Django框架基础7
本节主要知识点:
- 一对一(OneToOneFiled)
- 一对多(ForeignKey)
- 多对多(ManyToManyField)
- F对象查询
- Q对象查询
一、Django数据表关联映射
- 一对一(OneToOneFiled)
- 一对多(ForeignKey)
- 多对多(ManyToManyField)
我们知道涉及到数据表之间的对应关系就会想到一对一、一对多、多对多,在学习 MySQL 数据库时表关系设计是需要重点掌握的知识。Django 中定义了三种关系类型的字段用来描述数据库表的关联关系:一对多(Foreignkey)、一对一(OneToOneFiled)、以及多对多(ManyToManyFiled),在本节我们对它们做简单的介绍。
1、一对多关系类型
这种类型在数据库中体现是外键关联关系,它在和其他的 Model 建立关联同时也和自己建立关联,用来描述一对多的关系,例如一个作者可以写很多不同的书,但是这些书又只能对应这一个作者,再比如一本图书只能属于一个出版社,一个出版社可以出版很多不同种类的图书,这就是一对多的关系。Django 会自动将字段的名称添加“_id”作为列名,ForgienKey 的定义如下:
class django.db,model.ForeignKey(to,on_delete,**options)(1)必填参数
on_delete 可以理解为 MySQL 外键的级联动作,当主表执行删除操作时对子表的影响,即子表要执行的操作,Django 提供的可选值如下所示:
-
CASCADE:级联删除,它是大部分 ForeignKey 的定义时选择的约束。它的表现是删除了“主”,则“子”也会被自动删除。
-
PROTECT:删除被引用对象时,将会抛出 ProtectedError 异常。当主表被一个或多个子表关联时,主表被删除则会抛出异常。
-
SET_NULL:设置删除对象所关联的外键字段为 null,但前提是设置了选项 null 为True,否则会抛出异常。
-
SET_DEFAULT:将外键字段设置为默认值,但前提是设置了 default 选项,且指向的对象是存在的。
-
SET(value):删除被引用对象时,设置外键字段为 value。value 如果是一个可调用对象,那么就会被设置为调用后的结果。
-
DO_NOTHING:不做任何处理。但是,由于数据表之间存在引用关系,删除关联数据,会造成数据库抛出异常。
(2)可选参数
-
to_field:关联对象的字段名称。默认情况下,Django 使用关联对象的主键(大部分情况下是 id),如果需要修改成其他字段,可以设置这个参数。但是,需要注意,能够关联的字段必须有 unique=True 的约束。
-
db_constraint:默认值是 True,它会在数据库中创建外键约束,维护数据完整性。通常情况下,这符合大部分场景的需求。如果数据库中存在一些历史遗留的无效数据,则可以将其设置为 False,这时就需要自己去维护关联关系的正确性了。
-
related_name:这个字段设置的值用于反向查询,默认不需要设置,Django 会设置其为“小写模型名 _set”。
-
related_query_name:这个名称用于反向过滤。如果设置了 related_name,那么将用它作为默认值,否则 Django 会把模型的名称作为默认值。
(3)语法格式
#一个A类实例对象关联多个B类实例对象
class A(model.Model):
....
class B(model.Model):
属性 = models.ForeignKey(多对一中"一"的模型类, ...)(4)实例应用
修改原来定义的代码,将出版社与图书之间修改为一对多的关系,添加如下代码:
from django.db import models
#新建出版社表
class PubName(models.Model):
pubname=models.CharField('名称', max_length=255, unique=True)
# 创建book表
class Book(models.Model):
title = models.CharField(max_length=30, unique=True, verbose_name='书名')
# public = models.CharField(max_length=50, verbose_name='出版社')
price = models.DecimalField(max_digits=7, decimal_places=2, verbose_name='定价')
retail_price = models.DecimalField(max_digits=7, decimal_places=2, verbose_name='零售价', default="30")
# 设置外键
pub = models.ForeignKey(to=PubName, on_delete=models.CASCADE, null=True) # 创建Foreign外键关联pub,以pub_id关联
def __str__(self):
return "title:%s pub:%s price:%s" % (self.title, self.pub, self.price)
- python manage.py makemigrations
- python manage.py migrate
如果迁移失败,需要删除数据中的所有表,再重新迁移。
插入数据创建一对多对象,如下所示:
from index.model import *
#创建PubName实例化对象pub1并插入书籍信息
pub1=PubName.objects.create(pubname="清华出版社")
Book.objects.create(title="Python",price="59.00",retail_price="59.00",pub=pub1)
Book.objects.create(title="Redis",price="25.00",retail_price="25.00",pub=pub1)
Book.objects.create(title="Java",price="45.00",retail_price="45.00",pub=pub1)
#创建PubName实例化对象pub2并插入书籍信息
pub2=PubName.objects.create(pubname="北大出版社")
Book.objects.create(title="Django",price="65.00",retail_price="65.00",pub=pub2)
Book.objects.create(title="Flask",price="45.00",retail_price="45.00",pub=pub2)
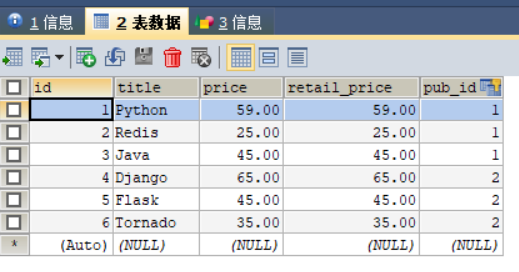
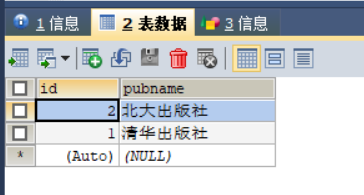
Book.objects.create(title="Tornado",price="35.00",retail_price="35.00",pub=pub2)访问 MySQL 数据库分别查询 index_book、index_pubname 数据表(如下所示):
2、一对一关系类型
一对一关系类型的使用和场景相对其他两种关联关系要少,经常用于对已有 Model 的扩展,例如我们可以对 UserInfo 表进行扩展,添加类似用户昵称、个性签名等字段。此时就可以新建一个 Model,并定义一个字段与 UserInfo 表一对一关联。这样就实现了用户信息拓展表与 UserInfo 表一对一关联,下面会用通过实例进行说明。
(1)语法格式
class A(model.Model):
...
class B(model.Model):
属性 = models.OneToOneField(A)(2)实例应用
新建 index\models.py 下添加以下代码:
#新建一对一关用户信息表拓展表,添加完成后执行数据库迁移同步操作
class ExtendUserinfo(models.Model):
user=models.OneToOneField(to=UserInfo,on_delete=models.CASCADE)
signature=models.CharField(max_length=255,verbose_name='用户签名',help_text='自建签名')
nickname=models.CharField(max_length=255,verbose_name='昵称',help_text='自建昵称')使用 Django shell 创建数据,如下所示:
from index.models import UserInfo,ExtendUserinfo
username=UserInfo.objects.create(username="xiaoming",password="******")
username=UserInfo.objects.create(username="xiaohong",password="*******",gender="F")
#创建一对一表关联
ExtendUserinfo.objects.create(user=username,signature="good good study,day day up",nickname="XH")3、多对多关系
多对多关系也是比较常见的,比如一个作者可以写很多本书,一本书也可以由很多作者一起完成,那么这时候 Author 和 Book 之间就是多对多的关系。
Django 通过中间表的方式来实现 Model 之间的多对多的关系,这和 MySQL 中实现方式是一致的。这个中间表我们可以自己提供,也可以使用 Django 默认生成的中间表。
(1)
class django.db.models.ManyToManyFiled(to,**options)它只有一个必填的参数即 to,与其他两个关联词在一样,用来指定与当前的 Model 关联的 Model。
(2)可选参数
当然 ManyToManyFiled 还有一些重要的可选参数,下面我们对它们依次进行介绍:
-
-
db_table 用于指定中间表的名称,如果没有提供,Django 会使用多对多字段的名称和包含这张表的 Model 的名称组合起来构成中间表的名称,当然也会包含 index 前缀。
-
through 用于指定中间表,这个参数不需要设置,Django会自动生成隐式的 through Model。由于 Django可以生成自身默认的中间表,该参数可以让用户自己去控制表之间的关联关系或者增加一些额外的信息。
(3)语法格式
class Author(models.Model):
...
class Book(models.Model):
...
