Python实现人脸检测(包括口罩检测)、人脸识别(基于Opencv,Dlib,Tensorflow,QT6) 自训练模型
刚好上计算机视觉课做实验做到了,就在这里记录下来,刚好顺便理一理思路。
1|0编译环境:
Python 3.12.6
Tensorflow 2.18.0
Keras 3.5.0
Opencv-python 4.10.0
Opencv-contrib-python 4.10.0
Dlib 19.24.6
PyQt6
Numpy 1.26.4
Matplotlib 3.9.2
2|0第一部分:人脸检测
关于如何进行人脸检测,现在主流的方法有很多,像早期使用的Haar级联分类器,Opencv可以直接调用,使用方便、简单,但是准确性和鲁棒性都较低,且如果有使用过的经验的话,就会发现很容易受到光照等环境因素的影响。这里就不多赘述了,具体实现和原理可以参考https://www.cnblogs.com/zyly/p/9410563.html
当然你也可以调用Dlib中的人脸检测模型,Dlib提供的人脸检测模型是基于HOG和CNN的人脸检测方法,效果还可以就是速度较慢。 如果使用深度学习的模型的话,MTCNN、SSD、YOLO、RetinaFace等方法效果都很优异,且速度上也较为迅捷。
在本次项目中我们主要使用的是SSD的方法。
什么是SSD?
SSD(Single Shot MultiBox Detector)是一种单阶段性检测算法,与传统的两阶段检测方法(例如Faster R-CNN)不同,SSD将检测过程合并为一个单独的过程,通过在图像中生成多个初读的默认边界框,直接在这些框上预测类别和位置偏移

SSD主要采用VGG16作为基础模型,在VGG16的基础上新增了卷积层来获取更多的特征图以便用来检测,在上述网络结构图上,我们可以看到SSD利用了多尺度的特征图做检测。
用我们自己的语言去组织一下,SSD的工作流程就是先检测图像的输入,然后在输入图像上提取6个feature map,再利用每一层的default box对feature map信息进行提取:定位器会根据每一个default box信息生成检测框偏移量;分类器会根据每一个default box信息生成类别标签,最终剔除标签为背景的检测框,利用nms清除冗余检测框,输出最终的检测框和标签。
在特征提取上我们采用ResNet-10作为主干网络进行特征提取,ResNet网络的主要特点是引入了残差链接,使得网络能够在较深的层次上保留信息,解决深层网络中的梯度消失问题,从而提升特征提取的效果。
个人理解有限,难免出错,具体讲解可以参考其他文章或者论文
Opencv提供了基于ResNet-10结构和SSD框架的经过训练的Caffe模型文件,在Opencv中只需要利用Opencv的DNN模块就行加载模型,就能直接调取使用了(cv2.dnn.readNetFromCaffe),直接在Opencv的github或者开源网下载res10_300x300_ssd_iter_140000_fp16.caffemodel和对应的网络配置文件deploy.prototxt即可
具体代码使用:
`
`
如果配置没有问题,就能得到例如下方效果

3|0第二部分:口罩检测(模型训练)
我们在人脸检测之后,如何去获取人脸的更多信息呢?对于现实生活中,单单一幅人脸,没有进行细分,可直接使用的信息很少。Dlib库提供了人脸的68特征点位,包括眼睛、鼻子、嘴巴等,Opencv的Harr级联器中也有人脸5点位的xml等等。那我们如何才能对人脸是否带着口罩进行检测呢?
这里我们利用预训练的MobileNetV2模型(轻量级卷积神经网络)来训练自己的口罩检测模型。具体原理参考原文https://www.kaggle.com/code/mirzamujtaba/face-mask-detection/notebook
1. 第一步:搭建训练集
当然我们可以自己搭建数据集,寻找大概1000张左右的照片,照片需要包含带着口罩的、不带口罩的,再对照片人脸区域进行检测和标记(是否带口罩)。这里我们为了便捷一些,我们可以直接使用公开数据集,飞浆上可以直接下载,数据集中包括了800多张包含口罩人脸的图片和对应的标签信息。https://aistudio.baidu.com/datasetdetail/127209
2. 第二步:数据预处理和增强
公开数据集中给出了人脸区域和对应人脸标签,我们需要将每个图像中的数据提取出来,从而才能进行后续的模型训练,具体实现可以看后续的代码实现,我们将数据人脸图像存放在face_images中和对应标签存放在face_labels中。数据增强操作的中我们使用LabelEncoder将标签转换为数字形式,并转换为One-hot编码格式,将每个标签表示为一个三维向量,同时加上ImageDataGenerator进行数据增强,包括旋转、缩放、平移等操作,增强模型的泛化能力
3. 第三步:模型搭建和训练
我们利用MobileNetV2来作为网络基础,利用AveragePooling2D在MobileNetV2的最后一个卷积层后添加一个平均池化层,从而减少特征图的大小;Flatten将特征图展品为一堆,以便连接全连接层,同时利用Dense添加一个具有256个神经元的全连接层,用于学习更加复杂的特征表示。Dropout是为了防止过拟合,使随机概率神经元失效,最后使用softmax激活函数生成三个类别的概率分布。
在网络搭建后,我们要对INIT_LR(学习率)、EPOCHS(训练次数)、BS(批次大小)等超参数进行初始化,再将我们的数据集划分为训练集和测试集,在局部优化上可以使用Adam优化器或者categorical_crossentropy损失函数等等来优化模型训练,避免类别数量差异导致模型偏向性过强。
最终训练模型即可,并将训练的模型保存下来。这样我们的口罩模型就训练完成了!
具体实现后效果:

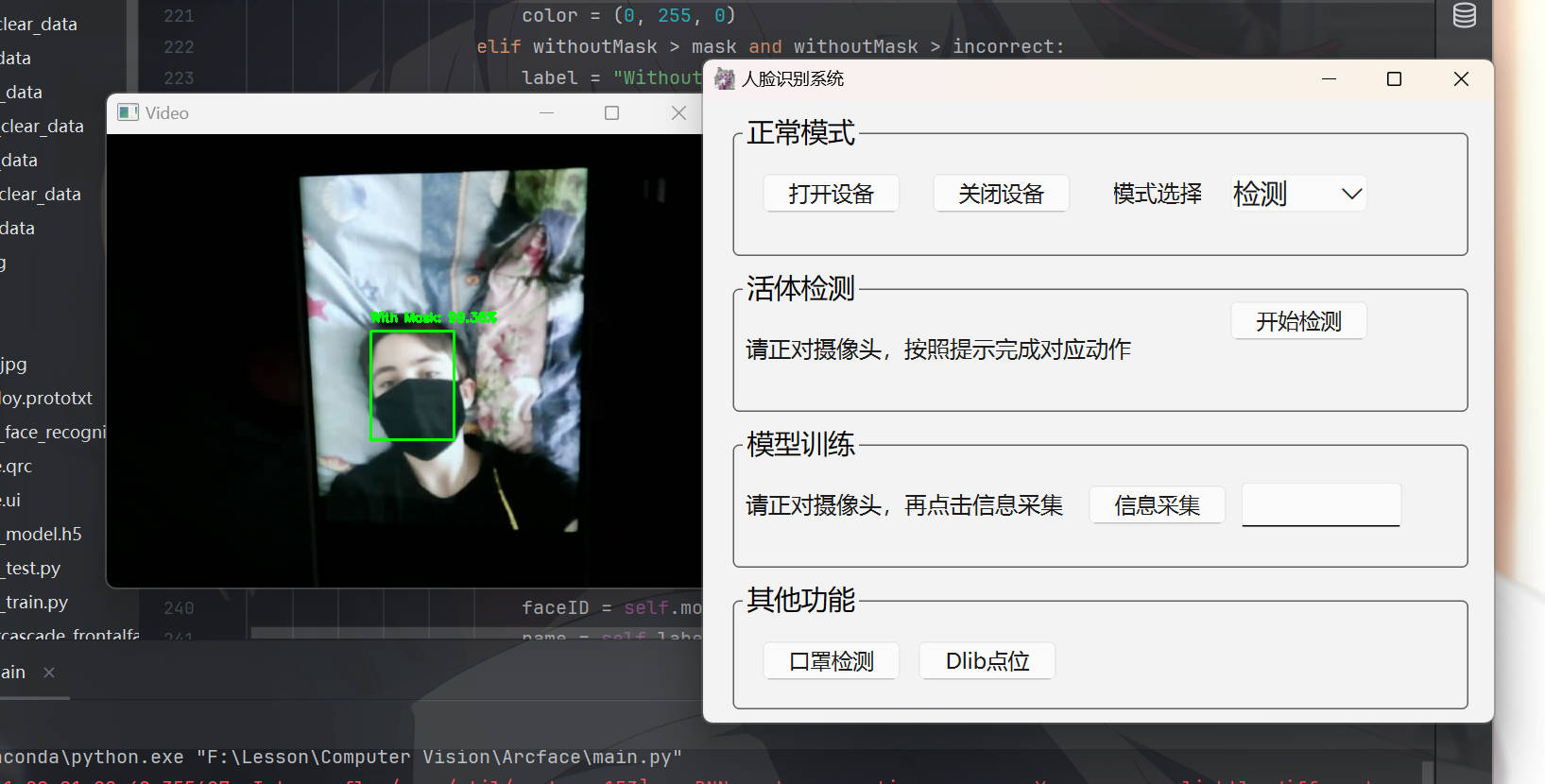
4|0第三部分:人脸识别(模型训练)
因为同上述口罩检测步骤差不多所以前面部分就不多赘述了,数据集部分就直接放代码进行理解了。
1. 第一步:训练集搭建
我们在工程文件下创建一个face_data文件夹,里面就存放对应人物的图像,我这里对于每一个人采集了1000张在不同光照条件下的人脸区域图像,并存放在对应人物姓名的文件夹中。下面的代码需要在后续的数据集初始化中需要使用到
这样我们就能对文件中所有人物图像进行数据集的处理和标签设定。当然,一个人物文件中不要出现其他人的图像,而且最好能够手动对采集的图像进行一个筛选和处理,因为直接利用摄像头采集的话也许会出现模糊看不清的图像,影响模型的训练。
Tip: IMAGE_SIZE的大小会对最终训练的模型大小产生影响,且如果后续使用的是MobileNetV2作为基础网络结构的话对IMAGE_SIZE有一定大小的要求,例如128✖128、224✖224等
1. 第二步:模型网络搭建
这里我们使用的是Keras的Sequential搭建一个层层堆叠的CNN网络,当然你也可以利用MobileNetV2或其他进行网络的搭建,具体搭建的话其实差不多,例如使用Conv2D加入卷积层,并在卷积层后连接一个ReLu激活层;利用MaxPooling2D进行下采样,搭建池化层,减少特征图大小,保留重要特征。其余就是一些优化层,一层层搭建下去,最终使用softmax激活函数,输出对应人物数量的类别的概率分布。 建议网络层数不要太深,在数据集数量过小的情况下,搭建层数过多的网络不一定会得到更好的效果,反之也许会带来过拟合现象。
训练模型过程中,我们指定SGD优化器、损失函数、评价指标等等,在训练的时候使用数据增强后的数据训练集来进行模型的训练。

