

MapReduce案例
一、MapReduce案例
1.1 好友推荐系统
固定类别推荐
莫扎特---->钢琴---->贝多芬----->命运交响曲
数据量
QQ好友推荐--->
每个QQ200个好友
5亿QQ号
解决思路:
需要按照行进行计算
将相同推荐设置成相同的key,便于reduce统一处理
数据:
tom hello hadoop cat world hello hadoop hive cat tom hive mr hive hello hive cat hadoop world hello mr hadoop tom hive world hello hello tom world hive mr分析:
我们需要在map阶段根据用户的直接联系和间接关系列举出来,map输出的为tom:hadoop 1,hello:hadoop 0,0代表间接关系,1代表直接关系。在Reduce阶段把直接关系的人删除掉,再输出。
具体实现
package com.shujia.tuijian; import com.sun.org.apache.bcel.internal.generic.ACONST_NULL; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.Mapper; import org.apache.hadoop.mapreduce.Reducer; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import java.io.IOException; import java.lang.management.LockInfo; class MyMapper extends Mapper<LongWritable, Text, Text, LongWritable> { private Text mkey = new Text(); private LongWritable mvalue = new LongWritable(); @Override protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, LongWritable>.Context context) throws IOException, InterruptedException { //tom hello hadoop cat /** * tom:hello 1 * tom:hadoop 1 * tom:cat 1 * * hello:hadoop -1 * hello:cat -1 * hadoop:cat -1 */ //hadoop tom hive world hello /** * hadoop:tom 1 * hadoop:hive 1 * hadoop:world 1 * hello:hadoop 1 */ //将value类型的数据转成String类型 String line = value.toString(); String[] strings = line.split(" "); for (int i = 1; i < strings.length; i++) { //处理直接好友 mkey.set(orderFriend(strings[0], strings[i])); mvalue.set(1L); context.write(mkey, mvalue); //处理间接好友 for (int j = i + 1; j < strings.length; j++) { mkey.set(orderFriend(strings[i], strings[j])); mvalue.set(-1L); context.write(mkey, mvalue); } } } //目的是将map输出的key进行统一 //hadoop:hello 1 //hello:hadoop 1 public static String orderFriend(String f1, String f2) { //比较字符串的大小 int i = f1.compareTo(f2); if (i > 0) { return f1 + ":" + f2; } else { return f2 + ":" + f1; } } } class MyReducer extends Reducer<Text, LongWritable, Text, LongWritable> { //(hive:hello [-1,-1,1]) @Override protected void reduce(Text key, Iterable<LongWritable> values, Reducer<Text, LongWritable, Text, LongWritable>.Context context) throws IOException, InterruptedException { //hadoop:hello 1 //hadoop:hello -1 int flag = 0; Long sum = 0L; for (LongWritable value : values) { if (value.get() == 1) { flag = 1; } sum += value.get(); } if (flag == 0) { context.write(key, new LongWritable(-1L)); } else { context.write(key, new LongWritable(0L)); } } } /* 计算出给出的数据中有多少直接关系的组合和间接关系的组合, 将组合作为key 直接关系,value是1 间接关系,value是-1 */ public class TuiJianDemo { public static void main(String[] args) throws IOException, InterruptedException, ClassNotFoundException { Configuration conf = new Configuration(); Job job = Job.getInstance(conf); job.setJarByClass(TuiJianDemo.class); job.setNumReduceTasks(1); job.setJobName("推荐任务"); job.setMapperClass(MyMapper.class); job.setReducerClass(MyReducer.class); job.setMapOutputKeyClass(Text.class); job.setMapOutputValueClass(LongWritable.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(LongWritable.class); FileInputFormat.setInputPaths(job, new Path(args[0])); FileOutputFormat.setOutputPath(job, new Path(args[1])); job.waitForCompletion(true); } }
1.2 PM2.5平均值
package com.shujia.airPM25;
import com.shujia.tuijian.TuiJianDemo;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
//20220527:1001 20
//20220527:1001 30
//20220527:1001 40
//...
class MyMapper extends Mapper<LongWritable, Text, Text, LongWritable> {
@Override
protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, LongWritable>.Context context) throws IOException, InterruptedException {
//将一行的数据转成String类型
String line = value.toString();
String[] strings = line.split(",");
//过滤出PM2.5对应的数据
if (strings.length >= 4 && "PM2.5".equals(strings[2])) {
for (int i = 3, j = 1001; i < strings.length; i++, j++) {
//对一行数据做简单的清洗,因为有的时间没有监控到PM2.5的值
if ("".equals(strings[i]) || strings[i] == null || " ".equals(strings[i])) {
strings[i] = "0";
}
context.write(new Text("date: " + strings[0] + "-城市编号:" + j), new LongWritable(Long.parseLong(strings[i])));
}
}
}
}
class MyReducer extends Reducer<Text, LongWritable, Text, LongWritable> {
@Override
protected void reduce(Text key, Iterable<LongWritable> values, Reducer<Text, LongWritable, Text, LongWritable>.Context context) throws IOException, InterruptedException {
Long sum = 0L;
for (LongWritable value : values) {
long l = value.get();
sum += l;
}
//除以24得到该城市当天的PM2.5平均值
long avg = sum / 24;
context.write(key, new LongWritable(avg));
}
}
public class Pm25Avg {
public static void main(String[] args) throws IOException, InterruptedException, ClassNotFoundException {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
job.setJarByClass(Pm25Avg.class);
job.setNumReduceTasks(1);
job.setJobName("计算每个城市每天的pm2.5平均值");
job.setMapperClass(MyMapper.class);
job.setReducerClass(MyReducer.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(LongWritable.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(LongWritable.class);
FileInputFormat.setInputPaths(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
job.waitForCompletion(true);
}
}
提升:两张表合并或者多张表
思路:map程序每次都是读取一行数据,读取两个表内的数据,可以根据数据来源(文件名称)判断当前读取的数据是来自哪一张表,然后打上标记送入reduce去处理,map输出的key是id值,value是id对应的数据。
reduce接收到的数据是<key,{value1,value2,value3,…}>,key是输入的id的值,value中包含表一的id对应的数据,也包含表二的id对应的数据,我们可以通过map里打的标记进行区分,分别记录到list1与list2中,然后将两个list中的数据进行笛卡尔积就能得到一个id连接后的数据,将所有id都进行这样的操作,就能把整个表都处理完
Combiner
job.setCombinerClass
二、MapReduce源码分析(高级部分)
快捷键
ctrl+alt+方向键:查看上一个或者下一个方法
ctrl+shift+alt+c: 拷贝方法的全名 com.shujia.airPM25.Pm25Avg#main
ctrl+alt+b:查看当前接口的实现类2.1 Split
带着问题看源码:
1、map的数量和切片的数量一样?
