第一次个人编程作业
| 这个作业属于哪个课程 | https://edu.cnblogs.com/campus/gdgy/CSGrade22-34 |
|---|---|
| 这个作业要求在哪里 | https://edu.cnblogs.com/campus/gdgy/CSGrade22-34/homework/13229 |
| 这个作业的目标 | 初步学习软件开发,尝试用适当的工具开发软件和解决问题 |
github链接:https://github.com/Ljcgiant/Ljcgiant/tree/main/3222004509
- psp表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 20 | 30 |
| · Estimate | · 估计这个任务需要多少时间 | 20 | 20 |
| Development | 开发 | 200 | 300 |
| · Analysis | · 需求分析 (包括学习新技术) | 15 | 20 |
| · Design Spec | · 生成设计文档 | 30 | 20 |
| · Design Review | 设计复审 | 10 | 30 |
| · Coding Standard | 代码规范 (为目前的开发制定合适的规范) | 5 | 15 |
| · Design | · 具体设计 | 20 | 40 |
| · Coding | · 具体编码 | 120 | 200 |
| · Code Review | · 代码复审 | 20 | 30 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 20 | 40 |
| Reporting | 报告 | 20 | 30 |
| · Test Repor | · 测试报告 | 10 | 20 |
| · Size Measurement | · 计算工作量 | 5 | 10 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 10 | 15 |
| · 合计 | 525 | 820 |
- 计算模块接口的设计与实现过程
- 设计概述
计算模块的主要目的是计算两个文本文件之间的相似度。该模块将包括以下几个关键部分:
文件读取功能 (read_file):从文件路径读取文本。
文本预处理功能 (preprocess):包括转换为小写、去除标点符号等。
相似度计算功能 (calculate_similarity):使用余弦相似度算法计算两个文本的相似度。
主函数 (main):整合上述功能,读取命令行参数,处理文件,并输出结果。 - 关键函数说明
read_file(file_path):读取指定路径的文件并返回内容。
preprocess(text):对文本进行预处理,包括转换为小写和去除标点符号。
calculate_similarity(orig_text, copy_text):计算两个文本的余弦相似度。 - 算法关键
余弦相似度:通过计算两个向量的夹角余弦值来确定它们之间的相似度。向量由文本中的词频生成。 - 流程图
