;
if(dep[v]==dep[k]+1 and w>0)
{
int now=DFS(v,min(w,mf));
sum+=now;mf-=now;
e[i].w-=now;e[i^1].w+=now;
if(mf==0) break;
}
}
if(sum==0) dep[k]=0;
// 说明这个点不能被流进了,后来久不用流进来了
// 把当前点深度赋值为0 ,那就一直不用再找了
return sum;
}
int Dicin()
{
int Ans=0;
while(BFS())
{
memcpy(cur,head,sizeof head);
Ans+=DFS(be,INF);
// 因为一次搜索不一定能全部搜索完成·
// 所以要所搜集此看看行不行
}
return Ans;
}
signed main()
{
ios::sync_with_stdio(false);
cin>>n>>m>>be>>en;
for(int i=1;i<=m;i++)
{
int u,v,w;
cin>>u>>v>>w;
add(u,v,w);
add(v,u,0);
}
cout<<Dicin();
return 0;
}
EK code
#include<bits/stdc++.h>
#include<queue>
#define int long long
using namespace std;
const int N=2e5+5;
int n,m,be,en;
struct node{
int v,w,next;
}e[N];
int head[N],let[N],flow[N],c=1;
void add(int u,int v,int w)
{
c++;
e[c].next=head[u];
e[c].v=v;
e[c].w=w;
head[u]=c;
}
int BFS()
{
memset(let,0,sizeof let);
flow[be]=1e9;
queue<int >q;
q.push(be);
while(!q.empty())
{
//cout<<1<<endl;
int now=q.front();q.pop();
if(now==en) break;
for(int i=head[now];i;i=e[i].next)
{
int v=e[i].v,w=e[i].w;
if(w>0 and !let[v])
{
let[v]=i;
flow[v]=min(flow[now],w);
q.push(v);
}
}
}
return let[en];
}
int EK()
{
int Ans=0;
while(BFS())
{
Ans+=flow[en];
for(int i=en;i!=be;i=e[let[i]^1].v)
{
e[let[i]].w-=flow[en];
e[let[i]^1].w+=flow[en];
}
}
return Ans;
}
signed main()
{
ios::sync_with_stdio(false);
cin>>n>>m>>be>>en;
for(int i=1;i<=m;i++)
{
int u,v,w;
cin>>u>>v>>w;
add(u,v,w);
add(v,u,0);
}
cout<<EK();
return 0;
}
** 例题**

[POJ1149]

