scrapy爬虫框架(三)Spider的使用
在前面已经简单介绍了spider的基础用法,那么今天我们来详细了解一下Spider的具体用法。
一、Spider的运行流程
spider是scrapy框架中最核心的组件,其定义了爬取网站的逻辑和解析方式,而spider主要做两件事情:
- 定义爬取网站的动作。
- 分析爬取下来的网页。
那么他的运行流程主要有以下四点:
(1)以初始的URL初始化Request并设置回调方法。当该Request成功请求并返回时,将生成Response并将其作为参数传给该回调方法。
(2)在回调方法内分析返回的网页内容。返回结果可以有两种形式,一种是将解析到的有效结果返回字典或Item对象,下一步可直接保存或者经过处理后保存;另一种是解析的下一个(如下一页)链接,可以利用此链接构造Request并设置新的回调方法,返回Request。
(3)如果返回的是字典或Item对象,可通过Feed Exports等形式存入文件,如果设置了Pipline,可以经由Pipeline处理(如过滤、修正等)并保存。
(4)如果返回的是Request,那么Request执行成功得到Response之后会再次传递给Request中定义的回调方法,可以再次使用选择器来分析新得到的网页内容,并根据分析的数据生成Item。
循环进行以上几步,便完成了站点的爬取。
二、Spider类分析
在之前我们有讲到Spider类继承自scrapy.Spider类,这个类里提供了start_requests方法的默认实现,首先读取并请求start_urls属性,然后根据返回的结果调用parse方法解析结果。还有一些其他重要的属性,我们来详细了解一下:
name:爬虫名称,是定义Spider名字的字符串。Spider的名字定义了Scrapy如何定位并初始化Spider,所以它必须是唯一的。不过我们可以生成多个相同的Spider示例,这灭有任何限制。name是Spider最重要的属性,而且是必须的。如果该Spider爬取单个网站,一个常见的作法是以该网站的域名名称来命名Spider。例如Spider爬取baidu.com,该Spider通常会被命名为baidu。
allowed_domains:允许爬取的域名,是一个可选的配置,不在此范围的链接不会被跟进爬取。