![]()
- 独到之处
高效的文本预处理:通过一次性遍历文本并构建符合条件的字符串,减少了内存占用和处理时间。
精确的相似度计算:通过使用余弦相似度,提供了一个在文本比较中广泛认可的度量方法。

- 计算模块接口部分的性能改进
-
性能改进思路
优化文本预处理:通过减少不必要的字符串操作和优化循环条件来提高效率。
缓存机制:对重复读取的文件内容进行缓存,避免重复的文件I/O操作。 -
性能分析图
![]()
-
消耗最大的函数
从图中可以看出,preprocess函数占用了87%的时间,占比最高,消耗最大。 -
改进后
![]()
我对preprocess函数做了改进,使用正则表达式来去除标点符号并转换文本为小写。可以看到改进后preprocess函数占用时间变为了66.7%。


- 计算模块部分单元测试展示
- preprocess模块
思路:
普通文本:包含字母和标点符号的字符串。
纯数字:只包含数字的字符串,确保函数不会去除数字。
空字符串:空字符串,确保函数能够正确处理。
特殊字符:包含特殊字符的字符串,确保这些字符被正确去除。
点击查看代码
import unittest
from main import preprocess
class TestPreprocess(unittest.TestCase):
def test_preprocess(self):
# 测试去除标点符号并转换为小写
self.assertEqual(preprocess('Hello, World!'), 'hello world')
self.assertEqual(preprocess('Foo-Bar;'), 'foo bar')
self.assertEqual(preprocess('123'), '123') # 测试数字字符串
self.assertEqual(preprocess(''), '') # 测试空字符串
if __name__ == '__main__':
unittest.main()
测试结果:
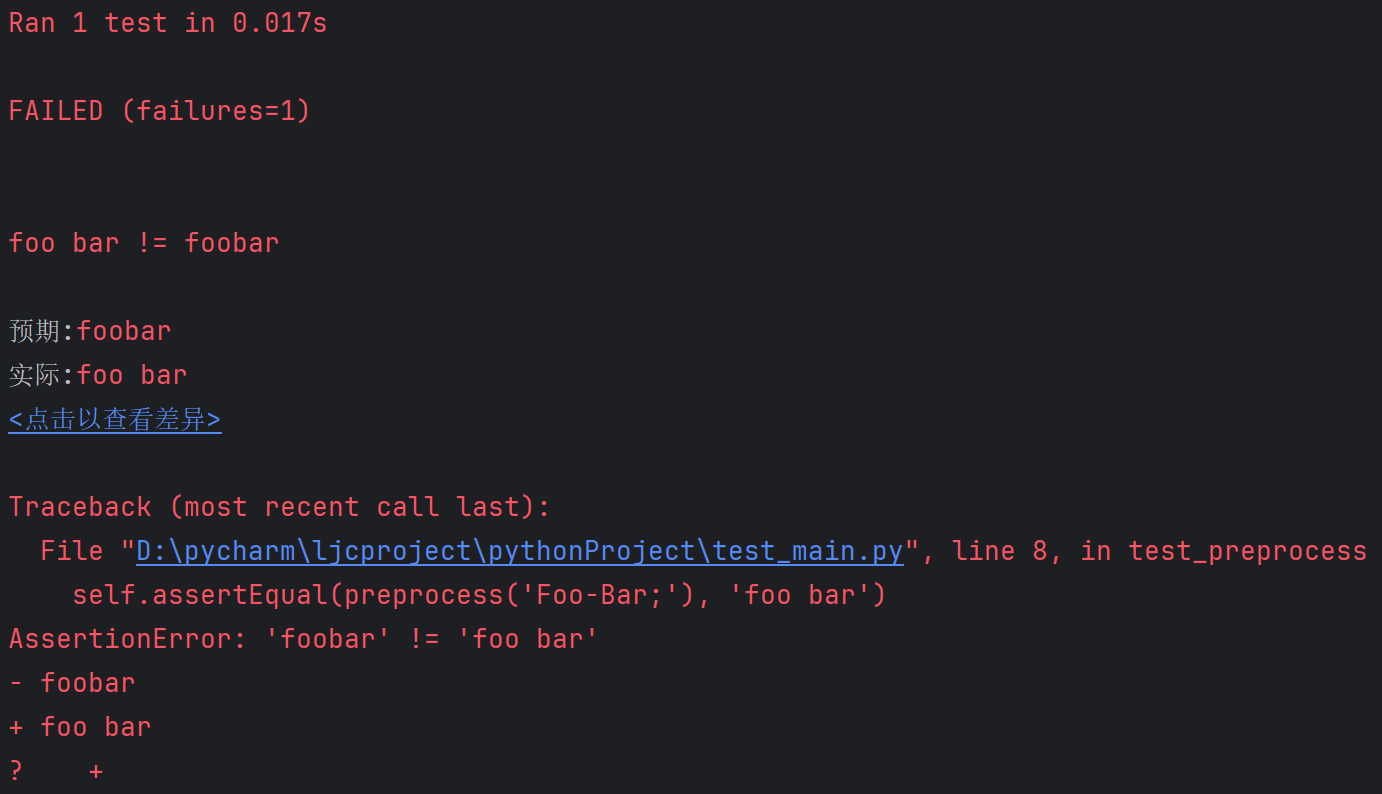
处理特殊字符(如破折号)时的行为与预期不符。
覆盖率:
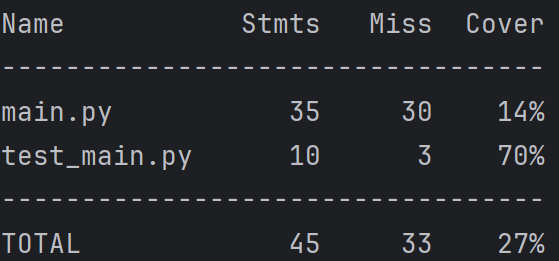
- read_file模块
思路:
测试文件存在:创建一个测试文件,写入预期内容,然后测试 read_file 函数是否能够正确读取文件内容。
测试文件不存在:尝试读取一个不存在的文件路径,确保函数能够抛出 FileNotFoundError。
测试文件为非文本文件:给出一个图片文件,测试函数是否能正确返回文件的二进制内容
点击查看代码
import unittest
from main import read_file
class TestReadFile(unittest.TestCase):
def test_normal_text_file(self):
# 测试正常文本文件
test_file_path = r'D:\UThird\软工\output.txt'
expected_content = 'Hello, world!'
