
基于中文新闻分词绘制词云图
1、数据导入展示,树形结构目录
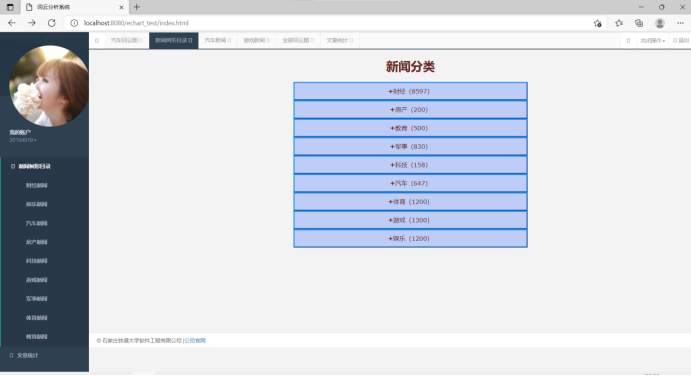
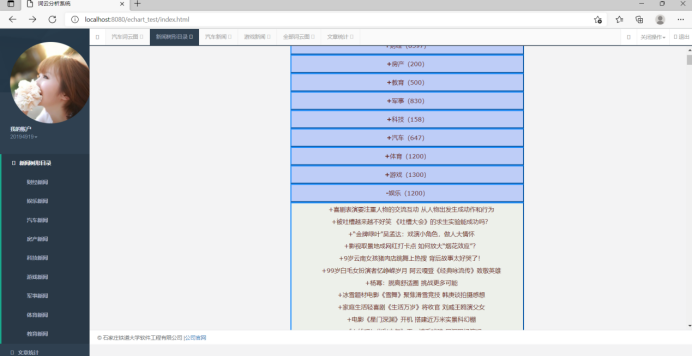
新闻列表
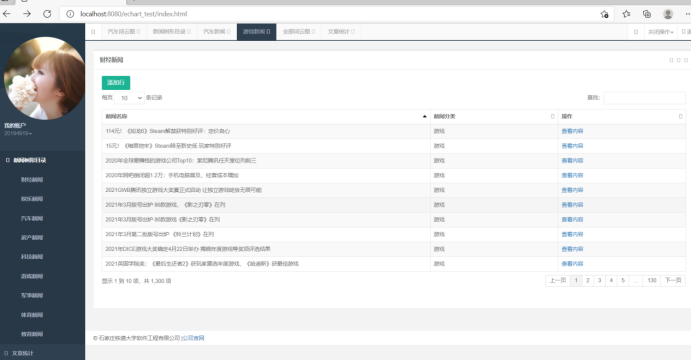
点击查看详情
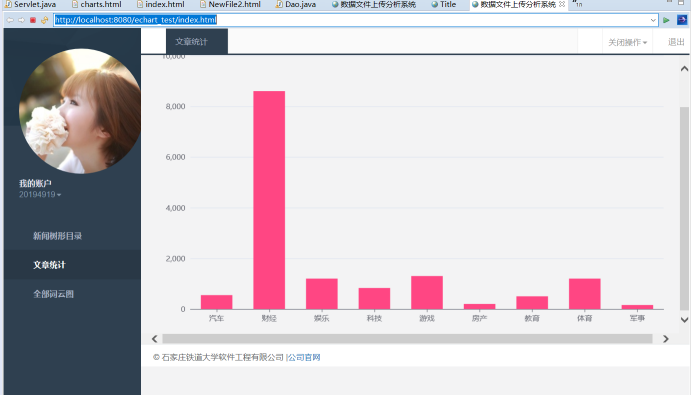
2、文章统计:统计各个类别的文章总数
3、文章分词:
采用python的jieba分词库进行中文分词
(1)解析所有新闻正文,绘制词云图
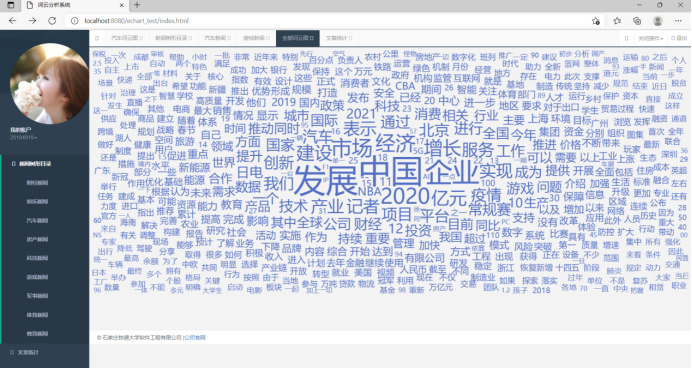
(2)选择汽车类新闻,进行分词解析,随后以图云形式展示

分词代码:
import os, codecs import jieba from collections import Counter from pymysql import * #词云 from PIL import Image import numpy as np import matplotlib.pyplot as plt #词云生成工具 from wordcloud import WordCloud,ImageColorGenerator #需要对中文进行处理 import matplotlib.font_manager as fm def get_words(txt): # 创建connection连接 conn = connect(host='localhost', port=3306, database='test', user='root', password='123asd..00', charset='utf8') # 获取cursor对象 cs1 = conn.cursor() # 执行sql语句 seg_list = jieba.cut(txt) c = Counter() for x in seg_list: if len(x) > 1 and x != '\r\n': c[x] += 1 print('常用词频度统计结果') for (k, v) in c.most_common(): print('%s %s %d' % (k,"***************", v)) query = 'insert into allnews(name, number) values(%s, %s)' for (k, v) in c.most_common(): name =k number = v values = (name, number) cs1.execute(query, values) # 提交之前的操作,如果之前已经执行多次的execute,那么就都进行提交 conn.commit() # 关闭cursor对象 cs1.close() # 关闭connection对象 conn.close() if __name__ == '__main__': with codecs.open('D:\softWareProject/txt/news_all.txt', 'r', 'utf8') as f: txt = f.read() get_words(txt)
