【转载】线段树详解
一:综述
二:原理
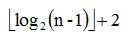 (n>1)。
(n>1)。
(1)线段树的点修改:
。
(2)线段树的区间查询:
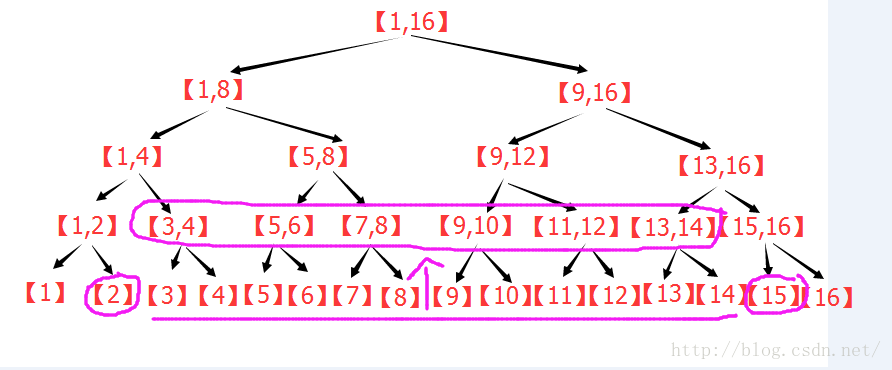
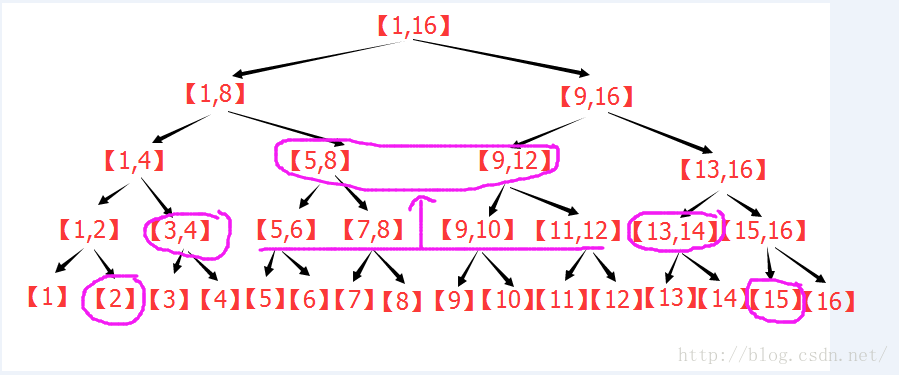
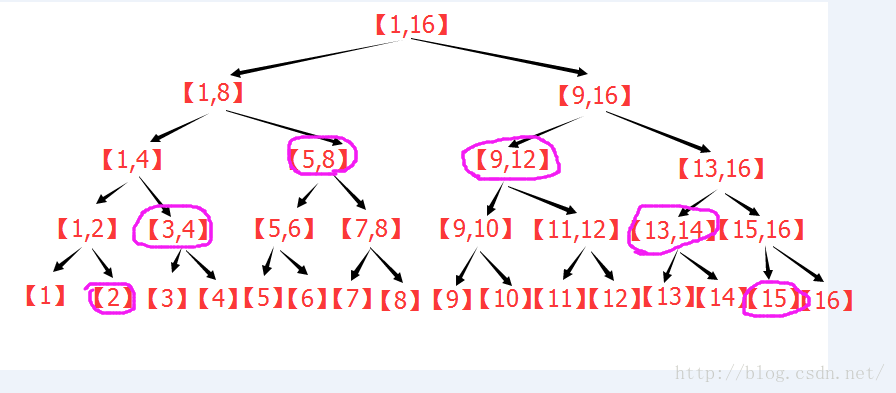
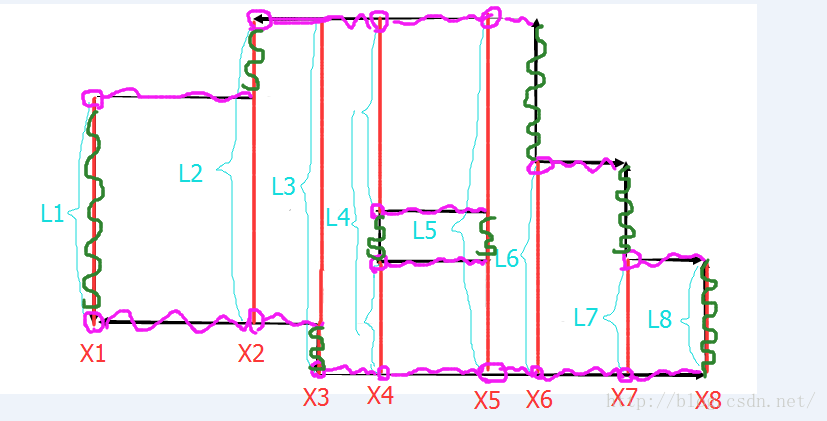
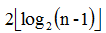 个子区间。个节点,就可以获得[L,R]的统计信息,实现了O(log2(n))的区间查询。
个子区间。个节点,就可以获得[L,R]的统计信息,实现了O(log2(n))的区间查询。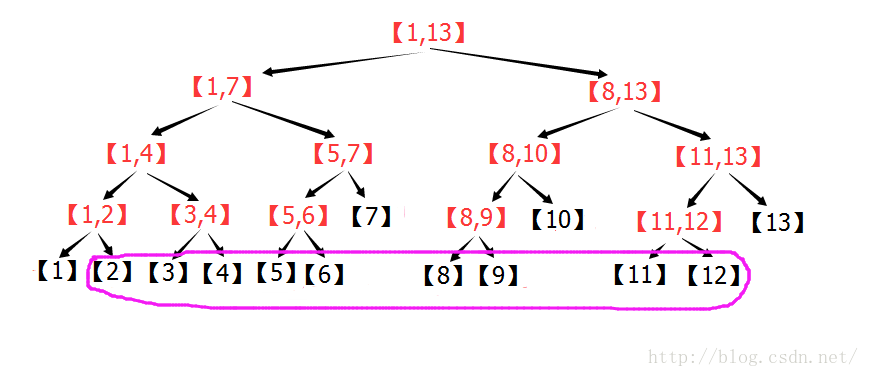
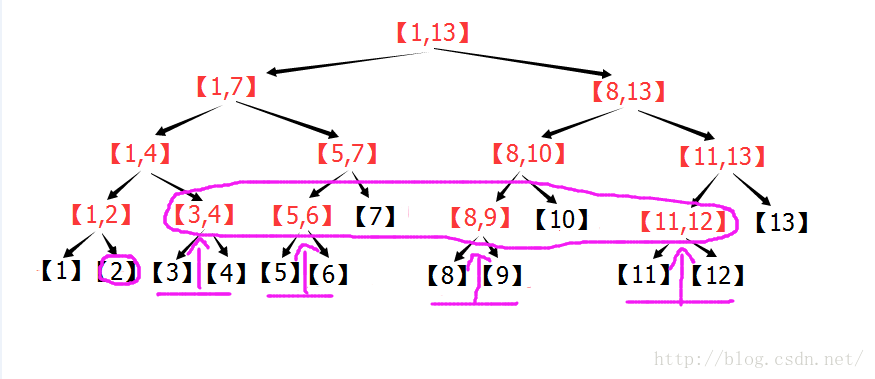
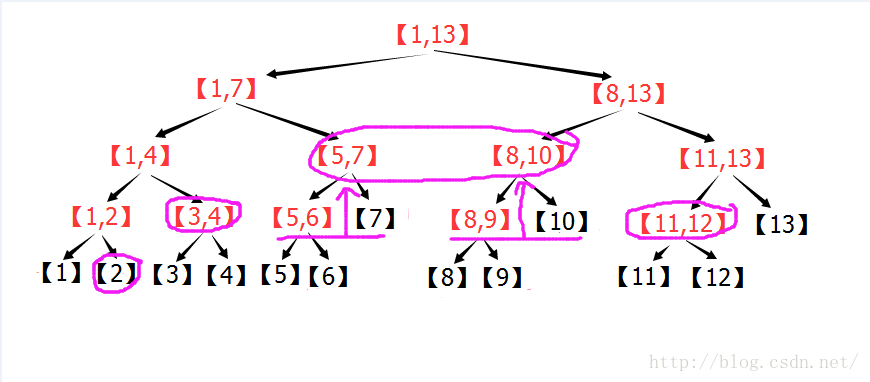
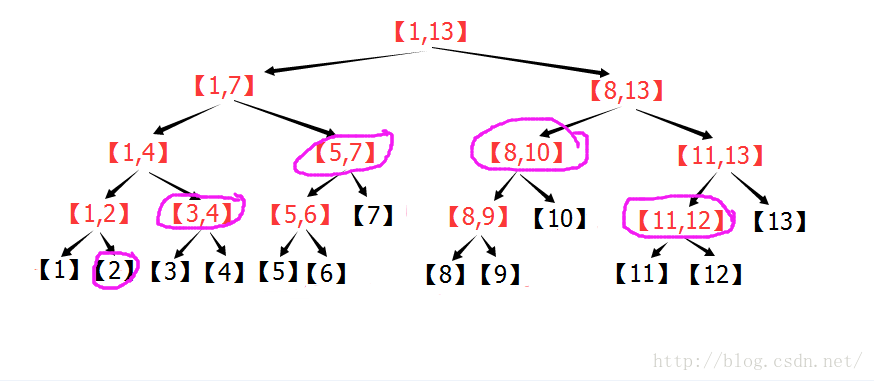 个子区间。
个子区间。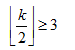 。
。 个区间。
个区间。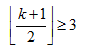 。
。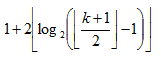 个区间。
个区间。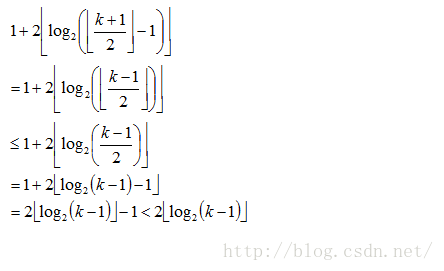
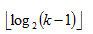 层,每层最多两个节点(参考粗略证明中的内容)。
层,每层最多两个节点(参考粗略证明中的内容)。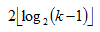 个区间,定理成立。是上界,但是,其实它是最小上界。。
个区间,定理成立。是上界,但是,其实它是最小上界。。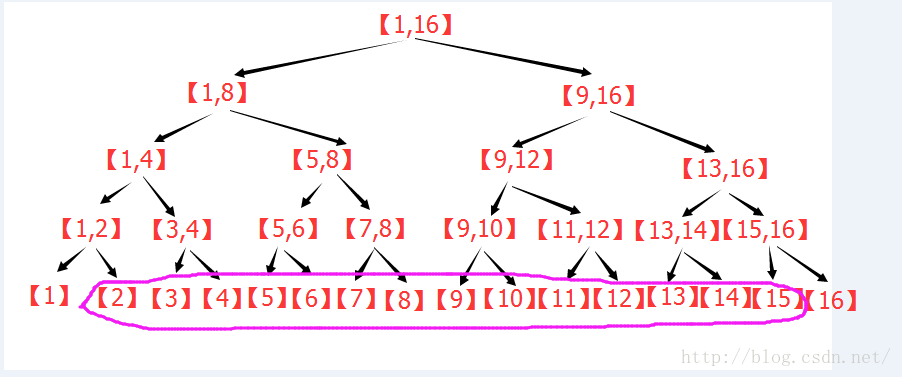
(3)线段树的区间修改:
(4)线段树的存储结构:
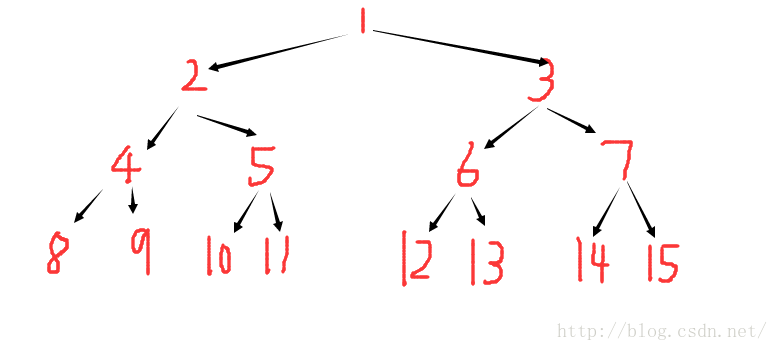
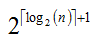 ,一般都开4倍空间,比如: int A[n<<2];
,一般都开4倍空间,比如: int A[n<<2];三:递归实现
(0)定义:
- #define maxn 100007 //元素总个数
- #define ls l,m,rt<<1
- #define rs m+1,r,rt<<1|1
- int Sum[maxn<<2],Add[maxn<<2];//Sum求和,Add为懒惰标记
- int A[maxn],n;//存原数组数据下标[1,n]
(1)建树:
- //PushUp函数更新节点信息 ,这里是求和
- void PushUp(int rt){Sum[rt]=Sum[rt<<1]+Sum[rt<<1|1];}
- //Build函数建树
- void Build(int l,int r,int rt){ //l,r表示当前节点区间,rt表示当前节点编号
- if(l==r) {//若到达叶节点
- Sum[rt]=A[l];//储存数组值
- return;
- }
- int m=(l+r)>>1;
- //左右递归
- Build(l,m,rt<<1);
- Build(m+1,r,rt<<1|1);
- //更新信息
- PushUp(rt);
- }
(2)点修改:
- void Update(int L,int C,int l,int r,int rt){//l,r表示当前节点区间,rt表示当前节点编号
- if(l==r){//到叶节点,修改
- Sum[rt]+=C;
- return;
- }
- int m=(l+r)>>1;
- //根据条件判断往左子树调用还是往右
- if(L <= m) Update(L,C,l,m,rt<<1);
- else Update(L,C,m+1,r,rt<<1|1);
- PushUp(rt);//子节点更新了,所以本节点也需要更新信息
- }
(3)区间修改:
- void Update(int L,int R,int C,int l,int r,int rt){//L,R表示操作区间,l,r表示当前节点区间,rt表示当前节点编号
- if(L <= l && r <= R){//如果本区间完全在操作区间[L,R]以内
- Sum[rt]+=C*(r-l+1);//更新数字和,向上保持正确
- Add[rt]+=C;//增加Add标记,表示本区间的Sum正确,子区间的Sum仍需要根据Add的值来调整
- return ;
- }
- int m=(l+r)>>1;
- PushDown(rt,m-l+1,r-m);//下推标记
- //这里判断左右子树跟[L,R]有无交集,有交集才递归
- if(L <= m) Update(L,R,C,l,m,rt<<1);
- if(R > m) Update(L,R,C,m+1,r,rt<<1|1);
- PushUp(rt);//更新本节点信息
- }
(4)区间查询:
- void PushDown(int rt,int ln,int rn){
- //ln,rn为左子树,右子树的数字数量。
- if(Add[rt]){
- //下推标记
- Add[rt<<1]+=Add[rt];
- Add[rt<<1|1]+=Add[rt];
- //修改子节点的Sum使之与对应的Add相对应
- Sum[rt<<1]+=Add[rt]*ln;
- Sum[rt<<1|1]+=Add[rt]*rn;
- //清除本节点标记
- Add[rt]=0;
- }
- }
然后是区间查询的函数:
- int Query(int L,int R,int l,int r,int rt){//L,R表示操作区间,l,r表示当前节点区间,rt表示当前节点编号
- if(L <= l && r <= R){
- //在区间内,直接返回
- return Sum[rt];
- }
- int m=(l+r)>>1;
- //下推标记,否则Sum可能不正确
- PushDown(rt,m-l+1,r-m);
-
- //累计答案
- int ANS=0;
- if(L <= m) ANS+=Query(L,R,l,m,rt<<1);
- if(R > m) ANS+=Query(L,R,m+1,r,rt<<1|1);
- return ANS;
- }
(5)函数调用:
-
- //建树
- Build(1,n,1);
- //点修改
- Update(L,C,1,n,1);
- //区间修改
- Update(L,R,C,1,n,1);
- //区间查询
- int ANS=Query(L,R,1,n,1);
四:非递归原理
点修改:
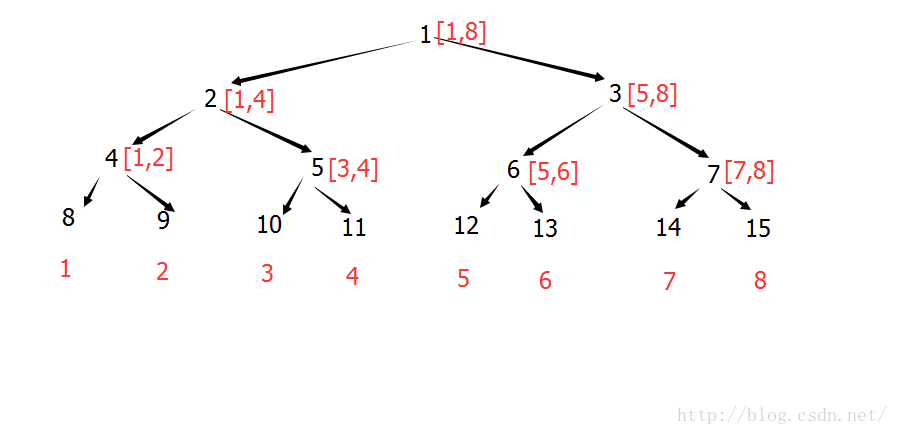
点修改下的区间查询:
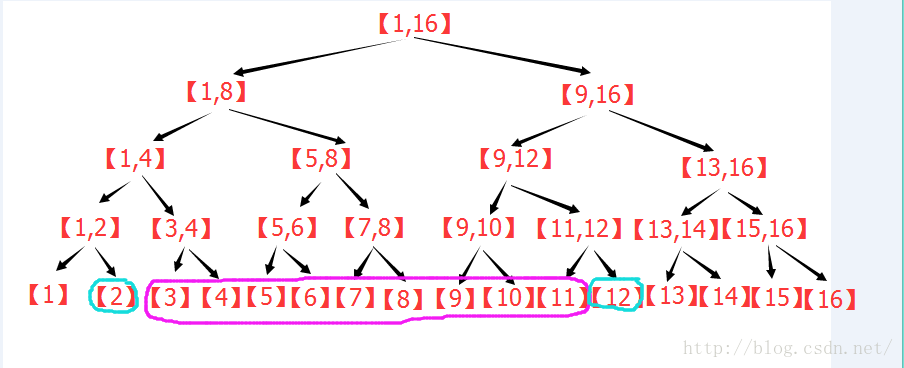
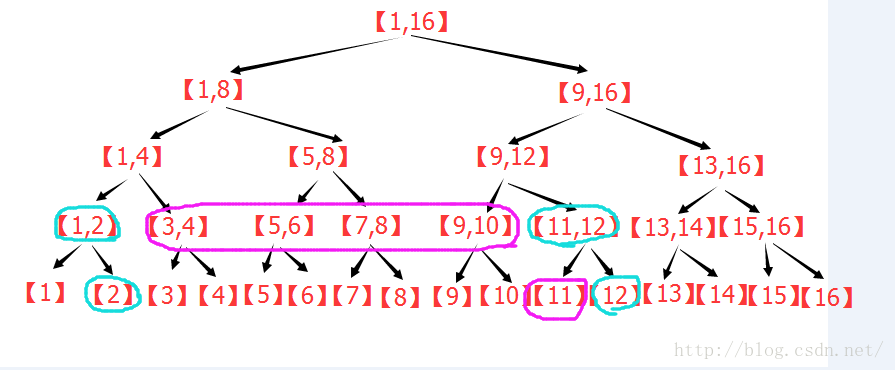
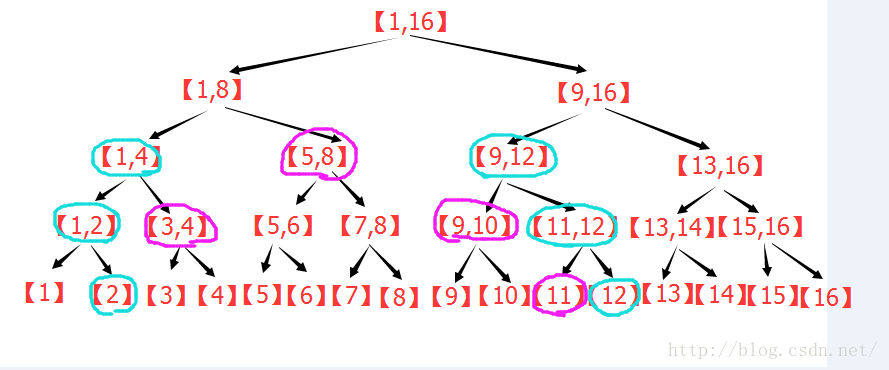
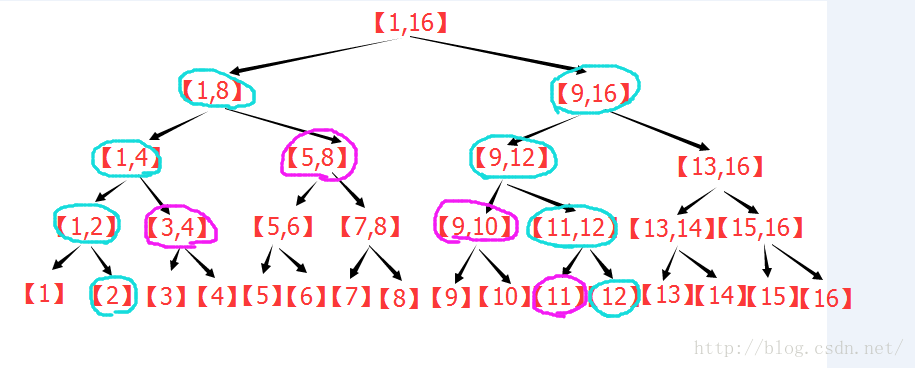
区间修改下的区间查询:
区间修改:
五:非递归实现
(0)定义:
- //
- #define maxn 100007
- int A[maxn],n,N;//原数组,n为原数组元素个数 ,N为扩充元素个数
- int Sum[maxn<<2];//区间和
- int Add[maxn<<2];//懒惰标记
(1)建树:
- //
- void Build(int n){
- //计算N的值
- N=1;while(N < n+2) N <<= 1;
- //更新叶节点
- for(int i=1;i<=n;++i) Sum[N+i]=A[i];//原数组下标+N=存储下标
- //更新非叶节点
- for(int i=N-1;i>0;--i){
- //更新所有非叶节点的统计信息
- Sum[i]=Sum[i<<1]+Sum[i<<1|1];
- //清空所有非叶节点的Add标记
- Add[i]=0;
- }
- }
(2)点修改:
- //
- void Update(int L,int C){
- for(int s=N+L;s;s>>=1){
- Sum[s]+=C;
- }
- }
(3)点修改下的区间查询:
- //
- int Query(int L,int R){
- int ANS=0;
- for(int s=N+L-1,t=N+R+1;s^t^1;s>>=1,t>>=1){
- if(~s&1) ANS+=Sum[s^1];
- if( t&1) ANS+=Sum[t^1];
- }
- return ANS;
- }
(4)区间修改:
- <span style="font-size:14px;">//
- void Update(int L,int R,int C){
- int s,t,Ln=0,Rn=0,x=1;
- //Ln: s一路走来已经包含了几个数
- //Rn: t一路走来已经包含了几个数
- //x: 本层每个节点包含几个数
- for(s=N+L-1,t=N+R+1;s^t^1;s>>=1,t>>=1,x<<=1){
- //更新Sum
- Sum[s]+=C*Ln;
- Sum[t]+=C*Rn;
- //处理Add
- if(~s&1) Add[s^1]+=C,Sum[s^1]+=C*x,Ln+=x;
- if( t&1) Add[t^1]+=C,Sum[t^1]+=C*x,Rn+=x;
- }
- //更新上层Sum
- for(;s;s>>=1,t>>=1){
- Sum[s]+=C*Ln;
- Sum[t]+=C*Rn;
- }
- } </span>
(5)区间修改下的区间查询:
- //
- int Query(int L,int R){
- int s,t,Ln=0,Rn=0,x=1;
- int ANS=0;
- for(s=N+L-1,t=N+R+1;s^t^1;s>>=1,t>>=1,x<<=1){
- //根据标记更新
- if(Add[s]) ANS+=Add[s]*Ln;
- if(Add[t]) ANS+=Add[t]*Rn;
- //常规求和
- if(~s&1) ANS+=Sum[s^1],Ln+=x;
- if( t&1) ANS+=Sum[t^1],Rn+=x;
- }
- //处理上层标记
- for(;s;s>>=1,t>>=1){
- ANS+=Add[s]*Ln;
- ANS+=Add[t]*Rn;
- }
- return ANS;
- }
六:线段树解题模型
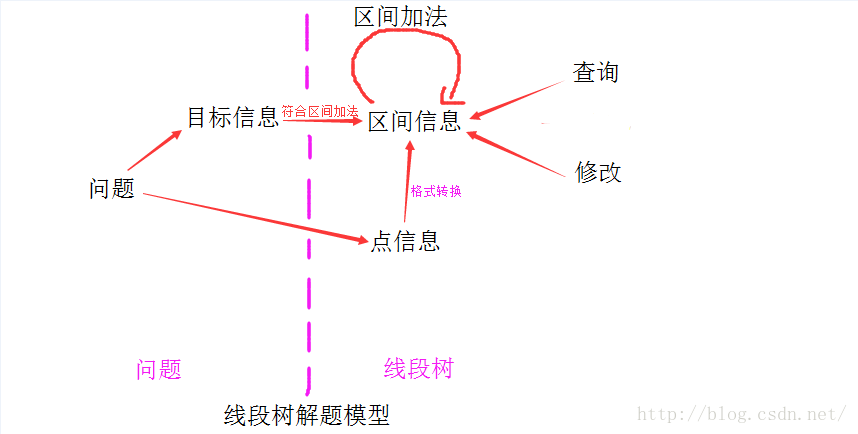
(1):字符串哈希
- //
- #define K 137
- #define maxn 100001
- char str[maxn];
- int Pow[maxn];//K的各个次方
- struct Node{
- int KeyL,KeyR;
- Node():KeyL(0),KeyR(0){}
- void init(){KeyL=KeyR=0;}
- }node[maxn<<2];
- void PushUp(int L,int R,int rt){
- node[rt].KeyL=node[rt<<1].KeyL+node[rt<<1|1].KeyL*Pow[L];
- node[rt].KeyR=node[rt<<1].KeyR*Pow[R]+node[rt<<1|1].KeyR;
- }
(2):最长连续零
题目:Codeforces 527C Glass Carving 题解- //
- #define maxn 200001
- using namespace std;
- int L[maxn<<2][2];//从左开始连续零个数
- int R[maxn<<2][2];//从右
- int Max[maxn<<2][2];//区间最大连续零
- bool Pure[maxn<<2][2];//是否全零
- int M[2];
- void PushUp(int rt,int k){//更新rt节点的四个数据 k来选择两棵线段树
- Pure[rt][k]=Pure[rt<<1][k]&&Pure[rt<<1|1][k];
- Max[rt][k]=max(R[rt<<1][k]+L[rt<<1|1][k],max(Max[rt<<1][k],Max[rt<<1|1][k]));
- L[rt][k]=Pure[rt<<1][k]?L[rt<<1][k]+L[rt<<1|1][k]:L[rt<<1][k];
- R[rt][k]=Pure[rt<<1|1][k]?R[rt<<1|1][k]+R[rt<<1][k]:R[rt<<1|1][k];
- }
-
(3):计数排序
给定一个长度不超过10^5的字符串(小写英文字母),和不超过5000个操作。
每个操作 L R K 表示给区间[L,R]的字符串排序,K=1为升序,K=0为降序。
最后输出最终的字符串。
题目转换成:
目标信息:区间的计数排序结果
点信息:一个字符
这里,目标信息是符合区间加法的,但是为了支持区间操作,还是需要扩充信息。
转换后的线段树结构:
区间信息:区间的计数排序结果,排序标记,排序种类(升,降)
点信息:一个字符
代码中需要解决的四个问题(难点在于标记下推和区间修改):
1.区间加法
对应的字符数量相加即可(注意标记是不上传的,所以区间加法不考虑标记)。
2.点信息->区间信息:把对应字符的数量设置成1,其余为0,排序标记为false。
3.标记下推
明显,排序标记是绝对标记,也就是说,标记对子节点是覆盖式的效果,一旦被打上标记,下层节点的一切信息都无效。
下推标记时,根据自己的排序结果,将元素分成对应的部分,分别装入两个子树。
4.区间修改
这个是难点,由于要对某个区间进行排序,首先对各个子区间求和(求和之前一定要下推标记,才能保证求的和是正确的)
由于使用的计数排序,所以求和之后,新顺序也就出来了。然后按照排序的顺序按照每个子区间的大小来分配字符。
操作后,每个子区间都被打上了标记。
最后,在所有操作结束之后,一次下推所有标记,就可以得到最终的字符序列。
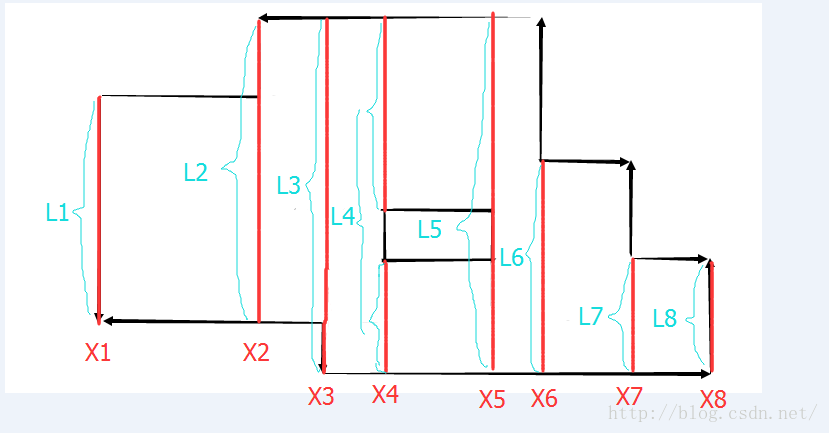
扫描线求重叠矩形面积:
- //
- struct LINE{
- int x;//横坐标
- int y1,y2;//矩形纵向线段的左右端点
- bool In;//标记是入边还是出边
- bool operator < (const Line &B)const{return x < B.x;}
- }Line[maxn];
然后扫描的时候,需要两个变量,一个叫PreL,存前一个x的操作结束之后的L值,和X,前一个横坐标。
- //
- int PreL=0;//前一个L值,刚开始是0,所以第一次计算时不会引入误差
- int X;//X值
- int ANS=0;//存累计面积
- int I=0;//线段的下标
-
- while(I < Ln){
- //先计算面积
- ANS+=PreL*(Line[I].x-X);
- X=Line[I].x;//更新X值
- //对所有X相同的线段进行操作
- while(I < Ln && Line[I].x == X){
- //根据入边还是出边来选择加入线段还是移除线段
- if(Line[I].In) Cover(Line[I].y1,Line[I].y2-1,1,n,1);
- else Uncover(Line[I].y1,Line[I].y2-1,1,n,1);
- ++I;
- }
- }
无论是求面积还是周长,扫描线的结构大概就是上面的样子。
需要解决的几个问题:
(1):线段树中点的含义
- //
- int Rank[maxn],Rn;
- void SetRank(){//调用前,所有y值被无序存入Rank数组,下标为[1..Rn]
- int I=1;
- //第一步排序
- sort(Rank+1,Rank+1+Rn);
- //第二步去除重复值
- for(int i=2;i<=Rn;++i) if(Rank[i]!=Rank[i-1]) Rank[++I]=Rank[i];
- Rn=I;
- //此时,所有y值被从小到大无重复地存入Rank数组,下标为[1..Rn]
- }
- int GetRank(int x){//给定x,求x的下标
- //二分法求下标
- int L=1,R=Rn,M;//[L,R] first >=x
- while(L!=R){
- M=(L+R)>>1;
- if(Rank[M]<x) L=M+1;
- else R=M;
- }
- return L;
- }
此时,线段树的下标的含义就变成:如果线段树下标为K,代表线段[ Rank[K] , Rank[K+1] )。
- //
- if(Line[I].In) Cover(GetRank(Line[I].y1),GetRank(Line[I].y2)-1,1,n,1);
- else Uncover(GetRank(Line[I].y1),GetRank(Line[I].y2)-1,1,n,1);
(2):如何维护覆盖线段长度
- //
- struct Node{
- int Cover;//区间整体被覆盖的次数
