scrapy爬虫框架(五)Spider Middleware
Spider Middleware,中文可以翻译为爬虫中间件,但我个人认为英文的叫法更为合适。它是处于Spider 和 Engine 之间的处理模块。当 Downloader 生成 Response 之后,Response 会被发送给 Spider,在发送给 Spider 之前,Response 会首先经过 Spider Middleware 的处理,当 Spider 处理生成 Item 和Request之后,Item和Request 还会经过 Spider Middleware 的处理。
Spider Middleware的作用:
- Downloader生成Reponse之后,Engine会将其发送给Spider进行解析,在Response发送给Spider之前,可以借助Spider Middleware对Response进行处理。
- Spider生成Request之后会被发送至Engine,然后Request会转发到Scheduler,在Request被发送给Engine之前,可以借助Spider Middleware对Request进行处理。
- Spider生成Item之后会被发送至Engine,然后Item会被转发到Item Pipeline,在Item被发送给Engine之前,可以借助Spider Middleware对Item进行处理。
总的来说,Spider Middleware可以用来处理输入给Spider的Response和Spider输出Item以及Request。
一、简介
Scrapy框架中其实已经提供了许多Spider Middleware,与Downloader Middleware类似,它们被SPIDER_MIDDLEWARES_BASE变量所定义。
SPIDER_MIDDLEWARES_BASE变量的内容如下:
{
'scrapy.spidermiddlewares.httperror.HttpErrorMiddleware":50,
'scrapy.spidermiddlewares.offsite.OffsiteMiddleware':500,
'scrapy.spidermiddlewares.referer.RefererMiddleware':700,
'scrapy.spidermiddlewares.urllength.UrlLengthMiddleware': 800,
' scrapy.spidermiddlewares.depth.DepthMiddleware':900,
}SPIDER_MIDDLEWARES_BASE里定义的Spider Middleware是默认生效的,如果我们要自定义Spider Middleware,可以和Downloader Middleware一样,创建Spider Middleware并将其加入SPIDER_MIDDLEWARES。直接修改这个变量就可以添加自己定义的Spider Middleware,以及禁用SPIDER_MIDDLEWARES_BASE里面定义的Spider Middleware。
这些Spider Middleware的调用优先级和Downloader Middleware也是类似的,数字越小的Spider Middleware是越靠近Engine的,数字越大的Spider Middleware是越靠近Spider的。
二、核心方法
Scrapy内置的Spider Middleware为Scrapy提供了基础的功能。如果我们想要扩展其功能,只需要实现某几个方法。
每个Spider Middleware都定义了以下一个或多个方法的类,核心方法有如下4个。
- process_spider_input(response, spider)
- process_spider_output(response, result, spider)
- process_spider_exception(response, exception, spider)
- process_start-requests(start_requests, spider)
只需要实现其中一个方法就可以定义一个Spider Middleware。下面我们来看看这4个方法的详细用法。
1、process_spider_input(response, spider)
当Response通过Spider Middleware时,process_spider_input方法被调用,处理该Response。它有两个参数。
(1)参数
- response:Response对象,即被处理的Response。
- spider:Spider对象,即该Response对应的Spider对象。
(2)返回值