2、split的大小可以自己调节吗?算法是什么?
源代码的分析从提交任务开始
job.waitForCompletion(true);org.apache.hadoop.mapreduce.Job#waitForCompletion
/**
* Submit the job to the cluster and wait for it to finish.
* @param verbose print the progress to the user
* @return true if the job succeeded
* @throws IOException thrown if the communication with the
* <code>JobTracker</code> is lost
*/
public boolean waitForCompletion(boolean verbose) throws IOException, InterruptedException,ClassNotFoundException {
//判断当前的状态
if (state == JobState.DEFINE) {
//=============关键代码================
submit();
}
//监控任务的运行状态
if (verbose) {
monitorAndPrintJob();
} else {
// get the completion poll interval from the client.
int completionPollIntervalMillis =
Job.getCompletionPollInterval(cluster.getConf());
while (!isComplete()) {
try {
Thread.sleep(completionPollIntervalMillis);
} catch (InterruptedException ie) {
}
}
}
//返回任务状态
return isSuccessful();
}org.apache.hadoop.mapreduce.Job#submit
public void submit() throws IOException, InterruptedException, ClassNotFoundException {
//确认当前任务的状态
ensureState(JobState.DEFINE);
//mapreduce1.x和2.x,但是2的时候将1的好多方法进行了优化
setUseNewAPI();
//获取当前任务所运行的集群
connect();
//创建Job的提交器
final JobSubmitter submitter = getJobSubmitter(cluster.getFileSystem(), cluster.getClient());
status = ugi.doAs(new PrivilegedExceptionAction<JobStatus>() {
public JobStatus run() throws IOException, InterruptedException, ClassNotFoundException {
//提交任务到系统去执行
//Internal method for submitting jobs to the system
//===========关键代码============
return submitter.submitJobInternal(Job.this, cluster);
}
});
//任务的状态修改为运行
state = JobState.RUNNING;
LOG.info("The url to track the job: " + getTrackingURL());
}org.apache.hadoop.mapreduce.JobSubmitter#submitJobInternal
//validate the jobs output specs
//检查一下输出路径存不存在呀,有没有权限之类的
checkSpecs(job);
//生成并设置新的JobId
JobID jobId = submitClient.getNewJobID();
job.setJobID(jobId);
//获取任务的提交目录
Path submitJobDir = new Path(jobStagingArea, jobId.toString());
// Create the splits for the job
LOG.debug("Creating splits at " + jtFs.makeQualified(submitJobDir));
//===========关键代码============ 197行
int maps = writeSplits(job, submitJobDir);
//设置map的数量,其中map的数量就等于切片的数量
conf.setInt(MRJobConfig.NUM_MAPS, maps);
LOG.info("number of splits:" + maps);org.apache.hadoop.mapreduce.JobSubmitter#writeSplits
private int writeSplits(org.apache.hadoop.mapreduce.JobContext job,Path jobSubmitDir) throws IOException,InterruptedException, ClassNotFoundException {
//获取作业的配置文件
JobConf jConf = (JobConf)job.getConfiguration();
int maps;
//今后我们看源码的时候,想都不要想,看新的方式
if (jConf.getUseNewMapper()) {
//===========关键代码============
maps = writeNewSplits(job, jobSubmitDir);
} else {
maps = writeOldSplits(jConf, jobSubmitDir);
}
return maps;
}org.apache.hadoop.mapreduce.JobSubmitter#writeNewSplits
private <T extends InputSplit> int writeNewSplits(JobContext job, Path jobSubmitDir) throws IOException,InterruptedException, ClassNotFoundException {
//获取集群配置
Configuration conf = job.getConfiguration();
//通过反射工具获取文件读取器对象
//===========关键代码============ job 的实现类
//org.apache.hadoop.mapreduce.lib.input.TextInputFormat --> input
//job->org.apache.hadoop.mapreduce.task.JobContextImpl#getInputFormatClass
InputFormat<?, ?> input = ReflectionUtils.newInstance(job.getInputFormatClass(), conf);
//获取到切片
//===========关键代码============ getSplits
List<InputSplit> splits = input.getSplits(job);
//转成数组
T[] array = (T[]) splits.toArray(new InputSplit[splits.size()]);
// sort the splits into order based on size, so that the biggest
// go first
Arrays.sort(array, new SplitComparator());
JobSplitWriter.createSplitFiles(jobSubmitDir, conf,
jobSubmitDir.getFileSystem(conf), array);
//返回的是数组的长度,对应着切片的数量,回到197行验证
return array.length;
}org.apache.hadoop.mapreduce.task.JobContextImpl#getInputFormatClass
/**
* Get the {@link InputFormat} class for the job.
*
* @return the {@link InputFormat} class for the job.
*/
@SuppressWarnings("unchecked")
public Class<? extends InputFormat<?,?>> getInputFormatClass() throws ClassNotFoundException {
return (Class<? extends InputFormat<?,?>>)
//getClass的操作是如果有值返回值,没有的话使用默认值
conf.getClass(INPUT_FORMAT_CLASS_ATTR, TextInputFormat.class);
}org.apache.hadoop.mapreduce.lib.input.FileInputFormat#getSplits
/**
* Generate the list of files and make them into FileSplits.
