1.hadoop
1: hadoop 核心组件
-
-
如何存储持续增长的海量网页: 单节点 V.S. 分布式存储
-
如何对持续增长的海量网页进行排序: 超算 V.S. 分布式计算
-
HDFS 解决分布式存储问题
-
-
-
-
源自于Google的GFS论文, 论文发表于2003年10月
-
HDFS是GFS的开源实现
-
HDFS的特点:扩展性&容错性&海量数量存储
-
将文件切分成指定大小的数据块, 并在多台机器上保存多个副本
-
-
-
-
分布式计算框架
-
源于Google的MapReduce论文,论文发表于2004年12月
-
MapReduce是GoogleMapReduce的开源实现
-
-
-
YARN: Yet Another Resource Negotiator
-
负责整个集群资源的管理和调度
-
-
2. Hadoop优势
-
高可靠
-
数据存储: 数据块多副本
-
-
-
高扩展性
-
存储/计算资源不够时,可以横向的线性扩展机器
-
一个集群中可以包含数以千计的节点
-
集群可以使用廉价机器,成本低
-
-
Hadoop生态系统成熟
3:hadoop 环境搭建(2.10.1)
1:下载: https://dlcdn.apache.org/hadoop/common/hadoop-2.10.1/hadoop-2.10.1.tar.gz
2: 解压:
tar -zxvf 压缩包名字
配置环境变量
vi ~/.bashrc export JAVA_HOME=/home/hadoop/app/jdk1.8.0_91 export PATH=$JAVA_HOME/bin:$PATH export HADOOP_HOME=/home/hadoop/app/hadoop...... export PATH=$HADOOP_HOME/bin:$PATH #保存退出后 source ~/.bashrc
-
配置文件作用
-
core-site.xml 指定hdfs的访问方式
-
hdfs-site.xml 指定namenode 和 datanode 的数据存储位置
-
mapred-site.xml 配置mapreduce
-
yarn-site.xml 配置yarn
-
-
cd etc/hadoop vi hadoop-env.sh #找到下面内容添加java home export_JAVA_HOME=/usr/local/java/jdk1.8.0_91
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://hadoop:9000</value>
</property>
</configuration>
- 修改hdfs-site.xml 在 configuration节点中添加
<configuration> <property> <name>dfs.name.dir</name> <value>/bigdata/hadoop-2.10.1/tmp/hdfs/name</value> </property> <property> <name>dfs.data.dir</name> <value>/bigdata/hadoop-2.10.1/tmp/hdfs/data</value> </property> <property> <name>dfs.replication</name> <value>1</value> </property> </configuration>
cp mapred-site.xml.template mapred-site.xml
在mapred-site.xml 的configuration 节点中添加
<property> <name>mapreduce.framework.name</name> <value>yarn</value> </property>
- 修改yarn-site.xml configuration 节点中添加
