

文章画像得计算
一: 计算TF-IDF 值
1: 初始化spark环境

# 初始化spark信息 import os import sys BASE_DIR= os.path.dirname(os.path.dirname("/bigdata/projects/toutiao_projects/reco_sys/offline/full_cal")) sys.path.insert(0,os.path.join(BASE_DIR)) PYSPARK_PYTHON = "/usr/local/python3/bin/python3" # 当存在多个版本时,不指定很可能会导致出错 os.environ["PYSPARK_PYTHON"] = PYSPARK_PYTHON os.environ["PYSPARK_DRIVER_PYTHON"] = PYSPARK_PYTHON
2:初始化spark配置
""" 离线相关的计算 spark 初始化相关配置 """ from pyspark.sql import SparkSession from pyspark import SparkConf from pyspark.sql import HiveContext import os class SparkSessionBase(object): SPARK_APP_NAME = None SPARK_URL = 'local' SPARK_EXECUTOR_MEMORY = '2g' SPARK_EXECUTOR_CORE = 2 SPARK_EXECUTOR_INSTANCES = 2 ENABLE_HIVE_SUPPORT = False HIVE_URL = "hdfs://hadoop:9000//user/hive/warehouse" HIVE_METASTORE = "thrift://hadoop:9083" def _create_spark_session(self): conf = SparkConf() # 创建spark config 对象 config = ( ("spark.app.name",self.SPARK_APP_NAME), # 设置启动spark 的app名字 ("spark.executor.memory",self.SPARK_EXECUTOR_MEMORY), # 设置app启动时占用的内存用量 ('spark.executor.cores',self.SPARK_EXECUTOR_CORE), # 设置spark executor使用的CPU核心数,默认是1核心 ("spark.master", self.SPARK_URL), # spark master的地址 ("spark.executor.instances", self.SPARK_EXECUTOR_INSTANCES), ("spark.sql.warehouse.dir",self.HIVE_URL), ("hive.metastore.uris",self.HIVE_METASTORE), ) conf.setAll(config) # 利用config对象,创建spark session if self.ENABLE_HIVE_SUPPORT: # return "aaa" return SparkSession.builder.config(conf=conf).enableHiveSupport().getOrCreate() else: # return "bbb" return SparkSession.builder.config(conf=conf).getOrCreate()
3: 初始化变量
class TestSparkCountVectorizer(SparkSessionBase): def __init__(self): self.spark = self._create_spark_session() def _create_DataFrame(self): df = self.spark.createDataFrame([(1, 'T really liked this movie'), (2, 'I would recommend this movie to my friends'), (3, 'movie was alright but acting was horrible'), (4, 'I am never watching that movie ever again i liked it')], ['user_id', 'review']) return df
4: 利用pyspark.ml.feature.Tokenizer进行分词
""" 标记化 分词 :return: """ from pyspark.ml.feature import Tokenizer oa = TestSparkCountVectorizer() df = oa._create_DataFrame() # df.show() tokenization = Tokenizer(inputCol='review',outputCol='tokens') tokenization_df = tokenization.transform(df) tokenization_df.show()
+-------+--------------------+--------------------+ |user_id| review| tokens| +-------+--------------------+--------------------+ | 1|T really liked th...|[t, really, liked...| | 2|I would recommend...|[i, would, recomm...| | 3|movie was alright...|[movie, was, alri...| | 4|I am never watchi...|[i, am, never, wa..