* @param job the job context
* @throws IOException
*/
public List<InputSplit> getSplits(JobContext job) throws IOException {
StopWatch sw = new StopWatch().start();
//开始计算两个变量(一个切片最少有一个字节,一个最小切片值也是1)
//1
long minSize = Math.max(getFormatMinSplitSize(), getMinSplitSize(job));
//Long.MAX_VALUE
long maxSize = getMaxSplitSize(job);
// generate splits
//创建一个List存放切片
List<InputSplit> splits = new ArrayList<InputSplit>();
//获取本次计算中所有的要计算的文件
List<FileStatus> files = listStatus(job);
//首先取出一个文件
for (FileStatus file: files) {
//获取文件路径
Path path = file.getPath();
//获取文件大小
long length = file.getLen();
if (length != 0) {
BlockLocation[] blkLocations;
if (file instanceof LocatedFileStatus) {
blkLocations = ((LocatedFileStatus) file).getBlockLocations();
} else {
FileSystem fs = path.getFileSystem(job.getConfiguration());
//获取文件块的信息
blkLocations = fs.getFileBlockLocations(file, 0, length);
}
//判断文件是否可以被切分,比如文件被压缩了,需要解压缩才可以
if (isSplitable(job, path)) {
//获取单个块的大小
long blockSize = file.getBlockSize();
//开始计算切片大小,这里可以验证切片大小与block大小一样
//思考如何生成256M的切片
//如果切片小于blocksize-->将maxsize小于blocksize
//如果切片大于blocksize-->将minsize大于blocksize
long splitSize = computeSplitSize(blockSize, minSize, maxSize);
//将文件大小分配给bytesRemaining
long bytesRemaining = length;
//private static final double SPLIT_SLOP = 1.1; // 10% slop
while (((double) bytesRemaining)/splitSize > SPLIT_SLOP) {
int blkIndex = getBlockIndex(blkLocations, length-bytesRemaining);
//制作切片
//封装切片对象并将其存放到list中
//makeSplit(路径,偏移量,切片大小,块的位置,备份的位置);
splits.add(makeSplit(path, length-bytesRemaining, splitSize,
blkLocations[blkIndex].getHosts(),
blkLocations[blkIndex].getCachedHosts()));
bytesRemaining -= splitSize;
}
//如果最后一个文件过小没有大于1.1,就与上一个一起生成切片
if (bytesRemaining != 0) {
int blkIndex = getBlockIndex(blkLocations, length-bytesRemaining);
splits.add(makeSplit(path, length-bytesRemaining, bytesRemaining,
blkLocations[blkIndex].getHosts(),
blkLocations[blkIndex].getCachedHosts()));
}
} else { // not splitable
//如果文件不可切,就生成一个切片
splits.add(makeSplit(path, 0, length, blkLocations[0].getHosts(),
blkLocations[0].getCachedHosts()));
}
} else {
//Create empty hosts array for zero length files
splits.add(makeSplit(path, 0, length, new String[0]));
}
}
// Save the number of input files for metrics/loadgen
job.getConfiguration().setLong(NUM_INPUT_FILES, files.size());
sw.stop();
if (LOG.isDebugEnabled()) {
LOG.debug("Total # of splits generated by getSplits: " + splits.size()
+ ", TimeTaken: " + sw.now(TimeUnit.MILLISECONDS));
}
//返回切片(后面的代码我们跟不进去了,是yarn上面的了)
return splits;
}计算切片大小逻辑
org.apache.hadoop.mapreduce.lib.input.FileInputFormat#computeSplitSize
protected long computeSplitSize(long blockSize, long minSize,
long maxSize) {
//blockSize--128M
//maxSize--56M ----> 56M
//minSize--256M ----> 256M
return Math.max(minSize, Math.min(maxSize, blockSize));
}2.2 Map源码-MapTask
带着问题:
1、map读取数据按照行读取数据?验证一下
2、如果切片把一行数据放在了两个切片中呢?怎么办?
3、map里面的第一个参数类型是LongWritable?哪里指定的?
org.apache.hadoop.mapred.MapTask
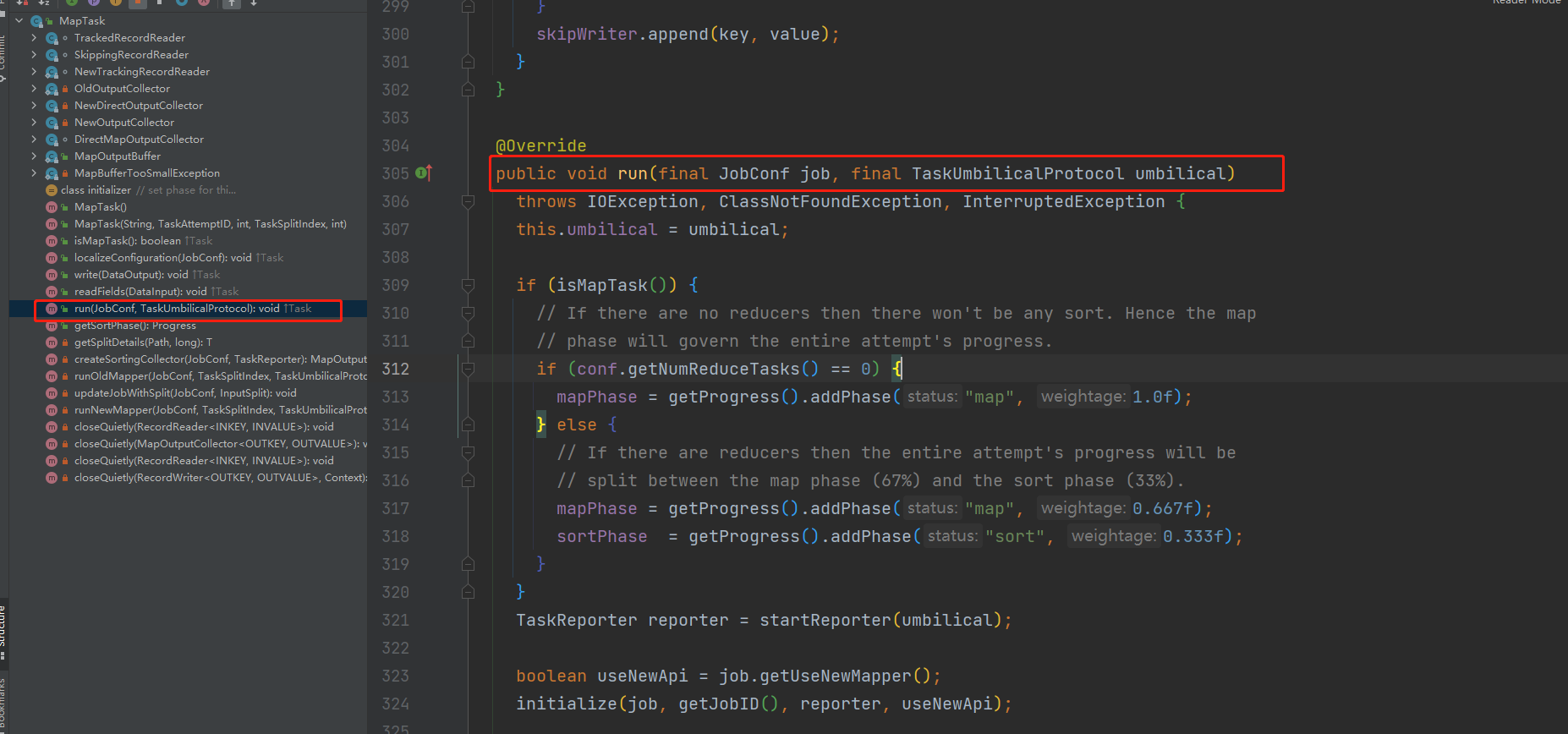
@Override
public void run(final JobConf job, final TaskUmbilicalProtocol umbilical)
throws IOException, ClassNotFoundException, InterruptedException {
this.umbilical = umbilical;
//判断是否为Map任务
if (isMapTask()) {
// If there are no reducers then there won't be any sort. Hence the map
// phase will govern the entire attempt's progress.