<property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property>
- 来到hadoop的bin目录
./hadoop namenode -format (这个命令只运行一次)
- 启动hdfs 进入到 sbin
./start-dfs.sh
./start-yarn.sh
- 通过jps命令查看当前运行的进程
[root@hadoop sbin]# jps
4160 Jps
3890 NodeManager
3077 NameNode
3257 DataNode
3517 SecondaryNameNode
3711 ResourceManager
4:HDFS 分布式文件系统
1:HDFS shell操作
-
调用文件系统(FS)Shell命令应使用 bin/hadoop fs <args>的形式
-
ls
使用方法:hadoop fs -ls <args>
如果是文件,则按照如下格式返回文件信息: 文件名 <副本数> 文件大小 修改日期 修改时间 权限 用户ID 组ID 如果是目录,则返回它直接子文件的一个列表,就像在Unix中一样。目录返回列表的信息如下: 目录名 <dir> 修改日期 修改时间 权限 用户ID 组ID 示例: hadoop fs -ls /user/hadoop/file1 /user/hadoop/file2 hdfs://host:port/user/hadoop/dir1 /nonexistentfile 返回值: 成功返回0,失败返回-1。
-
text
使用方法:hadoop fs -text <src>
将源文件输出为文本格式。允许的格式是zip和TextRecordInputStream。
-
mv
使用方法:hadoop fs -mv URI [URI …] <dest>
将文件从源路径移动到目标路径。这个命令允许有多个源路径,此时目标路径必须是一个目录。不允许在不同的文件系统间移动文件。 示例:
-
hadoop fs -mv /user/hadoop/file1 /user/hadoop/file2
-
hadoop fs -mv hdfs://host:port/file1 hdfs://host:port/file2 hdfs://host:port/file3 hdfs://host:port/dir1
返回值:
成功返回0,失败返回-1。
-
-
put
使用方法:hadoop fs -put <localsrc> ... <dst>
从本地文件系统中复制单个或多个源路径到目标文件系统。也支持从标准输入中读取输入写入目标文件系统。
-
hadoop fs -put localfile /user/hadoop/hadoopfile
-
hadoop fs -put localfile1 localfile2 /user/hadoop/hadoopdir
-
hadoop fs -put localfile hdfs://host:port/hadoop/hadoopfile
-
hadoop fs -put - hdfs://host:port/hadoop/hadoopfile 从标准输入中读取输入。
返回值:
成功返回0,失败返回-1。
-
-
rm
使用方法:hadoop fs -rm URI [URI …]
删除指定的文件。只删除非空目录和文件。请参考rmr命令了解递归删除。 示例:
-
hadoop fs -rm hdfs://host:port/file /user/hadoop/emptydir
返回值:
成功返回0,失败返回-1。
-
-
2. HDFS shell操作练习
-
在centos 中创建 test.txt
touch test.txt -
在centos中为test.txt 添加文本内容
vi test.txt -
在HDFS中创建 hadoop001/test 文件夹
hadoop fs -mkdir -p /hadoop001/test -
把text.txt文件上传到HDFS中
hadoop fs -put test.txt /hadoop001/test/ -
hadoop fs -cat /hadoop001/test/test.txt -
将hdfs中 hadoop001/test/test.txt文件下载到centos
hadoop fs -get /hadoop001/test/test.txt test.txt -
删除HDFS中 hadoop001/test/
hadoop fs -rm -r /hadoop001
-
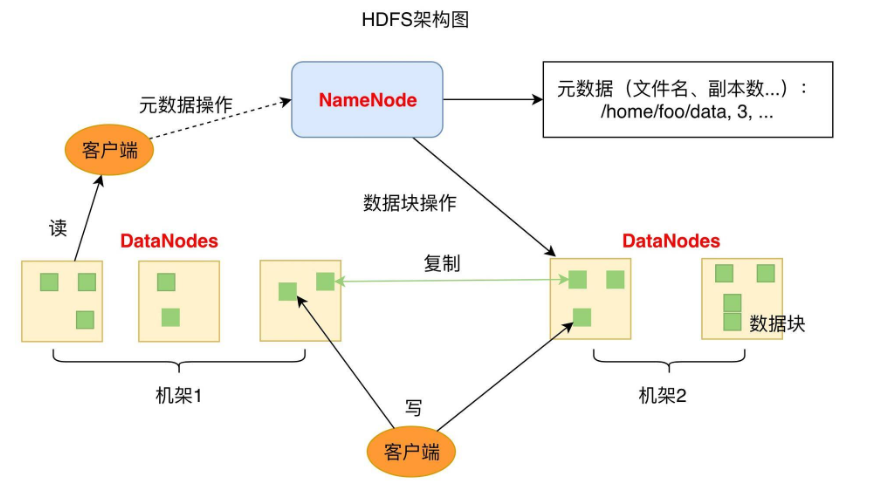
3 HDFS架构
-
1个NameNode/NN(Master) 带 DataNode/DN(Slaves) (Master-Slave结构)
-
1个文件会被拆分成多个Block
-
NameNode(NN)
-
负责客户端请求的响应
-
负责元数据(文件的名称、副本系数、Block存放的DN)的管理
-
元数据 MetaData 描述数据的数据
-
-
监控DataNode健康状况 10分钟没有收到DataNode报告认为Datanode死掉了
-
-
DataNode(DN)
-
-
要定期向NN发送心跳信息,汇报本身及其所有的block信息,健康状况
-
-
分布式集群NameNode和DataNode部署在不同机器上
-
优点
-
数据冗余 硬件容错
-
适合存储大文件
-
处理流式数据
-
可构建在廉价机器上
-
-
缺点
-
低延迟的数据访问
-
-
5:资源调度框架 YARN
1 什么是YARN
-
Yet Another Resource Negotiator, 另一种资源协调者
-
通用资源管理系统
-
为上层应用提供统一的资源管理和调度,为集群在利用率、资源统一管理和数据共享等方面带来了巨大好处
-
通用资源管理系统
-
Hadoop数据分布式存储(数据分块,冗余存储)
-
当多个MapReduce任务要用到相同的hdfs数据, 需要进行资源调度管理
-
Hadoop1.x时并没有YARN,MapReduce 既负责进行计算作业又处理服务器集群资源调度管理
-
-
服务器集群资源调度管理和MapReduce执行过程耦合在一起带来的问题
-
Hadoop早期, 技术只有Hadoop, 这个问题不明显
-
随着大数据技术的发展,Spark Storm ... 计算框架都要用到服务器集群资源
-
如果没有通用资源管理系统,只能为多个集群分别提供数据
-
资源利用率低 运维成本高
-
-
-
3 YARN的架构和执行流程
-
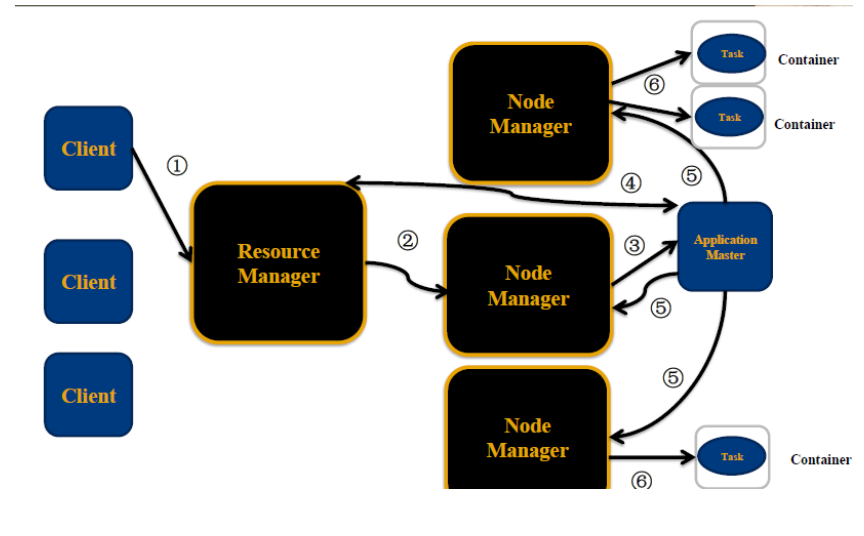
ResourceManager: RM 资源管理器 整个集群同一时间提供服务的RM只有一个,负责集群资源的统一管理和调度 处理客户端的请求: submit, kill 监控我们的NM,一旦某个NM挂了,那么该NM上运行的任务需要告诉我们的AM来如何进行处理
-
NodeManager: NM 节点管理器 整个集群中有多个,负责自己本身节点资源管理和使用 定时向RM汇报本节点的资源使用情况 接收并处理来自RM的各种命令:启动Container 处理来自AM的命令
-
ApplicationMaster: AM 每个应用程序对应一个:MR、Spark,负责应用程序的管理 为应用程序向RM申请资源(core、memory),分配给内部task 需要与NM通信:启动/停止task,task是运行在container里面,AM也是运行在container里面
-
Container 容器: 封装了CPU、Memory等资源的一个容器,是一个任务运行环境的抽象
-
Client: 提交作业 查询作业的运行进度,杀死作业
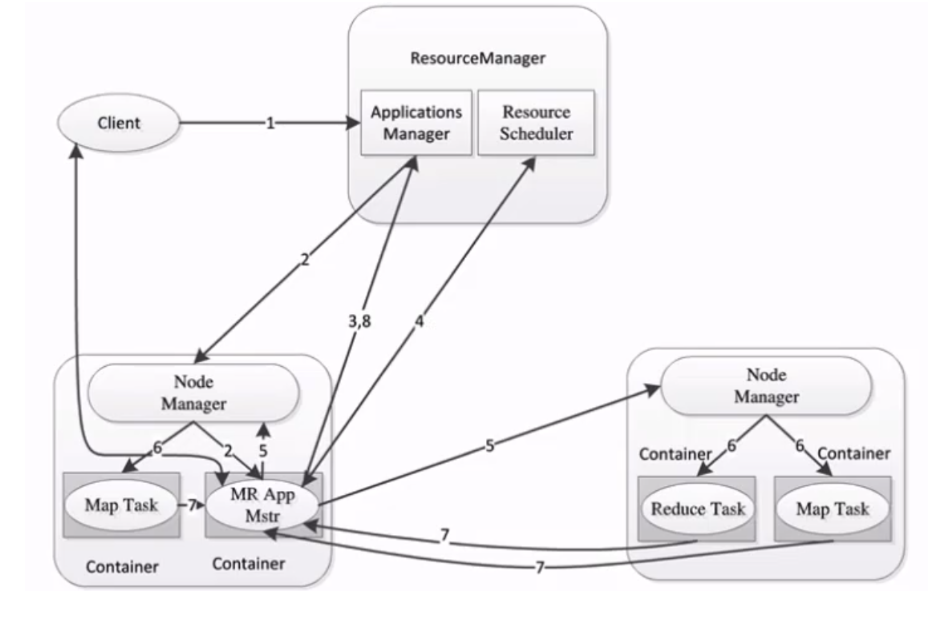
- 1,Client提交作业请求