5:利用 pyspark.ml.feature.StopWordsRemover 移除停用词
""" 停用词移除 :param df: :return: """ from pyspark.ml.feature import StopWordsRemover stopword_removal = StopWordsRemover(inputCol='tokens', outputCol='refind_tokens') refind_df = stopword_removal.transform(tokenization_df) refind_df.select(['user_id', 'tokens', 'refind_tokens']).show(4, False)
+-------+----------------------------------------------------------------+-------------------------------------+ |user_id|tokens |refind_tokens | +-------+----------------------------------------------------------------+-------------------------------------+ |1 |[t, really, liked, this, movie] |[really, liked, movie] | |2 |[i, would, recommend, this, movie, to, my, friends] |[recommend, movie, friends] | |3 |[movie, was, alright, but, acting, was, horrible] |[movie, alright, acting, horrible] | |4 |[i, am, never, watching, that, movie, ever, again, i, liked, it]|[never, watching, movie, ever, liked]| +-------+----------------------------------------------------------------+-------------------------------------+
6:利用pyspark.ml.feature.CountVectorizer 统计词频,训练词频模型,保存词频模型
CountVectorizer会统计特定文档中单词出现的次数,并且会根据单词的频率进行排序,频率高的排在前面,当频率相同时,则它的位置个人感觉是随机的。因为太多例子跑出来,每一次都不相同。
""" ####词袋 数值形式表示文本数据 ###计数向量器 会统计特定文档中单词出现的次数 :return: """ from pyspark.ml.feature import CountVectorizer count_vec = CountVectorizer(inputCol='refind_tokens', outputCol='features') # 训练词频统计模型 cv_model = count_vec.fit(refind_df) # cv_model.write().overwrite().save("hdfs://hadoop:9000/headlines/models/TestCV.model") # 将词频统计模型转换为 DataFrame cv_df = cv_model.transform(refind_df) cv_df.select(['user_id', 'refind_tokens', 'features']).show(4, False)
-------+-------------------------------------+--------------------------------------+ |user_id|refind_tokens |features | +-------+-------------------------------------+--------------------------------------+ |1 |[really, liked, movie] |(11,[0,1,4],[1.0,1.0,1.0]) | |2 |[recommend, movie, friends] |(11,[0,3,8],[1.0,1.0,1.0]) | |3 |[movie, alright, acting, horrible] |(11,[0,2,5,10],[1.0,1.0,1.0,1.0]) | |4 |[never, watching, movie, ever, liked]|(11,[0,1,6,7,9],[1.0,1.0,1.0,1.0,1.0])| +-------+-------------------------------------+--------------------------------------+
7:利用 pyspark.ml.feature.CountVectorizerModel加载词频模型,获取词频结果,利用pyspark.ml.feature.IDF 训练IDF模型
7.1. TF
在一份给定的文档d dd里,词频(term frequency,tf)指的是某一个给定的词语在该文档中出现的频率。这个数字是对词数(term count)的归一化,以防止它偏向长的文档。(同一个词语在长文档里可能会比短文档有更高的词数,而不管该词语重要与否。)对于在某一特定文档里的词语w i 来说,它的重要性可表示为:

7.2. IDF
逆向文档频率(inverse document frequency,idf)是一个词语普遍重要性的度量。某一特定词语的idf,可以由总文档数目除以包含该词语之文档的数目,再将得到的商取以10为底的对数得到:
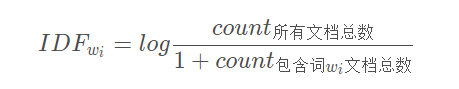
如果一个词越常见,那么分母就越大,逆文档频率(IDF)就越小越接近0。分母之所以要加1,是为了避免分母为0(即所有文档都不包含该词),log表示对得到的值取对数
7.3. TF-IDF
某一特定文档内的高词语频率,以及该词语在整个文档集合中的低文档频率,可以产生出高权重的tf-idf。因此,tf-idf倾向于过滤掉常见的词语,保留重要的词语。
T F − I D F = T F ∗ I D F
""" 训练idf模型 :return: """ # 1: 获取词频统计模型 from pyspark.ml.feature import CountVectorizerModel cv_model = CountVectorizerModel.load("hdfs://hadoop:9000/headlines/models/TestCV.model") # 2: 获取词频结果 cv_result = cv_model.transform(refind_df) print("-------------------------------词频结果-------------------------") cv_result.show()