//判断reduce数量是否等于0,有可能等于0的如果我们只是清洗数据,就不需要
if (conf.getNumReduceTasks() == 0) {
//map所占的比例100%,没有reducce就不用分区了
mapPhase = getProgress().addPhase("map", 1.0f);
} else {
// If there are reducers then the entire attempt's progress will be
// split between the map phase (67%) and the sort phase (33%).
//如果有reduce的话分区排序
mapPhase = getProgress().addPhase("map", 0.667f);
sortPhase = getProgress().addPhase("sort", 0.333f);
}
}
//任务报告一下,说明我要处理多少数据
TaskReporter reporter = startReporter(umbilical);
//使用新api
boolean useNewApi = job.getUseNewMapper();
//===========关键代码============
//使用新api进行初始化
initialize(job, getJobID(), reporter, useNewApi);
// check if it is a cleanupJobTask
if (jobCleanup) {
runJobCleanupTask(umbilical, reporter);
return;
}
if (jobSetup) {
runJobSetupTask(umbilical, reporter);
return;
}
if (taskCleanup) {
runTaskCleanupTask(umbilical, reporter);
return;
}
if (useNewApi) {
//===========关键代码============
runNewMapper(job, splitMetaInfo, umbilical, reporter);
} else {
runOldMapper(job, splitMetaInfo, umbilical, reporter);
}
done(umbilical, reporter);
}org.apache.hadoop.mapred.Task#initialize
public void initialize(JobConf job, JobID id,
Reporter reporter,
boolean useNewApi) throws IOException,
ClassNotFoundException,
InterruptedException {
//获取作业的上下文
jobContext = new JobContextImpl(job, id, reporter);
//获取任务的上下文
taskContext = new TaskAttemptContextImpl(job, taskId, reporter);
if (getState() == TaskStatus.State.UNASSIGNED) {
setState(TaskStatus.State.RUNNING);
}
if (useNewApi) {
if (LOG.isDebugEnabled()) {
LOG.debug("using new api for output committer");
}
//创建了一个outputFormat对象
outputFormat = ReflectionUtils.newInstance(taskContext.getOutputFormatClass(), job);
committer = outputFormat.getOutputCommitter(taskContext);
} else {
committer = conf.getOutputCommitter();
}
Path outputPath = FileOutputFormat.getOutputPath(conf);
if (outputPath != null) {
if ((committer instanceof FileOutputCommitter)) {
FileOutputFormat.setWorkOutputPath(conf,
((FileOutputCommitter)committer).getTaskAttemptPath(taskContext));
} else {
FileOutputFormat.setWorkOutputPath(conf, outputPath);
}
}
committer.setupTask(taskContext);
Class<? extends ResourceCalculatorProcessTree> clazz =
conf.getClass(MRConfig.RESOURCE_CALCULATOR_PROCESS_TREE,
null, ResourceCalculatorProcessTree.class);
pTree = ResourceCalculatorProcessTree
.getResourceCalculatorProcessTree(System.getenv().get("JVM_PID"), clazz, conf);
LOG.info(" Using ResourceCalculatorProcessTree : " + pTree);
if (pTree != null) {
pTree.updateProcessTree();
initCpuCumulativeTime = pTree.getCumulativeCpuTime();
}
}org.apache.hadoop.mapred.MapTask#runNewMapper
@SuppressWarnings("unchecked")
private <INKEY,INVALUE,OUTKEY,OUTVALUE>
void runNewMapper(final JobConf job,
final TaskSplitIndex splitIndex,
final TaskUmbilicalProtocol umbilical,
TaskReporter reporter
) throws IOException, ClassNotFoundException,
InterruptedException {
// make a task context so we can get the classes
org.apache.hadoop.mapreduce.TaskAttemptContext taskContext =
new org.apache.hadoop.mapreduce.task.TaskAttemptContextImpl(job,
getTaskID(),
reporter);
// make a mapper--com.shujia.MyMapper
//对应自己写的map类 TaskAttemptContextImpl
org.apache.hadoop.mapreduce.Mapper<INKEY,INVALUE,OUTKEY,OUTVALUE> mapper =
(org.apache.hadoop.mapreduce.Mapper<INKEY,INVALUE,OUTKEY,OUTVALUE>)
ReflectionUtils.newInstance(taskContext.getMapperClass(), job);
// make the input format
//org.apache.hadoop.mapreduce.lib.input.TextInputFormat
org.apache.hadoop.mapreduce.InputFormat<INKEY,INVALUE> inputFormat =
(org.apache.hadoop.mapreduce.InputFormat<INKEY,INVALUE>)
ReflectionUtils.newInstance(taskContext.getInputFormatClass(), job);
// rebuild the input split
//获取切片
org.apache.hadoop.mapreduce.InputSplit split = null;
split = getSplitDetails(new Path(splitIndex.getSplitLocation()),
splitIndex.getStartOffset());
LOG.info("Processing split: " + split);
//===========关键代码============ NewTrackingRecordReader
org.apache.hadoop.mapreduce.RecordReader<INKEY,INVALUE> input =
new NewTrackingRecordReader<INKEY,INVALUE>
(split, inputFormat, reporter, taskContext);
job.setBoolean(JobContext.SKIP_RECORDS, isSkipping());
org.apache.hadoop.mapreduce.RecordWriter output = null;
// get an output object
if (job.getNumReduceTasks() == 0) {
//如果reduce数量等于0,直接输出
output =
new NewDirectOutputCollector(taskContext, job, umbilical, reporter);
} else {
//如果reduce数量不等于0,待会来看,看下面的初始化
output = new NewOutputCollector(taskContext, job, umbilical, reporter);
}
org.apache.hadoop.mapreduce.MapContext<INKEY, INVALUE, OUTKEY, OUTVALUE>
mapContext =
new MapContextImpl<INKEY, INVALUE, OUTKEY, OUTVALUE>(job, getTaskID(),
input, output,
committer,
reporter, split);
org.apache.hadoop.mapreduce.Mapper<INKEY,INVALUE,OUTKEY,OUTVALUE>.Context
mapperContext =
new WrappedMapper<INKEY, INVALUE, OUTKEY, OUTVALUE>().getMapContext(
mapContext);
try {
//===========关键代码============
//初始化的时候有意识的将第一行省略了
input.initialize(split, mapperContext);
