瑞吉外卖项目
瑞吉外卖项目(初学+简略)
1.准备
瑞吉外卖项目
视频链接:https://www.bilibili.com/video/BV13a411q753/?p=37&spm_id_from=pageDriver&vd_source=73cf57eb7e9ae1ddd81e6b44cf95dbeb
项目资料:
百度网盘链接:https://pan.baidu.com/s/1bxEy2bHiCYQtouifUppsTA 提取码:1234
大佬的笔记和项目
大佬A跟着敲完了 项目地址:https://gitee.com/GeforceLite/takeout-system/tree/master/ 项目笔记:https://blog.csdn.net/weixin_46906696/article/details/125040457 希望大家少遇Bug~
大佬B笔记:https://cyborg2077.github.io/2022/09/29/ReggieTakeOut/
各种包的作用
-
controller
- Controller是SpringBoot里最基本的组件,他的作用是把用户提交来的请求通过对URL的匹配,分配个不同的接收器,再进行处理,然后向用户返回结果。
- 后台登录功能的开发就是
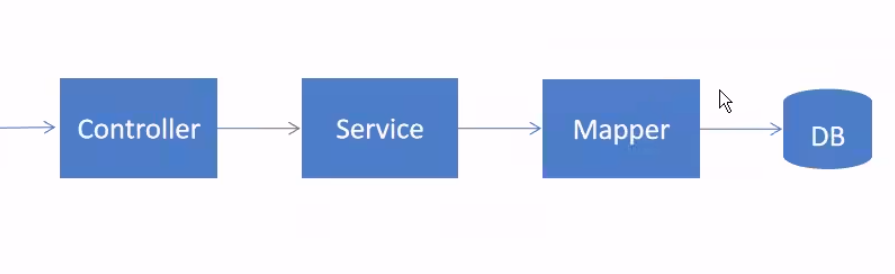
- controller 接收到用户名和密码,然后调用service来查数据库,而service查数据库(间接)是调用了mapper,然后用mapper来调数据库。
-
config
- 所有的配置类都放在这里
-
entity
- 实体类,与数据库表中的数据一一对应
-
common
- 通用的类,比如R是统一的返回结果类
-
filter
- 就是过滤器,全部过滤器都放在这个包里
一些注解的作用
-
@Autowired
使构造函数、字段、设值方法或配置方法可以被Spring依赖注入工具自动装配(Autowired)。
用于字段:字段在bean构造之后,任何配置方法被调用之前被注入。被注入的类需要是一个组件(@Component)。该注解不要求字段是public。
-
json
- JSON(JavaScript Object Notation, JS对象简谱)是一种轻量级的数据交换格式。它基于 ECMAScript(European Computer Manufacturers Association, 欧洲计算机协会制定的js规范)的一个子集,采用完全独立于编程语言的文本格式来存储和表示数据。简洁和清晰的层次结构使得 JSON 成为理想的数据交换语言。 易于人阅读和编写,同时也易于机器解析和生成,并有效地提升网络传输效率。
-
@PostMapping,@GetMapping最主要的区别是
@PostMapping一般处理对象的findUser
@GetMapping一般处理单个id,比如findbyId
@PutMapper一般用在编辑,也可以只用上面两种
-
@Transactional 处理业务逻辑需要的注解,一般在同时操作多张数据库表的时候用,保障数据的一致性,如果没有都修改到,就直接回滚
前端小tips
- 通过scope.row的方式可以把一整条数据传过来

- 比如这里当我单击修改按钮的时候,scope.row就会把对应的一整条数据传过来到editHandle里去。
需要搭建的骨架

2.实际操作
2.1通用的项目骨架

实操





关于如何查看返回值R ,其实是看前端需要后端返回什么样的数据类型。像下图他就只需要res.code。那么后端controller写的时候,就只需要R
3.部分功能实现
3.1 菜品的起售与停售包括批量操作
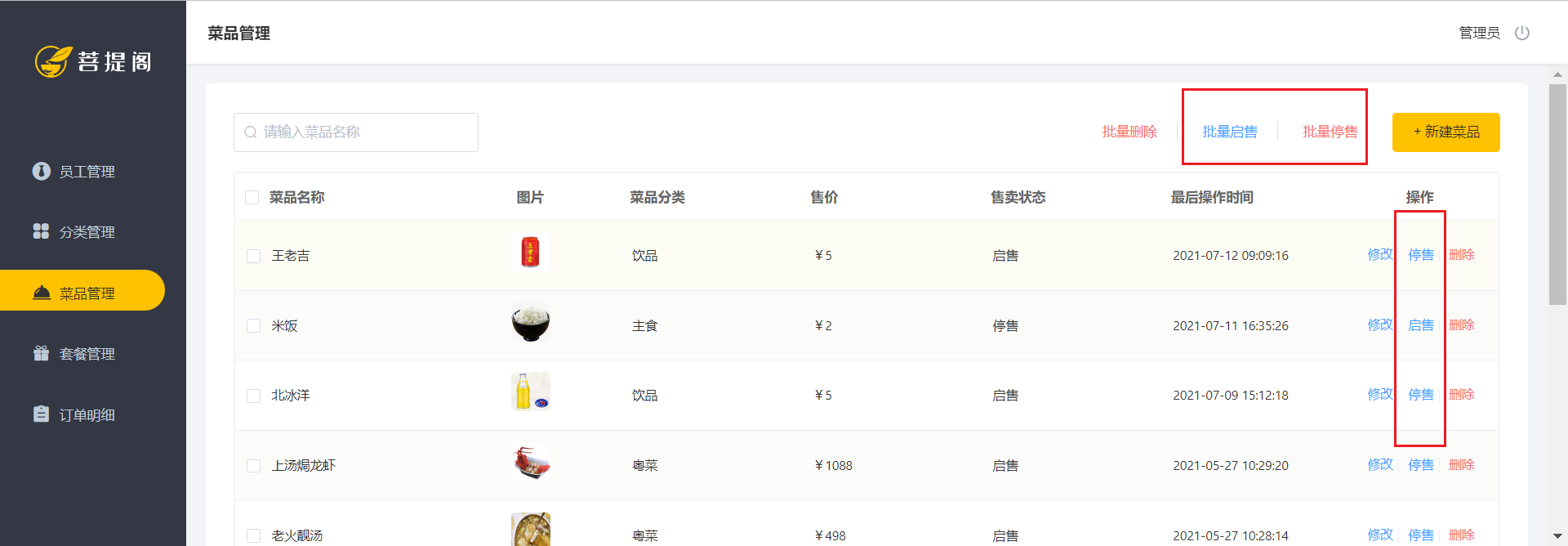
思路
先在浏览器看前端的请求
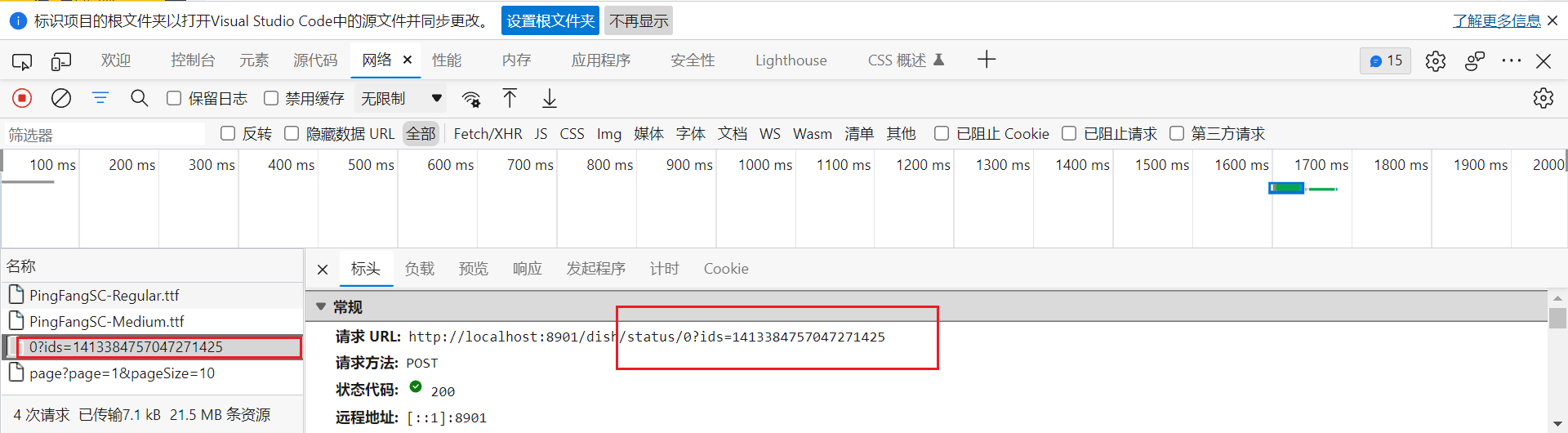
当点击具体的菜品的时候,前端会返回一个作用域上的数据,就是一阵条数据,然后返回一个参数给后端
也就是ids。
所以后端需要设置一个ids参数。
图中可以看到,url路径里有0,1.对应数据库里的起售和停售状态。
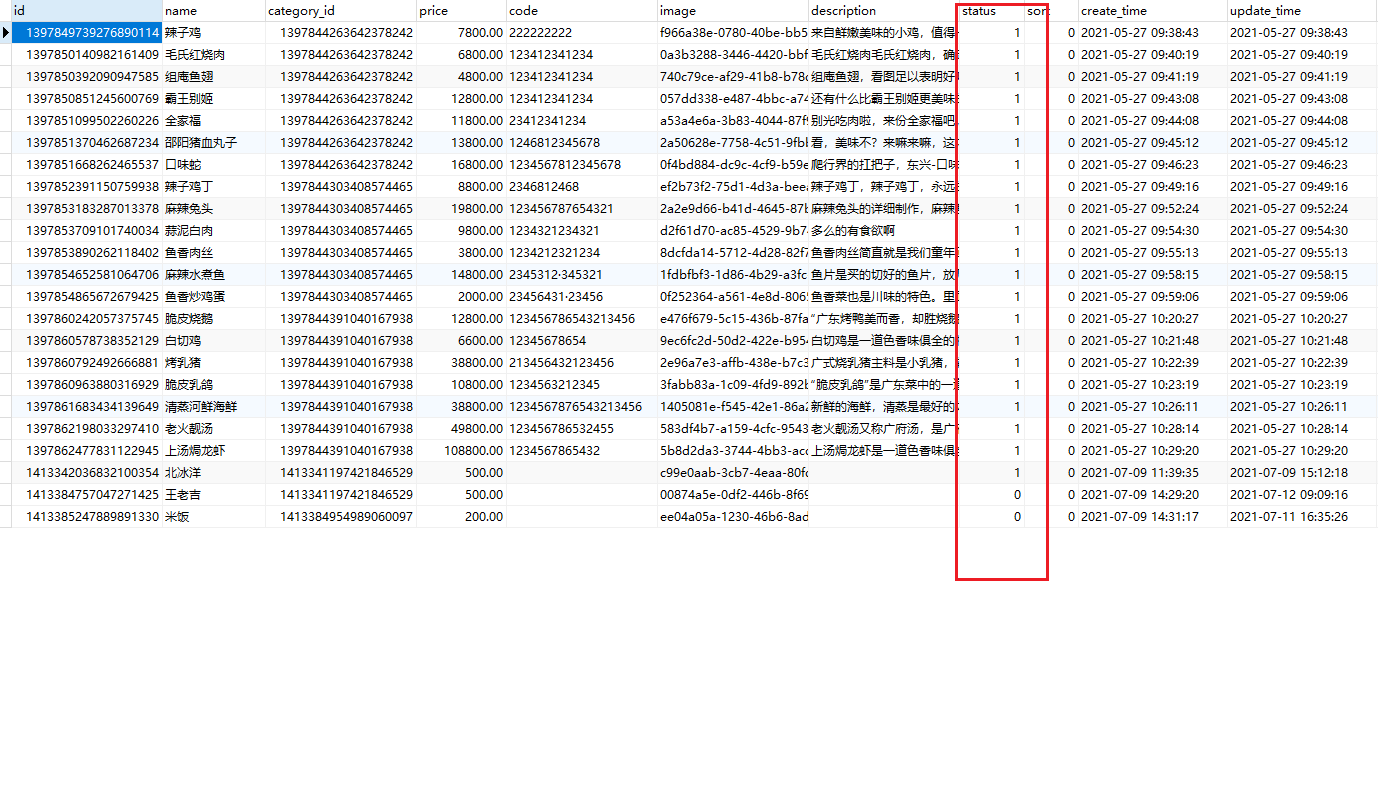
1是起售2是停售。
结合前端代码来看。
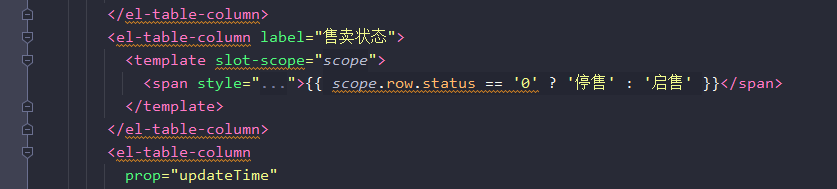
这里用了个正则表达式,当我在前端页面点击起售,对应的售卖状态就要修改为起售,而按钮就变成了停售。

那么后端代码的实现也就是获得对应的菜品id,然后根据按钮的状态修改数据库的表就可以了
后端代码实现
/**
* 菜品的起售和停售,包括批量操作!
* @param status
* @param ids
* @return
*/
@PostMapping("/status/{status}")
public R<String> status(@PathVariable Integer status, @RequestParam List<Long> ids) {
log.info("status:{},ids:{}", status, ids);
LambdaUpdateWrapper<Dish> updateWrapper = new LambdaUpdateWrapper<>();
//对应的菜品的id
updateWrapper.in(ids != null, Dish::getId, ids);
//设置售卖的状态为按钮按下的状态,修改数据库的表即可
updateWrapper.set(Dish::getStatus, status);
//操作数据库
dishService.update(updateWrapper);
return R.success("批量操作成功");
}
3.2 菜品的修改
思路

实现这修改
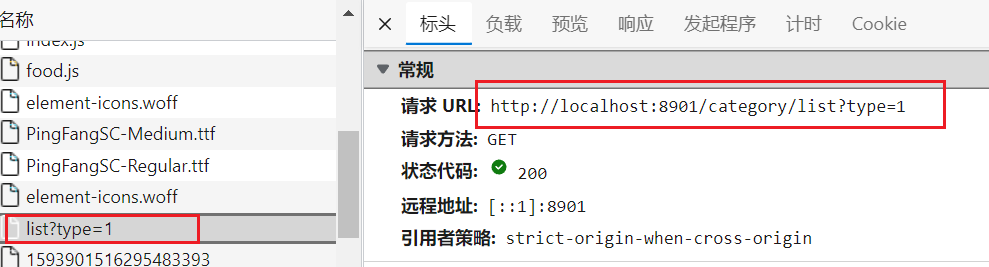
当点击修改按钮的时候前端发送这个ajax请求
- 来看看前端应该如何发出请求
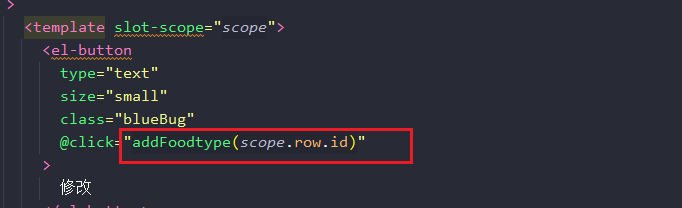
单击该按钮的时候,前端绑定单击时间,获取数据的一整条作用域,包括id。执行哪个addFoodtype函数
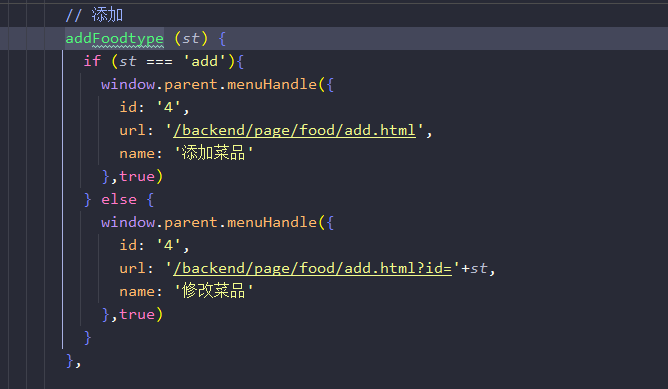
函数的内容则是自动的请求url地址。并且将数据进行回显。
接着后端得满足修改请求,不仅得修改菜品表字段,还得修改口味表字段,同时操作多张表。
所以得定义一个同时修改多张表的方法。
后端先更新简单的菜品表信息,接着由于里边没有口味信息,因此用dishdto对象左右一个扩展,包括了口味信息和菜品名字等
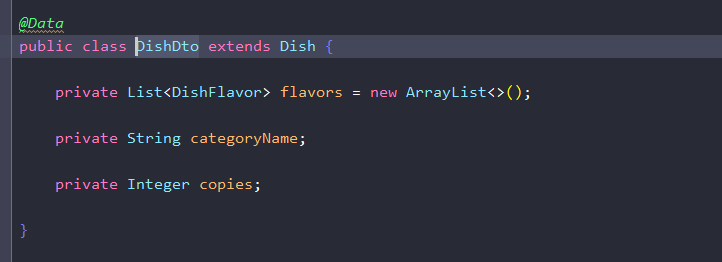
接着由于dto信息最开始是空的,所以得进行dish信息记得的对象拷贝,
然后操控菜品口味表,把里边的信息以stream流的方式收集到list里
然后批量加入到菜品口味表里
代码实现
controller层
/**
* 修改菜品
* @param dishDto
* @return
*/
@PutMapping
public R<String> update(@RequestBody DishDto dishDto){
log.info(dishDto.toString());
dishService.updateWithFlavor(dishDto);
return R.success("修改菜品成功!");
}
接着在service层实现这个updatewithFlavor方法。
/**
* 更新菜品信息同时更新对应的口味信息
* @param dishDto
*/
@Override
@Transactional
public void updateWithFlavor(DishDto dishDto) {
//更新dish表基本信息
this.updateById(dishDto);
//清理当前菜品对应口味数据---dish_flavor表的delete操作
LambdaQueryWrapper<DishFlavor> queryWrapper = new LambdaQueryWrapper<>();
queryWrapper.eq(DishFlavor::getDishId,dishDto.getId());
dishFlavorService.remove(queryWrapper);
