
C语言II博客作业01
1.作业头
| 这个作业属于哪个课程 | https://edu.cnblogs.com/campus/zswxy/SE2020-2/ |
|---|---|
| 这个作业要求在哪里 | https://edu.cnblogs.com/campus/zswxy/SE2020-2/homework/11769 |
| 这个作业的目标 | <学会测试数据和改进代码,还有学会文件调用> |
| 学号 | <20209130> |
一、本周教学内容&目标
第6章 回顾数据类型和表达式,第12章 文件
二、本周作业(总分:50分)
2.1 题目:给定一个十进制正整数N,写下从1开始,到N的所有整数,然后数一下其中出现的所有“1”的个数。
例如:
N=2,写下1,2。这样只出现了1个”1“。
N=12,我们会写下1,2,3,4,5,6,7,8,9,10,11,12。这样,1的个数是5。
问题是:
1.写出一个函数f(N),返回1到N之间出现的”1“的个数,比如f(12)=5;
2.满足条件”f(N)=N“的最大的N是多少?
要求:
1.贴出代码图片,写出解题思路,列出测试数据(5分)
代码图片
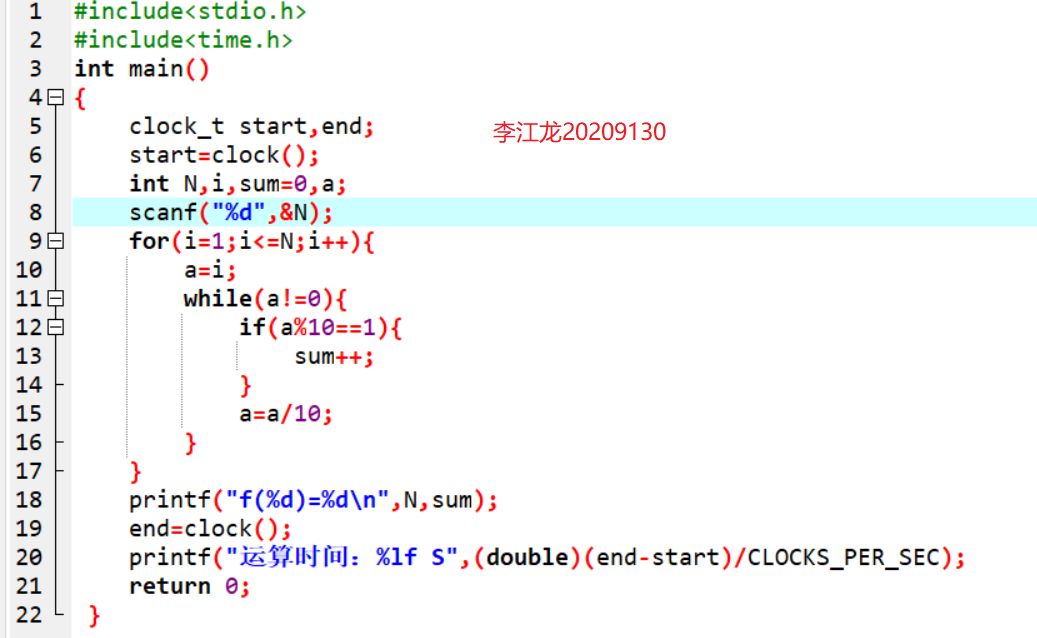
解题思路
首先,是要得到从1到N的所有整数,所以一开始就利用for循环来作为计数器得到1到N之间的所有整数,再然后题目要求算出1到N之间所有整数里的“1”的个数,首先想到利用分支结构进行判断,但使用后还不能得到答案,之后又可以想到把计数器所得到的数的位数拆分,逐个判断是否为“1”,所以由此可以想到再次使用循环进行拆分,最后代码就可以得到最终答案了。
2.给出不同测试数据的运算时间,如果你的运算时间不变,说明你的测试数据不够大(5分)
| 测试数据 | 运算结果 | 运算时间 |
|---|---|---|
| 1 | 1 | 0.419000s |
| 9 | 1 | 0.876000s |
| 999 | 300 | 1.611000s |
| 99999 | 50000 | 2.15000s |
| 9999999 | 7000000 | 3.402000s |
| 999999999 | 900000000 | 33.368000s |
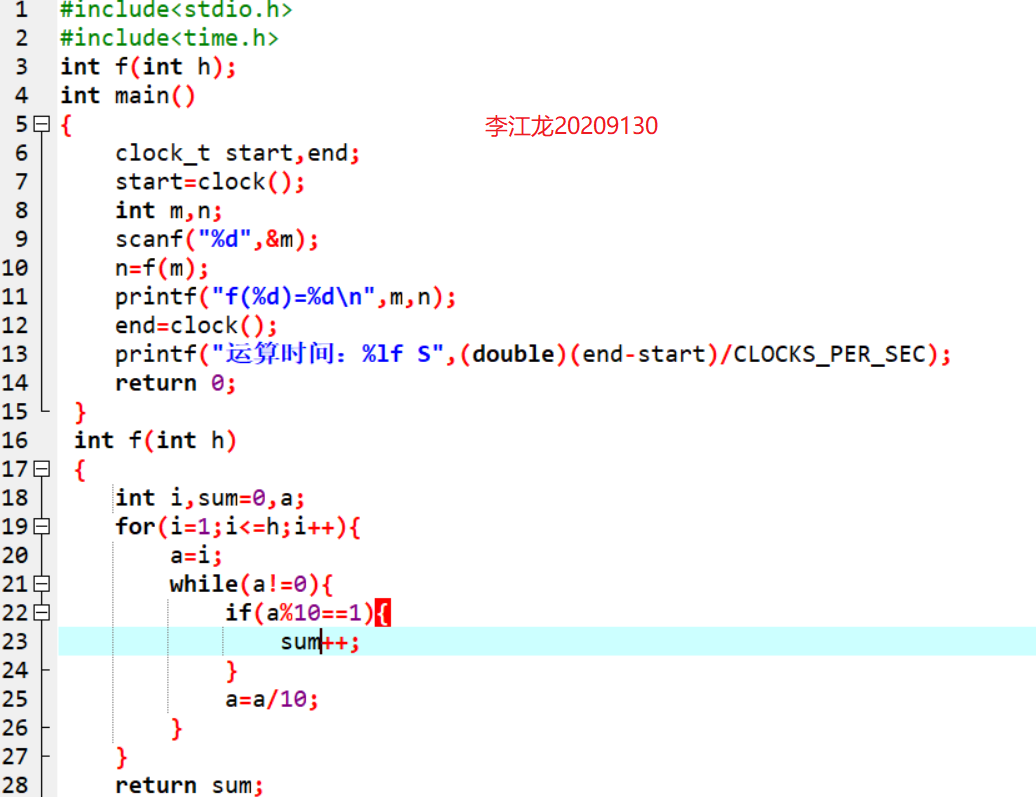
3.思考针对足够大的数据,如何减少运算时间,并给出在原有算法基础上的改进算法和改进思路。(10分)
为了减少运算时间可以尽量减少定义变量,优化算法,尽可能的进行简化,应该就可以减少运算时间。改进就是不进行循环的嵌套,而是把里面的循环单独放开,作为一个函数进行调用,应该在数据大的时候就可以减少运算时间。