//实际上调用的就是我们自己重写的map方法
//===========关键代码============
mapper.run(mapperContext);
mapPhase.complete();
setPhase(TaskStatus.Phase.SORT);
statusUpdate(umbilical);
input.close();
input = null;
output.close(mapperContext);
output = null;
} finally {
closeQuietly(input);
closeQuietly(output, mapperContext);
}
}org.apache.hadoop.mapred.MapTask.NewTrackingRecordReader#NewTrackingRecordReader
NewTrackingRecordReader(org.apache.hadoop.mapreduce.InputSplit split,
org.apache.hadoop.mapreduce.InputFormat<K, V> inputFormat,
TaskReporter reporter,
org.apache.hadoop.mapreduce.TaskAttemptContext taskContext)
throws InterruptedException, IOException {
this.reporter = reporter;
this.inputRecordCounter = reporter
.getCounter(TaskCounter.MAP_INPUT_RECORDS);
this.fileInputByteCounter = reporter
.getCounter(FileInputFormatCounter.BYTES_READ);
List <Statistics> matchedStats = null;
if (split instanceof org.apache.hadoop.mapreduce.lib.input.FileSplit) {
matchedStats = getFsStatistics(((org.apache.hadoop.mapreduce.lib.input.FileSplit) split)
.getPath(), taskContext.getConfiguration());
}
fsStats = matchedStats;
long bytesInPrev = getInputBytes(fsStats);
//===========关键代码============
//真正工作的人是谁,创建一个记录读取器
//返回的是一个行记录读取器
this.real = inputFormat.createRecordReader(split, taskContext);
long bytesInCurr = getInputBytes(fsStats);
fileInputByteCounter.increment(bytesInCurr - bytesInPrev);
}org.apache.hadoop.mapreduce.RecordReader
@Override
public RecordReader<LongWritable, Text>
createRecordReader(InputSplit split,
TaskAttemptContext context) {
String delimiter = context.getConfiguration().get(
"textinputformat.record.delimiter");
byte[] recordDelimiterBytes = null;
if (null != delimiter)
recordDelimiterBytes = delimiter.getBytes(Charsets.UTF_8);
return new LineRecordReader(recordDelimiterBytes);
}org.apache.hadoop.mapreduce.lib.input.LineRecordReader#initialize
public void initialize(InputSplit genericSplit,
TaskAttemptContext context) throws IOException {
FileSplit split = (FileSplit) genericSplit;
Configuration job = context.getConfiguration();
this.maxLineLength = job.getInt(MAX_LINE_LENGTH, Integer.MAX_VALUE);
//获取开始的位置
start = split.getStart();
end = start + split.getLength();
final Path file = split.getPath();
// open the file and seek to the start of the split
//获取分布式文件系统
final FileSystem fs = file.getFileSystem(job);
//获取一个输入流
fileIn = fs.open(file);
CompressionCodec codec = new CompressionCodecFactory(job).getCodec(file);
if (null!=codec) {
isCompressedInput = true;
decompressor = CodecPool.getDecompressor(codec);
if (codec instanceof SplittableCompressionCodec) {
final SplitCompressionInputStream cIn =
((SplittableCompressionCodec)codec).createInputStream(
fileIn, decompressor, start, end,
SplittableCompressionCodec.READ_MODE.BYBLOCK);
in = new CompressedSplitLineReader(cIn, job,
this.recordDelimiterBytes);
start = cIn.getAdjustedStart();
end = cIn.getAdjustedEnd();
filePosition = cIn;
} else {
in = new SplitLineReader(codec.createInputStream(fileIn,
decompressor), job, this.recordDelimiterBytes);
filePosition = fileIn;
}
} else {
//读取偏移量
fileIn.seek(start);
in = new UncompressedSplitLineReader(
fileIn, job, this.recordDelimiterBytes, split.getLength());
filePosition = fileIn;
}
// If this is not the first split, we always throw away first record
// because we always (except the last split) read one extra line in
// next() method.
//解决第二个问题 从第二行开始读,把切片的第一行将给上一个切片去读
if (start != 0) {
//返回的start正好是下一行数据的开头
start += in.readLine(new Text(), 0, maxBytesToConsume(start));
}
this.pos = start;
}org.apache.hadoop.mapreduce.lib.map.WrappedMapper
@Override
public boolean nextKeyValue() throws IOException, InterruptedException {
return mapContext.nextKeyValue();
}org.apache.hadoop.mapreduce.task.MapContextImpl#MapContextImpl
@Override
public boolean nextKeyValue() throws IOException, InterruptedException {
//最终调用的是LineRecordReader中的nextKeyValue方法
return reader.nextKeyValue();
}org.apache.hadoop.mapreduce.lib.input.LineRecordReader
public boolean nextKeyValue() throws IOException {
if (key == null) {
key = new LongWritable();
}
//设置当前的偏移量
key.set(pos);
if (value == null) {
value = new Text();
}
int newSize = 0;
// We always read one extra line, which lies outside the upper
// split limit i.e. (end - 1)
//循环读取数据
while (getFilePosition() <= end || in.needAdditionalRecordAfterSplit()) {
if (pos == 0) {
newSize = skipUtfByteOrderMark();
} else {
//pos是当前数据的定位,value是数据
newSize = in.readLine(value, maxLineLength, maxBytesToConsume(pos));
pos += newSize;
}
if ((newSize == 0) || (newSize < maxLineLength)) {
break;
}
// line too long. try again
LOG.info("Skipped line of size " + newSize + " at pos " +
(pos - newSize));
}
if (newSize == 0) {
//如果本次啥也没有读到,返回false
key = null;
value = null;
return false;
} else {
//读到了返回true
return true;
}
}
//看完这里回到map方法,key就是数据的偏移量,value就是一行数据,context上下文,写到环形缓冲区,map结束2.3 KV-Buffer
通过context中的write方法进行写
带着问题:
1、分区的数量和reduce数量一样?
2、环形缓冲区内存大小100M?80%溢写?可以自己设置吗?
3、排序是快速排序?