//添加当前提交过来的口味数据———— dish_flavor表的insert操作
List<DishFlavor> flavors = dishDto.getFlavors();
flavors = flavors.stream().map((item)->{
item.setDishId(dishDto.getId());
return item;
}).collect(Collectors.toList());
dishFlavorService.saveBatch(flavors);//批量加入口味
}
3.3 套餐管理批量删除的实现
思路与代码实现
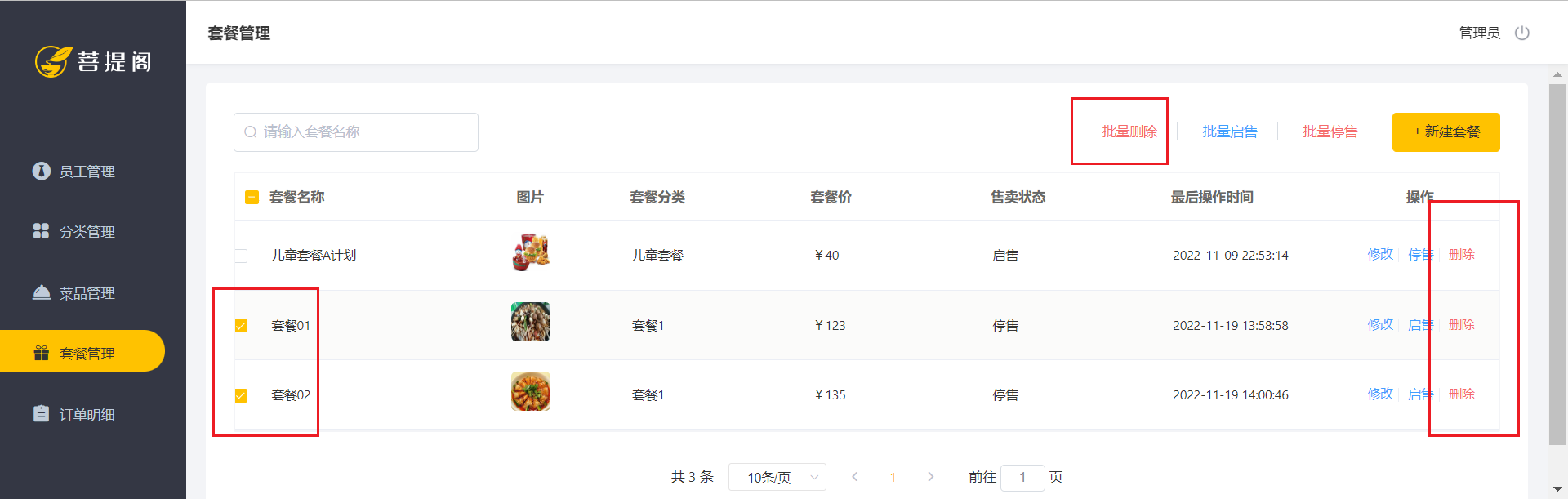
先看看要做的功能是批量删除,其实和删除是差不多的
删除之前必须的停售
-
前端发送删除请求的实现
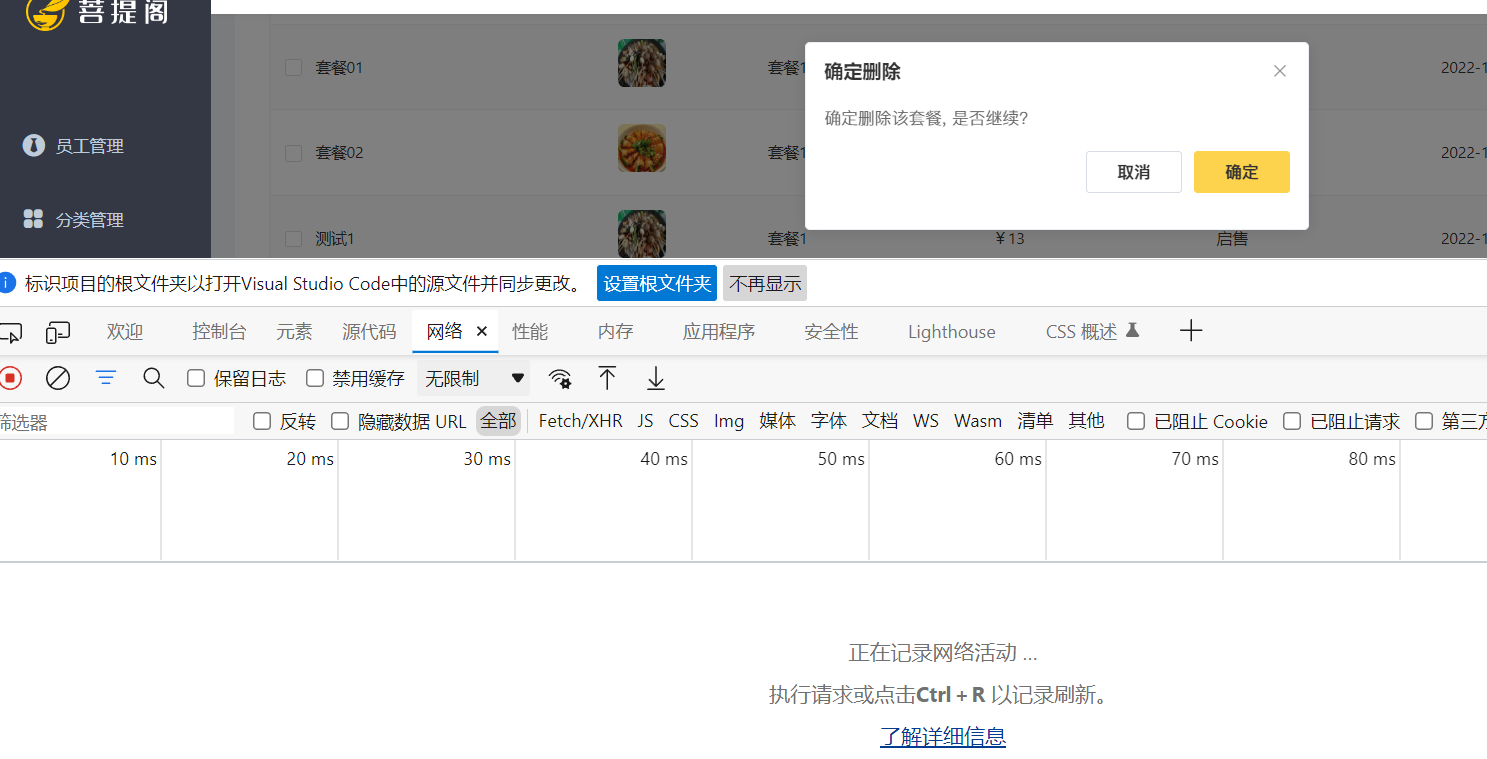
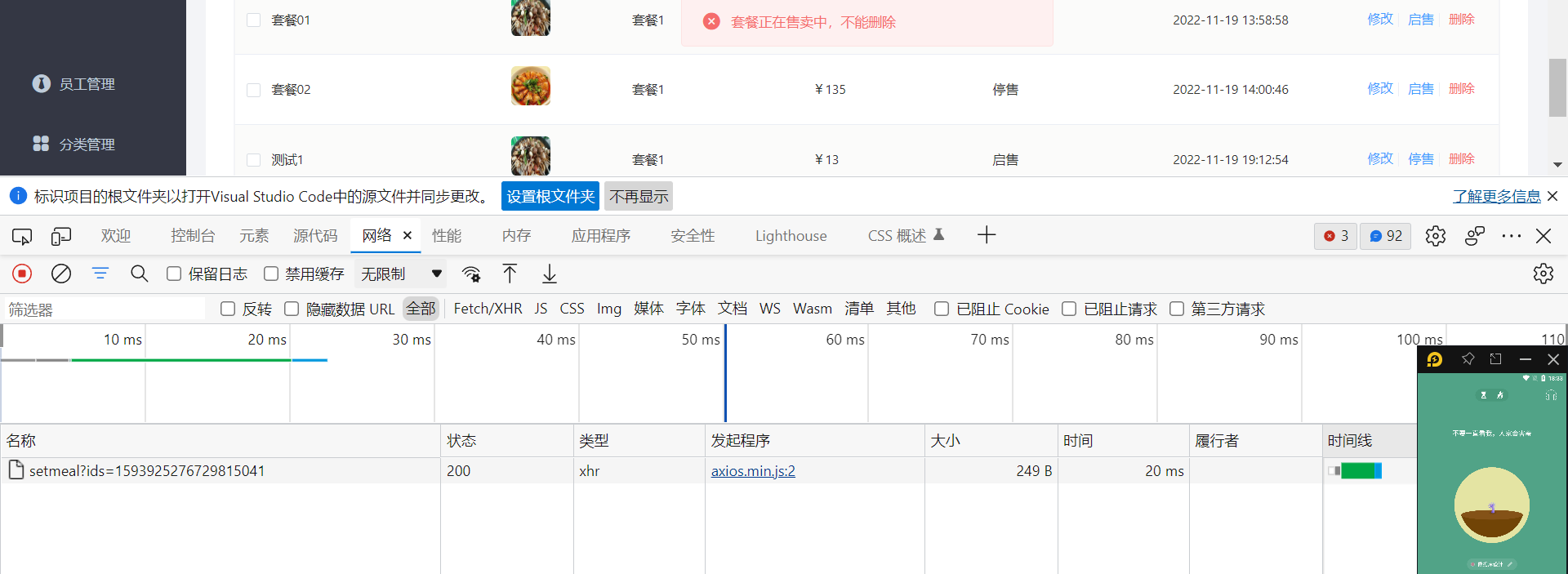
- 请求delete方法。并且要接收需要删除的id去数据库里按照id删除
-
前端发送请求代码
- 点击删除按钮,会执行deleteHandle方法。并且通过该 scope.row.id 获取当前需要删除菜品的id
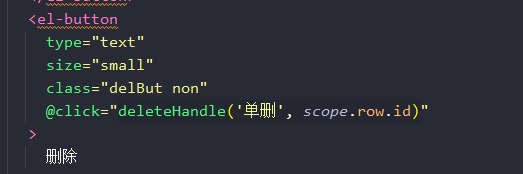
- 具体的方法就是先弹出确认框

- 然后当点击确认之后执行后端方法需要
- 发送Ajax请求
- 需要后端的正确删除返回res。即可
-
后端思路
- 在controller层直接执行mp提供的删除方法调用sevice操纵数据库删除即可
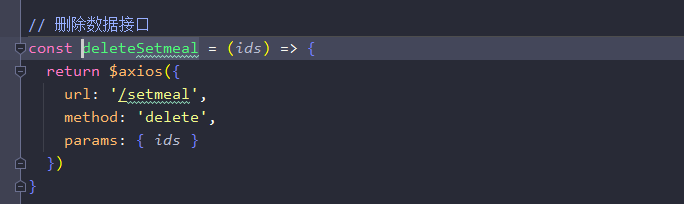
/** * 删除套餐 * @param ids * @return */ @DeleteMapping public R<String> delete(@RequestParam List<Long> ids){ log.info("进入套餐删除!ids:{}",ids); setmealService.removeWithDish(ids); return R.success("套餐数据删除成功"); }
3.4 订单明细的分页查询
-
页面显示
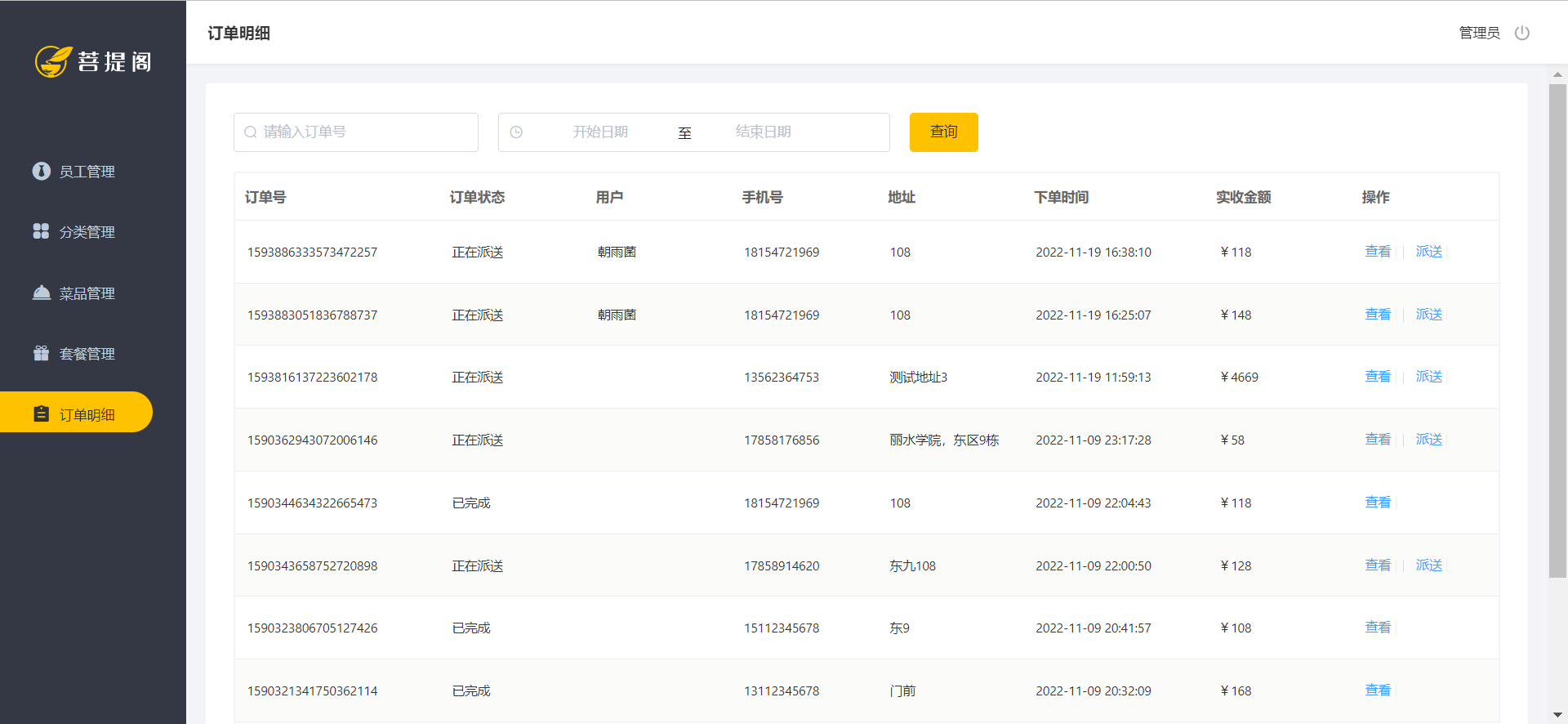
- 要查询出这些数据并且实现分页效果
思路和代码实现
前端
-
前端实现请求分页url
-
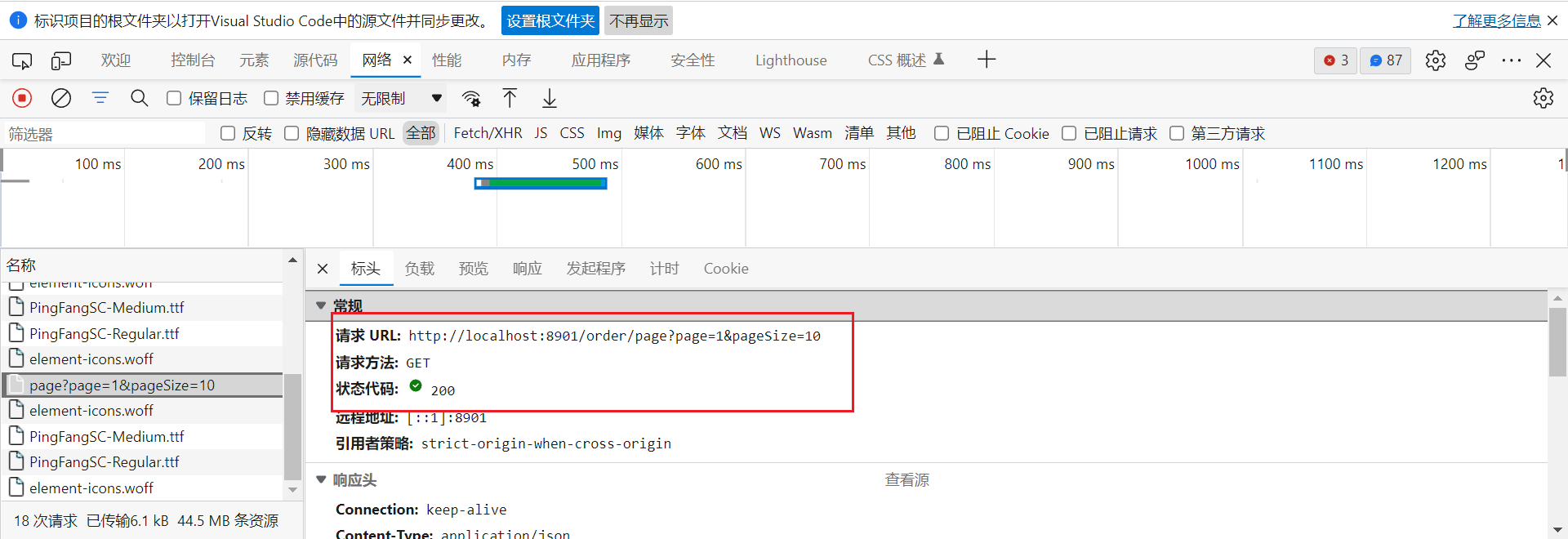
-
定义分页数据指,默认pageSize=10,page=1,
- 也就是默认请求第一页数据,10条一页
-
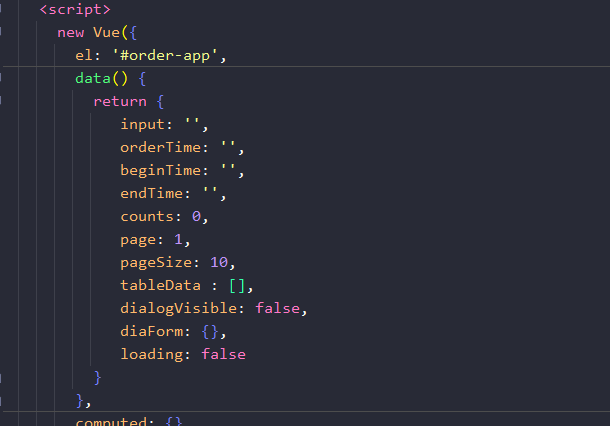
-
页面初始化的时候就执行这个方法
getOrderDetailPage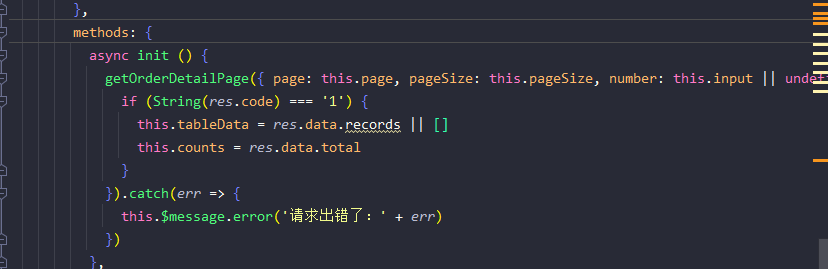
- 这个接口会自动发送ajax请求
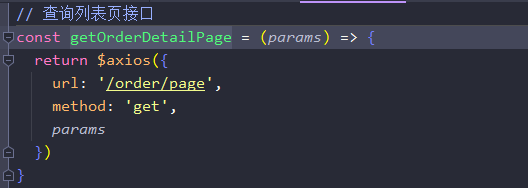
- 这个时候前端发送请求的功能就实现成功了
后端部分
-
思路
-
查看了页面的请求之后,需要先建立get方法的page网络映射。
-
利用mp提供的分页方法构造分页对象。
-
又因为页面上显示的是多张表的数据,所以单独的pageinfo是不够的,这个时候用了扩展的OrdersDtoPage对象。进行一个对象那个拷贝。
-
条件构造,排序一下再调用service层的方法把排好序的条件传进去即可得到分页对象
-
扩展
- 查询功能,
- 开始时间与结束时间,用的是公共字段自动填充获取订单表里的订单创建时间的方法在数据库表里匹配的方法
