

00 为什么学这门课
课程当中有4个Lab要完成。
Lab1:实现一个单机版的MapReduce
Lab2:实现用于容错的Raft协议
Lab3:实现基于Raft协议的KV存储系统
Lab4:通过分区实现可扩展的KV存储系统

这四个Lab从分布式计算、一致性协议、到最终的可分区的强一致性的存储系统。我在想的是完成Lab后,我应该不仅仅只从概念词、文章、书本去组合这些,更能从实践上去完成,有更深刻的了解
从课程日历上可以清晰的看到,它提供了完整的学习资料,相关的论文资料、代码实例,所以学习起来循序渐进跟着走便行。
作为一个想在技术夯实基础的人来说,学这门课会比仅仅看书好,希望在分布式架构上能有一些提升。
01 完成Lab1的一些经历
总结
先说下完成Lab1的一些总结,这是一门突出实践的课程,在完成Lab的过程中,如果只完成Lab的话,看视频的收益是不大的,当然如果想有更多的思考的话,看视频也有不一样的收获。在视频中,教授对分布式的思考以及学生们的问题都能开拓下我们的思考。
这门课是会给代码的,所以已经提供了整体的代码模版,你只需要在的位置实现相应的代码(这让我想起那我之前的学校,希望学校越来越好,老师也能做到这种程度)。还有在每个Lab中都会说明一些需要注意的事项,以及一些提示,一定要看,一定要看,一定要看。
整个的Lab的实现,是基于项目的test去完成了。所以,你可以认为你在通关,或者说这是你的需求。你能
 看到这张图,代表你可以开心一小伙了。而且,每一个case都是精心设计的,比如Lab1中的从基本实现功能,到符合要求实现功能,到容错的Case,一个Case一个Case让你度过去,从基本实现功能,到最终健壮的实现整体代码。
看到这张图,代表你可以开心一小伙了。而且,每一个case都是精心设计的,比如Lab1中的从基本实现功能,到符合要求实现功能,到容错的Case,一个Case一个Case让你度过去,从基本实现功能,到最终健壮的实现整体代码。
当然,这门课程是有难度的。第一,你要通过论文实现。其实视频上并不会授予太多的实践细节,更多是一个交流的过程,所以,并不能指着光看视频你就能完成实现。第二,这是一门比较高阶的实验课,你要对并发编程有一定的掌握度才行。第三,语言是Go,所以对指针不习惯的人可能会有个适应的过程。
再有说下,我的通关过程吧。我是先看了视频的,但是发现看视频Introduction还好,到后面就默认你已经看了论文的了。所以,一定要把对应课程的Preparation中的论文看了,再去看视频。如果英文不好的话,推荐下“沉浸式翻译”,翻译的效果还好。发现自己不知道关注什么的话,可以先看下上图的对应课程的资料,它会带有一些思考或者课程的重点解答;或者,你草略看完论文后,直接上手Lab,可能会让你在实践中思考一些问题。当然一定要记笔记,无论是思维导图还是文字性的都能带动你思考。
我自己的话,会用思维导图+文字性的标记。思维导图有一个总体的概要,文字能让你进入细节的思考。
实践
下面开始说实践、实践、实践。
思考方式
我的思考方式是如下的,实践以来返工会比较少,而且能思考的全面些,也能在全局上思考,做出一些合理的trade-off。(如果有更好的方式,请大家多多指教)
- 通读需求(这里就是test了。把test要实现的都知道了,且没有异议)
- 整体设计实现方案
- 完成case的版本
- 为一些可能存在的功能,留一些扩展性
- 实现
- 基本实现(保证代码全跑通后)
- 优化代码(保证代码全跑通后优化)
现在我基于这个结构去说。
了解需求以及解答疑问
通读需求:test-mr.sh总共有7个Case需要你去过。
分为3类:基本的实现需求。多任务并发的需求。容错需求
- 基本的实现需求:需要我们真的知道论文的Programming Model
- 多任务并发执行的需求:需要我们真的知道论文的Implementation中的Execution Overview
- 容错需求:需要我们真的知道论文的Implementation中Fault Tolerance
下列是我带着实现的目通读论文时的一些问题。
- MapReduce提供了整体的分布式计算框架,用户只需要编写Map与Reduce的实现。为什么不将MapReduce编写成一个函数呢?(其实在实现的时候,可以都写在Map中,Reduce做复制操作,这是我的假想,应该是不建议的)
-> 基于函数式编程的思想,Map是提取与转化的,而Reduce是做合并操作的。可以抽象大多数的计算任务
- 那为什么要基于函数式编程呢?是方便扩展吗?因为函数式编程是无状态的,并没有赋值带来的困扰(SICP带来的)。论文中给出的结果。确实是方便扩展。
- 那这里的Map、Reduce的与整体系统的交互方式是如何的?(因为这里类似于模版模式实现,你需要知道模版模式的上下文是什么,且这里需要你实现上下文,去屏蔽parallelization, fault-tolerance, data distribution and load balancin这些细节。)
-> 从论文以及代码知道,Map跟Reduce的函数标准设计如下。Map需要将获取的数据基于Key构建成一个集合,用于Reduce通过Key获取集合进行合并。


- Worker如何与Master交互,Map的中间文件如何存储,Reduce如何获取Map的Worker的文件,以及Reduce产生的结果存储在哪里?为什么这么设计?
-> 论文告诉我,由于数据较大的原因,因为带宽的瓶颈,Map会将数据从GFS读取被分解成16~64M的多个文件放置在本地中,Reduce会从根据文件从Map的Worker中读取。(这里MapReduce可以通过一些策略获取附近机架的机器)
-> 这里重点的是一个文件相当于下图的一个split,即一个Map任务,且Map任务对应的Worker会在本地存储Map的文件,已经Map执行后的结果。
-> Reduce的Worker会通过网络读取Map任务存储在Worker本地的文件,以及执行后的结果将直接存储在GFS中
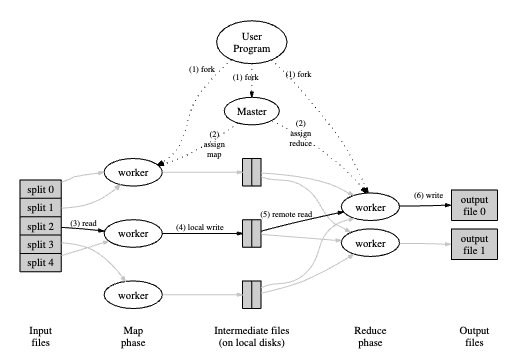
- 如何Worker Crash了怎么办?论文中也有说明,Map的任务会重新执行,Reduce的任务如果已经完成了便不会重新执行。
-> 由于Map的任务执行后会存储在本地,如果本地机器Crash了,可能造成给Reduce任务的Worker的文件获取不到。所以需要重新执行
-> Reduce任务最终都会存储到GFS中,所以,不需要重新执行。
- 如何判断Worker已经Crash了?心跳机制。在Lab中,间隔为10S。
设计与取舍(设计时在书上写的,之后补上相关的图)
- 如何注册Worker、确定Worker状态?
- 如何分配Map计算任务到Worker?
- Worker如何告知Master计算任务状态?
- Worker如何存储在本地计算结果?
- Master如何确定可以分配Reduce计算任务了,Reduce要读取哪些文件时机是?
这里的时机当时的取舍有俩种,第一种以一个Map计算任务为单元生成Reduce任务。第二种是以生成所有的属于Reduce的文件为一个集合单元生成一个任务。最终选择了后者。
因为,第一种的优势是如果Map任务对应的Worker Crash了,只要重新恢复未完成的Reduce任务的Map任务,方便容错时候恢复策略。劣势却更明显,如果按照Reduce的结果存储回GFS的话,将达不到对带宽的节省,且需要保证多个文件对同一存储读写的一致性。
而,第二种除了劣势为需要等待Map任务全部执行完,并在Map对应的Worker Crash后,停掉未生成的Reduce任务,重新执行Map任务。如果负载均衡策略得当,将能保证只有一个Worker写GFS,并不可能回读GFS内容。(其实这个劣势,在大多数任务存在的情况下,并不会出现空闲机器。所以机器资源并不会有闲置)
- 如何Worker Crash了,如何重新恢复计算任务?
- 那个状态是核心的竞争状态,如何保证竞争状态尽量小,甚至能否用到无锁呢?
- 能不能做到记录计算任务历史?
- 能不能Crash Master时,重新恢复呢?
- 现在是单机版本的,能不能做到多机版本?
编码
编码可能是最省事的时候了,因为很多问题的trade-off都已经在设计阶段解决了,顶多是一些Go工具使用不清楚的问题。
还有的是定位多线程问题。
在Mac上的话,执行test-mr.sh时关闭的不友好导致的进程存在,需要杀一下,不然在跑crash用例时会有异常现象
ps -ef | grep "sh test-mr.sh" | awk -F ' ' '{print $2}' | xargs kill -9
感悟
第一次写这种作业,有点不知所措。真心的说很喜欢这种课。工作也4年了,之前一直在写业务相关的,慢慢的发现自己还是喜欢整较技术些的活,所以这俩年一直持续的学习,但是更多的是看书,希望把整个计算机知识体系建立起来,但最终的结果是,说起来头头是道,用起来畏畏缩缩。
这个Lab需要我深入的读论文,让我对分布式计算中有了跟多的思考,以及提供给用户使用时需要让用户注意什么、以及在扩展性以及容错性的理解与考虑都有更深入的思考。更重要如何基于这些去设计,以及为什么要分布式。
所以,有了这些论文实践课希望能提升自己的整体技术能力。加油