改进的算法如下
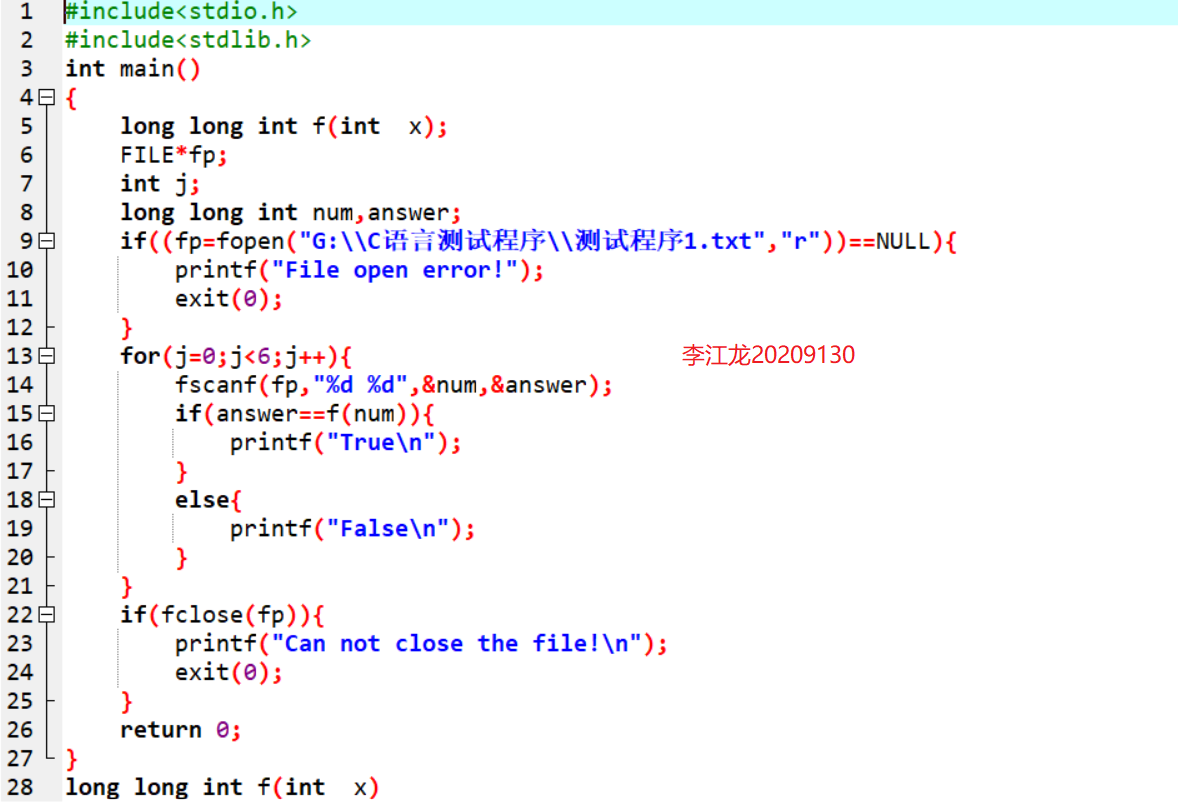
2.2 将上题中多组测试数据写入文件,并给出测试程序以检测你的代码有没有问题,贴出你的代码、运行结果和文件内容。(5分)
代码

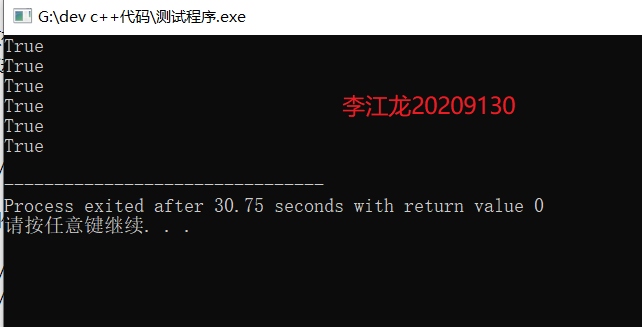
运行结果
文件内容

2.3 用自己的语言回答两个问题,并给出所查阅资料的引用(10分)
1.什么是文件缓冲系统?工作原理如何?
文件缓冲系统:它是系统专门为正在使用的文件开辟的区域,正在使用的文件的存取一般都在这个区域,大小一般为512B,可以更好的提升效率。
工作原理:从磁盘向内存读数据时会先从磁盘文件取数据送到缓冲区,在送到内存,从内存向磁盘写数据时也是一样,会中间经过缓冲区,而且输送数据时是一批批进行,而不是进行一次输入或输出就访问一次磁盘。
缓冲文件系统和非缓冲文件系统
2.什么是文本文件和二进制文件?
文本文件:存入文件的编码是以字符方式写入文件的,那么这个文件就是文本文件。
二进制文件:存入文件的编码是以二进制接口方式写入文件的,那么这个文件就是二进制文件。
文本文件和二进制文件主要是windows下的概念,UNIX/Linux并没有区分这两种文件。
文本文件与二进制文件