- 查看功能。
queryWrapper.eq(number != null, Orders::getId, number);- 当点击查看的时候,页面会自动获取到id号

- 接着我们可以在后端去在数据库里匹配对应的id号,即可查看到详情信息

- 查询功能,
具体的代码实现
/** * 订单页面分页查询 * @param page * @param pageSize * @param number * @param beginTime * @param endTime * @return */ @GetMapping("/page") public R<Page> page(int page, int pageSize, Long number, String beginTime, String endTime) { //获取当前id Page<Orders> pageInfo = new Page<>(page, pageSize); Page<OrdersDto> ordersDtoPage = new Page<>(page, pageSize); //条件构造器 LambdaQueryWrapper<Orders> queryWrapper = new LambdaQueryWrapper<>(); //按时间降序排序 queryWrapper.orderByDesc(Orders::getOrderTime); //订单号 queryWrapper.eq(number != null, Orders::getId, number); //时间段,大于开始,小于结束 queryWrapper.gt(!StringUtils.isEmpty(beginTime), Orders::getOrderTime, beginTime) .lt(!StringUtils.isEmpty(endTime), Orders::getOrderTime, endTime); ordersService.page(pageInfo, queryWrapper); List<OrdersDto> list = pageInfo.getRecords().stream().map((item) -> { OrdersDto ordersDto = new OrdersDto(); //获取orderId,然后根据这个id,去orderDetail表中查数据 Long orderId = item.getId(); LambdaQueryWrapper<OrderDetail> wrapper = new LambdaQueryWrapper<>(); wrapper.eq(OrderDetail::getOrderId, orderId); List<OrderDetail> details = orderDetailService.list(wrapper); BeanUtils.copyProperties(item, ordersDto); //之后set一下属性 ordersDto.setOrderDetails(details); return ordersDto; }).collect(Collectors.toList()); BeanUtils.copyProperties(pageInfo, ordersDtoPage, "records"); ordersDtoPage.setRecords(list); //日志输出看一下 log.info("list:{}", list); return R.success(ordersDtoPage); } -
3.5 订单状态的改变(派送订单,完成订单)
功能说明
- 用户在下单之后是等待派送的状态
