Region
Region信息观察
创建表指定命名空间
在创建表的时候可以选择创建到bigdata17这个namespace中,如何实现呢? 使用这种格式即可:‘命名空间名称:表名’ 针对default这个命名空间,在使用的时候可以省略不写
create 'bigdata17:t1','info','level'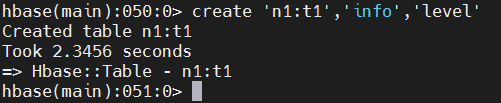
此时使用list查看所有的表
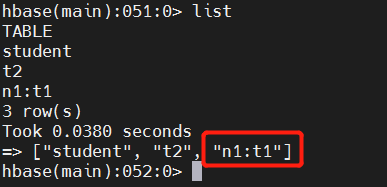
如果只想查看bigdata17这个命名空间中的表,如何实现呢? 可以使用命令list_namespace_tables
list_namespace_tables 'n1'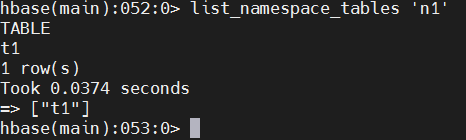
查看region中的某列簇数据(Hadoop中执行)
hbase hfile -p -f /hbase/data/default/tbl_user/92994712513a45baaa12b72117dda5e5/info/d84e2013791845968917d876e2b438a51.1 查看表的所有region
list_regions '表名'
1.2 强制将表切分出来一个region(负载均衡)
split '表名','行键'
但是在页面上可以看到三个:过一会会自动的把原来的删除
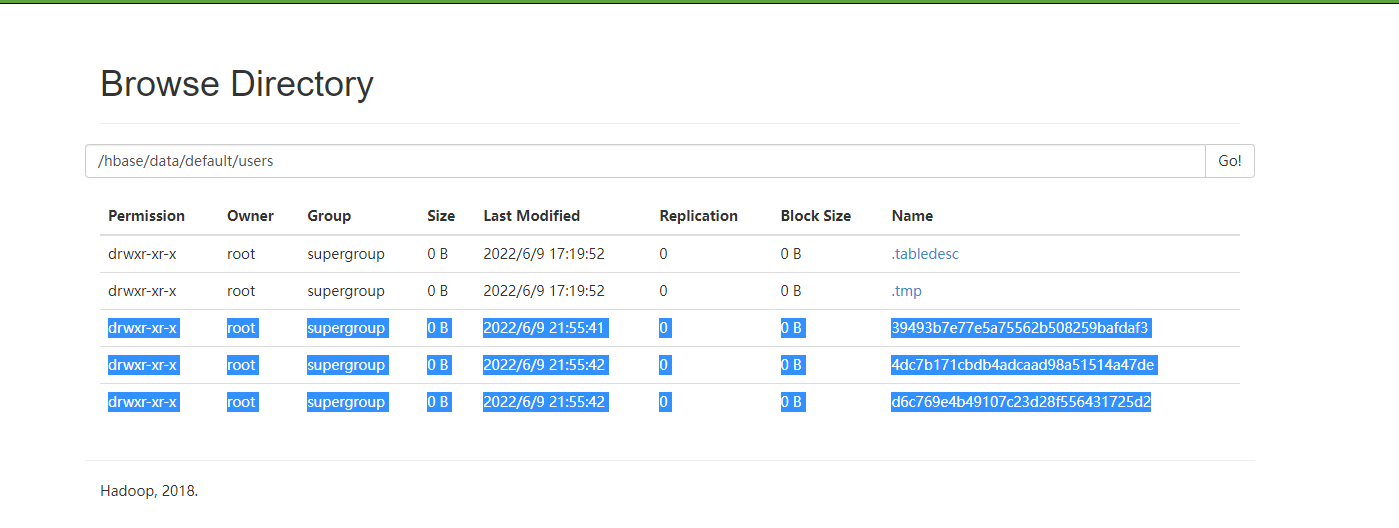
1.2 查看某一行在哪个region中
locate_region '表名','行键'
可以hbase hfile -p -f xxxx 查看一下
2、预分region解决热点问题
row设计的一个关键点是查询维度
(在建表的时候根据具体的查询业务 设计rowkey 预拆分)
在默认的拆分策略中 ,region的大小达到一定的阈值以后才会进行拆分,并且拆分的region在同一个regionserver中 ,只有达到负载均衡的时机时才会进行region重分配!并且开始如果有大量的数据进行插入操作,那么并发就会集中在单个RS中, 形成热点问题,所以如果有并发插入的时候尽量避免热点问题 ,应当预划分 Region的rowkeyRange范围 ,在建表的时候就指定预region范围
查看命令使用(指定4个切割点,就会有5个region)
help 'create'
create 'tb_split','cf',SPLITS => ['e','h','l','r']list_regions 'tb_split'
添加数据试试(bigdata17:tb_split 加上命名空间)
put 'tb_split','c001','cf:name','first'
put 'tb_split','f001','cf:name','second'
put 'tb_split','z001','cf:name','last'hbase hfile -p --f xxxx 查看数据
如果没有数据,因为数据还在内存中,需要手动刷新内存(flush 'bigdata17:tb_split')到HDFS中,以HFile的形式存储
4、日志查看
演示不启动hdfs 就启动hbase
日志目录:
/usr/local/soft/hbase-1.7.1/logs
start-all.sh发现HMaster没启动,hbase shell客户端也可以正常访问
再启动hbase就好了

 浙公网安备 33010602011771号
浙公网安备 33010602011771号