python 编码
1.字符编码简介:
1.1 ASCII :
ASCII(发音: /ˈæski/ ass-kee[1],American Standard Code for Information Interchange,美国信息交换标准代码)是基于拉丁字母的一套电脑编码系统。它主要用于显示现代英语,而其扩展版本EASCII则可以部分支持其他西欧语言,并等同于国际标准ISO/IEC 646。(维基百科)
ASCII码在python中的使用:
1.python 2.7中解释器默认的字符编码是ascii
2.支持的字符有:英文字母,部分西欧字母,数字,标点符号及部分特殊字符,不支持中文。
3.一个ASCII码字符使用一个字节,8位
1.2 GBK:
汉字内码扩展规范,称GBK,全名为《汉字内码扩展规范(GBK)》1.0版,由中华人民共和国全国信息技术标准化技术委员会1995年12月1日制订,国家技术监督局标准化司和电子工业部科技与质量监督司1995年12月15日联合以《技术标函[1995]229号》文件的形式公布。 GBK共收录21886个汉字和图形符号,其中汉字(包括部首和构件)21003个,图形符号883个。
GBK的K为汉语拼音Kuo Zhan(扩展)中“扩”字的声母。英文全称Chinese Internal Code Extension Specification。(维基百科)
GBK在python中的使用:
1.当读取编码格式为GBK的文件时,需要在读取时指定编码为GBK。
2.如果写入的文件全部都是中文的话,可以考虑选用GBK编码。
3.支持的字符有:中文,大部分韩文及日文,字母,数字,标点符号及特殊字符等。
4.一个GBK字符使用2个字节,16位
5.兼容ASCII
1.3 UNICODE:
Unicode(中文:万国码、国际码、统一码、单一码)是计算机科学领域里的一项业界标准。它对世界上大部分的文字系统进行了整理、编码,使得电脑可以用更为简单的方式来呈现和处理文字。
Unicode伴随着通用字符集的标准而发展,同时也以书本的形式[1]对外发表。Unicode至今仍在不断增修,每个新版本都加入更多新的字符。目前最新的版本为2018年6月5日公布的11.0.0[2],已经收录超过13万个字符(第十万个字符在2005年获采纳)。Unicode涵盖的数据除了视觉上的字形、编码方法、标准的字符编码外,还包含了字符特性,如大小写字母。(维基百科)
1.python3 中字符显示的编码就是unicode
2.基本支持所有的字符类型(万国码)
3.一个UNICODE字符使用4个字节,32位
4.UNICODE不支持文件传输和文件存储
5.python的字符串默认是unicode类型,可以理解unicode为一个中间转换的规范,它可以识别其他所有的编码,decode(解码)是将其他编码转换为unicode(可识别字符),encode(编码)是将unicode转换为其他编码的byte数据。
6.兼容ASCII
1.4 utf-8
UTF-8(8-bit Unicode Transformation Format)是一种针对Unicode的可变长度字符编码,也是一种前缀码。它可以用来表示Unicode标准中的任何字符,且其编码中的第一个字节仍与ASCII兼容,这使得原来处理ASCII字符的软件无须或只须做少部分修改,即可继续使用。因此,它逐渐成为电子邮件、网页及其他存储或发送文字的应用中,优先采用的编码。(维基百科)
1.python3 源代码编码及解释器默认编码都为utf-8
2.可变的unicode编码,最低长度一个字节,根据具体字符分配字符长度,
英文字母,数字 分配一个字节,8位
中文 分配3个字节 24位
总结: 广义的来理解UNICODE 是一个标准,定义了一个字符集和一系列的编码标准,即utf-8,utf-16等.
ASCII,GBK,UTF-8这些才是编码规则,将字符串(unicode,python3中字符串的编码就是unicode)通过编码转换为bytes的过程叫做encode,将bytes通过指定编码转换为字符串(unicode)的过程教程decode.
3.兼容 ASCII
2编码解码
encode 和 decode默认不指定编码,编码为utf-8
In [1]: a = "python之禅" In [2]: a.encode() Out[2]: b'python\xe4\xb9\x8b\xe7\xa6\x85' In [3]: b = a.encode() In [4]: b Out[4]: b'python\xe4\xb9\x8b\xe7\xa6\x85' In [5]: b.decode() Out[5]: 'python之禅'
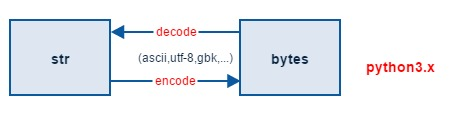
encode : 将字符串编码成进制字节
decode:将二进制字节解码成字符串
不可在编解码过程中指定编码为unicode,因为unicode本身不是一种编码规则,它是一种字符集,utf-8,16,32才是其衍生出来的编码规则,可以理解其为一个中间件。
python3 中str其实是可以和unicode等价的,所以说str通过编码进行编解码的过程其实就是 unicode与其他编码进行转换的过程。
理论上是你用什么编码进行编码,就需要用什么编码进行解码。
我们可以通过unicode进行不同编码间的转换。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号