- int L;//Length : 所代表的区间总长度
- int CL;//Cover Length :实际覆盖长度
- Node operator +(const Node &B)const{
- Node X;
- X.Cover=0;//因为若上级的Cover不为0,不会调用子区间加法函数
- X.L=L+B.L;
- X.CL=CL+B.CL;
- return X;
- }
- }K[maxn<<2];
这样定义之后,区间的信息更新是这样的:
- //
- Node Query(int L,int R,int l,int r,int rt){
- if(L <= l && r <= R){
- return K[rt];
- }
- int m=(l+r)>>1;
- Node LANS,RANS;
- int X=0;
- if(L <= m) LANS=Query(L,R,ls),X+=1;
- if(R > m) RANS=Query(L,R,rs),X+=2;
- if(X==1) return LANS;
- if(X==2) return RANS;
- return LANS+RANS;
- }
维护线段覆盖3次或以上的长度:
- //
- struct Nodes{
- int C;//Cover
- int CL[4];//CoverLength[0~3]
- //CL[i]表示被覆盖了大于等于i次的线段长度,CL[0]其实就是线段总长
- }ST[maxn<<2];
- void PushUp(int rt){
- for(int i=1;i<=3;++i){
- if(ST[rt].C < i) ST[rt].CL[i]=ST[rt<<1].CL[i-ST[rt].C]+ST[rt<<1|1].CL[i-ST[rt].C];
- else ST[rt].CL[i]=ST[rt].CL[0];
- }
- }
这里给出节点定义和PushUp().
(3):如何维护扫描线过程中线段的数量
- //
- struct Node{
- int cover;//完全覆盖层数
- int lines;//分成多少个线段
- bool L,R;//左右端点是否被覆盖
- Node operator +(const Node &B){//连续区间的合并
- Node C;
- C.cover=0;
- C.lines=lines+B.lines-(R&&B.L);
- C.L=L;C.R=B.R;
- return C;
- }
- }K[maxn<<2];
要维护被分成多少个线段,就需要记录左右端点是否被覆盖,知道了这个,就可以合并区间了。
扫描线求重叠矩形周长:
- //
- struct Node{
- int cover;//完全覆盖层数
- int lines;//分成多少个线段
- bool L,R;//左右端点是否被覆盖
- int CoverLength;//覆盖长度
- int Length;//总长度
- Node(){}
- Node(int cover,int lines,bool L,bool R,int CoverLength):cover(cover),lines(lines),L(L),R(R),CoverLength(CoverLength){}
- Node operator +(const Node &B){//连续区间的合并
- Node C;
- C.cover=0;
- C.lines=lines+B.lines-(R&&B.L);
- C.CoverLength=CoverLength+B.CoverLength;
- C.L=L;C.R=B.R;
- C.Length=Length+B.Length;
- return C;
- }
- }K[maxn<<2];
- void PushUp(int rt){//更新非叶节点
- if(K[rt].cover){
- K[rt].CoverLength=K[rt].Length;
- K[rt].L=K[rt].R=K[rt].lines=1;
- }
- else{
- K[rt]=K[rt<<1]+K[rt<<1|1];
- }
- }
- int PreX=L[0].x;//前X坐标
- int ANS=0;//目前累计答案
- int PreLength=0;//前线段总长
- int PreLines=0;//前线段数量
- Build(1,20001,1);
- for(int i=0;i<nL;++i){
- //操作
- if(L[i].c) Cover(L[i].y1,L[i].y2-1,1,20001,1);
- else Uncover(L[i].y1,L[i].y2-1,1,20001,1);
- //更新横向的边界
- ANS+=2*PreLines*(L[i].x-PreX);
- PreLines=K[1].lines;
- PreX=L[i].x;
- //更新纵向边界
- ANS+=abs(K[1].CoverLength-PreLength);
- PreLength=K[1].CoverLength;
- }
- //输出答案
- printf("%d\n",ANS);
求立方体重叠3次或以上的体积:
个节点,于是,其实操作前后的两个线段树,结构一样,个节点不同,其余的节点都一样,于是可以重复利用其余的点。个节点。- //主席树
- int L[maxnn],R[maxnn],Sum[maxnn],T[maxn],TP;//左右子树,总和,树根,指针
- void Add(int &rt,int l,int r,int x){//建立新树,l,r是区间, x是新加入的数字的排名
- ++TP;L[TP]=L[rt];R[TP]=R[rt];Sum[TP]=Sum[rt]+1;rt=TP;//复制&新建
- if(l==r) return;
- int m=(l+r)>>1;
- if(x <= m) Add(L[rt],l,m,x);
- else Add(R[rt],m+1,r,x);
- }
- int Search(int TL,int TR,int l,int r,int k){//区间查询第k大
- if(l==r) return l;//返回第k大的下标
- int m=(l+r)>>1;
- if(Sum[L[TR]]-Sum[L[TL]]>=k) return Search(L[TL],L[TR],l,m,k);
- else return Search(R[TL],R[TR],m+1,r,k-Sum[L[TR]]+Sum[L[TL]]);
- }
以上就是主席树部分的代码。
个节点。九:练习题
适合非递归线段树的题目:
Codeforces 35E Parade : 题解
题意:给定若干矩形,下端挨着地面,求最后的轮廓形成的折线,要求输出每一点的坐标。
思路:虽然是区间修改的线段树,但只需要在操作结束后一次下推标记,然后输出,所以适合非递归线段树。
URAL 1846 GCD2010 : 题解
题意:总共10万个操作,每次向集合中加入或删除一个数,求集合的最大公因数。(规定空集的最大公因数为1)