-------------------------------词频结果------------------------- +-------+--------------------+--------------------+--------------------+--------------------+ |user_id| review| tokens| refind_tokens| features| +-------+--------------------+--------------------+--------------------+--------------------+ | 1|T really liked th...|[t, really, liked...|[really, liked, m...|(11,[0,1,4],[1.0,...| | 2|I would recommend...|[i, would, recomm...|[recommend, movie...|(11,[0,3,8],[1.0,...| | 3|movie was alright...|[movie, was, alri...|[movie, alright, ...|(11,[0,2,5,10],[1...| | 4|I am never watchi...|[i, am, never, wa...|[never, watching,...|(11,[0,1,6,7,9],[...| +-------+--------------------+--------------------+--------------------+--------------------+
# 3: 训练IDF模型 from pyspark.ml.feature import IDF idf = IDF(inputCol='features',outputCol='idfFeatures') idfModel = idf.fit(cv_result) idfModel.write().overwrite().save("hdfs://hadoop:9000/headlines/models/TestIDF.model") idf_result = idfModel.transform(cv_result) idf_result.show() print(cv_model.vocabulary) print(idfModel.idf.toArray()[:20])
+-------+--------------------+--------------------+--------------------+--------------------+--------------------+ |user_id| review| tokens| refind_tokens| features| idfFeatures| +-------+--------------------+--------------------+--------------------+--------------------+--------------------+ | 1|T really liked th...|[t, really, liked...|[really, liked, m...|(11,[0,1,4],[1.0,...|(11,[0,1,4],[0.0,...| | 2|I would recommend...|[i, would, recomm...|[recommend, movie...|(11,[0,3,8],[1.0,...|(11,[0,3,8],[0.0,...| | 3|movie was alright...|[movie, was, alri...|[movie, alright, ...|(11,[0,2,5,10],[1...|(11,[0,2,5,10],[0...| | 4|I am never watchi...|[i, am, never, wa...|[never, watching,...|(11,[0,1,6,7,9],[...|(11,[0,1,6,7,9],[...| +-------+--------------------+--------------------+--------------------+--------------------+--------------------+ ['movie', 'liked', 'horrible', 'recommend', 'really', 'alright', 'never', 'watching', 'friends', 'ever', 'acting'] [0. 0.51082562 0.91629073 0.91629073 0.91629073 0.91629073 0.91629073 0.91629073 0.91629073 0.91629073 0.91629073]
8:利用索引和IDF 值进行排序,并且将其显示为keyword得索引与IDF值对应
def func(partition): TOPK = 20 for row in partition: # 利用索引和IDf值进行排序 _ = list(zip( row.idfFeatures.indices,row.idfFeatures.values)) _ = sorted(_,key=lambda x:x[1],reverse=True) result = _[:TOPK] for word_index,word_value in result: yield row.user_id,int(word_index),round(float(word_value),4) _keywordsByTFIDF = idf_df.rdd.mapPartitions(func).toDF(["user_id","index","tfidf"]) _keywordsByTFIDF .show()
+-------+-----+------+ |user_id|index| tfidf| +-------+-----+------+ | 1| 4|0.9163| | 1| 1|0.5108| | 1| 0| 0.0| | 2| 3|0.9163| | 2| 8|0.9163| | 2| 0| 0.0| | 3| 2|0.9163| | 3| 5|0.9163| | 3| 10|0.9163| | 3| 0| 0.0| | 4| 6|0.9163| | 4| 7|0.9163| | 4| 9|0.9163| | 4| 1|0.5108| | 4| 0| 0.0| +-------+-----+------+
9:寻找 keyword 和IDF 得对应关系
#cv_model.vocabulary, idf_model.idf.toArray() 分别存储 keyword 与其对应得idf值
keywords_list_with_idf = list(zip(cv_model.vocabulary, idf_model.idf.toArray())) print(keywords_list_with_idf)