数论
矩阵
两个矩阵要相乘:第一个矩阵的列数==第二个矩阵的行数
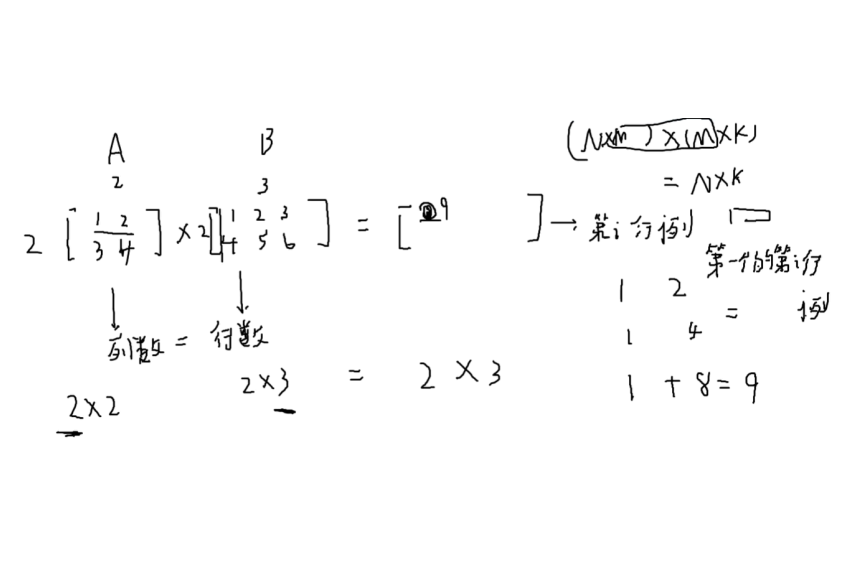
i行j列的矩的个值 = 第一个矩阵的第i行和第二个矩阵的第j列相乘然后加起来`
struct node{
int n,m;// 矩阵的行数和列数
int z[505][505];//代表矩阵i行j列的数
node()
{
m = n = 0;
memset(z,0,sizeof z);
}
}
node jzcf(node &m3,const node &m1,const node & m2)
// m1 * m2;
{
/*
m3 是局部变量,和全局变量最大的区别是
全局变量在堆空间中,也就是题目给出的空间
,但是局部变量是存储在栈中间中,但是矩阵乘法又占有大量空间
所以不用重载运算,直接改为函数;
当读入完一个n发现读入不进去了,那就要考虑一下
是不是爆栈了
// const 表示不能修改,便于检查
*/
m2.n = m1.n;
m3.m = m2.m;
for(int i=1;i<=m3.n;i++)
for(int j=1;j<=m3.m;j++)// 计算m3的第i行和第j列
for(int k=1;k<m1.m;k++)// 最好k放中间
m2.z[i][j] += m1.z[i][k] * m2.z[k][j];
// 循环顺序是可以调换的
/*
i j k 9.837 s
k j i 13.16 s
i k j 5.828 s // The best
是因为系统缓存机制导致的
当访问 a[1]这个元素的时候,会把后面的放进缓存区,那么访问a[2],a[3]这些
后面的就会快很多,所以说正着枚举一些东西可能比倒着枚举快
*/
}
jzcf(m2,m1,m2);
循环顺序是可以调换的
是因为系统缓存机制导致的
当访问 a[1]这个元素的时候,会把后面的放进缓存区,那么访问a[2],a[3]这些
后面的就会快很多,所以说正着枚举一些东西可能比倒着枚举快
模运算
减法取模是这样
( (a-b)%Mod + Mod ) % Mod;
(2+3)%5 = 1
注意1.
(2-3)%5 这个比较特殊:
1.在数学中 = 4
2.在c++中 = -1
int a,b,Mod;
Ans = a * b % Mod;
不要这么写,可能会被卡,
应该 Ans = 1ll * a * b % Mod;
注意2.
在运算中边算边模
逆元:用来做取模运算下的除法的
1.费马小定理:(p必须是质数)
如果
所以
所以除以一个数
把这个式子两边同时除以
2.欧拉定理
*对于
所以
如果求
首先有
求除以
// 求 φ(n)
int get_phi(int n)
{
int Ans = n;
for(int i=2;i*i<=n;i++)
if(n%i==0)// i是n的质因子
{
//Ans = Ans * (i-1) /i ;
Ans = Ans / i * (i-1);
// 这样写是先除再乘,防止爆int
while(n%i==0) n/=i;
}
if(n!=1) Ans = Ans / n * (n-1);
return Ans;
}
// 模 P 下除以 a *ksm(a,p-2,p) // a ^ (p-2) %P;
// 模 m(任意数) 下除以 a:*ksm(a,get_phi_(m)-1,m);
// NOIP 2012 同于方程
组合数学
乘法原理:前面的和后面的有关系久用加法原理
加法原理:前面怎么走和后面怎么走没有关系
排列:从
组合:从n中选m个不同顺序算一种方案
选n,m n-1选m-1 n-1选m
[P2822 NOIP2016 组合数问题]
杨辉三角形第
组合数取模
n,m,p 算
预处理阶乘就能快速算出
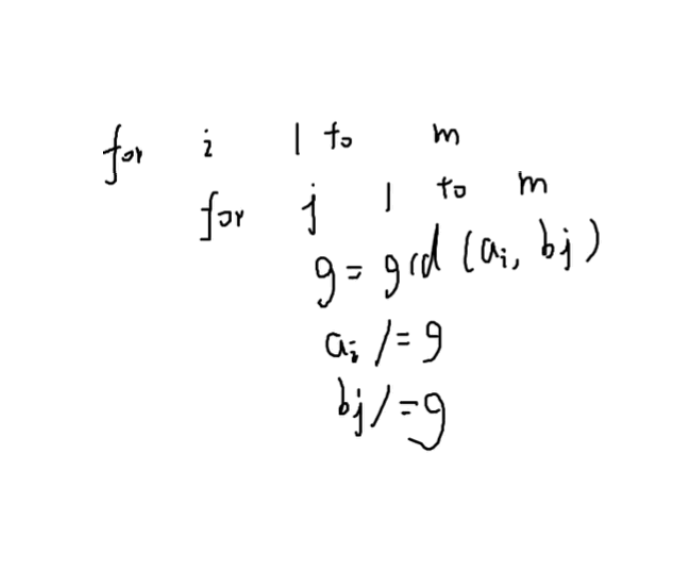
4.
卢卡斯定理 把
[P6669]
计算 C(n,m) % p
p <= 1000,n,m<=10^9
C[0][0] = 1;
for(int i=1;i<p;i++)
{
C[i][0] = 1;
for(int j=1;j<i;j++)
{
C[i][j] = (C[i-1][j-1] + C[i-1][j]) % P;
}// 杨辉三角
}
int lucas(int n,int m,int p)
{
int n_=0
while(n!=0)
{
n_++;
z[n_] = n%P;
n /= p
}
int m_=0
while(m!=0)
{
m_++;
y[m_] = m%p
m/=p
}
int Ans = 1;
for(int i=1;i<=max(n_,,m_);i++)
{
Ans = 1ll * Ans * C[z[i]][y[i]] % p;
}
return Ans;
}
《相信你们听了这节课之后还是不会做题》
例题
1.把
2.比较
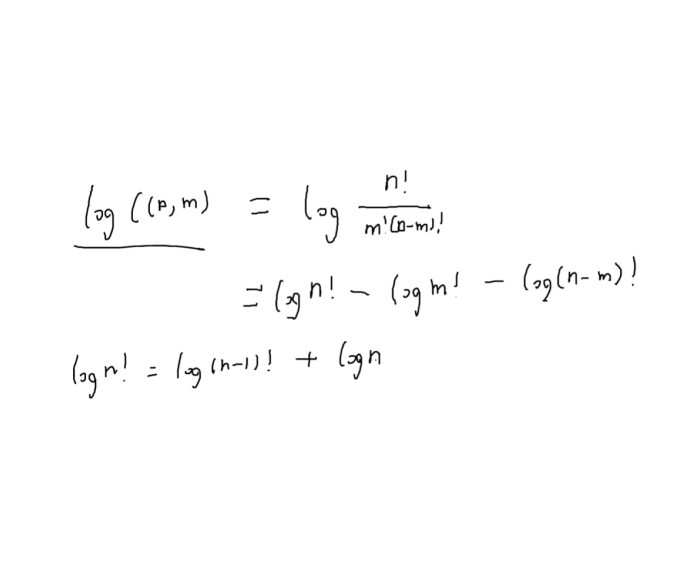