- 2,ResourceManager 进程和 NodeManager 进程通信,根据集群资源,为用户程序分配第一个Container(容器),并将 ApplicationMaster 分发到这个容器上面
- 3,在启动的Container中创建ApplicationMaster
- 5,ApplicationMaster申请到资源后,向对应的NodeManager申请启动Container,将要执行的程序分发到NodeManager上
- 6,Container启动后,执行对应的任务
- 7,Tast执行完毕之后,向ApplicationMaster返回结果
- 8,ApplicationMaster向ResourceManager 请求kill
sbin/start-yarn.sh
jps 验证
[root@hadoop sbin]# jps 3584 NameNode 4214 ResourceManager 4392 NodeManager 3770 DataNode 4027 SecondaryNameNode 8779 Jps 8541 RunJar [root@hadoop sbin]#
访问:
http://192.168.50.129:8088/cluster
1 什么是MapReduce
-
源于Google的MapReduce论文(2004年12月)
-
Hadoop的MapReduce是Google论文的开源实现
-
MapReduce优点: 海量数据离线处理&易开发
-
2 MapReduce编程模型
-
MapReduce分而治之的思想
-
数钱实例:一堆钞票,各种面值分别是多少
-
单点策略
-
一个人数所有的钞票,数出各种面值有多少张
-
-
分治策略
-
每个人分得一堆钞票,数出各种面值有多少张
-
汇总,每个人负责统计一种面值
-
-
解决数据可以切割进行计算的应用
-
-
-
MapReduce编程分Map和Reduce阶段
-
将作业拆分成Map阶段和Reduce阶段
-
Map阶段 Map Tasks 分:把复杂的问题分解为若干"简单的任务"
-
Reduce阶段: Reduce Tasks 合:reduce
-
-
MapReduce编程执行步骤
-
准备MapReduce的输入数据
-
准备Mapper数据
-
Shuffle
-
Reduce处理
-
结果输出
-
-
编程模型
-
借鉴函数式编程方式
-
用户只需要实现两个函数接口:
-
Map(in_key,in_value)
--->(out_key,intermediate_value) list
-
Reduce(out_key,intermediate_value) list
--->out_value list
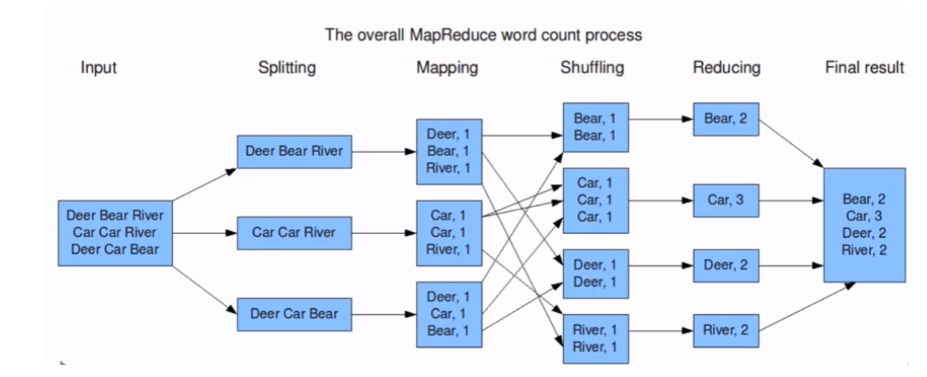
- Word Count 词频统计案例
-
-
Word Count 词频统计案例
-
3 Hadoop Streaming 实现wordcount (实验 了解)
Mapper
import sys #输入为标准输入stdin for line in sys.stdin: #删除开头和结尾的空行 line = line.strip() #以默认空格分隔单词到words列表 words = line.split() for word in words: #输出所有单词,格式为“单词 1”以便作为Reduce的输入 print("%s %s"%(word,1))
Reducer
