scrapy爬虫框架(一)入门介绍
在爬虫过程中,每次写一个爬虫程序时,都会从研究网页信息基本情况,所用到的库和方法。每次写基础代码时,都会略显繁琐。之前我也曾想过自己写一个基础的框架,从请求到响应再到解析和数据的保存。实现代码复用率,但发现其实并不用自己再造一遍轮子,因为市面上已经有了强大的异步框架--scrapy。我们只需要在此框架的基础上进行修改和添加相应的爬虫逻辑就可以了,那么我们今天就来先初始了解scrapy框架的大致内容及运行流程。
一、scrapy的架构
我们先来看一下scrapy框架的运行流程图:
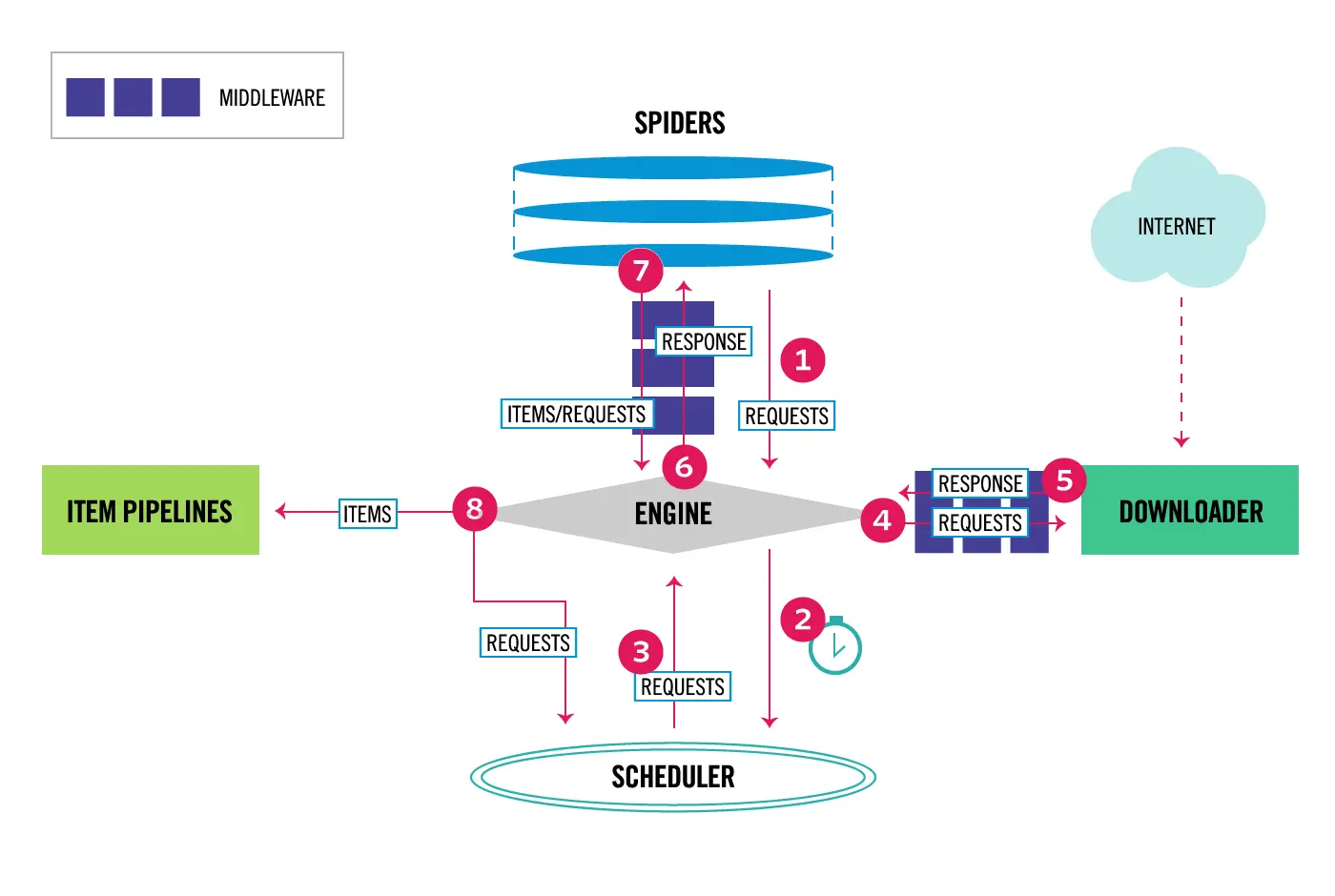
Engine:图中最核心的部分,中文称之为引擎,也可以理解为处理器。是用来处理整个系统的数据流和事件,是整个框架的核心。
- 作用:负责数据的流转和逻辑的处理。
Scheduler:图中下方的部分(步骤2-3),中文可以成为调度器,它用来接受Engine发过来的Request并将其加入队列中。同时如步骤三所示,将Request发回给Engine供Downloader执行。
- 作用:维护Request的调度逻辑及顺序,比如:先进先出、先进后出、优先级进出等等。
Downloader:图中右侧部分(步骤4-5),中文称为下载器。通过对Engine传过来的请求,进行具体执行。
- 作用:Request请求给到Downloader,其负责向服务器发送请求,拿到服务器返回的响应结果,再发送给Engine进行处理。
Spiders:图中最上方的部分(步骤1、6-7),中文成为蜘蛛,Spiders是一个复数统称,其可以对应多个Spider,每个spider里面定义了站点的爬取逻辑和页面的解析规则。
- 作用:定义爬虫逻辑和规则,解析响应并生成Item和新的请求,然后发送给Engine进行处理。
Item Pipelines:图中左侧部分(步骤8),中文可以称之为项目管道,这也是一个复数统称,代表不仅仅是一个,可以对应多个item Pipeline。
- 作用:Item Pipeline主要负责处理由Spider从页面中抽取的Item,做一些数据清洗、验证和存储的工作,如将Item的某些字段进行规整,将Item存储到数据库等操作都可以由Item Pipeline来完成。
除了这五大组件之外还有两个较为特殊的中间件:
Downloader Middlewares:图中Engine和Downloader之间的方块部分,中文成为下载器中间件。同样其也是复数统称,包含多个Downloader Middleware,它是位于Engine和Downloader之间的Hook框架。
- 作用:负责实现Downloader和Engine之间的请求和响应的处理过程。如ua伪装、ip代理池的实现都可以在这构建。
Spider Middlewares:图中Engine和Spiders之间的方块部分,中文称之为蜘蛛中间件,同时他也是位于Engine和Spiders之间的Hook框架。
- 作用:负责实现Spiders和Engine之间的Item、请求和响应的处理过程。
以上便是scrapy框架所有的核心组件,下面我们来看一下scrapy框架运行的流程。
二、scrapy框架的运行流程
通过上图可以看出来Engine是scrapy框架的核心,所有的步骤都经过Engine的调度。而数据的流通则经过Spider、Downloader和item三个组件。那么我们来看一下数据的具体流通过程是怎么样的。
(1)启动爬虫。首先,启动爬虫项目时,Engine会先根据创建项目所提供的目标站点找到处理该站点的Spider,Spider会生成最初需要爬取的页面对应的一个或多个Request请求,然后发送到Engine。
(2)队列调度。其次,Engine会将Request请求发送给Scheduler进行队列请求的排序。之后,Engine向Scheduler索取下一个所要处理的Request,这时候Scheduler根据其调度逻辑选择合适的Request发送给Engine。
(3)执行下载。然后,Engine将Scheduelr发来的Request发送给Downloader进行下载执行,但是,在Request发送给Downloader的过程中会经过定义好的Downloder Middlewares进行处理(请求伪装)。
(4)请求响应。再则,Downloader将Request发送给目标服务器,得到对应的Response,然后将其返回给Engine。同上,在返回的过程中会经过许多定义好的Downloder Middlewares处理。
(5)传递响应。然后,Engine从Downloader处收到的Reponse里包含了许多爬取的目标站点内容。Engine会将此Response发送给对应的Spider进行处理。同样,在将response发送给Spider的过程中会经由定义好的Spider Middlewares进行处理。
(6)解析响应。Spider处理Response,解析Response内容,这时候Spider会产生一个或多个爬取结果Item,或者后续要爬取的目标页面对应的一个或多个Request,然后再将这些Item或Request发送给Engine进行处理。将Item或Request发送给Engine的过程会经由定义好的Spider Middlewares的处理。
(7)保存数据,返回请求。Engine将Spider发回的一个或多个Item转发给定义好的Item Pipelines进行数据处理或存储的一系列操作,将Spider发回的一个或多个Request转发给Scheduler等待下一次被调度。再重复第(2)步到第(7)步,直到Scheduler中没有更多的Request,这时候Engine会关闭Spider,整个爬取过程结束。
以上就是scrapy框架的运行流程了,纵观scrapy框架,Spiders、Scheduler、Item、Downloader这些组件互不相关,但经由Engine的调度管理,使得每个组件各司其职,互相配合,共同完成爬取工作。再加上scrapy对异步处理的支持,scrapy可以最大限度地利用网络带宽,提高数据爬取和处理地效率。
三、scrapy的创建及简单运行
主要命令:
scrapy下载命令:pip install scrapy
scrapy框架创建命令:scrapy startproject 项目名
scrapy框架中创建spider的命令(即创建抓取指定目标):scrapy genspider 爬虫名 目标网站域名
scrapy框架的启动命令:scrapy crawl 爬虫名
1、创建项目
首先,我们需要在指定的目录下创建我们需要的scrapy框架文件,将百度作为目标网站为例,创建命令如下:
- scrapy startproject baidu_spider
我们在此创建了一个scrapy文件,文件下会生成多个子文件,如下:
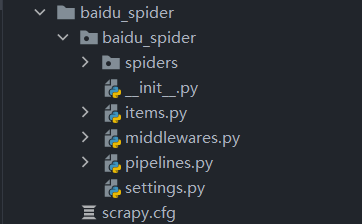
接下来,我们还需要创建一个执行爬虫逻辑的spider文件。
首先,cd到baidu_spider文件中,然后,执行以下语句:
- scrapy genspider baidu www.baidu.com
- 命令逻辑:scrapy + genspider + 爬虫文件名 + 爬虫目标域名
这样就成功的在spiders文件下成功的创建了一个名为baidu的爬虫文件
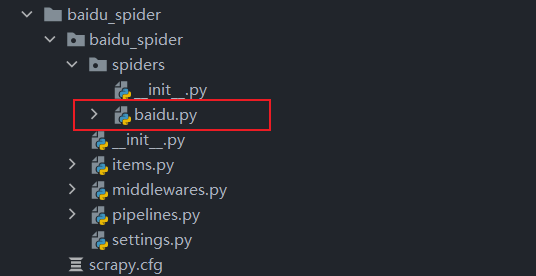
这样,关于scrapy框架的布置就完成了,那么接下来我们来看一下每个组件所蕴含的功能吧。
2、scrapy组件的功能
以下图为例

首先我们看一下主要的文件有scrapy.cfg、items.py、pipelines.py、settings.py、middlewares.py和spiders。
scrapy.cfg:Scrapy项目的配置文件,其中定义了项目的配置文件路径、部署信息等。
items.py:定义了Item数据结构,所有Item的定义都可以放在这里。
pipelines.py:定义了Item Pipeline的实现,所有的Item Pipeline的实现都可以放在这里。
setting.py:定义了项目的全局配置。
middlewares.py:定义了Spider Middlewares和Downloader Middlewares的实现。
spiders:里面包含了一个个的Spider的实现,每个Spider都对应一个Python文件。
3、组件内容简介
(1)spider.py
这里以baidu.py为例。当我们创建好一个spider后,就会出现这样的内容:
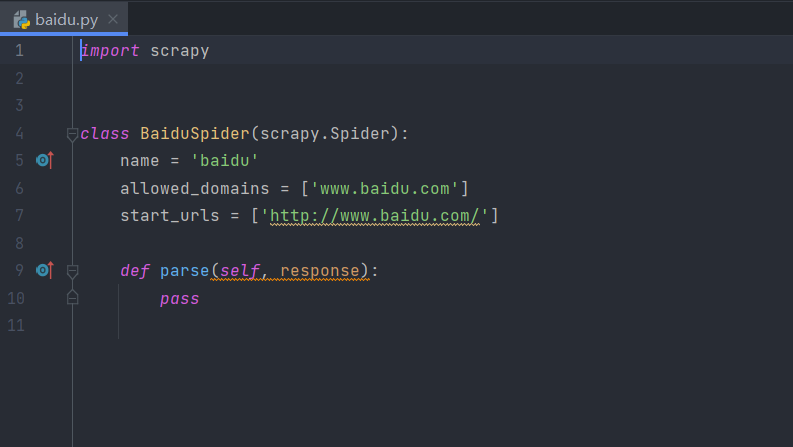
spider文件单独给我们定义了一个BaiduSpider的类,该类继承了Scrapy提供的Spider类scrapy.Spider,通常在该类中定义抓取数据的逻辑和规则。其中有三个属性:
- name:name是每一个项目唯一的名字,用来区分不同的Spider。
- allowed_domains:是允许爬取的域名,如果初始或后续的请求链接不是这个域名下的,则请求链接会被过滤掉。
- start_urls:包含了Spider在启动时爬取的URL列表,初始请求是由它来定义的。
- parse:是Spider的一个方法。在默认情况下,start_url里面的链接构成的请求完成下载后,parse方法就会被调用,返回的响应就会作为唯一的参数传递给parse方法。该方法负责解析返回的响应,提取数据或者进一步生成要处理的请求。
这些就是baidu.py文件的大致结构,值得注意的是,可以在parse方法中,传入不定长参数**kwargs(个人习惯),这样就看起来好多了。

(2)item.py
通过上面的讲述,可以了解到item的大致作用,没错,他是用来储存字段和数据的,也就是我们所说的爬取数据的容器。同样的它的使用方法和字典类似,不过相比于字典,Item多了额外的保护机制,可以避免拼写错误或者定义字段错误。具体如下所示:
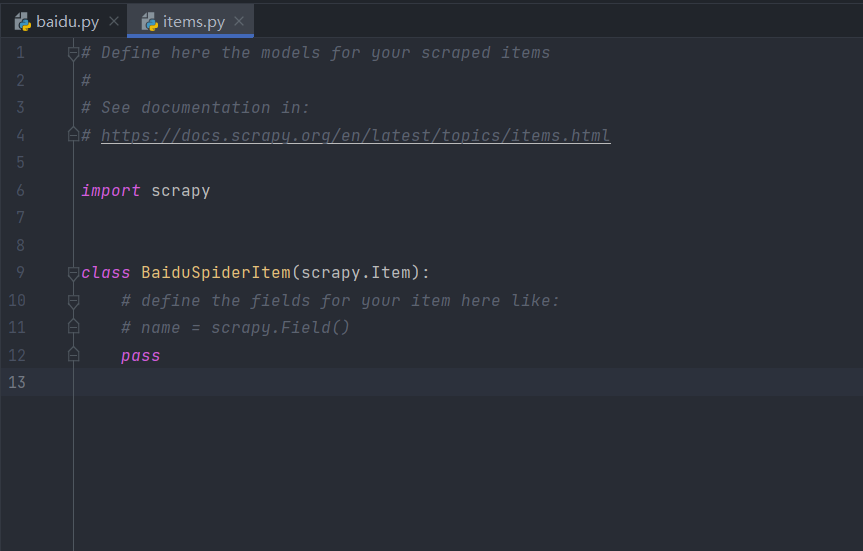
通过上面的items大致代码内容可以看到,创建Item需要继承scrapy的Item类,并且定义类型为Field的字段,这个字段就是我们要爬取的字段。
若我们要爬取网站的信息时,需要的所有字段名,只需要定义对应的Item就可以了,将items.py改成如下即可:
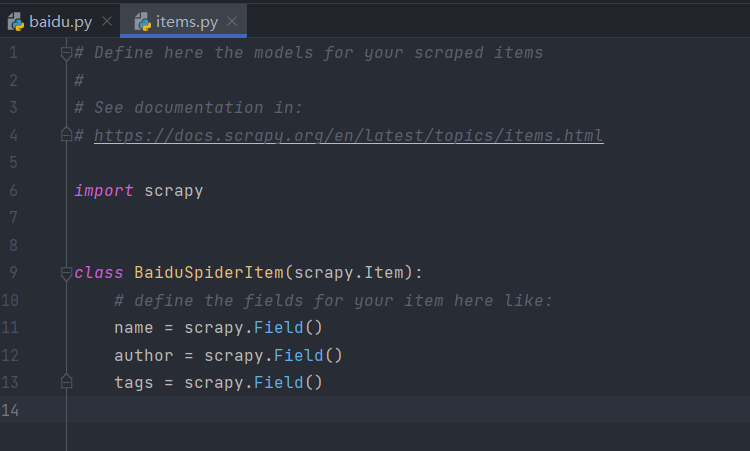
(3)pipelines.py
代码样式:
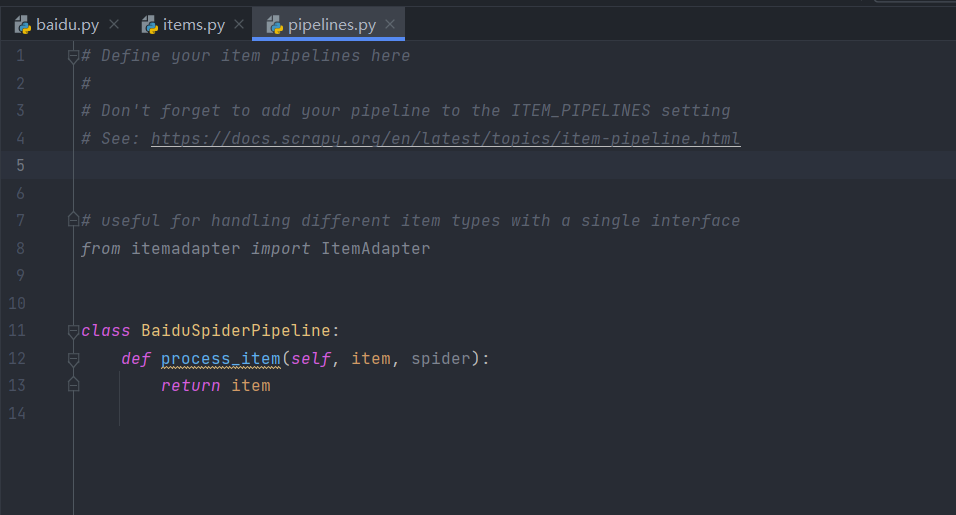
pipelines又常被称为item pipelines,即项目管道,当Item生成后,它会自动被送到Item Pipeline处进行处理,我们可以用Item Pipeline来做如下操作:
- 清洗HTML数据。
- 验证爬取数据,检查爬取字段。
- 查重并丢弃重复内容。
- 将爬取结果存储到数据库。
实现Item Pipeline很简单,只需要定义一个类并实现process_item方法即可。启用Item Pipeline后,Item Pipeline会自动调用这个方法。process_item方法必须返回包含数据的字典或Item对象,或者抛出DropItem异常。
process_item方法有两个参数,一个参数是item,每次Spider生成的Item都会作为参数传递过来,另一个参数是Spider,就是Spider实例。
下面通过自定义的链接MySQL数据库来定义一个完整保存数据至数据库的案例:
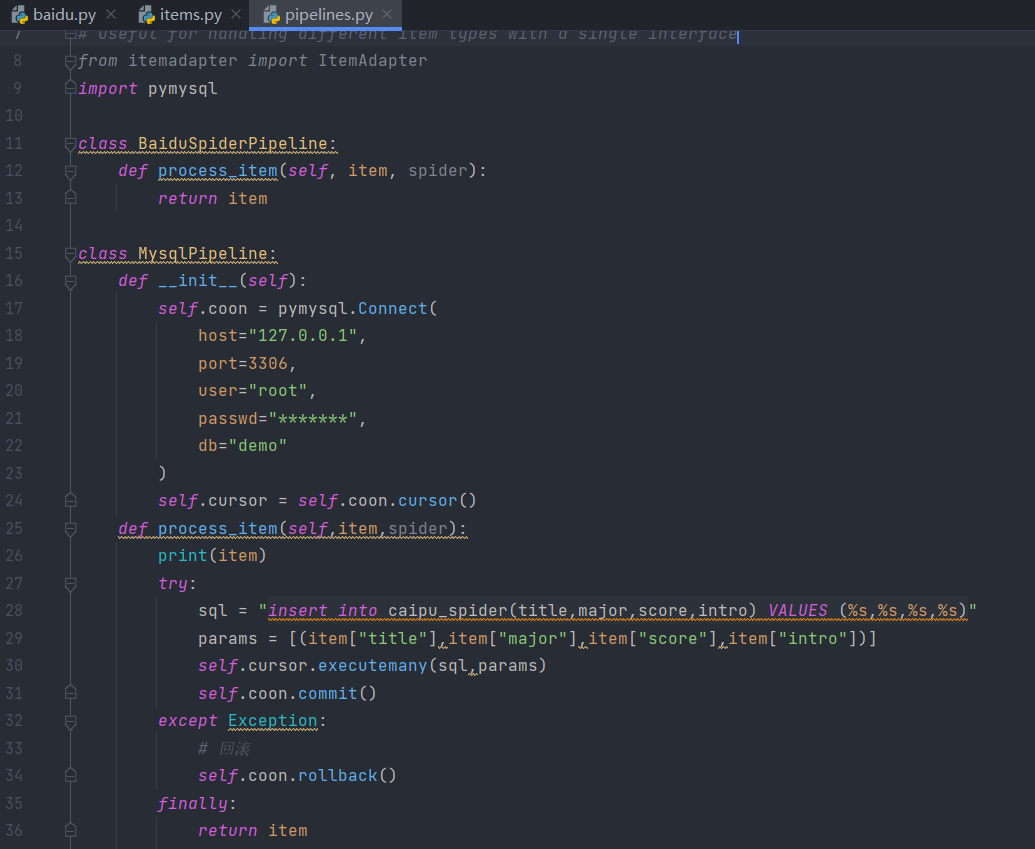
通过自定义MysqlPipeline类,在初始方法中连接数据库,在process_item方法中执行字符串插入数据库的语句,最后释放item。
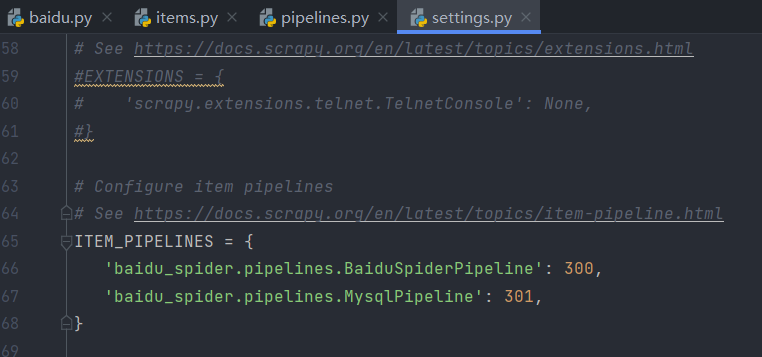
但是,如果想实现pipeline储存至数据库,还需要在setting.py文件中打开如下设置,并设置优先级,才可保存至数据库。
其中前面代表管道,后面代表优先级,数字越小,优先级越高。
四、保存到文件
运行完 Scrapy后,我们只在控制台上看到了输出结果。如果想保存结果该怎么办呢?
要完成这个任务其实不需要任何额外的代码,Scrapy 提供的 Feed Exports 可以轻松将抓取结果输出。
1、Json文件
如果我们想将上面的结果保存成JSON 文件,这里的将爬虫名定义为quotes为例。那么可以执行如下命令:
- scrapy crawl quotes -o quotes.json
命令运行后,项目内多了一个quotes,json文件,文件包含了刚才抓取的所有内容,内容是JSON格式。
另外我们还可以让每一个Item 输出一行JSON,输出后缀为jl为jsonline 的缩写,命令如下所示:
- scrapy crawl quotes -o quotes.jl
或者
- scrapy crawl quotes -o quotes.jsonlines
2、其他常用类型的文件
FeedExports支持从输出格式还有很多,例如csv、xml、pickle marshal等,同时它支持ps3等远程输出,另外还可以通过自定义ItemExporter 来实现其他的输出。
下面命令对应的输出分别为csv、xml、pickle、marshal格式以及ftp远程输出:例如:
- scrapy crawl quotes -o quotes.csv
- scrapy crawl quotes -o quotes.xml
- scrapy crawl quotes -o quotes.pickle
- scrapy crawl quotes -o quotes.marshal
- scrapy crawl quotes -o ftp://user:pass@ftp.example.com/path/to/quotes.csv
其中,ftp输出需要正确配置用户名、密码、地址、输出路径,否则会报错,通过Scrapy提供的 Feed Exports,我们可以轻松地将抓取结果到输出到文件中。对于一些小型项目来说,这应该足够了
如果想要更复杂的输出,如输出到数据库等,我们可以使用Item Pileline 来完成,我们后面会提到Item Pipeline的使用。
在这里,对于scrapy框架的简单入门了解就结束了,后续会继续更新相关组件的使用方法。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号