[P4370]
概率
期望的和等于和的期望
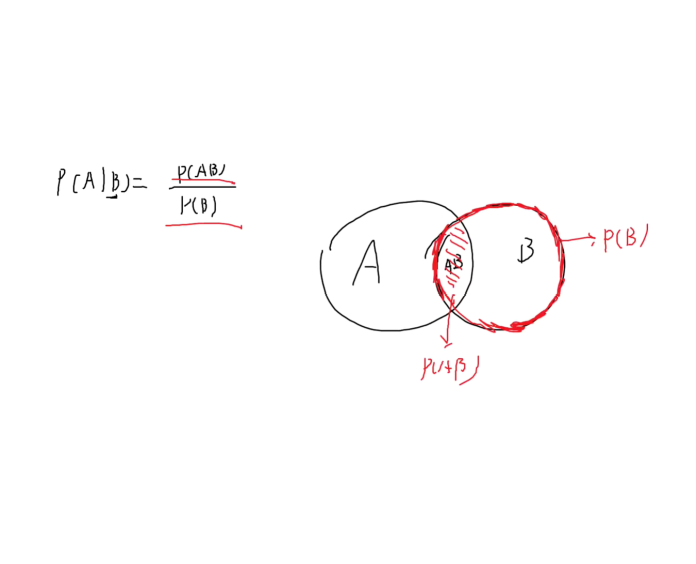
条件概率
已经事件B发生时时间A发生的概率为 P ,等于AB同时发生的概率除以B发生的概率
独立事件
如果
那么
可以反推
不可能事件,必然事件,和任何事件都是独立的

1.把
例题:
假设有散装形状相同的卡片,其中一张两面都是黑色,一张两面都是红色,一张一面黑一面红,随机取出一张放在桌上,朝上的面为红色,那么另一面是黑色的概率是?
例题:
问:这种抓阄方式是不是公平?
这里用第一个人的概率来表示了所有人的概率
后面的以此类推

这两道题目是不一样的,因为主持人知道门后的东西,但是小泽不知道
所以说主持人一定不会打开车的那扇门,
Day 7
今天上午考了最后一场考试,考了160分,虽然看着是很高,其实全是暴力分,就是有一个遗憾,T4的暴力分没有拿到(其实也不是遗憾,因为样例还没过),但是赛后一想其实T4的暴力也挺好拿的,就是一个简单的dfs + 最简单的背包,还是功夫没有学到家。
然后今天下午讲了讲考试策略:
1.考试的时候先把四个题目全都读懂,哪怕用半个小时读题也要都,先判断出题目的难度,手推一下样例
2.第一条做完后就开始写四个题的暴力,暴力就是拿分的关键,然后如果有时间再开始做T1
3.考试结束前的10-20分钟不要写代码了,检查一下调试信息有没有删,看看freopen有没有写错
4.如果暴力都不会写,那就退役
然后就是考前该做些什么题:
1.套题,这个是最有效的方法,做套题可以广泛的接触知识点,查缺补漏
2.随机题目,比如说洛谷的随机跳题,这样也能广泛地接触知识点
3.顺序做题,和第二条一样
4.限定时间做题,如果到一定时间不会做那就直接看题解,不要浪费时间,如果一个题目限定时间没做出来的话,也是果断放弃并查看题解
upd 2022.10.7 18:55 世间再无清北学堂2022 CSP-S 突破营


【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】凌霞软件回馈社区,博客园 & 1Panel & Halo 联合会员上线
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】博客园社区专享云产品让利特惠,阿里云新客6.5折上折
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 一个费力不讨好的项目,让我损失了近一半的绩效!
· 实操Deepseek接入个人知识库
· CSnakes vs Python.NET:高效嵌入与灵活互通的跨语言方案对比
· 【.NET】调用本地 Deepseek 模型
· Plotly.NET 一个为 .NET 打造的强大开源交互式图表库