start_urls:起始URL列表,当我们没有实现start_requests方法时,默认会从这个列表开始抓取。
custom_settings:一个字典,是专属于本Spider的配置,此设置会覆盖项目全局的设置,而且此设置必须在初始化前被跟新,所以它必须定义成类变量。
crawler:此属性是由from_crawler方法设置的,代表的是本Spider类对应的Crawler对象,Crawler对象中包含了很多项目组件,利用它我们可以获取项目的一些配置信息,常见的就是获取项目的设置信息,即Settings。
settings:一个Settings对象,利用它我们可以直接获取项目的全局设置变量。除了一些基础属性,Spider还有一些常用的方法,在此介绍如下。
start_requests:此方法用于生成初始请求,它必须返回一个可迭代对象,此方法会默认使用start_urls里面的URL来构造Request,而且Request是GET请求方式。如果我们想在启动时以POST方式访问某个站点,可以直接重写这个方法,发送POST请求时我们使用FormRequest即可。
parse:当Response没有指定回调方法时,该方法会默认被调用,它负责处理Response,并从中提取想要的数据和下一步的请求,然后返回。该方法需要返回一个包含Request或Item的可迭代对象。
closed:当Spider关闭时,该方法会被调用,这里一般会定义释放资源的一些操作或其他收尾操作。
三、实例演示
1、创建文件
接下来我们来实操以下spider的一些基本用法。首先我们需要创建一个Scrapy项目,名字叫做scrapy_demo。
- scrapy startproject scrapy_demo
这样就创建好了我们的scrapy_demo文件,我们再cd到文件该中,我们以www.httpbin.org这个网站为例,创建一个spider类。
- scrapy genspider httpbin www.httpbin.org
这时会生成一个httpbinSpider,内容如下:
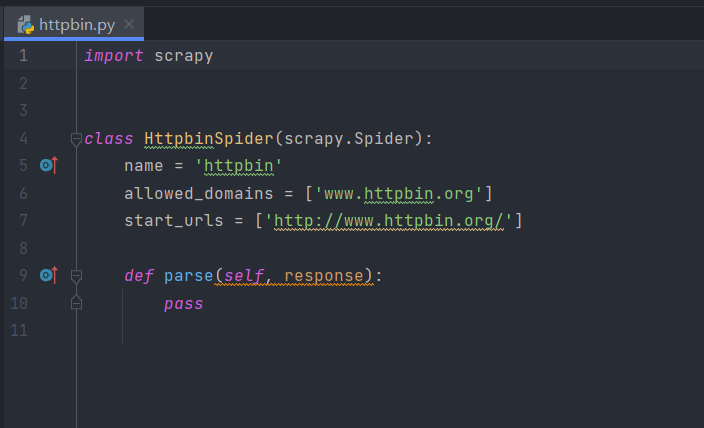
2、查看spider基础用法