Codeforces 12D Ball : 题解
题意:
给N (N<=500000)个点,每个点有x,y,z ( 0<= x,y,z <=10^9 )
对于某点(x,y,z),若存在一点(x1,y1,z1)使得x1 > x && y1 > y && z1 > z 则点(x,y,z)是特殊点。
问N个点中,有多少个特殊点。
提示:排序+线段树
Codeforces 19D Points : 题解
题意:
给定最多20万个操作,共3种:
1.add x y :加入(x,y)这个点
2.remove x y :删除(x,y)这个点
3.find x y :找到在(x,y)这点右上方的x最小的点,若x相同找y最小的点,输出这点坐标,若没有,则输出-1.
提示:排序,线段树套平衡树
Codeforces 633E Startup Funding : 题解
这题需要用到一点概率论,组合数学知识,和二分法。
非递归线段树在这题中主要解决RMQ问题(区间最大最小值问题),由于不带修改,这题用Sparse Table求解RMQ是标答。
因为RMQ询问是在二分法之内求的,而Sparse Table可以做到O(1)查询,所以用Sparse Table比较好,总复杂度O(n*log(n))。
不过非递归线段树也算比较快的了,虽然复杂度是O(n*log(n)*log(n)),还是勉强过了这题。
扫描线题目:
递归线段树题目:
给定一个长度不超过10^5的字符串(小写英文字母),和不超过5000个操作。
每个操作 L R K 表示给区间[L,R]的字符串排序,K=1为升序,K=0为降序。
最后输出最终的字符串。
题意:有一个板,h行,每行w长度的位置。每次往上面贴一张海报,长度为1*wi .
每次贴的时候,需要找到最上面的,可以容纳的空间,并且靠边贴。
题意就是,给定n,m.
满足m个条件的n个数,或说明不存在。
每个条件的形式是,给定 Li,Ri,Qi ,要求 a[Li]&a[Li+1]&...&a[Ri] = Qi ;
Codeforces 474E Pillar (线段树+动态规划): 题解
题意就是,给定10^5 个数(范围10^15),求最长子序列使得相邻两个数的差大于等于 d。
POJ 2777 Count Color : 题解
给线段涂颜色,最多30种颜色,10万个操作。
每个操作给线段涂色,或问某一段线段有多少种颜色。
30种颜色用int的最低30位来存,然后线段树解决。
URAL 1019 Line Painting: 线段树的区间合并 题解
给一段线段进行黑白涂色,最后问最长的一段白色线段的长度。
Codeforces 633H Fibonacci-ish II :题解
这题需要用到莫队算法(Mo's Algorithm)+线段树区间修改,不过是单边界的区间,写起来挺有趣。
另一种解法就是暴力,很巧妙的方法,高复杂度+低常数居然就这么给过了。
树套树题目:
Codeforces 19D Points : 题解
题意:
给定最多20万个操作,共3种:
1.add x y :加入(x,y)这个点
2.remove x y :删除(x,y)这个点
3.find x y :找到在(x,y)这点右上方的x最小的点,若x相同找y最小的点,输出这点坐标,若没有,则输出-1.
提示:排序,线段树套平衡树
转载请注明出处: 原文地址:http://blog.csdn.net/zearot/article/details/48299459

 浙公网安备 33010602011771号
浙公网安备 33010602011771号