4、怎么分区的?Hash?
org.apache.hadoop.mapreduce.task.TaskInputOutputContextImpl
/**
* Generate an output key/value pair.
*/
public void write(KEYOUT key, VALUEOUT value
) throws IOException, InterruptedException {
output.write(key, value);
}通过参数的个数
org.apache.hadoop.mapred.MapTask.NewOutputCollector#NewOutputCollector
@SuppressWarnings("unchecked")
NewOutputCollector(org.apache.hadoop.mapreduce.JobContext jobContext,
JobConf job,
TaskUmbilicalProtocol umbilical,
TaskReporter reporter
) throws IOException, ClassNotFoundException {
//========关键代码=============
collector = createSortingCollector(job, reporter);
partitions = jobContext.getNumReduceTasks();
if (partitions > 1) {
//========关键代码============= 分区器
partitioner = (org.apache.hadoop.mapreduce.Partitioner<K,V>)
ReflectionUtils.newInstance(jobContext.getPartitionerClass(), job);
} else {
partitioner = new org.apache.hadoop.mapreduce.Partitioner<K,V>() {
@Override
public int getPartition(K key, V value, int numPartitions) {
return partitions - 1;
}
};
}
}org.apache.hadoop.mapred.MapTask#createSortingCollector
private <KEY, VALUE> MapOutputCollector<KEY, VALUE>
createSortingCollector(JobConf job, TaskReporter reporter)
throws IOException, ClassNotFoundException {
MapOutputCollector.Context context =
new MapOutputCollector.Context(this, job, reporter);
//========关键代码==========
Class<?>[] collectorClasses = job.getClasses(
JobContext.MAP_OUTPUT_COLLECTOR_CLASS_ATTR, MapOutputBuffer.class);
int remainingCollectors = collectorClasses.length;
Exception lastException = null;
for (Class clazz : collectorClasses) {
try {
if (!MapOutputCollector.class.isAssignableFrom(clazz)) {
throw new IOException("Invalid output collector class: " + clazz.getName() +
" (does not implement MapOutputCollector)");
}
Class<? extends MapOutputCollector> subclazz =
clazz.asSubclass(MapOutputCollector.class);
LOG.debug("Trying map output collector class: " + subclazz.getName());
MapOutputCollector<KEY, VALUE> collector =
ReflectionUtils.newInstance(subclazz, job);
//====================进行初始化===============
collector.init(context);
LOG.info("Map output collector class = " + collector.getClass().getName());
//返回MapOutputBuffer
return collector;
} catch (Exception e) {
String msg = "Unable to initialize MapOutputCollector " + clazz.getName();
if (--remainingCollectors > 0) {
msg += " (" + remainingCollectors + " more collector(s) to try)";
}
lastException = e;
LOG.warn(msg, e);
}
}
throw new IOException("Initialization of all the collectors failed. " +
"Error in last collector was :" + lastException.getMessage(), lastException);
}org.apache.hadoop.mapred.MapTask.MapOutputBuffer#init
public void init(MapOutputCollector.Context context
) throws IOException, ClassNotFoundException {
job = context.getJobConf();
reporter = context.getReporter();
mapTask = context.getMapTask();
mapOutputFile = mapTask.getMapOutputFile();
sortPhase = mapTask.getSortPhase();
spilledRecordsCounter = reporter.getCounter(TaskCounter.SPILLED_RECORDS);
partitions = job.getNumReduceTasks();
rfs = ((LocalFileSystem)FileSystem.getLocal(job)).getRaw();
//sanity checks
//溢写
final float spillper =
job.getFloat(JobContext.MAP_SORT_SPILL_PERCENT, (float)0.8);
final int sortmb = job.getInt(JobContext.IO_SORT_MB, 100);
indexCacheMemoryLimit = job.getInt(JobContext.INDEX_CACHE_MEMORY_LIMIT,
INDEX_CACHE_MEMORY_LIMIT_DEFAULT);
if (spillper > (float)1.0 || spillper <= (float)0.0) {
throw new IOException("Invalid \"" + JobContext.MAP_SORT_SPILL_PERCENT +
"\": " + spillper);
}
if ((sortmb & 0x7FF) != sortmb) {
throw new IOException(
"Invalid \"" + JobContext.IO_SORT_MB + "\": " + sortmb);
}
//默认排序器是快速排序
sorter = ReflectionUtils.newInstance(job.getClass("map.sort.class",
QuickSort.class, IndexedSorter.class), job);
// buffers and accounting
//100左移2位 ×2^20
int maxMemUsage = sortmb << 20;
//对16进行取余,让这个数字变成16的整数倍
maxMemUsage -= maxMemUsage % METASIZE;
//环形缓冲区100M
//并且设置环形缓冲区的一些初始值
kvbuffer = new byte[maxMemUsage];
bufvoid = kvbuffer.length;
kvmeta = ByteBuffer.wrap(kvbuffer)
.order(ByteOrder.nativeOrder())
.asIntBuffer();
setEquator(0);
bufstart = bufend = bufindex = equator;
kvstart = kvend = kvindex;
//双重索引,大家课下可以自己了解
maxRec = kvmeta.capacity() / NMETA;
softLimit = (int)(kvbuffer.length * spillper);
bufferRemaining = softLimit;
LOG.info(JobContext.IO_SORT_MB + ": " + sortmb);
LOG.info("soft limit at " + softLimit);
LOG.info("bufstart = " + bufstart + "; bufvoid = " + bufvoid);
LOG.info("kvstart = " + kvstart + "; length = " + maxRec);
// k/v serialization
//如果是自己自定义的类型,需要自定义排序器
comparator = job.getOutputKeyComparator();
keyClass = (Class<K>)job.getMapOutputKeyClass();
valClass = (Class<V>)job.getMapOutputValueClass();
//
serializationFactory = new SerializationFactory(job);
keySerializer = serializationFactory.getSerializer(keyClass);
keySerializer.open(bb);
valSerializer = serializationFactory.getSerializer(valClass);
valSerializer.open(bb);
// output counters
mapOutputByteCounter = reporter.getCounter(TaskCounter.MAP_OUTPUT_BYTES);
mapOutputRecordCounter =
reporter.getCounter(TaskCounter.MAP_OUTPUT_RECORDS);
fileOutputByteCounter = reporter
.getCounter(TaskCounter.MAP_OUTPUT_MATERIALIZED_BYTES);
// compression
if (job.getCompressMapOutput()) {
Class<? extends CompressionCodec> codecClass =
job.getMapOutputCompressorClass(DefaultCodec.class);
codec = ReflectionUtils.newInstance(codecClass, job);
} else {
codec = null;
}
// combiner
final Counters.Counter combineInputCounter =
reporter.getCounter(TaskCounter.COMBINE_INPUT_RECORDS);
combinerRunner = CombinerRunner.create(job, getTaskID(),
combineInputCounter,
reporter, null);
if (combinerRunner != null) {
final Counters.Counter combineOutputCounter =
reporter.getCounter(TaskCounter.COMBINE_OUTPUT_RECORDS);
