Hadoop实验-HDFS与Mapreduce操作
一、实验目的
1、利用虚拟机搭建集群部署hadoop
2、HDFS文件操作以及文件接口编程;
3、MAPREDUCE并行程序开发、发布与调用。
二、实验内容
1、虚拟机集群搭建部署hadoop
利用VMware、centOS-7、Xshell(secureCrt)等软件搭建集群部署hadoop,具体操作参照
https://www.bilibili.com/video/BV1Kf4y1z7Nw?p=1
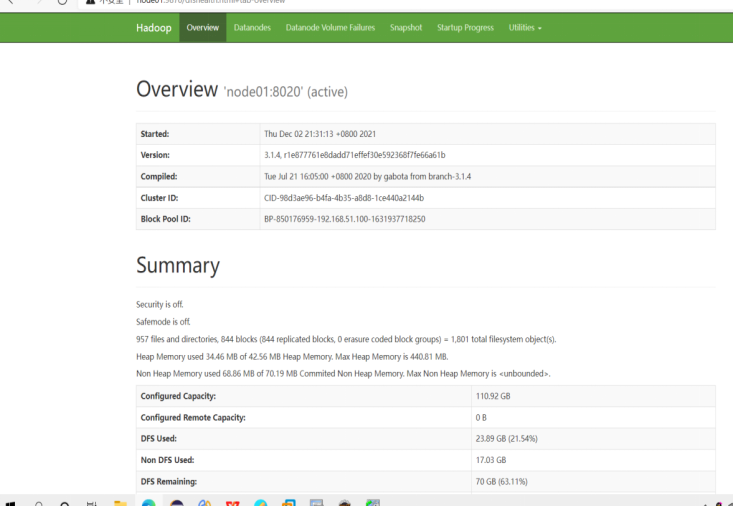
2、HDFS文件操作
(1)在分布式文件系统上验证HDFS文件命令
[-ls <path>] //显示目标路径当前目录下的所有文件

[-du <path>] //以字节为单位显示目录中所有文件的大小,或该文件的大小(如果path为文件)
(2). HDFS文件操作
调用HDFS文件接口实现对分布式文件系统中文件的访问,如创建、修改、删除等。
源代码:
package mapreduce;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataOutputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.log4j.BasicConfigurator;
public class test {
public static void main(String[] args) {
BasicConfigurator.configure();
try {
Configuration conf = new Configuration();
FileSystem fs = FileSystem.get(conf);
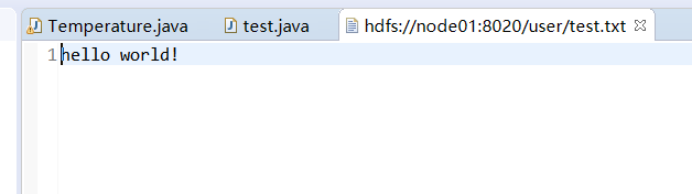
String filename = "hdfs://node01:8020/user/test.txt";
FSDataOutputStream os = fs.create(new Path(filename));
byte[] buff = "hello world!".getBytes();
os.write(buff, 0, buff.length);
System.out.println("Create" + filename);
} catch (Exception e) {
e.printStackTrace();
}
}
}
运行结果:

3.MAPREDUCE并行程序开发
1)求每年最高气温
源代码:
package mapreduce;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class Temperature {
static class TempMapper extends Mapper<LongWritable, Text, Text, IntWritable> {
@Override
public void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
System.out.print("Before Mapper: " + key + ", " + value);
String line = value.toString();
String year = line.substring(0, 4);
int temperature = Integer.parseInt(line.substring(8));
context.write(new Text(year), new IntWritable(temperature));
System.out.println("======" + "After Mapper:" + new Text(year) + ", " + new IntWritable(temperature));
}
}
static class TempReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
@Override
public void reduce(Text key, Iterable<IntWritable> values, Context context)
throws IOException, InterruptedException {
int maxValue = Integer.MIN_VALUE;
StringBuffer sb = new StringBuffer();
for (IntWritable value : values) {
maxValue = Math.max(maxValue, value.get());
sb.append(value).append(",");
}
System.out.print("Before Reduce: " + key + ", " + sb.toString());
context.write(key, new IntWritable(maxValue));
System.out.println("======" + "After Reduce: " + key + ", " + maxValue);
}
}
public static void main(String[] args) throws Exception {
String dst = "hdfs://node01:8020/user/zzy/input.txt";
String dstOut = "hdfs://node01:8020/user/zzy/output";
Configuration hadoopConfig = new Configuration();
hadoopConfig.set("fs.hdfs.impl", org.apache.hadoop.hdfs.DistributedFileSystem.class.getName());