- 进入管理端之后,点击派送,就派送出去了,就会显示完成
- 再点击一下完成,订单就真的完成啦,显示完成状态



思路和代码实现
-
前端实现
- 前端就是接收具体的订单号,然后发送请求
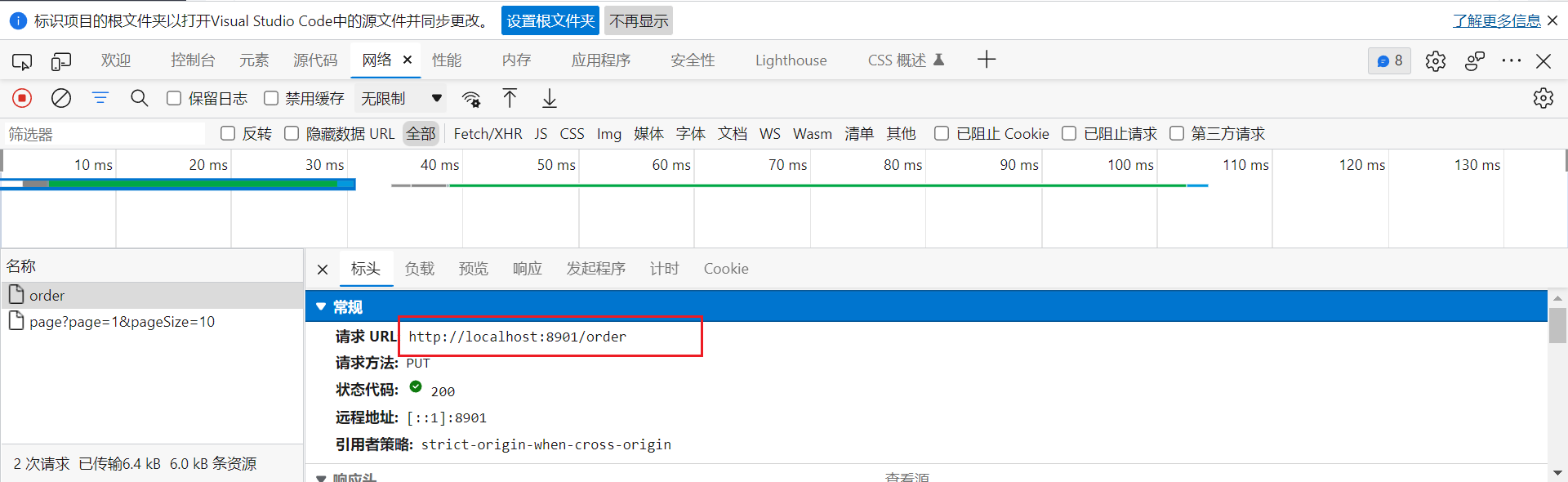
- 也就是按了那个派送按钮之后,获取了当前的订单号然后调用方法发送请求

- 接着对应这个方法
- 先弹出确认框,确认之后发送ajax请求
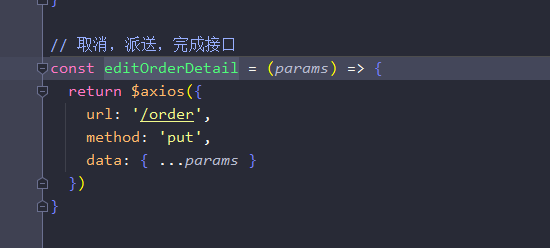
- 接着等后端成功之后回传成功信息在页面上回显
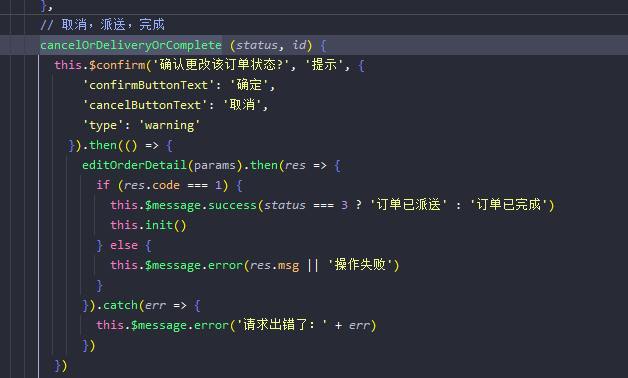
-
后端实现
- 已经知道前端需要请求到的status和id参数就可以拿过来直接用。
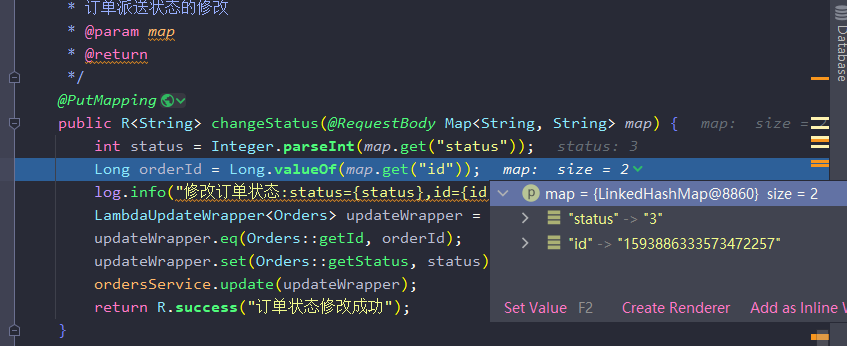
- 用map对象获取了前端请求到的status和id之后,构造条件调用sevice操纵数据库即可。
- 代码实现
/** * 订单派送状态的修改 * @param map * @return */ @PutMapping public R<String> changeStatus(@RequestBody Map<String, String> map) { int status = Integer.parseInt(map.get("status")); Long orderId = Long.valueOf(map.get("id")); log.info("修改订单状态:status={status},id={id}", status, orderId); LambdaUpdateWrapper<Orders> updateWrapper = new LambdaUpdateWrapper<>(); updateWrapper.eq(Orders::getId, orderId); updateWrapper.set(Orders::getStatus, status); ordersService.update(updateWrapper); return R.success("订单状态修改成功"); }
许久后的回顾(2023/5/13)
参考博客:https://cyborg2077.github.io/2022/09/29/ReggieTakeOut/
准备工作
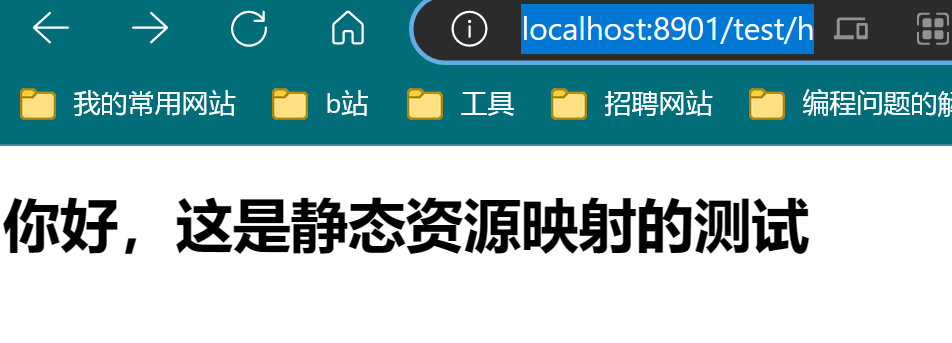
1.关于静态资源映射。
- 简单来说就是把resource目录下的文件夹映射到网络路径上。
如下。
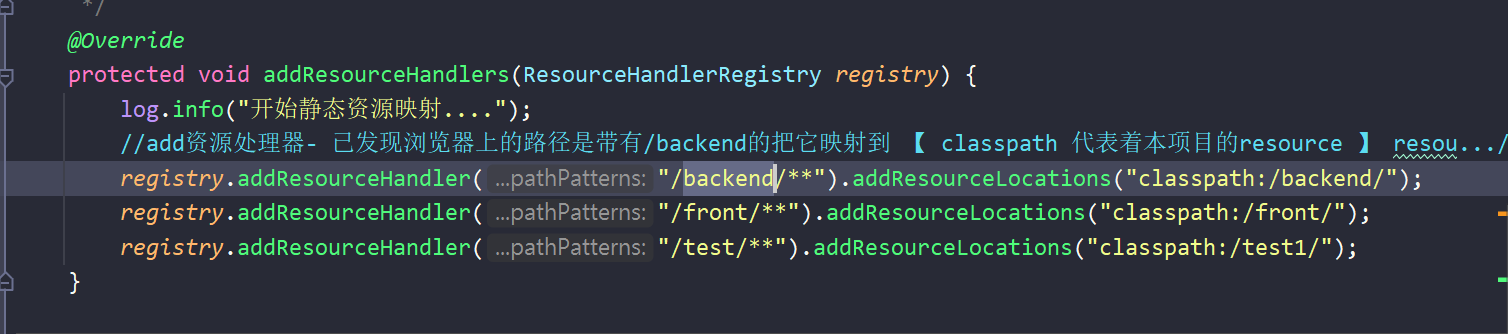
- 这里把resource目录下的test1文件夹映射到了/test/下
并且在拦截器那里要加对应的放行
- 测试如下
2.关于mybatisPlus
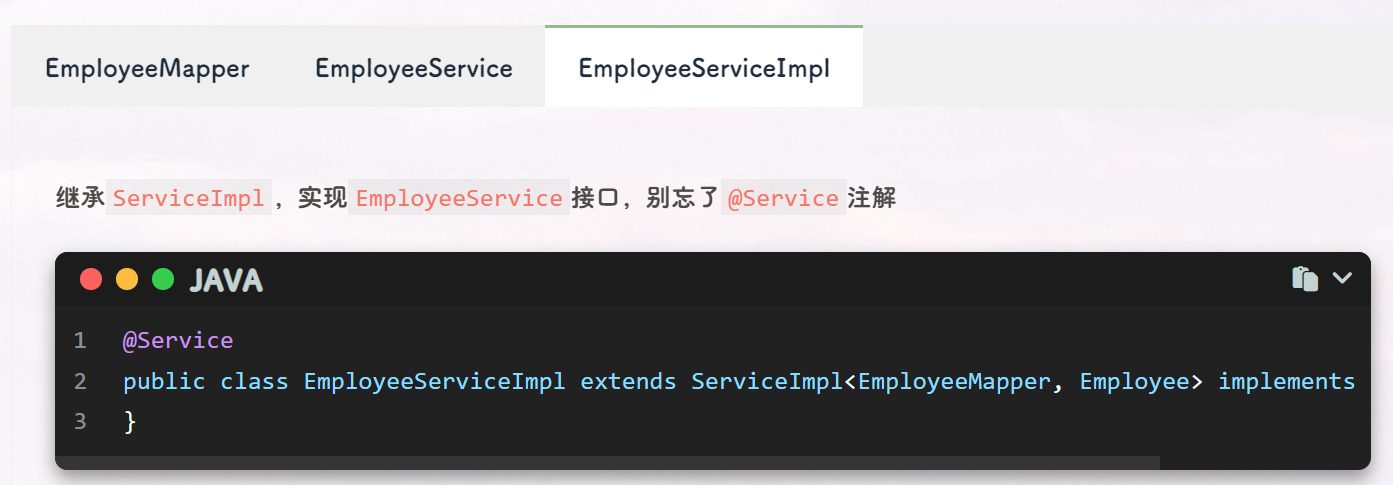
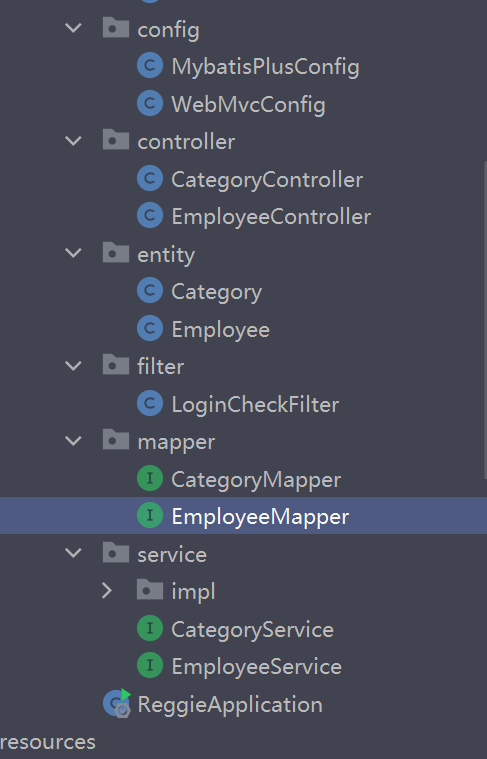
这几步实现了一个基于 MyBatis Plus 框架的 CRUD 操作,主要涉及到以下几个类和接口:
-
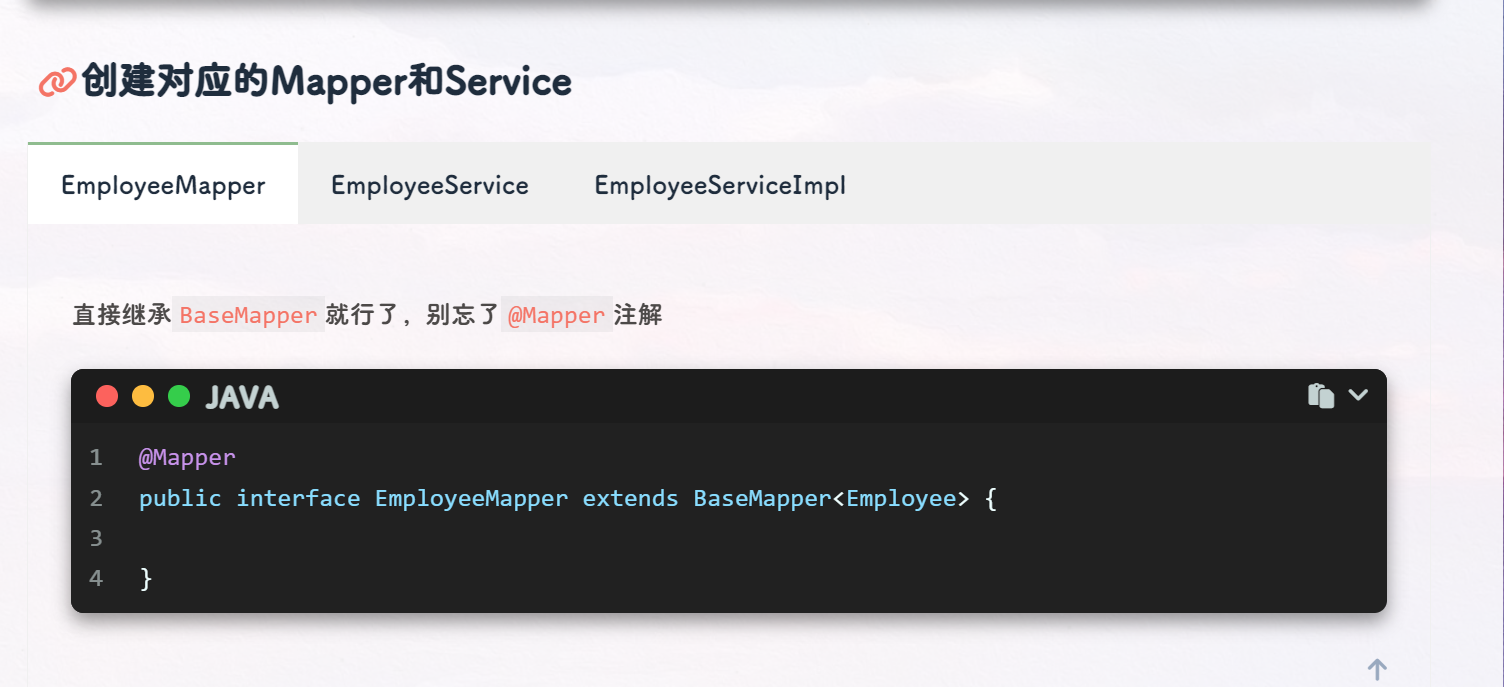
BaseMapper: MyBatis Plus 框架提供的一个基础的 Mapper 接口,其中封装了一些基础的 CRUD 操作方法,如insert、delete、update、select等。 -
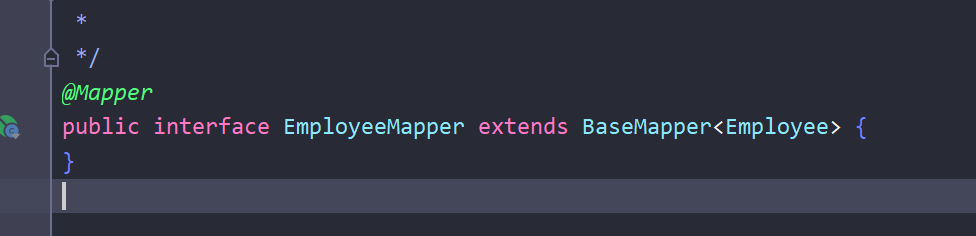
EmployeeMapper: 继承了BaseMapper<Employee>接口,表示对Employee实体进行持久化操作的 Mapper 接口,其中Employee是一个实体类,对应着数据库中的一张表。 -