authors = models.ManyToManyField(Author)(4)多对多中间表
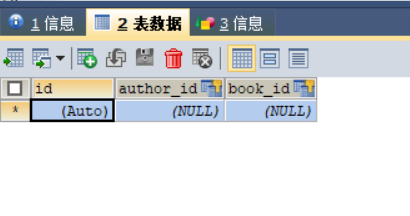
books=models.ManyToManyField(to="Book") #创建多对多映射关系然后再执行数据库迁移命令,刷新数据库,可以看到如下中间表:
(5)实例应用
插入作者信息数据,如下所示:
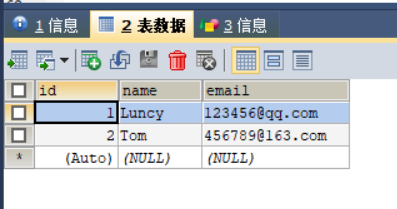
author1=Author.objects.create(name="Luncy",email="123456@qq.com")
author2=Author.objects.create(name="Tom",email="456789@163.com")
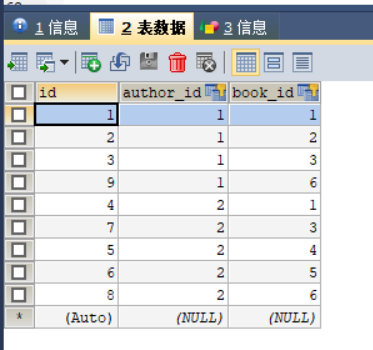
author1.books.add(Book.objects.get(id="1"))
author1.books.add(Book.objects.get(id="2"))
author1.books.add(Book.objects.get(id="3"))
author2.books.add(Book.objects.get(id="1"))
author2.books.add(Book.objects.get(id="4"))
author2.books.add(Book.objects.get(id="5"))
author2.books.add(Book.objects.get(id="3"))
author2.books.add(Book.objects.get(id="6"))
author1.books.add(Book.objects.get(id="6"))多对多关系在中间表插入数据需要使用 add() 方法,books 是对应的多对多字段。
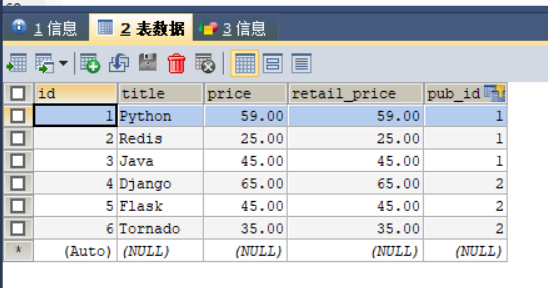
通过以上代码就完成多对多关系的创建,最后在 MySQL 中查看多对多相关联的三张数据表,如下所示:
书籍信息表:
作家信息表:
中间表:
本节用了较长的篇幅给大家讲解了 Django 中数据表的关联关系,它和 MySQL 的思想是一致的,只是 Django 提供了自己的一套方法,所以我们也要学会使用它,在后续章节我们将基于此节的内容介绍 Django QuerySet API 即与数据库接口相关的表查询、更新、删除操作。
二、
F对象查询与Q对象查询,刚看到大家一定会感到很陌生,其实它们也是 Django 提供的查询方法,而且非常的简单的高效,对于一些特殊的场景需求应用起来非常的合适,在本节我们将对这两种查询方法进行讲解,帮助大家掌握它们的使用方法以及适合应用的场景。
1、F对象查询
F对象主要用于模型类的 A 字段属性与 B 字段属性两者的比较,即操作数据库中某一列的值。通常是对数据库中的字段值在不获取的情况下进行操作。F 对象内置在数据包django.db.models中,所以使用时需要提前导入。如下所示:
from django.db.models import F它的语法格式如下所示:
from django.db.models import F
F('字段名')在使用F对象进行查询的时候需要注意:一个 F() 对象代表了一个 Model 的字段的值;F 对象可以在没有实际访问数据库获取数据值的情况下对字段的值进行引用。
Django 支持对 F对象引用字段的算术运算操作,并且运算符两边可以是具体的数值或者是另一个 F 对象,下面我们通过实例进一步认识 F 对象。
from django.db.models import F
from index.models import Book
#给Book所有实例价格(retail_price)涨价20元
Book.objects.all().update(retail_price=F('retail_price')+20) #获取该列所有值并加20
#利用传统的方法实现涨价20元
books = Book.objects.all()
for book in books:
book.retail_price += 20
book.save()
return HttpResponse("增加价格成功")
通过上述实例可以看出,使用 F 对象相对传统的方法要简单的多。那么如何通过 F 对象实现两个字段值(列)之间的比较呢?实例如下所示:
#对数据库中两个字段的值进行比较,列出哪儿些书的零售价高于定价
books = Book.objects.filter(retail_price__gt=F('price'))
for book in books:
print(book.title, '定价:', book.price, '现价:', book.retail_price)2、
Q 对象相比 F 对象更加复杂一点,它主要应用于包含逻辑运算的复杂查询。Q 对象把关键字参数封装在一起,并传递给 filter、exclude、get 等查询的方法。多个 Q 对象之间可以使用&或者|运算符组合(符号分别表示与和或的关系),从而产生一个新的 Q 对象。当然也可以使用~(非)运算符来取反,从而实现NOT查询。Q 对象的导入方式如下所示:
from django.db.models import Q它和 Q 对象位于一个数据包里面。常用语法格式如下:
from django.db.models import Q
Q(条件1)|Q(条件2) # 条件1成立或条件2成立
Q(条件1)&Q(条件2) # 条件1和条件2同时成立
Q(条件1)&~Q(条件2) # 条件1成立且条件2不成立
#...等最简单的 Q 对象的使用方法是将单个字段类属性作为参数进行查询,实例如下:
#查询 书籍的title中包含有字母P的