combineCollector= new CombineOutputCollector<K,V>(combineOutputCounter, reporter, job);
} else {
combineCollector = null;
}
spillInProgress = false;
minSpillsForCombine = job.getInt(JobContext.MAP_COMBINE_MIN_SPILLS, 3);
spillThread.setDaemon(true);
spillThread.setName("SpillThread");
spillLock.lock();
try {
spillThread.start();
while (!spillThreadRunning) {
spillDone.await();
}
} catch (InterruptedException e) {
throw new IOException("Spill thread failed to initialize", e);
} finally {
spillLock.unlock();
}
if (sortSpillException != null) {
throw new IOException("Spill thread failed to initialize",
sortSpillException);
}
}org.apache.hadoop.mapreduce.task.JobContextImpl#getPartitionerClass 默认是hash分区
@SuppressWarnings("unchecked")
public Class<? extends Partitioner<?,?>> getPartitionerClass()
throws ClassNotFoundException {
return (Class<? extends Partitioner<?,?>>)
conf.getClass(PARTITIONER_CLASS_ATTR, HashPartitioner.class);
}org.apache.hadoop.mapreduce.lib.partition.HashPartitioner
public class HashPartitioner<K, V> extends Partitioner<K, V> {
/** Use {@link Object#hashCode()} to partition. */
public int getPartition(K key, V value,
int numReduceTasks) {
return (key.hashCode() & Integer.MAX_VALUE) % numReduceTasks;
}
}output-->NewOutputCollector--->write
@Override
public void write(K key, V value) throws IOException, InterruptedException {
collector.collect(key, value,
partitioner.getPartition(key, value, partitions));
}MapOutputBuffer
/**
* Serialize the key, value to intermediate storage.
* When this method returns, kvindex must refer to sufficient unused
* storage to store one METADATA.
*/
public synchronized void collect(K key, V value, final int partition
) throws IOException {
reporter.progress();
if (key.getClass() != keyClass) {
throw new IOException("Type mismatch in key from map: expected "
+ keyClass.getName() + ", received "
+ key.getClass().getName());
}
if (value.getClass() != valClass) {
throw new IOException("Type mismatch in value from map: expected "
+ valClass.getName() + ", received "
+ value.getClass().getName());
}
if (partition < 0 || partition >= partitions) {
throw new IOException("Illegal partition for " + key + " (" +
partition + ")");
}
checkSpillException();
bufferRemaining -= METASIZE;
if (bufferRemaining <= 0) {
// start spill if the thread is not running and the soft limit has been
// reached
spillLock.lock();
try {
do {
if (!spillInProgress) {
final int kvbidx = 4 * kvindex;
final int kvbend = 4 * kvend;
// serialized, unspilled bytes always lie between kvindex and
// bufindex, crossing the equator. Note that any void space
// created by a reset must be included in "used" bytes
final int bUsed = distanceTo(kvbidx, bufindex);
final boolean bufsoftlimit = bUsed >= softLimit;
if ((kvbend + METASIZE) % kvbuffer.length !=
equator - (equator % METASIZE)) {
// spill finished, reclaim space
resetSpill();
bufferRemaining = Math.min(
distanceTo(bufindex, kvbidx) - 2 * METASIZE,
softLimit - bUsed) - METASIZE;
continue;
} else if (bufsoftlimit && kvindex != kvend) {
// spill records, if any collected; check latter, as it may
// be possible for metadata alignment to hit spill pcnt
//====开始溢写====================
startSpill();
final int avgRec = (int)
(mapOutputByteCounter.getCounter() /
mapOutputRecordCounter.getCounter());
// leave at least half the split buffer for serialization data
// ensure that kvindex >= bufindex
final int distkvi = distanceTo(bufindex, kvbidx);
final int newPos = (bufindex +
Math.max(2 * METASIZE - 1,
Math.min(distkvi / 2,
distkvi / (METASIZE + avgRec) * METASIZE)))
% kvbuffer.length;
setEquator(newPos);
bufmark = bufindex = newPos;
final int serBound = 4 * kvend;
// bytes remaining before the lock must be held and limits
// checked is the minimum of three arcs: the metadata space, the
// serialization space, and the soft limit
bufferRemaining = Math.min(
// metadata max
distanceTo(bufend, newPos),
Math.min(
// serialization max
distanceTo(newPos, serBound),
// soft limit
softLimit)) - 2 * METASIZE;
}
}
} while (false);
} finally {
spillLock.unlock();
}
}2.4 溢写Spill
output--->NewOutputCollector
@Override
public void close(TaskAttemptContext context
) throws IOException,InterruptedException {
try {
//===============关键代码===============
collector.flush();
} catch (ClassNotFoundException cnf) {
throw new IOException("can't find class ", cnf);
}
collector.close();
}
}collector--->MapOutputBuffer
public void flush() throws IOException, ClassNotFoundException,
InterruptedException {
LOG.info("Starting flush of map output");
if (kvbuffer == null) {
LOG.info("kvbuffer is null. Skipping flush.");
return;
}
spillLock.lock();
try {
while (spillInProgress) {
reporter.progress();
spillDone.await();
}
checkSpillException();
final int kvbend = 4 * kvend;
if ((kvbend + METASIZE) % kvbuffer.length !=
equator - (equator % METASIZE)) {
// spill finished
resetSpill();
}
if (kvindex != kvend) {
kvend = (kvindex + NMETA) % kvmeta.capacity();
bufend = bufmark;
LOG.info("Spilling map output");
LOG.info("bufstart = " + bufstart + "; bufend = " + bufmark +
"; bufvoid = " + bufvoid);
LOG.info("kvstart = " + kvstart + "(" + (kvstart * 4) +
"); kvend = " + kvend + "(" + (kvend * 4) +
"); length = " + (distanceTo(kvend, kvstart,
kvmeta.capacity()) + 1) + "/" + maxRec);
sortAndSpill();
}
} catch (InterruptedException e) {
throw new IOException("Interrupted while waiting for the writer", e);
} finally {
spillLock.unlock();
}
assert !spillLock.isHeldByCurrentThread();
// shut down spill thread and wait for it to exit. Since the preceding
// ensures that it is finished with its work (and sortAndSpill did not
// throw), we elect to use an interrupt instead of setting a flag.