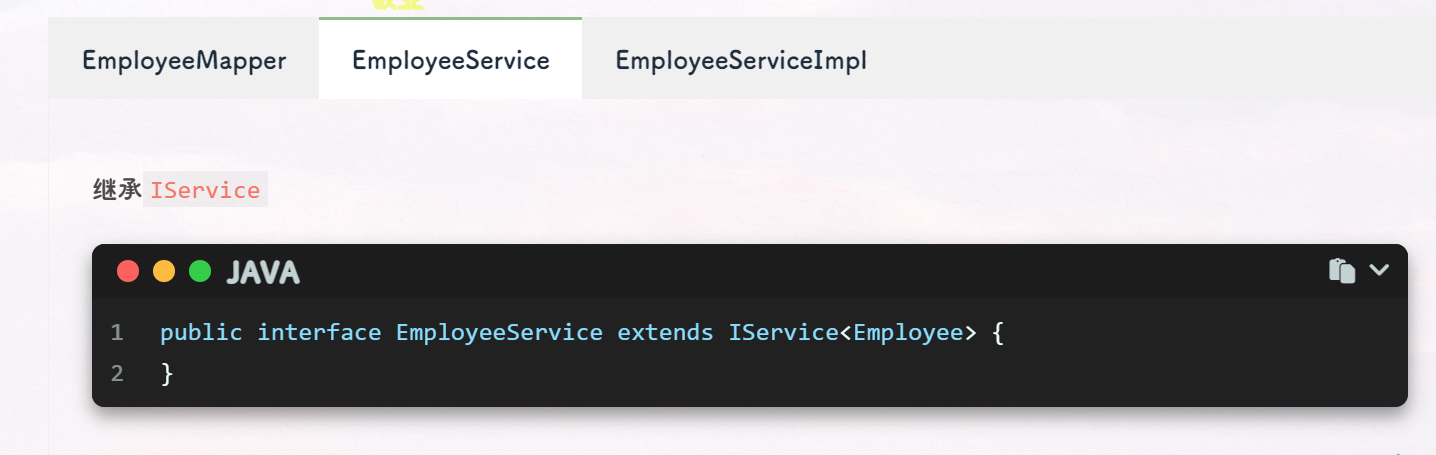
IService: MyBatis Plus 框架提供的一个基础的 Service 接口,其中封装了一些基础的 CRUD 操作方法,如save、removeById、updateById、getById等。 -
EmployeeService: 继承了IService<Employee>接口,表示对Employee实体进行业务操作的 Service 接口。 -
ServiceImpl: MyBatis Plus 框架提供的一个基础的 Service 实现类,其中封装了一些基础的 CRUD 操作方法的实现,如save、removeById、updateById、getById等。 -
EmployeeServiceImpl: 继承了ServiceImpl<EmployeeMapper, Employee>类,表示对Employee实体进行业务操作的 Service 实现类,其中EmployeeMapper是对Employee实体进行持久化操作的 Mapper 接口,Employee是一个实体类,对应着数据库中的一张表。
这样,通过上述几步,我们就可以基于 MyBatis Plus 框架快速地实现对 Employee 实体的 CRUD 操作了。
BaseMapper 提供的 CRUD 操作方法和 IService 提供的 CRUD 操作方法有部分是相同的,但也有一些是不同的。下面分别列出它们提供的主要操作方法:
BaseMapper 提供的主要操作方法:
insert:插入一条记录。insertBatch:批量插入多条记录。deleteById:根据 ID 删除一条记录。deleteBatchIds:根据多个 ID 批量删除多条记录。updateById:根据 ID 更新一条记录。selectById:根据 ID 查询一条记录。selectList:查询所有记录。selectPage:分页查询记录。
IService 提供的主要操作方法:
save:保存一条记录,根据传入的实体对象判断是插入一条新记录还是更新一条已有记录。saveBatch:批量保存多条记录,根据传入的实体对象列表判断是插入多条新记录还是更新多条已有记录。removeById:根据 ID 删除一条记录。removeByIds:根据多个 ID 批量删除多条记录。updateById:根据 ID 更新一条记录。getById:根据 ID 查询一条记录。list:查询所有记录。page:分页查询记录。
以 Employee 表为例,下面是它们对应的 SQL 语句:
insert:INSERT INTO employee(name, age, gender) VALUES (?, ?, ?)insertBatch:INSERT INTO employee(name, age, gender) VALUES (?, ?, ?), (?, ?, ?), ...deleteById:DELETE FROM employee WHERE id = ?deleteBatchIds:DELETE FROM employee WHERE id IN (?, ?, ...)updateById:UPDATE employee SET name = ?, age = ?, gender = ? WHERE id = ?selectById:SELECT * FROM employee WHERE id = ?selectList:SELECT * FROM employeeselectPage:SELECT * FROM employee LIMIT ?, ?