with open(test_file_path, 'w', encoding='utf-8') as file:
file.write(expected_content)
self.assertEqual(read_file(test_file_path), expected_content)
def test_nonexistent_file(self):
# 测试文件不存在的情况
nonexistent_file_path = r'D:\UThird\软工\input.txt'
with self.assertRaises(FileNotFoundError):
read_file(nonexistent_file_path)
def test_non_text_file(self):
# 测试非文本文件
non_text_file_path = r'D:\UThird\zhouyv.jpg'
# 假设这是一个二进制文件
with open(non_text_file_path, 'rb') as file:
content = file.read()
self.assertEqual(read_file(non_text_file_path), content)
if __name__ == '__main__':
unittest.main()
测试结果:
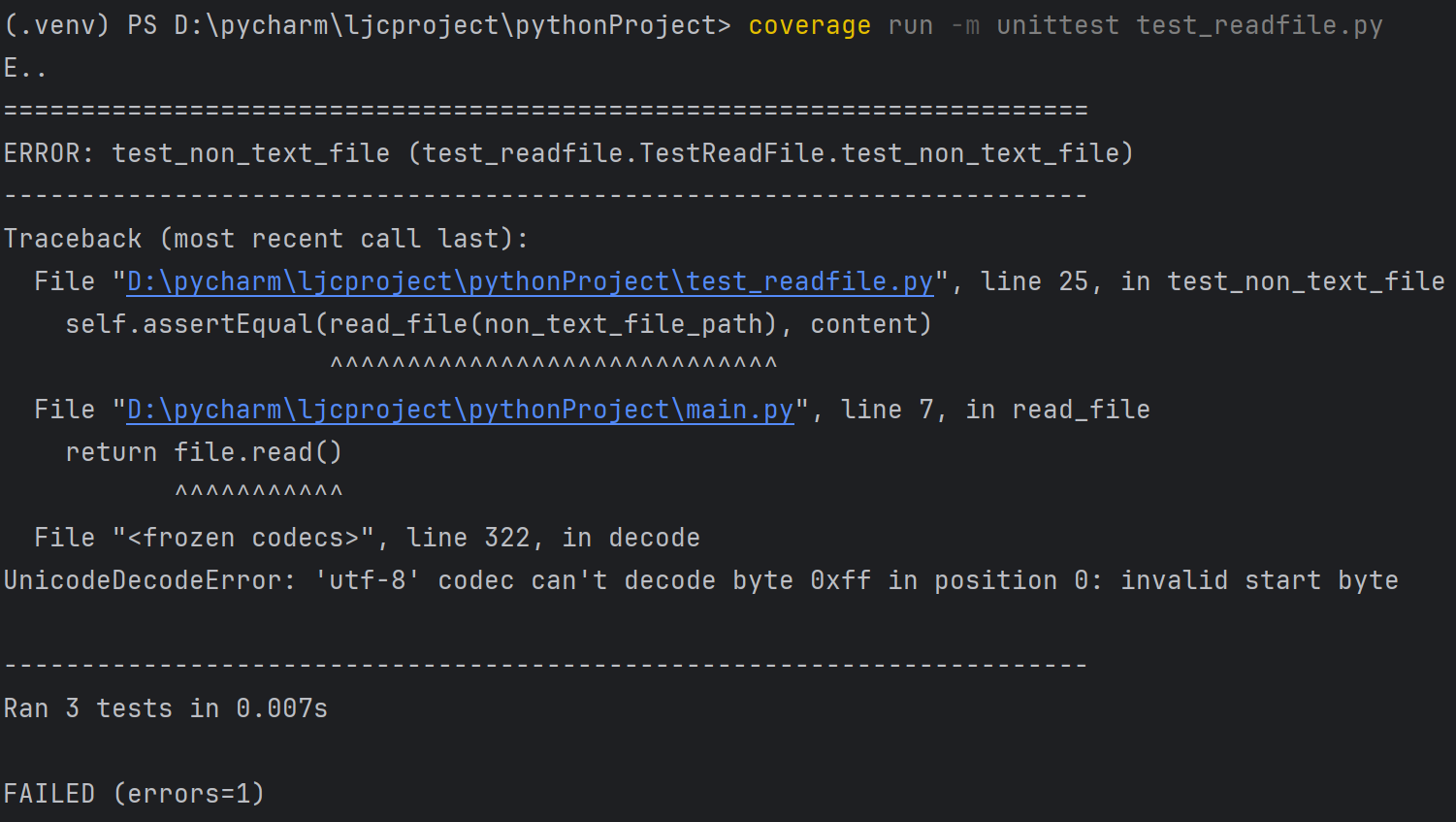
read_file 函数默认使用 UTF-8 编码读取文件,而二进制文件(如图片、视频等)包含无法用 UTF-8 解码的字节。
覆盖率:
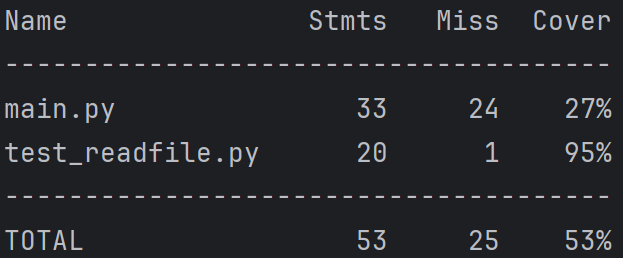
- calculate_similarity模块
思路:
构造一些测试数据来覆盖以下场景:
