认识requests
requests
- python中原生的一款基于网络请求的模块,功能强大,代码简便,效率极高。
- 作用:模拟浏览器发送请求。
注意:requests是第三方模块,使用时需要下载。
pip install requests- 若下载时出现超时,换源即可。
示例:
pip install requests -i https://pypi.tuna.tsinghua.edu.cn/simple/也可以从以下地址下载
# 阿里云 http://mirrors.aliyun.com/pypi/simple/
# 豆瓣http://pypi.douban.com/simple/
# 清华大学 https://pypi.tuna.tsinghua.edu.cn/simple/
# 中国科学技术大学 http://pypi.mirrors.ustc.edu.cn/simple/
# 华中科技大学http://pypi.hustunique.com/
一、发送请求
- 使用Requests发送网络请求非常简单,导入模块包之后添加方法进行即可。
import requests
resp = requests.get("url")
resp = requests.post("url")- requests请求内容格式主要有以下几类内容:
def request(url,params=None,headers=None,cookies=None,timeout=None,
allow_redirects=True,proxies=None,verify=None,data=None):
pass二、url-请求地址
- 通过向某一个地址发送请求,并获取到数据。
- url中文名叫统一资源定位符。
- 俗称:网址。
# https://www.baidu.com/s?wd=美女
import requests
url = "https://www.baidu.com/s?"
params = {
"wd":"美女"
}
resp = requests.get(url,params=params)
print(resp.url)三、params-请求参数
- 可将get请求的参数以字典的形式存放在params里面,发送请求时携带即可。
# https://www.baidu.com/s?wd=美女
import requests
url = "https://www.baidu.com/s?"
params = {
"wd":"美女"
}
resp = requests.get(url,params=params)
print(resp.url)
-----------------------------------------------
https://wappass.baidu.com/static/captcha/tuxing.html?&logid=11320769684884274402&ak=c27bbc89afca0463650ac9bde68ebe06&backurl=https%3A%2F%2Fwww.baidu.com%2Fs%3Fwd%3D%25E5%25B8%2585%25E5%2593%25A5&signature=afcf38ce749eb17b0462d6c90c1694ff×tamp=1666536248- 往params的字典里加入关键字,就像在百度输入框输入内容一样!
四、headers-请求头
- 如果想自定义请求的Headers,同样的将字典数据传递给headers参数。
- 作用:伪装。
import requests
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/104.0.0.0 Safari/537.36"
}
url = "https://www.baidu.com?"
resp = requests.get(url,headers=headers)
resp.encoding="utf-8"
print(resp.text)五、timeout-访问超时
- 设置访问超时,一旦超过设置时间,则会抛出异常。
import requests
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/104.0.0.0 Safari/537.36"
}
url = "https://www.baidu.com?"
resp = requests.get(url,headers=headers,timeout=0.01)
resp.encoding="utf-8"
print(resp.text)- 设置timeout,在规定时间内,如果没有响应完成,那么会进行报错。防止响应时间过长不能自动停止。
六、proxies-设置代理
- 当我们请求的ip有风险时,可以使用代理,同样构造代理字典,传递给proxies参数。
import requests
proxy = {"http":"127.0.0.1:80"}
resp = requests.get("http://httpbin.org/ip",proxies=proxy)
print(resp.text)- 当使用自己的ip地址运行爬虫代码,设置访问服务器时,由于超频点击和访问,服务器端可以检测出来,并封掉异常ip,这时候就可以使用代理ip,用来“背锅”。
七、allow_redirects-重定向
- 很多网站是http开头,为了不影响老客户,原网站不动,当访问http的原网址时,重定向到新的https网址,在requests中 allow_redirects默认是True,如果是False则不允许重定向,也就无法重定向新网址获取数据。
import requests
url = "http://github.com"
resp = requests.get(url,allow_redirects=False)
print(resp.url)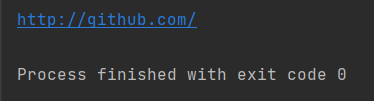
- 允许重定向
import requests
url = "http://github.com"
resp = requests.get(url,allow_redirects=True)
print(resp.url)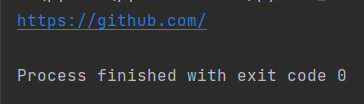
八、verify-证书忽略
- 有时候再打开一个网站的时候,会出现安全证书验证,会导致爬虫获取不到数据,所以我们就需要关闭证书验证。在请求的时候把verify参数设置为False就可以关闭证书验证了。
url = "http://github.com"
resp = requests.get(url,verify=False)
resp.encoding="utf-8"
print(resp)- 但是关闭证书验证后,控制台会输出一个警告信息。

- 虽然这个警告并不影响数据的抓取,但是对于强迫症患者来说,看着也是很烦人,想去掉这些警告。
- 可以使用以下方法,去掉所有警告。
import warnings
warnings.filterwarnings('ignore')九、response对象
- 属性
print(resp.text)#直接转换成字符串 非字节码
print(resp.content)#图片数据 使用此参数
print(resp.status_code)#状态码
print(resp.json()["headers"]["User-Agent"])#自动转换成 字典格式
print(resp.headers)#响应头
print(resp.cookies)#响应cookie
print(resp.url)#请求的url
print(resp.request.url)#请求的url
print(resp.request.headers)#请求头

 浙公网安备 33010602011771号
浙公网安备 33010602011771号