注意,上述 SQL 语句中的 employee 是表名,name、age、gender、id 是表的列名,? 是占位符,实际值将在代码中根据具体情况进行替换。
实际上,IService 接口的主要目的是为了封装业务逻辑的实现,而 BaseMapper 接口的主要目的是为了封装数据访问的实现,它们之所以提供的 CRUD 操作方法有所不同,是因为它们的职责不同。
在一个典型的 Java Web 应用中,通常是将应用分成多层,如控制层、业务层和数据访问层。其中,控制层负责接收用户的请求并返回响应,业务层负责处理业务逻辑,而数据访问层负责与数据库进行交互。
使用 BaseMapper 接口提供的 CRUD 操作方法,可以方便地进行数据访问的实现,但是它并没有考虑业务逻辑的实现,比如保存一条记录时需要进行数据校验、更新一条记录时需要记录修改日志等。这些业务逻辑的实现,通常需要在业务层中进行。
因此,IService 接口提供了一些与业务逻辑相关的操作方法,比如 save、removeById、updateById 等,它们继承了 BaseMapper 接口提供的 CRUD 操作方法,并在此基础上增加了一些业务逻辑的实现。通过使用 IService 接口提供的操作方法,我们可以在业务层中方便地实现业务逻辑,并与数据访问层进行解耦。
以上解决了这些问题:
-
那几个操作实现了什么?
-
BaseMapper 提供的CRUD操作方法和IService提供的CRUD操作方法是不一样的吗?它们的操作方法有哪些,请列的全面一点。甚至可以以Employee 表为例把对应的sql语句列出来
-
为什么BaseMapper 提供的CRUD操作方法和IService提供的CRUD操作方法,大部分是相同的,但是却还要分开来呢?不能都用BaseMapper的方法嘛?
3.统一结果封装R.succeed
就像这个
/**
* 通用的返回结果 R对象。服务端响应的数据最终都会封装成此对象
* @param <T>
*/
@Data
public class R<T> {
private Integer code; //编码:1成功,0和其它数字为失败
private String msg; //错误信息
private T data; //数据,这里是有T 上边是R<T>,泛型增加通用性。
private Map map = new HashMap(); //动态数据
public static <T> R<T> success(T object) {
R<T> r = new R<T>();
r.data = object;
r.code = 1;
return r;
}
public static <T> R<T> error(String msg) {
R r = new R();
r.msg = msg;
r.code = 0;
return r;
}
public R<T> add(String key, Object value) {
this.map.put(key, value);
return this;
}
}
理解起来就是T是泛型,这里对于成功的结果,T是任意的值。可以是字符串,可以是数字,可以是数组,可以是任意的类型。
- 其中T并不是固定写法,
<T>是一种泛型方法的声明方式,只是一种泛型常用习惯常用的还有,E,K,V 等。
那么对应返回到结果就是这些:
返回到成功结果可以是任意数据。
基本上我理解了。
R是这么起作用的。
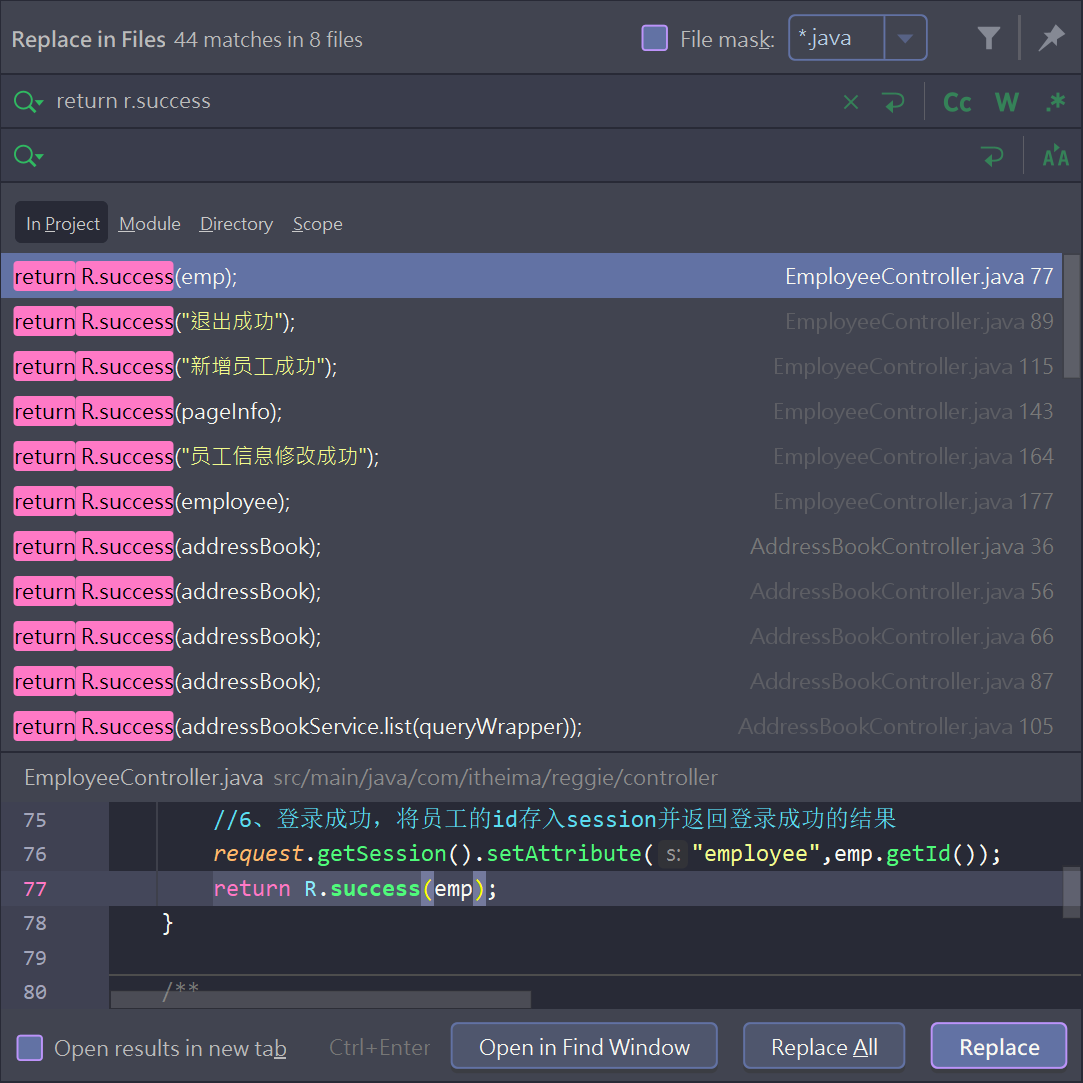
- 首先前端发起异步请求,请求后端数据
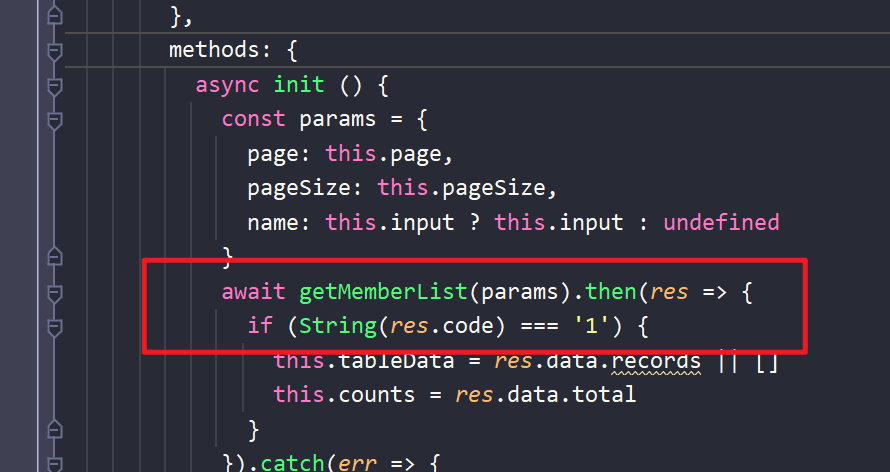
进入getMemberList(params) 方法内部
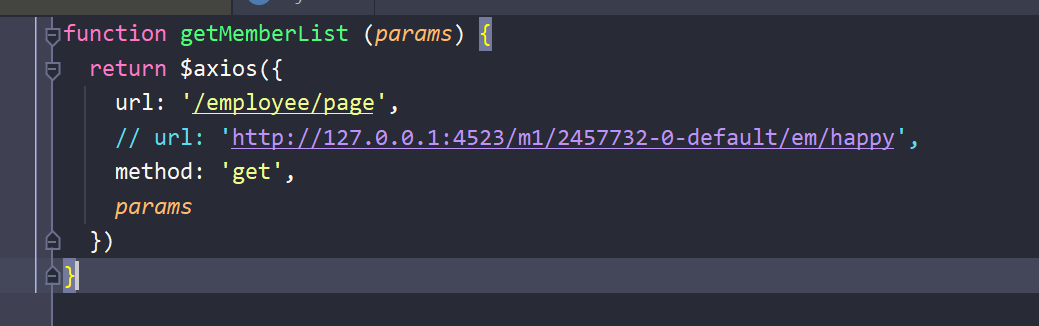
- 我们来看看请求到了后端的什么数据
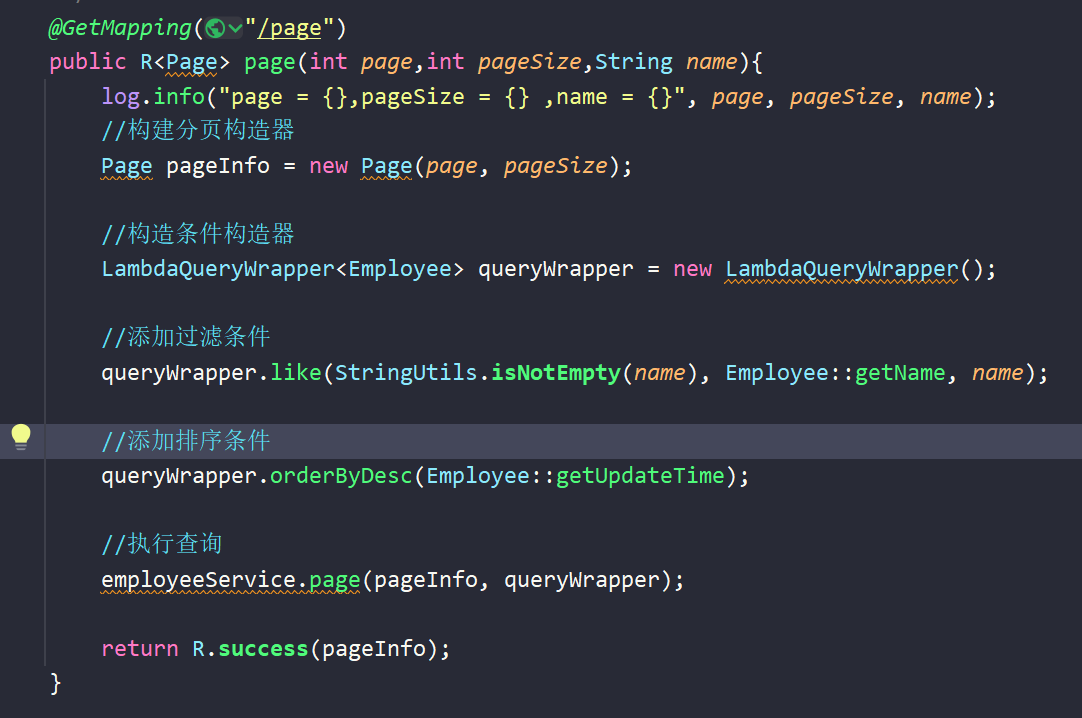
调用了R.success方法,参数是pageInfo,也就是分页构造器。
- 进入R.success方法
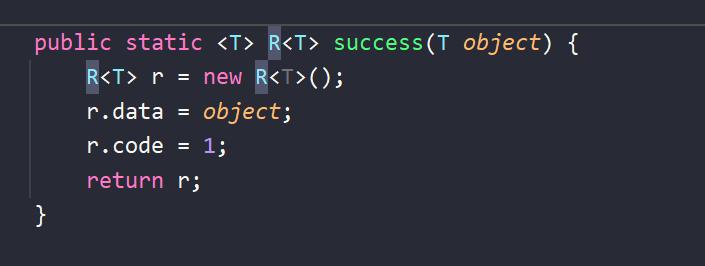
这里返回了r对象,对应的r.data 就是我们的分页构造器。
- 接着对后端的数据进行处理
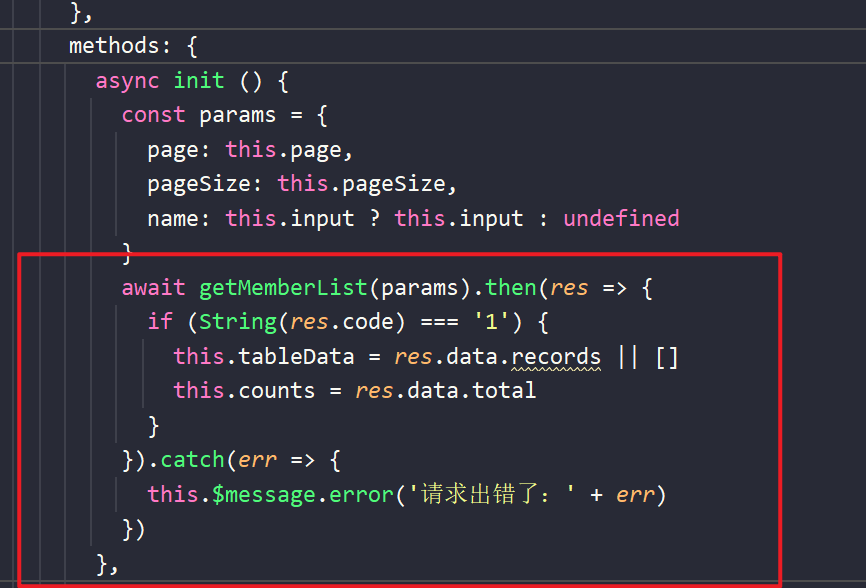
其中res.data对应的就是分页构造器。
这里把后端成功的时候拿到的数据给存到前端的tableDate 和counts上了。
这样可以把数据成功显示出来。
@RestController 注解表示该类是一个 REST 风格的控制器,它的所有方法都会被解析为 API 接口,而不是视图。在 Spring Boot 中,使用 @RestController 注解来定义 REST 风格的控制器,它的返回值会自动转换为 JSON 格式的数据,并通过 HTTP 协议返回给客户端。
4.员工登录和退出
@PostMapping("/login")
public R<Employee> login(HttpServletRequest request,@RequestBody Employee employee ){
//1,将页面提交的密码进行md5加密处理
String password = employee.getPassword();
password = DigestUtils.md5DigestAsHex(password.getBytes());
//2、根据页面提交的为户名username登询数据库
//条件构造器
LambdaQueryWrapper<Employee> queryWrapper = new LambdaQueryWrapper<>();
//这里前者数据库里的,后者是页面接收的,进行一个等值查询
queryWrapper.eq(Employee::getUsername, employee.getUsername());
//这里getOne是因为进行了唯一约束,emp其实是比对过后,查到的对象
Employee emp = employeeService.getOne(queryWrapper);
//3、如果没有查询到则返回登录失败的结果
if(emp == null){
return R.error("登录失败");
}
//4、密码比对,如果不一致则返回登录失败结果
if(!emp.getPassword().equals(password)){
return R.error("登录失败");
}
//5、查看员工状态,如果是已禁用的员工,则返回员工已禁用的结果
if(emp.getStatus() == 0){
return R.error("账号已禁用");
}
//6、登录成功,将员工的id存入session并返回登录成功的结果
request.getSession().setAttribute("employee",emp.getId());
return R.success(emp);
}
/**
* 员工退出
* @param request
* @return
*/
@PostMapping("/logout")
public R<String> logout(HttpServletRequest request){