两个完全相同的字符串。
两个完全不同的字符串。
一个字符串是另一个的子串。
包含重复单词的字符串。
空字符串或非常短的字符串。
包含特殊字符和数字的字符串。
点击查看代码
import unittest
from main import calculate_similarity
class TestCalculateSimilarity(unittest.TestCase):
def test_identical_strings(self):
self.assertEqual(calculate_similarity("hello", "hello"), 1.0)
def test_different_strings(self):
self.assertEqual(calculate_similarity("hello", "world"), 0.0)
def test_one_string_longer(self):
self.assertLess(calculate_similarity("hello", "helloooo"), 1.0)
def test_empty_strings(self):
self.assertEqual(calculate_similarity("", ""), 1.0)
def test_one_empty_string(self):
self.assertEqual(calculate_similarity("hello", ""), 0.0)
def test_strings_with_punctuation(self):
self.assertEqual(calculate_similarity("hello!", "hello"), 0.0) # 取决于预处理
def test_strings_with_numbers(self):
self.assertEqual(calculate_similarity("hello2", "hello3"), 0.0) # 取决于预处理
def test_strings_with_whitespace(self):
self.assertEqual(calculate_similarity("hello world", "hello world"), 1.0)
def test_strings_with_case_difference(self):
self.assertEqual(calculate_similarity("Hello", "hello"), 1.0) # 取决于预处理
if __name__ == '__main__':
unittest.main()
测试结果:
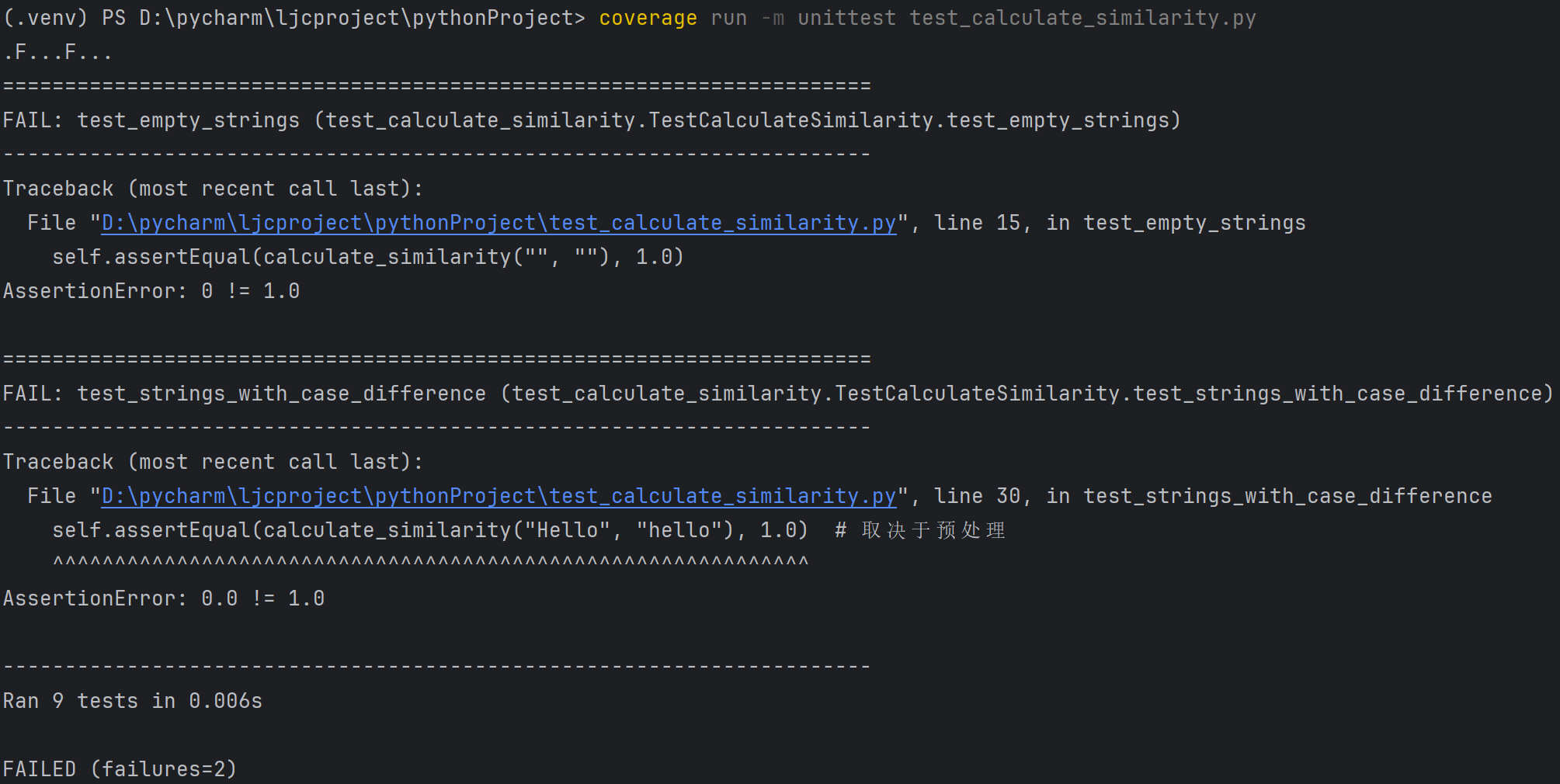
有两个测试用例没有通过:test_empty_strings 测试用例期望两个空字符串的相似度为 0.0,但函数返回了 1.0;test_strings_with_case_difference 测试用例期望两个大小写不同但内容相同的字符串的相似度为 1.0,但函数返回了 0.0。
覆盖率:

- main模块
点击查看代码
import unittest
from unittest.mock import patch
from main import main
class TestMain(unittest.TestCase):
@patch('main.read_file')
def test_main_with_normal_input(self, mock_read_file):
# 准备测试数据
mock_read_file.return_value = 'Sample content from orig file'