// Spilling simultaneously from this thread while the spill thread
// finishes its work might be both a useful way to extend this and also
// sufficient motivation for the latter approach.
try {
spillThread.interrupt();
spillThread.join();
} catch (InterruptedException e) {
throw new IOException("Spill failed", e);
}
// release sort buffer before the merge
kvbuffer = null;
//当最后一个数据写出后,开始对溢写的小文件进行合并
mergeParts();
Path outputPath = mapOutputFile.getOutputFile();
fileOutputByteCounter.increment(rfs.getFileStatus(outputPath).getLen());
}(1)Read阶段:MapTask通过InputFormat获得的RecordReader,从输入InputSplit中解析出一个个key/value。 (2)Map阶段:该节点主要是将解析出的key/value交给用户编写map()函数处理,并产生一系列新的key/value。 (3)Collect收集阶段:在用户编写map()函数中,当数据处理完成后,一般会调用OutputCollector.collect()输出结果。在该函数内部,它会将生成的key/value分区(调用Partitioner),并写入一个环形内存缓冲区中。 (4)Spill阶段:即“溢写”,当环形缓冲区满后,MapReduce会将数据写到本地磁盘上,生成一个临时文件。需要注意的是,将数据写入本地磁盘之前,先要对数据进行一次本地排序,并在必要时对数据进行合并、压缩等操作。 溢写阶段详情: 步骤1:利用快速排序算法对缓存区内的数据进行排序,排序方式是,先按照分区编号Partition进行排序,然后按照key进行排序。这样,经过排序后,数据以分区为单位聚集在一起,且同一分区内所有数据按照key有序。 步骤2:按照分区编号由小到大依次将每个分区中的数据写入任务工作目录下的临时文件output/spillN.out(N表示当前溢写次数)中。如果用户设置了Combiner,则写入文件之前,对每个分区中的数据进行一次聚集操作。 步骤3:将分区数据的元信息写到内存索引数据结构SpillRecord中,其中每个分区的元信息包括在临时文件中的偏移量、压缩前数据大小和压缩后数据大小。如果当前内存索引大小超过1MB,则将内存索引写到文件output/spillN.out.index中。 (5)Merge阶段:当所有数据处理完成后,MapTask对所有临时文件进行一次合并,以确保最终只会生成一个数据文件。 当所有数据处理完后,MapTask会将所有临时文件合并成一个大文件,并保存到文件output/file.out中,同时生成相应的索引文件output/file.out.index。 在进行文件合并过程中,MapTask以分区为单位进行合并。对于某个分区,它将采用多轮递归合并的方式。每轮合并mapreduce.task.io.sort.factor(默认10)个文件,并将产生的文件重新加入待合并列表中,对文件排序后,重复以上过程,直到最终得到一个大文件。
让每个MapTask最终只生成一个数据文件,可避免同时打开大量文件和同时读取大量小文件产生的随机读取带来的开销。
Reduce
run方法
@Override
@SuppressWarnings("unchecked")
public void run(JobConf job, final TaskUmbilicalProtocol umbilical)
throws IOException, InterruptedException, ClassNotFoundException {
job.setBoolean(JobContext.SKIP_RECORDS, isSkipping());
//reduce的三个阶段
if (isMapOrReduce()) {
copyPhase = getProgress().addPhase("copy");
sortPhase = getProgress().addPhase("sort");
reducePhase = getProgress().addPhase("reduce");
}
// start thread that will handle communication with parent
TaskReporter reporter = startReporter(umbilical);
boolean useNewApi = job.getUseNewReducer();
//初始化信息
initialize(job, getJobID(), reporter, useNewApi);
// check if it is a cleanupJobTask
if (jobCleanup) {
runJobCleanupTask(umbilical, reporter);
return;
}
if (jobSetup) {
runJobSetupTask(umbilical, reporter);
return;
}
if (taskCleanup) {
runTaskCleanupTask(umbilical, reporter);
return;
}
// Initialize the codec
codec = initCodec();
RawKeyValueIterator rIter = null;
ShuffleConsumerPlugin shuffleConsumerPlugin = null;
Class combinerClass = conf.getCombinerClass();
CombineOutputCollector combineCollector =
(null != combinerClass) ?
new CombineOutputCollector(reduceCombineOutputCounter, reporter, conf) : null;
Class<? extends ShuffleConsumerPlugin> clazz =
job.getClass(MRConfig.SHUFFLE_CONSUMER_PLUGIN, Shuffle.class, ShuffleConsumerPlugin.class);
shuffleConsumerPlugin = ReflectionUtils.newInstance(clazz, job);
LOG.info("Using ShuffleConsumerPlugin: " + shuffleConsumerPlugin);
ShuffleConsumerPlugin.Context shuffleContext =
new ShuffleConsumerPlugin.Context(getTaskID(), job, FileSystem.getLocal(job), umbilical,
super.lDirAlloc, reporter, codec,
combinerClass, combineCollector,
spilledRecordsCounter, reduceCombineInputCounter,
shuffledMapsCounter,
reduceShuffleBytes, failedShuffleCounter,
mergedMapOutputsCounter,
taskStatus, copyPhase, sortPhase, this,
mapOutputFile, localMapFiles);
//=================关键代码=========================
shuffleConsumerPlugin.init(shuffleContext);
rIter = shuffleConsumerPlugin.run();
// free up the data structures
mapOutputFilesOnDisk.clear();
sortPhase.complete(); // sort is complete
setPhase(TaskStatus.Phase.REDUCE);
statusUpdate(umbilical);
Class keyClass = job.getMapOutputKeyClass();
Class valueClass = job.getMapOutputValueClass();
RawComparator comparator = job.getOutputValueGroupingComparator();
if (useNewApi) {
runNewReducer(job, umbilical, reporter, rIter, comparator,
keyClass, valueClass);
} else {
runOldReducer(job, umbilical, reporter, rIter, comparator,
keyClass, valueClass);
}
shuffleConsumerPlugin.close();
done(umbilical, reporter);
}

【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· winform 绘制太阳,地球,月球 运作规律
· AI与.NET技术实操系列(五):向量存储与相似性搜索在 .NET 中的实现
· 超详细:普通电脑也行Windows部署deepseek R1训练数据并当服务器共享给他人
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 上周热点回顾(3.3-3.9)