//清理session中保存的当前登录员工的id
request.getSession().removeAttribute("employee");
return R.success("退出成功");
}
5.登录拦截器
package com.itheima.reggie.filter;
import com.alibaba.fastjson.JSON;
import com.itheima.reggie.common.BaseContext;
import com.itheima.reggie.common.R;
import lombok.extern.slf4j.Slf4j;
import org.springframework.transaction.annotation.Transactional;
import org.springframework.util.AntPathMatcher;
import javax.servlet.*;
import javax.servlet.annotation.WebFilter;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
import java.io.IOException;
/**
* 检查用户是否完成登录
*
* @WebFilter(filterName = "loginCheckFilter",urlPatterns = "/*")
* 要加入网路拦截器的注解,前者是名称,可以随意,后者是要拦截的路径
*/
@Slf4j
@WebFilter(filterName = "loginCheckFilter",urlPatterns = "/*")
public class LoginCheckFilter implements Filter {
//路径匹配器 ,支持通配符 .(专门用来路径比较)
public static final AntPathMatcher PATH_MATCHER = new AntPathMatcher();
//拦截主要实现这个方法即可
@Override
public void doFilter(ServletRequest servletRequest, ServletResponse servletResponse, FilterChain filterChain) throws IOException, ServletException {
//这里得转换一下
HttpServletRequest request = (HttpServletRequest) servletRequest;
HttpServletResponse response = (HttpServletResponse) servletResponse;
//1.获取本次请求的URI,并且定义不需要处理的请求路径
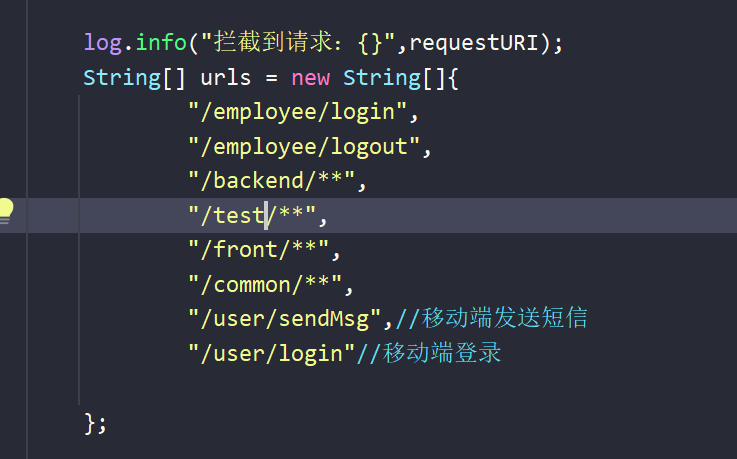
String requestURI = request.getRequestURI();// 这里当请求 /backend/index.html 的时候是和通配符不匹配的。所以需要弄路径匹配器让它们能够匹配,也就是能够放行成功
log.info("拦截到请求:{}",requestURI);
String[] urls = new String[]{
"/employee/login",
"/employee/logout",
"/backend/**",
"/test/**",
"/front/**",
"/common/**",
"/user/sendMsg",//移动端发送短信
"/user/login"//移动端登录
};
//2.判断本次请求是否需要处理
boolean check = check(urls, requestURI);
//3.如果不需要处理则直接放行
if(check){
log.info("本次请求{}不需要处理",requestURI);
filterChain.doFilter(request,response);
return;
}
//4-1.判断登录状态,如果已登录则直接放行。(后台端)
if(request.getSession().getAttribute("employee")!=null){
log.info("用户已登录,用户id为:{}",request.getSession().getAttribute("employee"));
Long empId = (Long) request.getSession().getAttribute("employee");
BaseContext.setCurrentId(empId);
filterChain.doFilter(request,response);
return;
}
//4-2.判断登录状态,如果已登录则直接放行。(移动端)
if(request.getSession().getAttribute("user")!=null){
log.info("用户已登录,用户id为:{}",request.getSession().getAttribute("user"));
Long userId = (Long) request.getSession().getAttribute("user");
BaseContext.setCurrentId(userId);
filterChain.doFilter(request,response);
return;
}
log.info("用户未登录");
//5.如果未登录则返回未登录的结果,通过输出流的方式向客户响应数据(响应就得写回去,将json数据写回去给用户响应。
response.getWriter().write(JSON.toJSONString(R.error("NOTLOGIN")));
return;
}
/**
* 路径匹配,检查本次请求是否需要放行
* @param urls
* @param requestURI
* @return
*/
public boolean check(String[] urls ,String requestURI){
for(String url: urls){
boolean match = PATH_MATCHER.match(url,requestURI);
if(match){
return true;
}
}
return false;
}
}
启动类加注解
@ServletComponentScan //这样子它才会去扫描过拦截器那些注解
6.员工增删查改
其实都没什么难度,都能分析看懂。
7.完善全局异常处理器(捕捉异常,自定义处理结果)
就很简单,套用就行
8.配置状态转换器(解决long丢失精度)
配过一次之后照着用就可了
9.dto对象
原理就是继承再扩展,不难理解。
stream流那些照着用也就可以了。
总结
- 测试的习惯很重要
- 不懂的点没有必要去死抠,很可能是知识点学的不够。有时间就学,没时间就以后再补。
- 很多配置都是会用就行。
- 整个项目基本上都是增删查改和各种配置。
完结撒花!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号