import sys current_word = None current_count = 0 word = None #获取标准输入,即mapper.py的标准输出 for line in sys.stdin: #删除开头和结尾的空行 line = line.strip() #解析mapper.py输出作为程序的输入,以tab作为分隔符 word,count = line.split() #转换count从字符型到整型 try: count = int(count) except ValueError: #count非数字时,忽略此行 continue #要求mapper.py的输出做排序(sort)操作,以便对连续的word做判断 if current_word == word: current_count += count else : #出现了一个新词 #输出当前word统计结果到标准输出 if current_word : print('%s\t%s' % (current_word,current_count)) #开始对新词的统计 current_count = count current_word = word
#输出最后一个word统计
if current_word == word:
print("%s\t%s"% (current_word,current_count))
-
得到最终的输出
注:hadoop-streaming会主动将map的输出数据进行字典排序
-
STREAM_JAR_PATH="/root/bigdata/hadoop/share/hadoop/tools/lib/hadoop-streaming-2.9.1.jar" # hadoop streaming jar包所在位置 INPUT_FILE_PATH_1="/The_Man_of_Property.txt" #要进行词频统计的文档在hdfs中的路径 OUTPUT_PATH="/output" #MR作业后结果的存放路径 hadoop fs -rm -r -skipTrash $OUTPUT_PATH # 输出路径如果之前存在 先删掉否则会报错 hadoop jar $STREAM_JAR_PATH \ -input $INPUT_FILE_PATH_1 \ # 指定输入文件位置 -output $OUTPUT_PATH \ #指定输出结果位置 -mapper "python map.py" \ #指定mapper执行的程序 -reducer "python red.py" \ # 指定reduce阶段执行的程序 -file ./map.py \ # 通过-file 把python源文件分发到集群的每一台机器上 -file ./red.py
1 利用MRJob编写和运行MapReduce代码
mrjob 简介
-
使用python开发在Hadoop上运行的程序, mrjob是最简单的方式
-
mrjob程序可以在本地测试运行也可以部署到Hadoop集群上运行
-
如果不想成为hadoop专家, 但是需要利用Hadoop写MapReduce代码,mrJob是很好的选择
mrjob 安装
-
使用pip安装
-
pip install mrjob
-
mrjob实现WordCount
from mrjob.job import MRJob class MRWordFrequencyCount(MRJob): def mapper(self, _, line): yield "chars", len(line) yield "words", len(line.split()) yield "lines", 1 def reducer(self, key, values): yield key, sum(values) if __name__ == '__main__': MRWordFrequencyCount.run()
运行WordCount代码
打开命令行, 找到一篇文本文档, 敲如下命令:
python mr_word_count.py my_file.txt
2 运行MRJOB的不同方式
1、内嵌(-r inline)方式
特点是调试方便,启动单一进程模拟任务执行状态和结果,默认(-r inline)可以省略,输出文件使用 > output-file 或-o output-file,比如下面两种运行方式是等价的
python word_count.py -r inline input.txt > output.txt python word_count.py input.txt > output.txt