我们先试着打印一些信息,那么我们需要试着修改一下parse中的内容。先将start_urls修改为http://www.httpbin.org/get。这个链接返回GET请求的一些详情信息,修改内容具体如下:
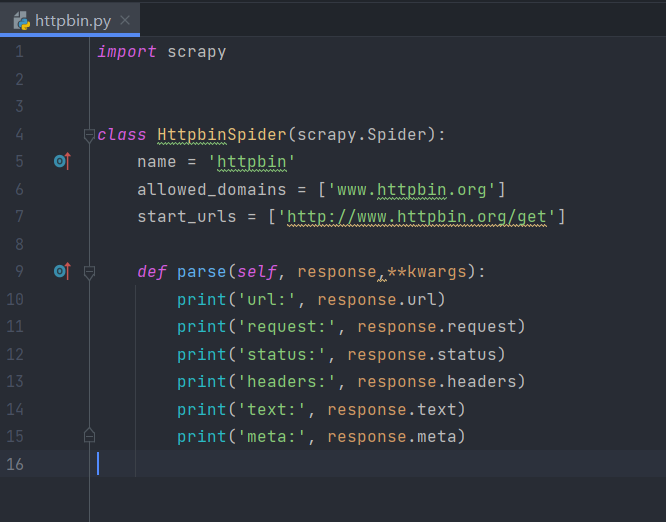
在这里,我们打印了response的多个属性。
- url:请求页面URL,即RequestURL。
- request:response对应的request对象。
- status:状态码,即Response Status Code。
- headers:响应头,即Response Headers。
- text:响应体,即Response Body。
- meta:一些附加信息,这些参数往往会附在meta属性里。
输入scrapy crawl httpbin 运行spider,结果如下:
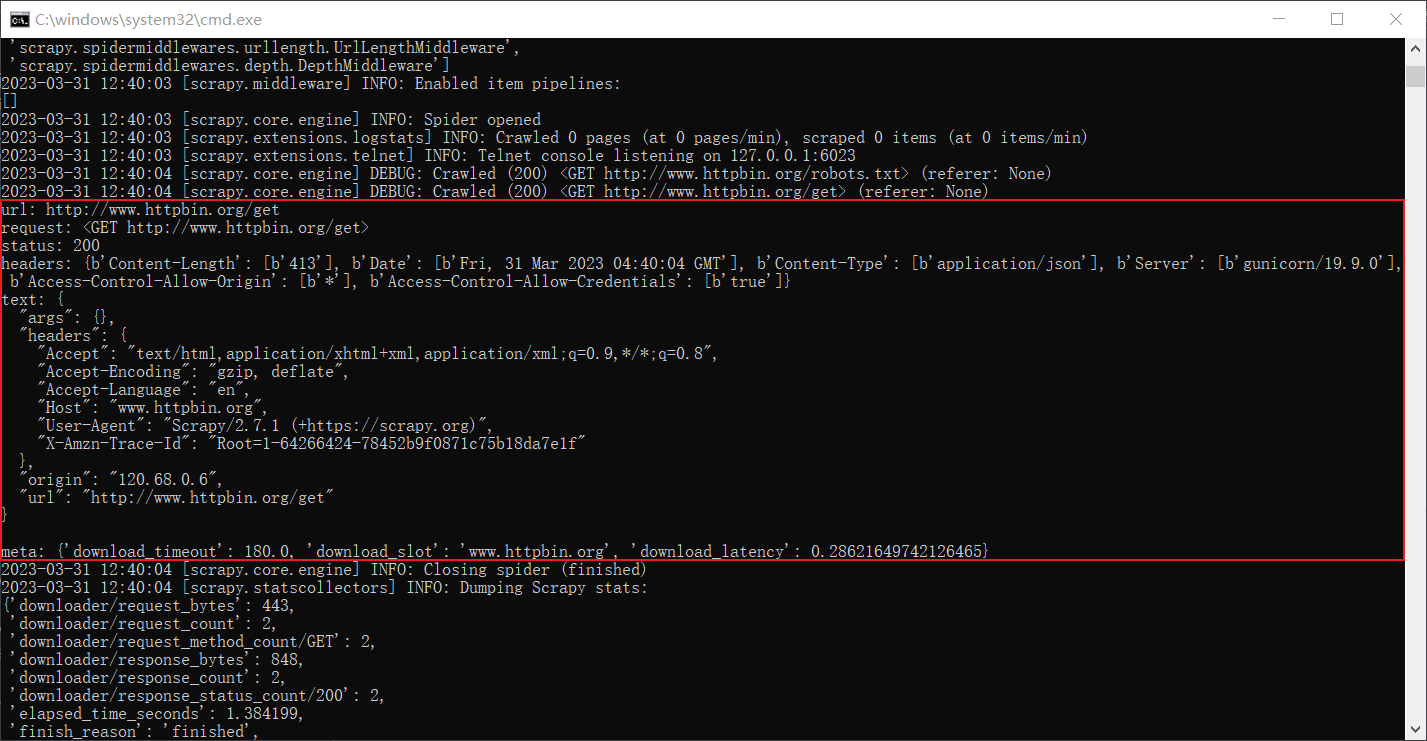
可以看到,这里分别打印输出了url、request、status、headers、text、meta信息,可以看出来text内容中包含了我们请求所使用的User-Agent、请求IP等信息。meta中包含了几个默认设置的参数。
3、start_requests()
在scrapy框架中并没有直接显示出初始请求函数的用法,但其默认为我们实现了一个start_requests方法,具体代码如下:
def start_requests(self):
for url in self.start_urls:
yield scrapy.Request(url, dont_filter=True)可以看到,逻辑就是读取start_urls然后生成Request,这里并没有为Request指定callback,默认就是parse方法。他是一个生成器,返回的所有Request都会作为初始Request加入调度队列。
因此,如果我们想要自定义初始请求,就可以在Spider中重写start_requests方法,比如我们想自定义请求页面链接和回调方法,可以把start_request方法修改为下面这样:
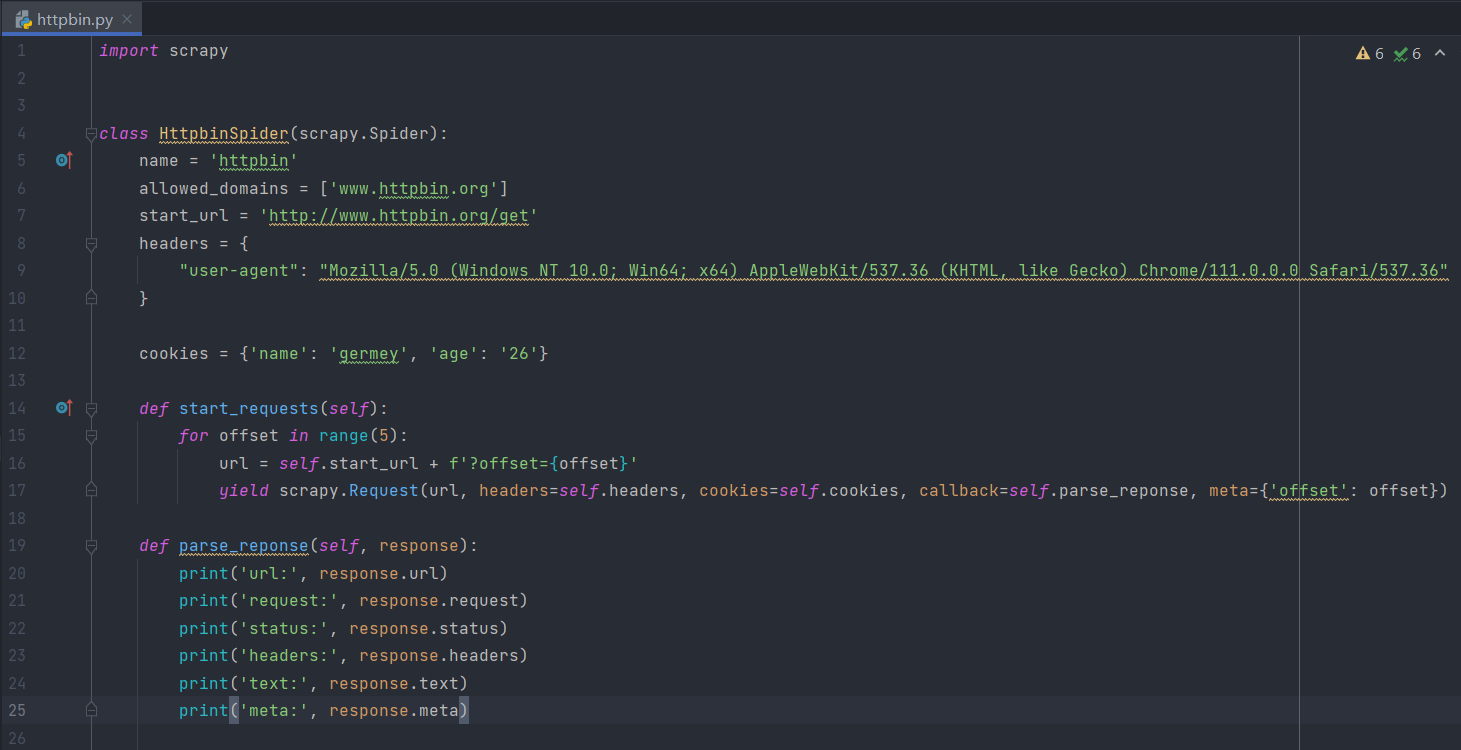
这里自定义了如下内容:
- url:我们不再依赖start_urls生成url,而是声明了一个start_url,然后利用循环给URL加上Query参数,如offset=0,拼接到https://www.httpbin.org/get后面,这样请求的链接就变成了https://www.httpbin.org/get?offset=0。
- headers:这里我们还声明了headers变量,为它添加了User-Agent属性并将其传递给Request的headers参数进行赋值。
- cookies:另外我们还声明了Cookie,以一个字典的形式声明,然后传给Request的cookies参数。
- callback:在HttpbinSpider中,我们声明了一个parse_response方法,同时我们也将Request的callback参数设置为parse_response,这样当该Request请求成功时就会回调parse_response方法进行处理。
- meta:meta参数可以用来传递额外参数,这样我们将offset的值也赋值给Request,通过response.meta就能获取这样的内容了,这样就实现了Request到Response的额外信息传递。
重新运行看看效果,输出如下内容:
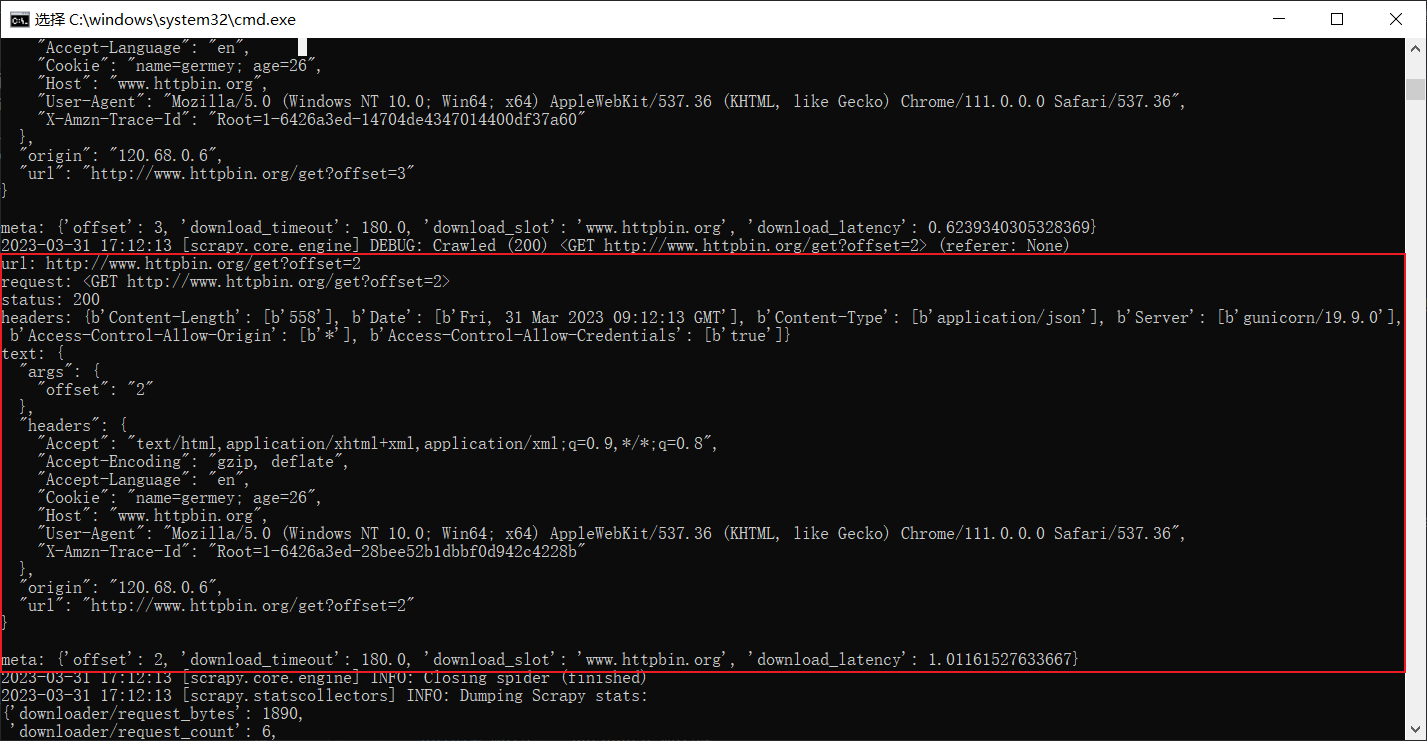
从上图中,可以看出我们相应的设置成功了。
- url:url上多了我们添加的Query参数。
- text:结果的headers可以看到Cookie和User-Agent,说明Request的Cookie和User-Agent都设置成功了。
- meta:meta中看到了offset这个参数,说明通过meta可以成功传递额外的参数。
4、POST请求
通过上面的案例,我们了解了Spider基本的流程和配置,但以上都是GET请求方式,那么如何进行POST请求呢?
其实不然,在scrapy框架中POST请求主要有两种方式:
- 一种是以Form Data的形式提交表单
- 一种是发送JSON数据。
以上两种方式分别可以使用FormRequest和JsonRequest来实现。但现在JsonRequest仿佛不能实现了,所以我们通过json库转换成json对象进行传递。即我们可以发起两种POST请求,对比一下结果,代码如下:
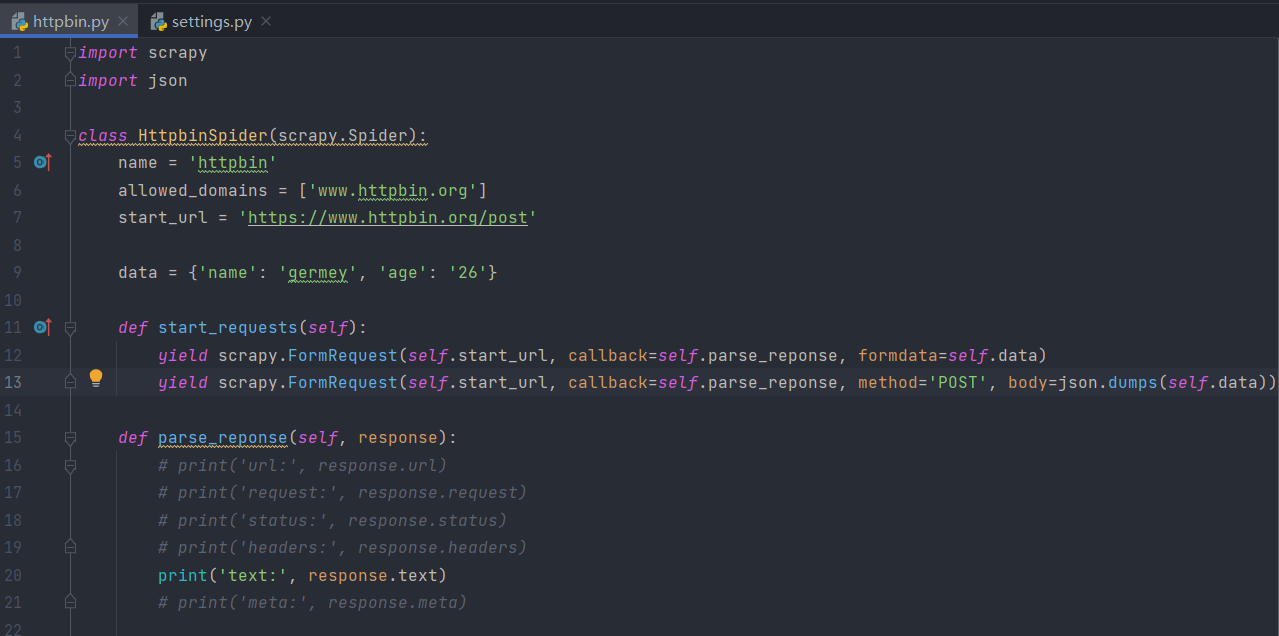
结果如下所示:
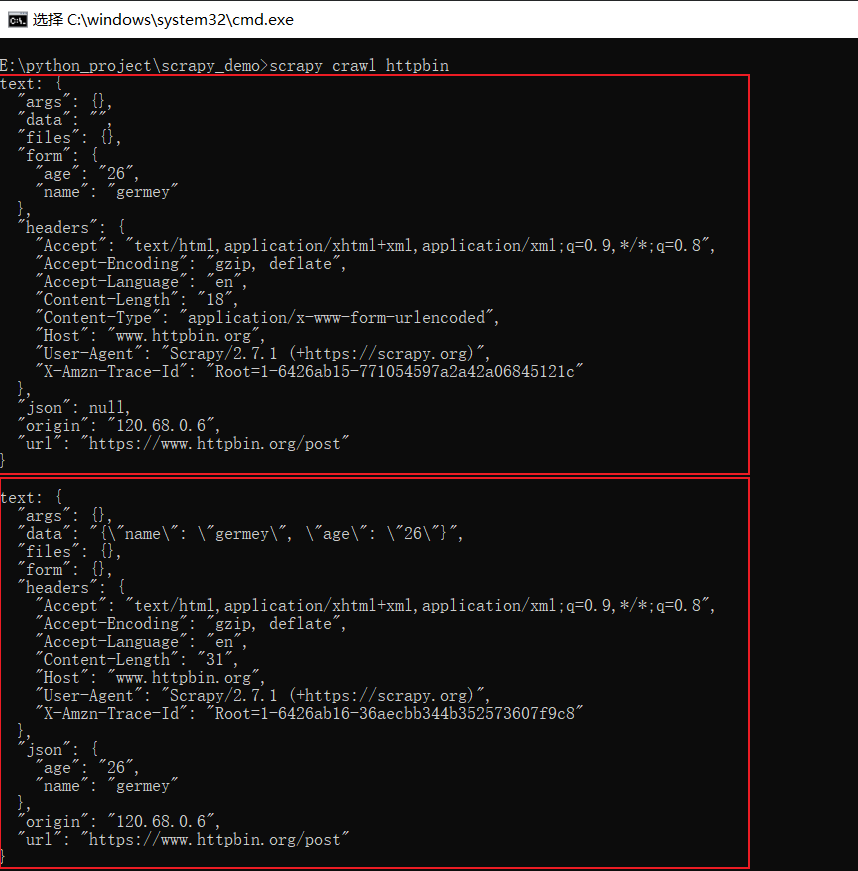
从上图中可以看出,两种请求的效果。
第一种Form Data。我们可以观察到页面返回结果的form字段就是我们请求时添加的data内容,这说明实际上是发送了Content-Type为application/x-www-form-urlencoded的POST请求,这种对应的表单提交。
第二种Json数据。我们可以看到页面返回结果的json字段就是我们所请求时添加的data内容,这说明实际上是发送了Content-Type为application/json的POST请求,这种对应的就是发送JSON数据。
对于这两种POST请求方式的运用,需要我们区分清除POST请求的发送方式,并根据服务器的实际需要进行选择。
四、Request和Response
通过上面的案例,我们已经可以掌握了一些Request和Response的基础用法。接下来,我们详细了解一下他们的用法和参数吧。
1、Request
在scrapy中,Request对象实际指的是scrapy.http.Request的一个实例。它包含了HTTP请求的基本信息,用则会个Request类我们可以构造Request对象发送HTTP请求,它会被Engine交给Downloader进行处理执行,返回一个Response对象。
但是这个Request类怎么使用呢?我们先来了解一下他的构造参数都有哪些:
- url:Request的页面链接,即Request URL。
- callback:Request的回调方法,通常这个方法需要定义在Spider类里面,并且需要对应一个response参数,代表Request执行请求后得到的Response对象。如果这个callback参数不指定,默认参数会使用Spider类里面的parse方法。
- method:Request的方法,默认是GET,还可以设置为POST、PUT、DELETE等。
- meta:Request请求携带的额外参数,利用meta,我们可以指定任意处理参数,特定的参数经由Scrapy各个组件的处理,可以得到不同的效果。另外,meta还可以用来向回调方法传递信息。