from index.models import Book
from django.db.models import Q
Book.objects.filter(Q(title__contains="P"))
# <QuerySet [<Book: Book object (1)>]>
#多个Q对象组合
from index.models import Book
from django.db.models import Q
#查找c语言中文网出版的书或价格低于35的书
Book.objects.filter(Q(retail_price__lt=35)|Q(pub_id='2'))#两个Q对象是或者的逻辑关系
#查找不是c语言中文出版的书且价格低于45的书
Book.objects.filter(Q(retail_price__lt=45)&~Q(pub_id='2'))#条件1成立条件2不成立三、
聚合查询是指对一个数据表(Model)中某个字段的数据进行部分或者全部统计查询的一种方式,比如所有全部书的平均价格或者是书籍的总数量等等,在这些时候就会使用到聚合查询这种方法。
1、
对数据表计算统计值,需要使用 aggregate 方法,提供的参数可以是一个或者多个聚合函数,aggregate 是 QuerySet 的一个子句,它的返回值是一个字典类型,键是聚合的关键字,值是聚合后的统计结果。
不带分组的聚合查询是指对将全部数据进行集中统计查询,Django 定义了一些常用的聚合函数,比如求平均值(Avg)、计数(Count)、求最值(Max和Min)以 Sum 求和。它们统一定义在 django.db.models模块中,所以再使用聚合函数时,同样需要提前导入,为了方便使用,我们采用下面的方式引入:
from django.db.models import *它的语法格式如下所示,它的返回值是一个字典,以统计结果变量名为 key,以统计值为 value:
MyModel.objects.aggregate(统计结果变量名=聚合函数('列名'))我们通过求所有书籍的价格平均值与所书籍数量来进行实例演练:
#求所有书籍的平均价格
from index.models import Book
from django.db.models import *
result =Book.objects.aggregate(myAvg=Avg('price'))
print("平均价格是:", result['myAvg'])
print("result=", result)
#result= {'myAvg': Decimal('47.800000')}
#求一共有多少本书
result =Book.objects.aggregate(MyCulate=Count('title'))
print("数据记录总个数是:", result['MyCulate'])
print("result=", result)
#result= {'MyCulate': 5}
#传递多个聚合函数一起求值
result=Book.objects.aggregate(l=Min("price"),m=Max("price"),n=Avg("retail_price"))
print("result=",result)
#result= {'l': Decimal('25.00'), 'm': Decimal('65.00'), 'n': Decimal('127.800000')}2、
QuerySet.annotate(结果变量名=聚合函数('列名'))分组聚合的实现主要两个步骤:首先使用 MyModel.objects.values 获得要分组聚合的列,它的返回结果是一个 QuerySet 类型的字典,然后通过 QuerySet.annotate(变量名=聚合函数('列名')) 的方法分组聚合得到相应的结果。下面我们通过实例进行说明,通过分组聚合查询获取价格相同的书籍数量:
#在index/views.py 添加代码
from django.db.models import Count
from index.models import Book,PubName
def test_annotate(request):
# 得到所有出版社的查询集合QuerySet
bk_set = Book.objects.values('price')
# bk=Book.objects.get(id=1)
# print('书名:',bk.title,'出版社是:',bk.pub.pubname)
# 根据出版社QuerySet查询分组,出版社和Count的分组聚合查询集合
bk_count_set = bk_set.annotate(myCount=Count('price')) # 返回查询集合
for item in bk_count_set: #通过外键关联进行查询bk_set.pub.pubname
print("价格是:", item['price'], "同等价格书籍数量:", item['myCount'])
return HttpResponse('请在CMD命令行控制台查看结果')
#路由配置为:path('annotate/',views.test_annotate)会得到如下输出:
价格是: 59.00 同等价格书籍数量: 1 价格是: 25.00 同等价格书籍数量: 1 价格是: 45.00 同等价格书籍数量: 2 价格是: 65.00 同等价格书籍数量: 1
3、知识点总结
本节主要讲解了聚合查询以及分组聚合查询的使用方法,还给大家介绍了几个常用的聚合函数。聚合查询和分组查询分别调用不同的方法来实现,聚合查询是 aggregate,而分组聚合查询是 annotate。后者经常配合 values 方法来选取要分组的字段。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号