2.4 请给出本周学习总结(15分)
1 学习进度条(5分)
| 周/日期 | 这周所花的时间 | 代码行 | 学到的知识点简介 | 目前比较迷惑的问题 |
|---|---|---|---|---|
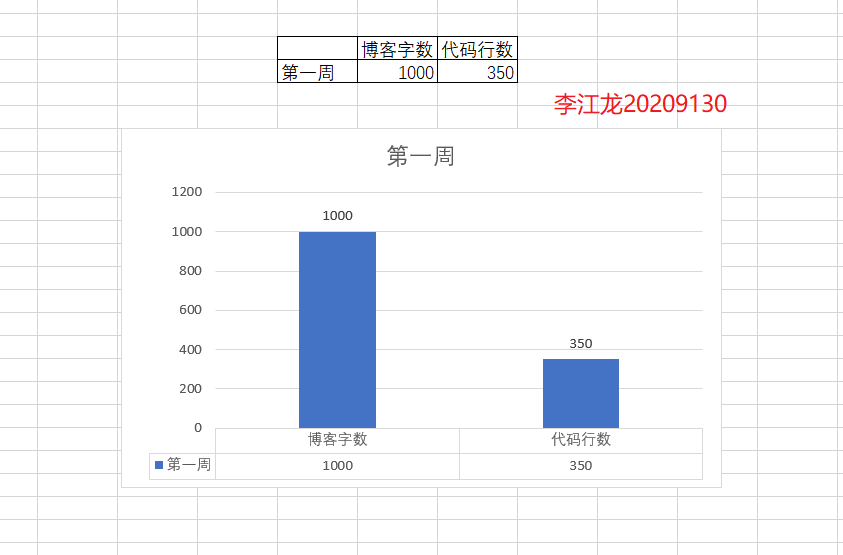
| 第一周 | 30h | 350 | 文件的概念,文件的基本调用,测试数据 | 对测试程序还不怎么熟 |
2 累积代码行和博客字数(5分)
3 学习内容总结和感悟(5分)
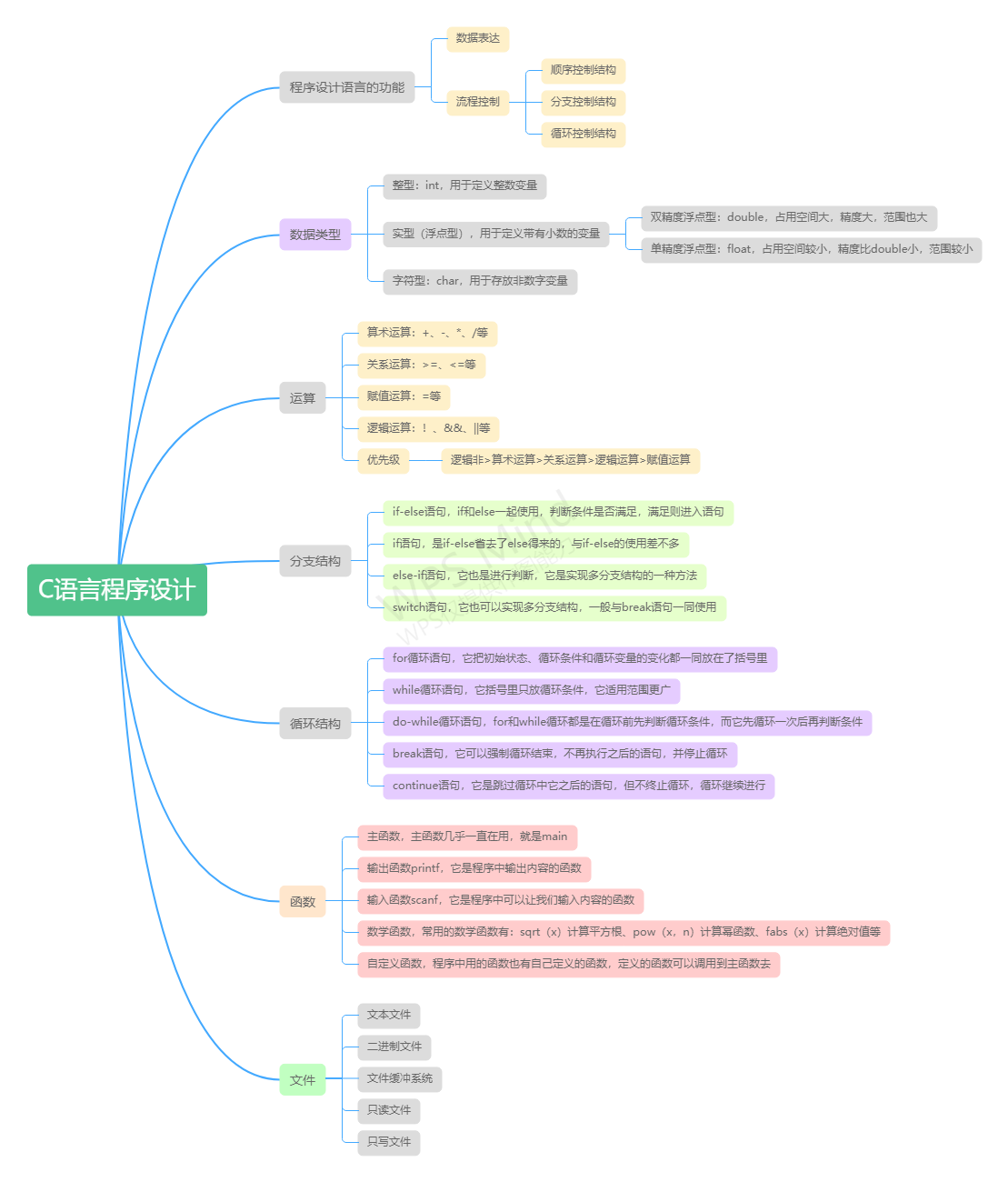
学习内容总结
感悟
1、一个寒假回来,还是忘了很多东西,虽说基本的知识点还记得,但如何灵活运用这些知识点就有点跟不上了,现在要尽快找回上个学期那个状态。
2、这个学期开学的学习总的来说还是效率低了些,开始越来越懒了,拖延症感觉已经到晚期了,还是不能这样,下一周一定要克服这个缺点。
3、有一点点好的地方就是对于函数的调用熟练了一些,上个学期我对于函数就是很不熟练,现在开始熟悉函数的使用了。
4、希望下周好的地方能够继承,坏的地方能够摈弃,然后慢慢提升自己,让自己回归甚至超越上个学期的状态,继续加油!!!!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号