- body:Request的内容,即Request Body,往往Request Body对应的是POST请求,我们可以使用FormRequest或JsonRequest更方便地实现POST请求。
- headers:Request Headers,是字典形式。
- cookies:Request携带的Cookie,可以是字典或列表形式。
- encoding:Request的编码,默认是utf-8。
- prority:Request优先级,默认是0,这个优先级是给Scheduler做Request调度使用的,数值越大,就越被优先调度并执行。
- dont_filter:Request不去重,Scrapy默认会根据Request的信息进行去重,使得在爬取过程中不会出现重复请求,设置为True代表这个Request会被忽略去重操作,默认是False。
- errback:错误处理方法,如果在请求处理过程中出现了错误,这个方法就会被调用。
- flags:请求的标志,可以用于记录类似的处理。
- cb_kwargs:回调方法的额外参数,可以作为字典传递。
以上便是Request的构造参数,利用这些参数,我们可以灵活地实现Request的构造。
Ps:meta参数是一个十分有用而且易扩展的参数,它可以以字典的形式传递,包含的信息不受限制。所以很多Scrapy的插件会基于meta参数做一些特殊处理。在默认情况下,Scrapy就预留了一些特殊的Key作为特殊处理。
比如:request.meta['proxy']可以用来设置请求时使用的代理,request.meta['max_retry_times']可以设置用来设置请求的最大重试次数等。
2、Response
Request由Downloader执行之后,得到的就是Response结果了,它代表的是HTTP请求得到的响应结果,同样的我们可以来了解一下其可用的属性和方法,以便做解析处理使用。
- url:Request URL
- status:Response状态码,如果请求成功就是200.
- headers:Response Headers,是一个字典,字段是一一对应的。
