
flume
一、Flume安装部署
1.1、安装地址
1) Flume 官网地址
2)文档查看地址
http://flume.apache.org/FlumeUserGuide.html
3)下载地址
http://archive.apache.org/dist/flume/
2.2、安装部署
1)将 apache-flume-1.7.0-bin.tar.gz 上传到 linux 的/opt/software 目录下 2)解压 apache-flume-1.7.0-bin.tar.gz 到/opt/module/目录下 [hadoop@hadoop102 software]$ tar -zxf apache-flume-1.7.0-bin.tar.gz -C /opt/module/ 3)修改 apache-flume-1.7.0-bin 的名称为 flume [hadoop@hadoop102 module]$ mv apache-flume-1.7.0-bin flume 4)将 flume/conf 下的 flume-env.sh.template 文件修改为 flume-env.sh,并配置 flumeenv.sh 文件 [hadoop@hadoop102 conf]$ mv flume-env.sh.template flume-env.sh [hadoop@hadoop102 conf]$ vi flume-env.sh export JAVA_HOME=/opt/module/jdk1.8.0_144
|
|

5)配置环境变量
[root@hadoop ~]# cat ~/.bashrc # .bashrc # User specific aliases and functions alias rm='rm -i' alias cp='cp -i' alias mv='mv -i' # Source global definitions if [ -f /etc/bashrc ]; then . /etc/bashrc fi export PYTHON_HOME=/usr/local/python3 export PATH=$PYTHON_HOME/bin:$PYTHON_HOME/sbin:$PATH export HADOOP_HOME=/bigdata/hadoop-2.10.1 export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH export HIVE_HOME=/bigdata/apache-hive-1.2.2-bin export PATH=$HIVE_HOME/bin:$PATH export HBASE_HOME=/bigdata/hbase-2.3.7 export PATH=$HBASE_HOME/bin:$HBASE_HOME/sbin:$PATH export MAVEN__HOME=/bigdata/apache-maven-3.3.9 export PATH=$MAVEN_HOME/bin:$MAVEN_HOME/sbin:$PATH export SPARK_HOME=/bigdata/spark-3.2.0-bin-hadoop3.2 export PATH=$SPARK_HOME/bin:$SPARK_HOME/sbin:$PATH export ZOOKEEPER_HOME=/bigdata/apache-hive-1.2.2-bin export PATH=$ZOOKEEPER_HOME/bin:$PATH export SQOOP_HOME=/bigdata/sqoop export PATH=$SQOOP_HOME/bin:$PATH export FLUME_HOME=/bigdata/flume export PATH=$FLUME_HOME/bin:$PATH
6)查看版本
[hadoop@hadoop102 ~]$ flume-ng version Flume 1.7.0 Source code repository: https://git-wip-us.apache.org/repos/asf/flume.git Revision: 511d868555dd4d16e6ce4fedc72c2d1454546707 Compiled by bessbd on Wed Oct 12 20:51:10 CEST 2016 From source with checksum 0d21b3ffdc55a07e1d08875872c00523
二:通过flume将业务数据服务器A的日志收集到hadoop服务器hdfs的hive中
1:flume 配置
官方文档 https://flume.apache.org/releases/content/1.7.0/FlumeUserGuide.html
- 进入flume/conf目录
创建一个collect_click.conf的文件,写入flume的配置
- sources:为实时查看文件末尾,interceptors解析json文件
- channels:指定内存存储,并且制定batchData的大小,PutList和TakeList的大小见参数,Channel总容量大小见参数
- 指定sink:形式直接到hdfs,以及路径,文件大小策略默认1024、event数量策略、文件闲置时间
collect_click.conf
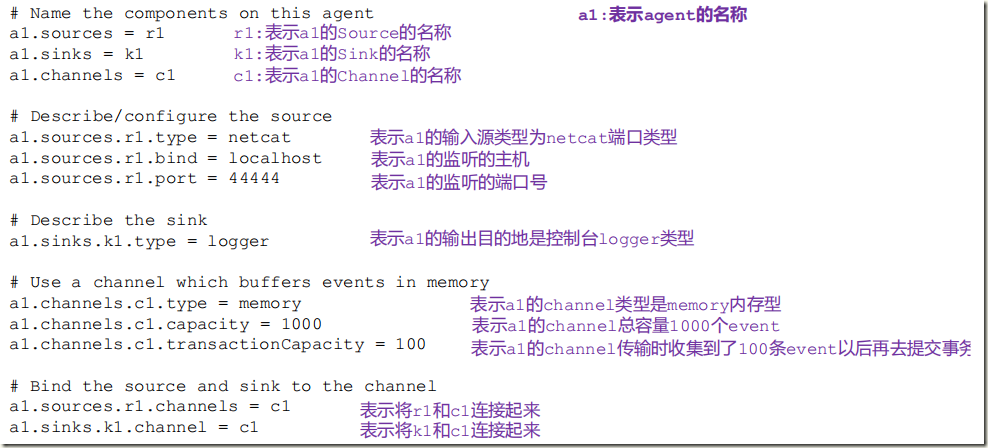
[root@hadoop conf]# cat collect_click.conf a1.sources = s1 a1.sinks = k1 a1.channels = c1 a1.sources.s1.channels= c1 a1.sources.s1.type = exec a1.sources.s1.command = tail -F /root/logs/userClick.log #日志目录 a1.sources.s1.interceptors=i1 i2 a1.sources.s1.interceptors.i1.type=regex_filter a1.sources.s1.interceptors.i1.regex=\\{.*\\} # 匹配json a1.sources.s1.interceptors.i2.type=timestamp # channel1 a1.channels.c1.type=memory a1.channels.c1.capacity=30000 a1.channels.c1.transactionCapacity=1000 # k1 a1.sinks.k1.type=hdfs a1.sinks.k1.channel=c1 a1.sinks.k1.hdfs.path=hdfs://192.168.50.129:9000/user/hive/warehouse/profile.db/user_action/%Y-%m-%d # hdfs 的存储目录 a1.sinks.k1.hdfs.useLocalTimeStamp = true a1.sinks.k1.hdfs.fileType=DataStream a1.sinks.k1.hdfs.writeFormat=Text a1.sinks.k1.hdfs.rollInterval=0 a1.sinks.k1.hdfs.rollSize=10240 a1.sinks.k1.hdfs.rollCount=0 a1.sinks.k1.hdfs.idleTimeout=60 [root@hadoop conf]#