这样我们的人脸识别模型也就训练好了!当然可以用现有的更加优秀的网络结构来进行优化,这里就先不演示了。
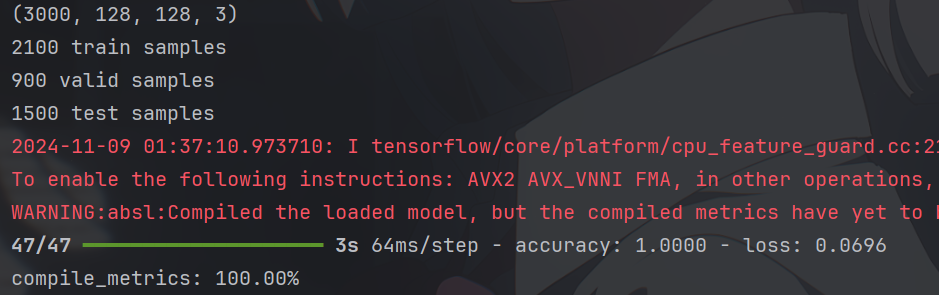
我们再测试一下,效果还是可以的(这里也许我做的有点问题,准确率100,有点离谱了) 😦
具体放到QT系统中的效果:

其余人物舍友就不展示了
5|0第四部分:活体检测
活体检测又可以分为静态检测和动态检测,静态检测具体实现需要模型的训练,具体实现可以去参照Github上官方文档讲解;动态检测的话,就是需要我们完成部分动作,例如眨眨眼、左右摇头等。在前面说过了,Dlib提供了人脸68点位信息,所以我们可以利用具体活动区域的偏移来实现是否完成对应动作的实现。

1. 眨眼检测:可以参照网上的教程,计算左眼和右眼的纵横比来实现眨眼检测。
2. 摇头检测:可以通过人脸区域的整体移动比例,假设按照上述68点位图像,我们取30点位为中心位置,左右取2点位和16点位,起初默认2和16到30的距离相同,当发生左右摇头时,对应比例就会变化,从而就能判断得到是否进行了摇头动作,同时也能识别是左摇头还是右摇头,同理抬头、低头也能实现。
3. 张嘴检测:直接计算上半嘴唇区域和下半嘴唇区域的高度差是否变化....
同理,可以在合理范围内实现多种检测操作
当然,为了能够实现实时的效果,我们可以利用线程设置对应的做出反应的时间来进行时间的约束,完成一定次数后显示检测成功。
具体实现效果:

6|0第五部分:QT UI设计
在Python中使用QT不是很方便,且进行控件绑定效果复杂麻烦。我这里使用的方法是先利用QT Designer或者Creator将Qt UI设计好,再利用uic.load直接加载ui文件,再将对应控件使用新的对象进行绑定;当然你可以照着网上的教程,将Designer和Pycharm绑定起来,直接导出ui.py文件。
用QT的Label控件是可以加载图像的,只要将cv的Mat类型转换为QPixmap类型,但是我在进行转换操作时出现了部分错误,调整不出来所以放弃了,直接使用了cv的独立窗口(我之前使用C++写的,转换没有问题)

OK了,这就是本次实验随笔的具体内容了,说的有点粗糙,但应该还行.....😃,如果错误之处,请多指教
具体代码我会在GitHub上开源,数据集就不上传了 https://github.com/Lwh1019/Face_Recognition
__EOF__
本文链接:https://www.cnblogs.com/Liwh04/p/18516150.html
关于博主:评论和私信会在第一时间回复。或者直接私信我。
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!
声援博主:如果您觉得文章对您有帮助,可以点击文章右下角【推荐】一下。您的鼓励是博主的最大动力!


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· 【自荐】一款简洁、开源的在线白板工具 Drawnix