爬虫笔记【1】如何爬取无HTTPS证书的网站?
在爬虫过程中遇到很多网页都多多少少会存在证书过期的情况,那么证书过期后,该网站会被认定为不安全网站,那么怎么进行正常的数据爬取呢?
主要从爬虫过程中常遇到的三个问题进行解决。
1、打开网页,检测出该网页连接不安全,但是想要直接访问怎么办?
- 原因:证书过期,或其他问题。
- 如图:
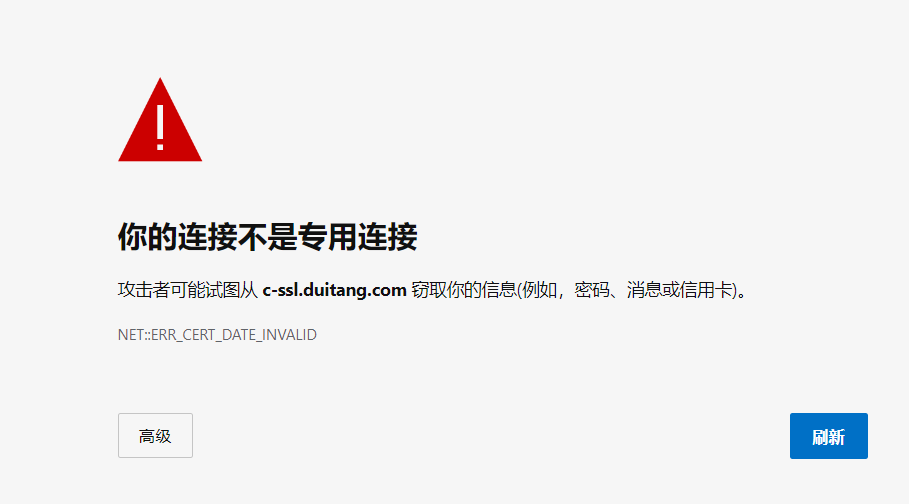
解决方案:在网页内直接键盘输入thisisunsafe,再按下回车键即可。
2、怎么在爬虫代码中解决证书验证的问题?
解决方案:
在requests中指定verify=False,这样进行爬取网页信息时,就不会进行证书验证了。
示例:
resp = requests.get(url,headers=self.headers,verify=False)3、在爬取数据时,可以正常爬取,但是会有不影响爬取数据的警告,怎么去掉这些警告呢?
解决方案:
在代码开头输入以下两行代码即可(使警告作废)。
import urllib3
urllib3.disable_warnings()这样就不会提示警告消息了。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号