[('movie', 0.0), ('liked', 0.5108256237659907), ('horrible', 0.9162907318741551), ('recommend', 0.9162907318741551), ('really', 0.9162907318741551), ('alright', 0.9162907318741551), ('never', 0.9162907318741551), ('watching', 0.9162907318741551), ('friends', 0.9162907318741551), ('ever', 0.9162907318741551), ('acting', 0.9162907318741551)]
datas = [] for i in range(len( keywords_list_with_idf)): word = keywords_list_with_idf[i][0] idf = float(keywords_list_with_idf[1][1]) datas.append([word,idf,i]) print(datas)
[['movie', 0.5108256237659907, 0], ['liked', 0.5108256237659907, 1], ['horrible', 0.5108256237659907, 2], ['recommend', 0.5108256237659907, 3], ['really', 0.5108256237659907, 4], ['alright', 0.5108256237659907, 5], ['never', 0.5108256237659907, 6], ['watching', 0.5108256237659907, 7], ['friends', 0.5108256237659907, 8], ['ever', 0.5108256237659907, 9], ['acting', 0.5108256237659907, 10]]
将数组转换为RDD,再转换为DataFrame
oa = TestSparkCountVectorizer() sc = oa.spark.sparkContext rdd = sc.parallelize(datas) df = rdd.toDF(["keywords", "idf", "index"]) df.show()
+---------+------------------+-----+ | keywords| idf|index| +---------+------------------+-----+ | movie|0.5108256237659907| 0| | liked|0.5108256237659907| 1| | horrible|0.5108256237659907| 2| |recommend|0.5108256237659907| 3| | really|0.5108256237659907| 4| | alright|0.5108256237659907| 5| | never|0.5108256237659907| 6| | watching|0.5108256237659907| 7| | friends|0.5108256237659907| 8| | ever|0.5108256237659907| 9| | acting|0.5108256237659907| 10| +---------+------------------+-----+
将其结果进行合并
df.join(_keywordsByTFIDF,df.index==_keywordsByTFIDF.index).select(["user_id","keywords","tfidf"]).show()
+-------+---------+------+ |user_id| keywords| tfidf| +-------+---------+------+ | 1| movie| 0.0| | 2| movie| 0.0| | 3| movie| 0.0| | 4| movie| 0.0| | 1| liked|0.5108| | 4| liked|0.5108| | 3| horrible|0.9163| | 2|recommend|0.9163| | 1| really|0.9163| | 3| alright|0.9163| | 4| never|0.9163| | 4| watching|0.9163| | 2| friends|0.9163| | 4| ever|0.9163| | 3| acting|0.9163| +-------+---------+------+
10:保存至数据库
df.write.insertInto("表名")
二:计算TextRank 值
https://www.cnblogs.com/Live-up-to-your-youth/p/15985227.html
1:创建textrank_keywords_values表,存储TextRank 得值
CREATE TABLE textrank_keywords_values( article_id INT comment "article_id", channel_id INT comment "channel_id", keyword STRING comment "keyword", textrank DOUBLE comment "textrank");
2:过滤计算


# 分词 def textrank(partition): import os import jieba import jieba.analyse import jieba.posseg as pseg import codecs abspath = "/root/words" # 结巴加载用户词典 userDict_path = os.path.join(abspath, "ITKeywords.txt") jieba.load_userdict(userDict_path) # 停用词文本 stopwords_path = os.path.join(abspath, "stopwords.txt") def get_stopwords_list(): """返回stopwords列表""" stopwords_list = [i.strip() for i in codecs.open(stopwords_path).readlines()] return stopwords_list # 所有的停用词列表 stopwords_list = get_stopwords_list() class TextRank(jieba.analyse.TextRank): def __init__(self, window=20, word_min_len=2): super(TextRank, self).__init__() self.span = window # 窗口大小 self.word_min_len = word_min_len # 单词的最小长度 # 要保留的词性,根据jieba github ,具体参见https://github.com/baidu/lac self.pos_filt = frozenset( ('n', 'x', 'eng', 'f', 's', 't', 'nr', 'ns', 'nt', "nw", "nz", "PER", "LOC", "ORG")) def pairfilter(self, wp): """过滤条件,返回True或者False""" if wp.flag == "eng": if len(wp.word) <= 2: return False if wp.flag in self.pos_filt and len(wp.word.strip()) >= self.word_min_len \ and wp.word.lower() not in stopwords_list: return True # TextRank过滤窗口大小为5,单词最小为2 textrank_model = TextRank(window=5, word_min_len=2) allowPOS = ('n', "x", 'eng', 'nr', 'ns', 'nt', "nw", "nz", "c") for row in partition: tags = textrank_model.textrank(row.sentence, topK=20, withWeight=True, allowPOS=allowPOS, withFlag=False) for tag in tags: yield row.article_id, row.channel_id, tag[0], tag[1]
3:进行分词处理与存储
# 计算textrank textrank_keywords_df = article_dataframe.rdd.mapPartitions(textrank).toDF( ["article_id", "channel_id", "keyword", "textrank"]) # textrank_keywords_df.write.insertInto("textrank_keywords_values")
三: 文章画像结果
对文章进行计算画像
- 步骤:
- 1、加载IDF,保留关键词以及权重计算(TextRank * IDF)
- 2、合并关键词权重到字典结果
- 3、将tfidf和textrank共现的词作为主题词
- 4、将主题词表和关键词表进行合并,插入表
1:加载IDF,保留关键词以及权重计算(TextRank * IDF)
idf = ktt.spark.sql("select * from idf_keywords_values") idf = idf.withColumnRenamed("keyword", "keyword1") result = textrank_keywords_df.join(idf,textrank_keywords_df.keyword==idf.keyword1) keywords_res = result.withColumn("weights", result.textrank * result.idf).select(["article_id", "channel_id", "keyword", "weights"])
2:合并关键词权重到字典结果
keywords_res.registerTempTable("temptable") merge_keywords = ktt.spark.sql("select article_id, min(channel_id) channel_id, collect_list(keyword) keywords, collect_list(weights) weights from temptable group by article_id") # 合并关键词权重合并成字典 def _func(row): return row.article_id, row.channel_id, dict(zip(row.keywords, row.weights)) keywords_info = merge_keywords.rdd.map(_func).toDF(["article_id", "channel_id", "keywords"])
3:将tfidf和textrank共现的词作为主题词
topic_sql = """ select t.article_id article_id2, collect_set(t.keyword) topics from tfidf_keywords_values t inner join textrank_keywords_values r where t.keyword=r.keyword group by article_id2 """ article_topics = ktt.spark.sql(topic_sql)
4:将主题词表和关键词表进行合并
article_profile = keywords_info.join(article_topics, keywords_info.article_id==article_topics.article_id2).select(["article_id", "channel_id", "keywords", "topics"]) # articleProfile.write.insertInto("article_profile")
结果显示
hive> select * from article_profile limit 1; OK 26 17 {"策略":0.3973770571351729,"jpg":0.9806348975390871,"用户":1.2794959063944176,"strong":1.6488457985625076,"文件":0.28144603583387057,"逻辑":0.45256526469610714,"形式":0.4123994242601279,"全自":0.9594604850547191,"h2":0.6244481634710125,"版本":0.44280276959510817,"Adobe":0.8553618185108718,"安装":0.8305037437573172,"检查更新":1.8088946300014435,"产品":0.774842382276899,"下载页":1.4256311032544344,"过程":0.19827163395829256,"json":0.6423301791599972,"方式":0.582762869780791,"退出应用":1.2338671268242603,"Setup":1.004399549339134} ["Electron","全自动","产品","版本号","安装包","检查更新","方案","版本","退出应用","逻辑","安装过程","方式","定性","新版本","Setup","静默","用户"] Time taken: 0.322 seconds, Fetched: 1 row(s)



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· winform 绘制太阳,地球,月球 运作规律
· 超详细:普通电脑也行Windows部署deepseek R1训练数据并当服务器共享给他人
· 上周热点回顾(3.3-3.9)
· AI 智能体引爆开源社区「GitHub 热点速览」
· 写一个简单的SQL生成工具