2、本地(-r local)方式
用于本地模拟Hadoop调试,与内嵌(inline)方式的区别是启动了多进程执行每一个任务。如:
python word_count.py -r local input.txt > output1.txt
3、Hadoop(-r hadoop)方式
用于hadoop环境,支持Hadoop运行调度控制参数,如:
1)指定Hadoop任务调度优先级(VERY_HIGH|HIGH),如:--jobconf mapreduce.job.priority=VERY_HIGH。
2)Map及Reduce任务个数限制,如:--jobconf mapreduce.map.tasks=2 --jobconf mapreduce.reduce.tasks=5
python word_count.py -r hadoop hdfs:///test.txt -o hdfs:///output
3 :mrjob 实现 topN统计(实验)
统计数据中出现次数最多的前n个数据
import sys from mrjob.job import MRJob,MRStep import heapq class TopNWords(MRJob): def mapper(self, _, line): if line.strip() != "": for word in line.strip().split(): yield word,1 #介于mapper和reducer之间,用于临时的将mapper输出的数据进行统计 def combiner(self, word, counts): yield word,sum(counts) def reducer_sum(self, word, counts): yield None,(sum(counts),word) #利用heapq将数据进行排序,将最大的2个取出 def top_n_reducer(self,_,word_cnts): for cnt,word in heapq.nlargest(2,word_cnts): yield word,cnt #实现steps方法用于指定自定义的mapper,comnbiner和reducer方法 def steps(self): return [ MRStep(mapper=self.mapper, combiner=self.combiner, reducer=self.reducer_sum), MRStep(reducer=self.top_n_reducer) ] def main(): TopNWords.run() if __name__=='__main__': main()
8:MapReduce原理详解
单机程序计算流程
输入数据--->读取数据--->处理数据--->写入数据--->输出数据
Hadoop计算流程
input data:输入数据
InputFormat:对数据进行切分,格式化处理
map:将前面切分的数据做map处理(将数据进行分类,输出(k,v)键值对数据)
shuffle&sort:将相同的数据放在一起,并对数据进行排序处理
reduce:将map输出的数据进行hash计算,对每个map数据进行统计计算
OutputFormat:格式化输出数据
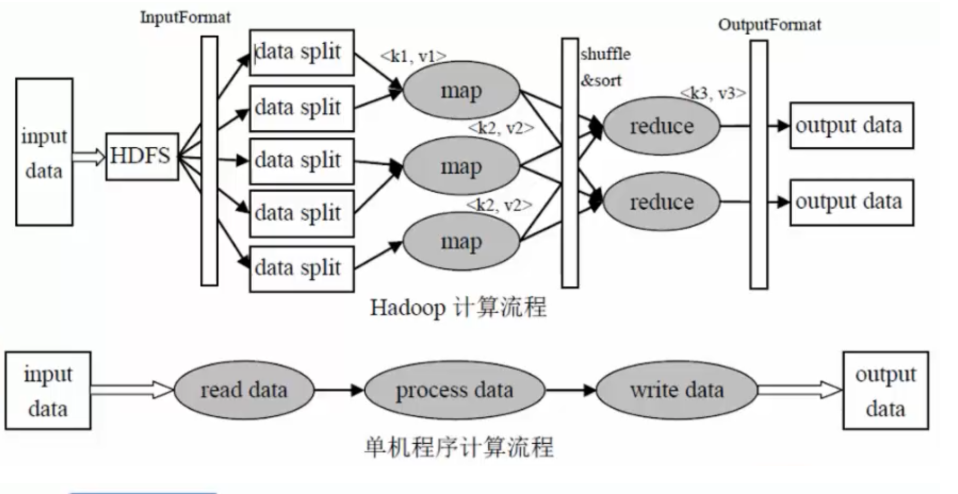
map:将数据进行处理
buffer in memory:达到80%数据时,将数据锁在内存上,将这部分输出到磁盘上
partitions:在磁盘上有很多"小的数据",将这些数据进行归并排序。
merge on disk:将所有的"小的数据"进行合并。
reduce:不同的reduce任务,会从map中对应的任务中copy数据
在reduce中同样要进行merge操作
2 MapReduce架构
-
ResourceManager:负责资源的管理,负责提交任务到NodeManager所在的节点运行,检查节点的状态
-