2: hive 的配置
解决办法可以按照日期分区
- 修改表结构
- 修改flume
在这里我们创建一个新的数据库profile,表示用户相关数据,画像存储到这里
create database if not exists profile comment "use action" location '/user/hive/warehouse/profile.db/';
在profile数据库中创建user_action表,指定格式
create table user_action( actionTime STRING comment "user actions time", readTime STRING comment "user reading time", channelId INT comment "article channel id", param map<string, string=""> comment "action parameter") COMMENT "user primitive action" PARTITIONED BY(dt STRING) # 分区 ROW FORMAT SERDE 'org.apache.hive.hcatalog.data.JsonSerDe' LOCATION '/user/hive/warehouse/profile.db/user_action';
- ROW FORMAT SERDE 'org.apache.hive.hcatalog.data.JsonSerDe':添加一个json格式匹配
重要:这样就有HIVE的user_action表,并且hadoop有相应目录,flume会自动生成目录,但是如果想要通过spark sql 获取内容,每天每次还是要主动关联,后面知识点会提及)
# 如果flume自动生成目录后,需要手动关联分区 alter table user_action add partition (dt='2018-12-11') location "/user/hive/warehouse/profile.db/user_action/2018-12-11/"
3. 开启收集命令
flume-ng agent -c /root/bigdata/flume/conf -f /root/bigdata/flume/conf/collect_click.conf -Dflume.root.logger=INFO,console -name a1
在可视化页面中查看 http://192.168.50.129:50070/explorer.html#/user/hive/warehouse/profile.db/user_action/2022-02-17
在hive 中查询
hive> alter table user_action add partition (dt='2022-02-17') location "/user/hive/warehouse/profile.db/user_action/2022-02-17/"; OK Time taken: 0.317 seconds hive> select * from user_action where dt='2022-02-17'; OK 2019-04-10 18:15:32 18 {"action":"click","userId":"2","articleId":"18005","algorithmCombine":"C2"} 2022-02-17 2019-04-10 18:15:34 1053 18 {"action":"read","userId":"2","articleId":"18005","algorithmCombine":"C2"} 2022-02-17 2019-04-10 18:15:36 18 {"action":"click","userId":"2","articleId":"18577","algorithmCombine":"C2"} 2022-02-17 2019-04-10 18:15:38 1621 18 {"action":"read","userId":"2","articleId":"18577","algorithmCombine":"C2"} 2022-02-17 2019-04-10 18:15:39 18 {"action":"click","userId":"1","articleId":"14299","algorithmCombine":"C2"} 2022-02-17 2019-04-10 18:15:39 18 {"action":"click","userId":"2","articleId":"14299","algorithmCombine":"C2"} 2022-02-17 2019-04-10 18:15:41 914 18 {"action":"read","userId":"2","articleId":"14299","algorithmCombine":"C2"} 2022-02-17 2019-04-10 18:15:47 7256 18 {"action":"read","userId":"1","articleId":"14299","algorithmCombine":"C2"} 2022-02-17 2019-04-10 21:04:39 18 {"action":"click","userId":"2","articleId":"14299","algorithmCombine":"C2"} 2022-02-17 2019-04-10 21:04:39 18 {"action":"click","userId":"2","articleId":"14299","algorithmCombine":"C2"} 2022-02-17 2019-04-10 21:04:39 18 {"action":"click","userId":"2","articleId":"14299","algorithmCombine":"C2"} 2022-02-17 2019-04-10 21:04:39 18 {"action":"click","userId":"2","articleId":"14299","algorithmCombine":"C2"} 2022-02-17 2019-04-10 21:04:39 18 {"action":"click","userId":"2","articleId":"14299","algorithmCombine":"C2"} 2022-02-17 2019-04-10 21:04:39 18 {"action":"click","userId":"2","articleId":"14299","algorithmCombine":"C2"} 2022-02-17 2019-04-10 21:04:39 18 {"action":"click","userId":"2","articleId":"14299","algorithmCombine":"C2"} 2022-02-17 Time taken: 0.358 seconds, Fetched: 15 row(s) hive>

