

Word2Vec 简介
- word2Vec 能做什么:
- 计算相似度: 寻找相似词 或者 相似文章的相似度
- 文本生成,机器编译等
- 定义:
- word2Vec 是谷歌2013年提出来的NLP工具,它的特点就是可以将单词转化为向量表示,这样就可以通过向量与向量之间的距离来度量它们之间的相似度,从而发现他们之间存在的潜在关系。
-
虽然现在深度学习比较广泛,但是其实word2vec并不是深度学习,因为在这个word2vec中,只是使用到了浅层的神经网络,同时它是计算词向量的一种开源工具,当我们说word2vec模型的时候,其实指的使它背后的CBOW和skip-gram算法,而word2vec本身并不是模型或者算法
- 词向量
- 定义:
- 将文字通过一串数字向量表示
- 表示方法
- 词的独热表示:One-hot Representation
- 采用稀疏方式 存储,简单易实现
- 灯泡:[0,0,0,0,0,1,0,0,0,0,0,0,0,0,0,0]、灯管:[0,0,0,0,0,0,0,1,0,0,0,0,0,0,0,0]
- 维度过大词汇鸿沟现象:任意两个词之间都是孤立的。光从这两个向量中看不出两个词是否有关系,哪怕”灯泡”和”灯管”这两个词是同义词也不行
- 词的分布式表示:Distributed representation
- 传统的独热表示( one-hot representation)仅仅将词符号化,不包含任何语义信息
- Distributed representation 最早由 Hinton在 1986 年提出。它是一种低维实数向量,这种向量一般长成这个样子: [0.792, −0.177, −0.107, 0.109, −0.542, …]
- 最大的贡献就是让相关或者相似的词,在距离上更接近了
- 词的独热表示:One-hot Representation
- 词向量的原理
- 统计语言模型: 统计语言模型把语言(词的序列)看作一个随机事件,并赋予相应的概率来描述其属于某种语言集合的可能性。例如:一个句子由w1,w2,w3,w4,w5,…….这些词组,使得P(w1,w2,w3,w4,w5……)概率大(可以从训练语料中得出)
- N-Gram
- 语言是一种序列,词与词之间并不是相互独立
- 一元模型(unigram model):假设某个出现的概率与前面所有词无关
- P(s) = P(w1)P(w2)P(w3)…P(w4)
- 二元模型(bigram model):假设某个出现的概率与前面一个词相关
- P(s) = P(w1)P(w2|w1)P(w3|w2)…P(w_i|w_i-1)
- 三元模型(trigram model):假设某个出现的概率与前面两个词相关
- P(s) = P(w1)P(w2|w1)P(w3|w1,w2)…P(w_i|w_i-2,w_i-1)
- 注:目前使用较多的是三元模型,由于训练语料限制,无法追求更大的N,并且N越大导致计算量越来越大
-
词向量计算得出
- 通过一个三层神经网络得出,由约书亚.本吉奥(Yoshua Bengio)提出word2vec模型
-
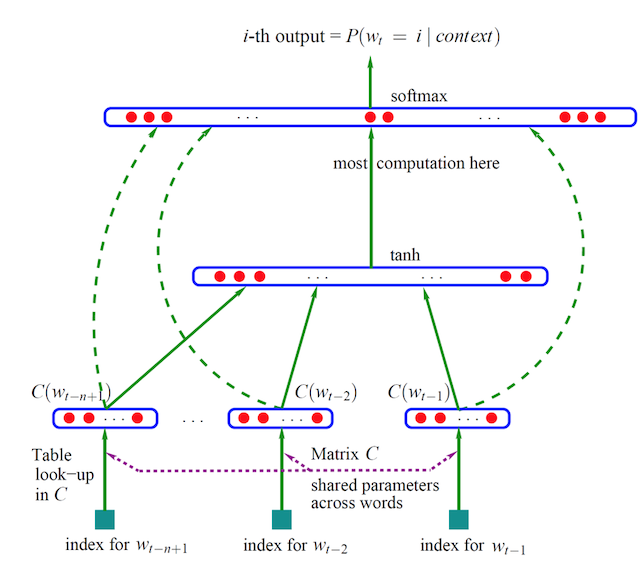
- 通过窗口输入句子中的连续三个词,w1,w2,w3
- 输入网络中已是初始化的向量,如w1:[0,0,0,0,…..,0],值的向量长度自定义
- 三个词向量,输入到网络中,目标值为原句子的后面一个w4,通过onehot编码定义
- 网络训练,网络参数更新,自动调整w1,w2,w3的向量值,达到经过最后的softmax(多分类概率),输出预测概率,与目标值计算损失
- 定义:



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 【自荐】一款简洁、开源的在线白板工具 Drawnix
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· Docker 太简单,K8s 太复杂?w7panel 让容器管理更轻松!