hadoopConfig.set("fs.file.impl", org.apache.hadoop.fs.LocalFileSystem.class.getName());
Job job = new Job(hadoopConfig);
// job.setJarByClass(NewMaxTemperature.class);
FileInputFormat.addInputPath(job, new Path(dst));
FileOutputFormat.setOutputPath(job, new Path(dstOut));
job.setMapperClass(TempMapper.class);
job.setReducerClass(TempReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
job.waitForCompletion(true);
System.out.println("Finished");
}
}
运行结果:
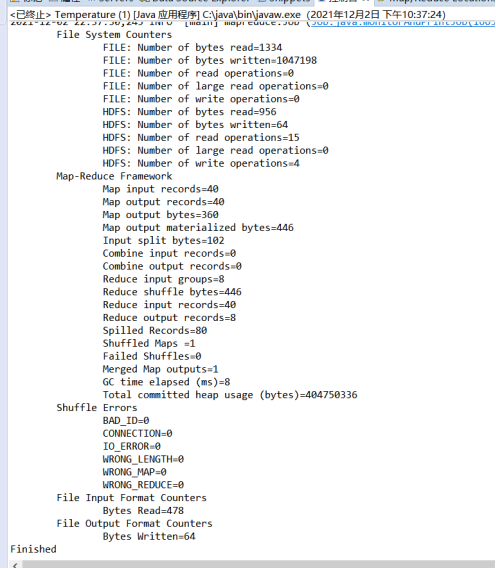
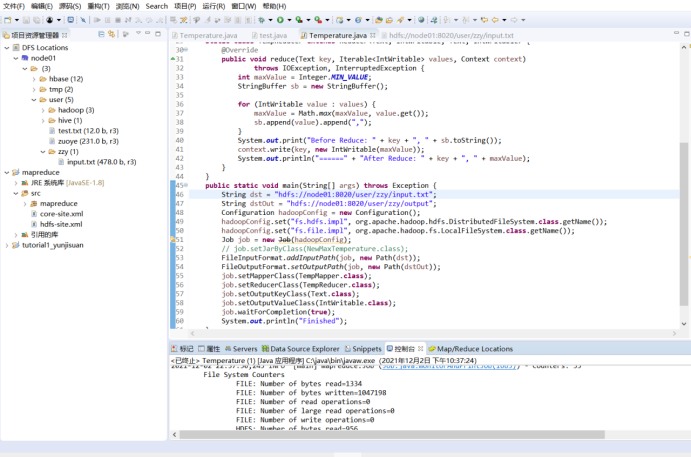
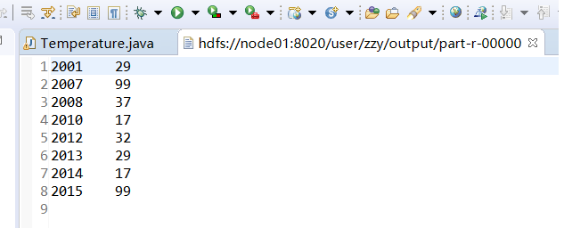
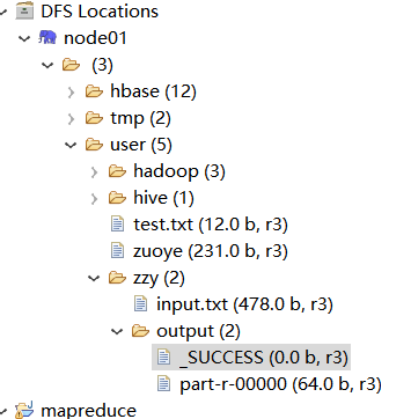
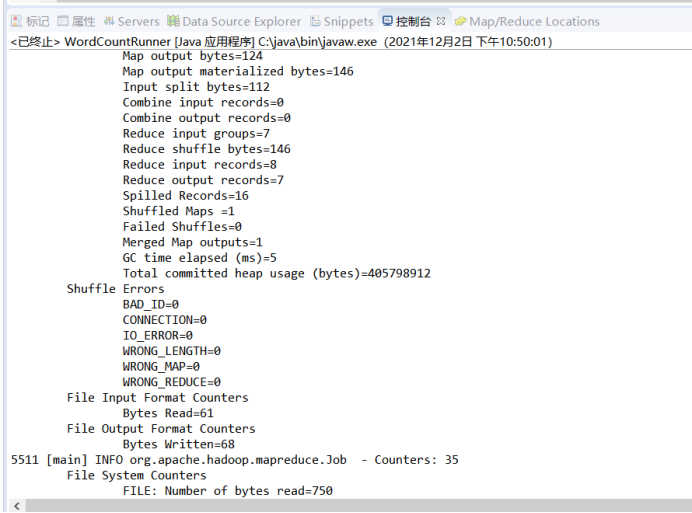
(2)词频统计
源代码:
import java.io.IOException;
import org.apache.commons.lang.StringUtils;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
public class WordCountMapper extends Mapper<LongWritable, Text, Text, LongWritable> {
@Override
protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, LongWritable>.Context context)
throws IOException, InterruptedException {
String[] words = StringUtils.split(value.toString(), " ");
for (String word : words) {
context.write(new Text(word), new LongWritable(1));
}
}
}
import java.io.IOException;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
public class WordCountReducer extends Reducer<Text, LongWritable, Text, LongWritable> {
@Override
protected void reduce(Text arg0, Iterable<LongWritable> arg1,
Reducer<Text, LongWritable, Text, LongWritable>.Context context) throws IOException, InterruptedException {
int sum = 0;
for (LongWritable num : arg1) {
sum += num.get();
}
context.write(arg0, new LongWritable(sum));
}
}
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import org.apache.log4j.BasicConfigurator;
public class WordCountRunner {
public static void main(String[] args)throws IllegalArgumentException, IOException, ClassNotFoundException, InterruptedException {
BasicConfigurator.configure();
Configuration conf = new Configuration();
Job job = new Job(conf);
job.setJarByClass(WordCountRunner.class);
job.setJobName("wordcount");
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(LongWritable.class);
job.setMapperClass(WordCountMapper.class);
job.setReducerClass(WordCountReducer.class);
job.setInputFormatClass(TextInputFormat.class);
job.setOutputFormatClass(TextOutputFormat.class);
FileInputFormat.addInputPath(job, new Path("hdfs://node01:8020/user/zzy/input_wordcount.txt"));// 输入路径
FileOutputFormat.setOutputPath(job, new Path("hdfs://node01:8020/user/zzy/output_wordcount"));// 输出路径
job.waitForCompletion(true);
}
}
运行结果: