scrapy框架图片爬取案例——以堆糖网为例
本节主要分享的是scrapy框架中关于图片类的简单爬取方法,在这里只需要用到三个文件:
1.setting.py进行scrapy抓取图片所用到的基础。
2.duitang_spider.py实现获取多出url进行翻页和数据处理。
3.pipelines.py对图片链家发起请求获取,设置图片名称,然后在管道中保存图片。
一、scrapy基础设置
- scrapy文件框架概览

(1)setting设置
1.robots协议
ROBOTSTXT_OBEY = False2.日志设置
LOG_LEVEL="ERROR"3.添加user-agent
USER_AGENT = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/110.0.0.0 Safari/537.36'4.管道
- 打开管道,后面对图片链接的保存、图片名设置会用到。
ITEM_PIPELINES = {
'duitang.pipelines.DuitangPipeline': 300,
'duitang.pipelines.ImagePipeline': 301,
}5.文件夹创建
IMAGES_STORE="./图片"(2)items设置
- 在后续保存进item字典数据时会用到,在这里我们进行图片链接抓取所以只设置一个数据就可以了。
href = scrapy.Field()二、基本代码实现
(1)duitang_spider.py
由于观察到堆糖网的数据都是Ajax加载,添加参数即可实现。
1.基础url设置
- 堆糖链接是需要参数的,我们这里先把参数去掉,在后面循环添加进行翻页。
class DuitangSpiderSpider(scrapy.Spider):
name = 'duitang_spider'
allowed_domains = ['www.duitang.com']
image_page="https://www.duitang.com/napi/blogv2/list/by_search/?"
start_urls = ['https://www.duitang.com/search/?kw=%E7%BE%8E%E5%A5%B3&type=feed']- 爬取前20页数据
- 这里观察到只有“after_id”参数在变,规律是递增乘以24。所以在这里直接循环添加就可以了。
def parse(self, response,**kwargs): for num in range(20): data={ "kw": "美女", "after_id": num*24, "type": "feed", "include_fields": 'top_comments,is_root, source_link, item, buyable, root_id, status, like_count, like_id, sender, album, reply_count, favorite_blog_id', "_type":"", "_": "1677407450111", } url=self.image_page+urlencode(data) yield scrapy.Request(url=url,callback=self.get_data)
2.数据抓取
- 将url返回后交给self.get_data函数进行数据抓取
- 先将数据转为json字符串,再进行循环传入。
def get_data(self,response): data_list=json.loads(response.text)["data"]["object_list"] for data in data_list: item=DuitangItem() item["href"]=data["photo"]["path"] yield item - 到这里就duitang_spider.py就结束了,剩下的交给管道进行保存就可以了。完整duitang_spider.py代码如下:
import scrapy import json from urllib.parse import urlencode from duitang.items import DuitangItem class DuitangSpiderSpider(scrapy.Spider): name = 'duitang_spider' allowed_domains = ['www.duitang.com'] image_page="https://www.duitang.com/napi/blogv2/list/by_search/?" start_urls = ['https://www.duitang.com/search/?kw=%E7%BE%8E%E5%A5%B3&type=feed'] def parse(self, response,**kwargs): for num in range(20): data={ "kw": "美女", "after_id": num*24, "type": "feed", "include_fields": 'top_comments,is_root, source_link, item, buyable, root_id, status, like_count, like_id, sender, album, reply_count, favorite_blog_id', "_type":"", "_": "1677407450111", } url=self.image_page+urlencode(data) yield scrapy.Request(url=url,callback=self.get_data) def get_data(self,response): data_list=json.loads(response.text)["data"]["object_list"] for data in data_list: item=DuitangItem() item["href"]=data["photo"]["path"] yield item
(2)pipelines.py
- 先导入scrapy框架中关于图片数据处理的专用模块
-
from scrapy.pipelines.images import ImagesPipeline - 第一个默认类不用管它,让他返回item数据,交给专有的图片类处理
class DuitangPipeline: def process_item(self, item, spider): return item - 函数get_media_requests()的作用是将item中获取到的图片链接发起请求,并将获取到的数据转交给file_path函数处理。
class ImagePipeline(ImagesPipeline): def get_media_requests(self, item, info): yield scrapy.Request(item["href"]) - file_path函数 的作用是处理图片的命名方式,这里将图片链接中"/"符号后的后缀作为图片名进行保存,再将命名的名称返回。
def file_path(self, request, response=None, info=None, *, item=None): img_name=request.url.split("/")[-1] return img_name - item_completed函数是将item在ImagePipeline管道进行返回。(若不返回则其他管道则无法获取到item数据,也就无法进行数据库等数据保存方式)
def item_completed(self, results, item, info): print(item) return item - pipelines.py代码完整代码如下:
import scrapy from itemadapter import ItemAdapter from scrapy.pipelines.images import ImagesPipeline class DuitangPipeline: def process_item(self, item, spider): return item class ImagePipeline(ImagesPipeline): def get_media_requests(self, item, info): yield scrapy.Request(item["href"]) def file_path(self, request, response=None, info=None, *, item=None): img_name=request.url.split("/")[-1] return img_name def item_completed(self, results, item, info): print(item) return item - 由于之前已经在setting中设置好的图片保存路径,所以这里直接运行scrapy框架即可。
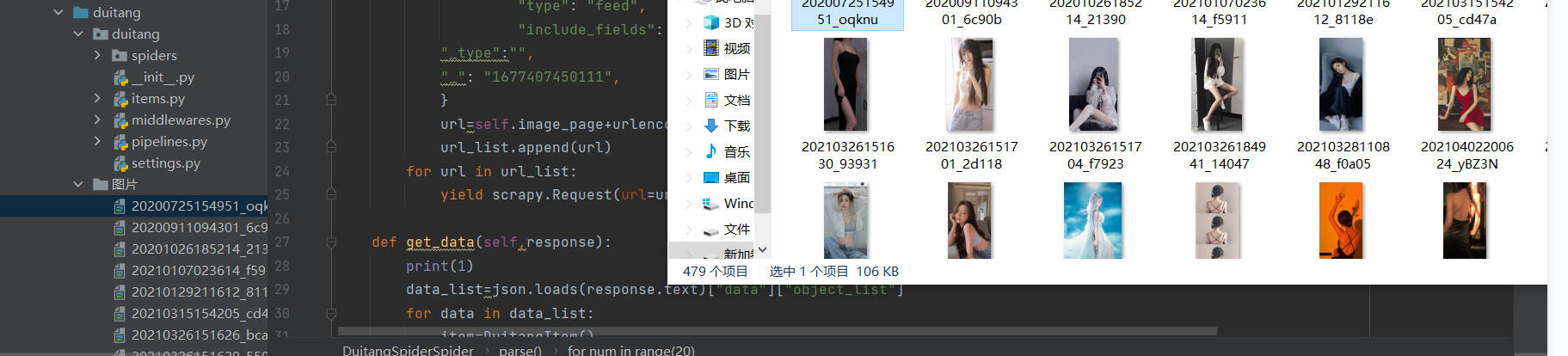
- 到这里,我们运用scrapy框架进行图片爬取就完成了。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号