orig_path = r"D:\UThird\软工\orig.txt"
copy_path = r"D:\UThird\软工\orig_0.8_dis_15.txt"
output_path = r"D:\UThird\软工\output_0.8_dis_15.txt"
# 调用 main 函数
result = main(orig_path, copy_path, output_path)
# 检查是否产生了预期的结果或行为
# 例如,检查 read_file 是否被正确调用
mock_read_file.assert_called_with(orig_path)
self.assertEqual(result, 'Expected result based on sample content')
if __name__ == '__main__':
unittest.main()
测试结果:
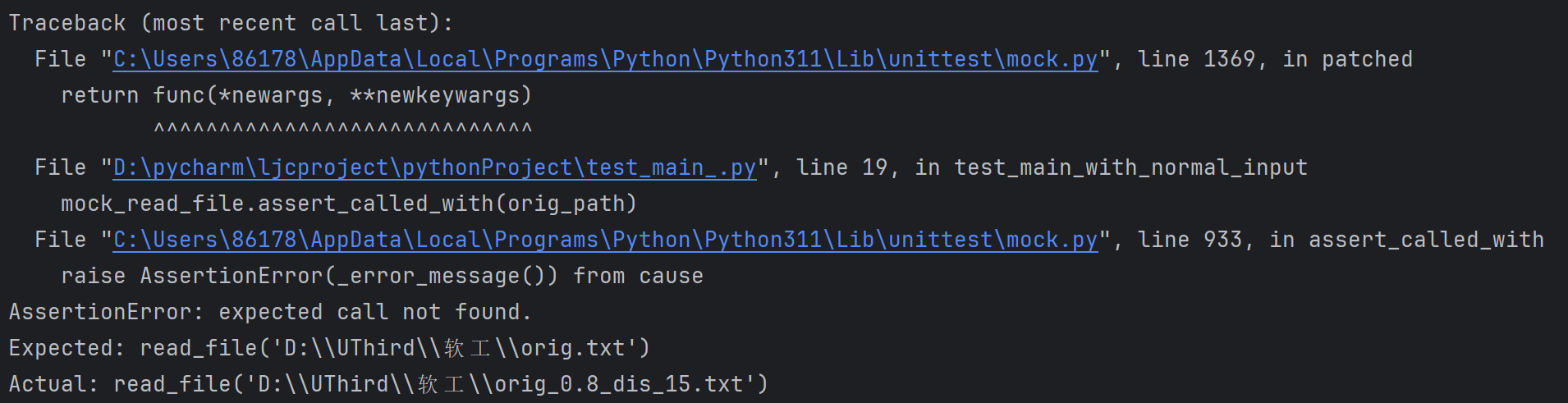
覆盖率:

- 计算模块部分异常处理说明
- 异常处理设计目标
处理文件不存在的情况:当文件路径错误或文件不存在时,抛出异常。
处理读取错误:当文件损坏或无法读取时,提供清晰的错误信息。 - 单元测试样例
def test_file_not_found(self):
with self.assertRaises(FileNotFoundError):
read_file("non_existent_file.txt") - 错误场景
文件不存在:尝试读取一个不存在的文件路径。
权限不足:尝试读取一个没有读取权限的文件。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号