- body:Response Body,这个通常就是访问页面之后得到的原代码结果了,比如里面包含的是HTML或者JSON字符串,但注意其结果是bytes类型。
- request:Request对应的Request对象。
- certificate:是twisted.internet.ssl.Certificate类型的对象,通常代表一个SSL证书对象。
- ip_address:是一个ipaddress.IPv4Address或ipaddress.IPv6Address类型的对象,代表服务器的IP地址。
- urljoin:是对URL的一个处理方法,可以传入当前页面的相对URL,该方法处理后返回的就是绝对URL。
- follow/follow_all:是一个根据URL来生成后续Request的方法,和直接构造Request不同的是,该方法接收的url可以相对URL,不必一定是绝对URL。
另外,Response还有几个常用的子类,如 TextResponse和HtmlResponse,HtmlResponse又是TextResponse的子类,实际上回调方法接受的response参数就是一个HtmlResponse对象,它还有几个常用的方法或属性。
- text:同body属性,但结果是str类型。
- encoding:Response的编码,默认是utf-8。
- selector:根据Response的内容构造而成的Selector对象,Selector在上一篇我们已经了解过了,利用它可以调用xpath、css等方法进行结果的提取。
- xpath:传入xpath进行内容提取,等同于调用selector的xpath方法。
- css:传入CSS选择器进行内容提取,等同于调用selector的css方法。
- json:是Scrapy2.2新增的方法,利用该方法可以直接将text属性转为JSON对象。
以上关于Response的介绍就结束了,而本节认识了spider的基本使用方法、Request和Response对象的基本数据结构,反复使用以上参数或方法,便可以灵活掌握scrapy的爬取数据的逻辑。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号