process_spider_input应该返回None或者抛出一个异常。
- None:如果它返回None,Scrapy会继续处理该Response,调用所有其他的Spider Middleware直到Spider处理该Response。
- 异常:如果它抛出一个异常,Scarapy不会调用任何其他Spider Middleware的process_spider_input方法,并调用Request的errback方法。errback的输出将会以另一个方向被重新输入中间件,使用process_spider_output处理,当其抛出异常时则调用process_spider_exception来处理。
2、process_spider_output(response, result, spider)
当Spider处理Response返回结果时,process_spider_output方法被调用。它有3个参数。
(1)参数
- response:Response对象,即生成该输出的Response。
- result:包含Request或Item对象的可迭代对象,即Spider返回的结果。
- spider:Spider对象,即结果对应的Spider对象。
(2)返回值
process_spider_output必须返回包含Request或Item对象的可迭代对象。
3、process_spider_exception(response, exception, spider)
当Spider或Spider Middleware的process_spider_input方法抛出异常时,process_spider_exception方法被调用。它有3个参数。
(1)参数
- response:Response对象,即异常被抛出时被处理的Response。
- exception:Exception对象,被抛出的异常。
- spider:Spider对象,即抛出该异常的Spider对象。
(2)返回值
process_spider_exception必须必须返回None或者一个(包含Response或Item对象的)可迭代对象。
- None:如果它返回None,那么Scrapy将继续处理该异常,调用其他Spider Middleware中process_spider_exception方法,直到所有Spider Middleware都被调用。
- 可迭代对象(Response或Item):如果它返回的是一个可迭代对象,则其他Spider Middleware的process_spider_output方法被调用,其他的process_spider_exception不会被调用。
4、process_start_requests(start_requests, spider)
process_start_requests方法以Spider启动的Request为参数被调用,执行的过程类似于process_spider_output,只不过它没有相关联的Response并且必须返回Request。它有两个参数。
(1)参数
- process_start_requests:包含Request的可迭代对象,即Start Requests。
- spider:Spider对象,即Start_Reqeusts所属的Spider。
(2)返回值
process_start_requests方法必须返回另一个包含Request对象的可迭代对象。
三、实例演示
上面的内容其实理解起来还是有点抽象,接下来我们结合一个实例来加深一下对Spider Middleware的认识。
1、创建文件
首先我们新建一个Scrapy项目叫做testspidermiddleware,命令如下所示:
- scrapy startproject scrapyspidermiddlewaredemo
然后进入项目,新建一个Spider。我们还是以https://www.httpbin.org/为例来进行演示,命令如下所示:
- scrapy genspider httpbin www.httpbin.org
命令执行完毕后,新建了一个名为httpbin的Spider。接下来我们修改start_url为https://www.httpbin.org/get,然后自定义start_requests方法,构造几个Request,回调方法还是定义为parse方法。随后将parse方法添加一行打印输出,将response变量的text属性输出,这样我们便可以看到Scrapy发送的Request信息了。修改Spider内容如下所示:
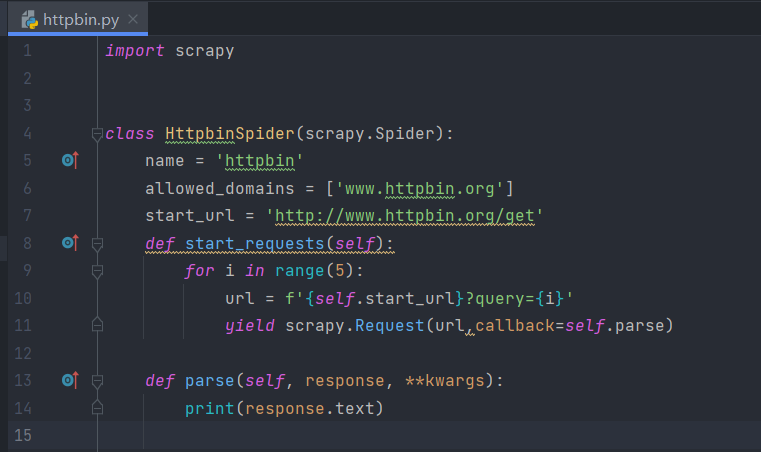
执行Scrapy结果,结果如下所示:
.........

这里我们可以看到几个Request对应的Response的内容就被输出了,每个返回结果带有args参数,query为0-4。
另外我们可以定义一个Item,4个字段就是目标站点返回的字段,相关代码如下:

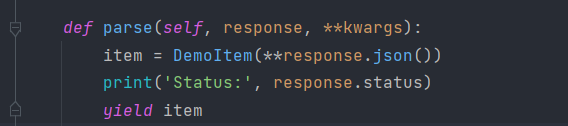
可以在parse方法中将返回的Response的内容转化为TestspidermiddlewareItem,将parse方法做如下修改:
需要注意的是,我们需要导入items.py文件的DemoItem类
这时候可能会产生未发现此文件导入的错误,或者运行时发现未发现此文件的错误。这时候我们将整个文件设为源根即可。

这时候就可以发现最终Spider就会产生对应的DemoItem了,运行效果如下:

可以看到原本Response的JSON数据就被转化成了DemoItem并返回。
接下来我们实现一个Spider Middleware,看看如何实现Response、Item、Request的处理。
2、process_start_requests
我们先在middlewares.py中重新声明一个CustomizeMiddleware类,内容如下:
 这里实现了process_start_requests方法,它可以对start_requests表示的每个Request进行处理,我们首先获取了每个Request的URL,然后在URL的后面又拼接上了另外一个Query参数,name等于germy,然后我们利用request的replace方法将url属性替换,这样就成功为Request赋值了新的URL。
这里实现了process_start_requests方法,它可以对start_requests表示的每个Request进行处理,我们首先获取了每个Request的URL,然后在URL的后面又拼接上了另外一个Query参数,name等于germy,然后我们利用request的replace方法将url属性替换,这样就成功为Request赋值了新的URL。
接着我们需要将此CustomizeMiddleware开启,在setting.py中进行如下的定义:
这样我们就开启了CustomizeMiddleware这个Spider Middleware。
重新运行Spider,这时候我们可以看到输出结果就变成了类似下面这样的结果: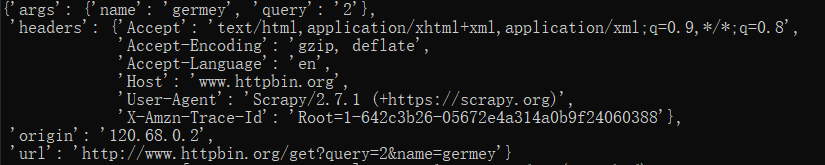
可以观察到url属性成功添加了name=germy的内容,这说明我们利用Spider Middleware成功改写了Request。
3、process_spider_input和process_spider_output
除了改写start_request,我们还可以对Response和Item进行改写,比如对Response进行改写,我们可以尝试更改其状态码,在CustomizeMiddleware里面增加如下定义:

这里我们定义了process_spider_input和process_spider_output方法,分别来处理Spider的输入和输出。对于process_spider_input方法来说,输入自然就是Response对象,所以第一个参数就是response,我们在这里直接修改了状态码。对于process_spider_output方法来说,输出就是Request或Item了,但是这里二者是混合在一起的,作为result参数传递过来。result是一个可迭代的对象,我们遍历了result,然后判断了每个元素的类型,在这里使用isinstance方法进行判定:如果i是DemoItem类型,就把它的origin属性设置为空。当然这里可以针对Request类型做类似的处理,此处略去。
另外在parse方法里面添加Response状态码的输出结果:
重新运行一下Spider,可以看到输出结果类似下面这样:

可以看到,状态码变成了201,Item的origin字段变成了None,证明CustomizeMiddleware对Spider输入的Response和输出的Item都实现了处理。
到这里,我们通过自定义Spider Middleware的方式,实现了对Spider输入的Response以及输出的Request和Item的处理。
四、内置Spider Middleware简介
在这里我们再介绍一些scrapy框架中内置的Spider Middleware。
1、HttpErrorMiddleware
HttpErrorMiddleware的主要作用是过滤我们需要忽略的Response,比如状态码为200~299的会处理,500以上的不会处理。其核心实现代码如下:
def init_ (self,settings):
self.handle httpstatus all = settings.getboo1('HTTPERROR ALLOW ALL')
self.handle httpstatus list = settings.getlist('HTTPERROR ALLOWED CODES')
def process spider input(self,response,spider):
if 200 <= response.status< 300:
return
meta=response.meta
if'handle httpstatus all' in meta:
return
if'handle httpstatus list'in meta:
allowed statuses = meta["handle httpstatus list']
elif self.handle httpstatus all:
return
else:
allowed statuses = getattr(spider, "handle httpstatus list', self.handle httpstatus list)
if response.status in allowed statuses:
return
raise HttpError(response,'Ignoring non-200 response')可以看到它实现了process_spider_input 方法,然后判断了状态码为200~299就直接返回,否则会根据handle_httpstatus_all 和 handle_httpstatus_list 来进行处理。例如状态码在 handle_httpstatus_list定义的范围内,就会直接处理,否则抛出HttpError 异常。这也解释了为什么刚才我们把 Response的状态码修改为 201却依然能被正常处理的原因,如果我们修改为非 200~299 的状态码,就会抛出异常了。
另外,如果想要针对一些错误类型的状态码进行处理,可以修改Spider的 handle_httpstatus_list属性,也可以修改 Request meta 的 handle_httpstatus_list 属性,还可以修改全局 setttings中的HTTPERROR_ALLOWED_CODES。
比如我们想要处理404状态码,可以进行如下设置:
2、OffsiteMiddleware
0ffsiteMiddleware的主要作用是过滤不符合 allowed_domains 的 Request,Spider 里面定义的allowed_domains其实就是在这个Spider Middleware 里生效的。其核心代码实现如下:
def process spider output(self,response,result,spider):
for xin result:
if isinstance(x,Request):
if x.dont_filter or self.should follow(x,spider):
yield x
else:
domain=urlparse cached(x).hostname
if domain and domain not in selfdomains seen:
self.domains seen.add(domain)
logger.debug(
"Filtered offsite request to %(domain)r:%(request)s"
{'domain': domain,'request': x},extra={'spider': spider})
self.stats.inc value('offsite/domains,spider=spider)
self.stats.inc value('offsite/filtered,spider=spider)
else:
yield x可以看到,这里首先遍历了 result,然后判断了 Request 类型的元素并赋值为 X。然后根据x 的dont_filter、url和Spider 的 allowed_domains 进行了过滤,如果不符合 allowed domains,就直接输出日志并不再返回Request,只有符合要求的Request才会被返回并继续调用。
3、UrlLengthMiddleware
UrlLengthMiddleware 的主要作用是根据 Request 的URL长度对 Request 进行过滤,如果URL的长度过长,此Request就会被忽略。其核心代码实现如下:
@classmethod
def from settings(cls,settings):
maxlength= settings.getint('URLLENGTH LIMIT')
def process spider output(self,response,result, spider):
def filter(request):
if isinstance(request,Request) and len(request.url) > self.maxlength:
logger.debug("Ignoring link (url length >%(maxlength)d): %(url)s",
{maxlength':self.maxlength,'url': request.url},
extra={'spider':spider})
return False
else:
return True
return (r for r in result or () if _filter(r)) 可以看到,这里利用了process_spider_output对result里面的Request进行过滤,如果是Request类型并且URL长度超过最大限制,就会被过滤。我们可以从中了解到,如果想要根据URL的长度进行过滤,可以设置URLLENGTH LIMIT。
比如我们只想爬取 URL长度小于 50 的页面,那么就可以进行如下设置:

可见 Spider Middleware 能够非常灵活地对 Spider 的输人和输出进行处理,内置的一些 Spider Middleware在某此场景下也发挥了重要作用。另外,还有一些其他的内置 Spider Middleware,就不在此一一赘述了。
本节介绍了 Spider Middleware 的基本原理和自定义 Spider Middleware 的方法,在必要的情况下我们可以利用它来对 Spider 的输人和输出进行处理,在某些场景下还是很有用的。在这里关于Spider Middleware到这里就结束了,对于Spider Middleware的学习建议是多看使用方法,再对内置方法进行深入理解......

 浙公网安备 33010602011771号
浙公网安备 33010602011771号