
4.线性回归api与波士顿房价预测案例
线性回归api再介绍
- sklearn.linear_model.LinearRegression(fit_intercept=True)
- 通过正规方程优化
- fit_intercept:是否计算偏置
- LinearRegression.coef_:回归系数
- LinearRegression.intercept_:偏置
- sklearn.linear_model.SGDRegressor(loss="squared_loss", fit_intercept=True, learning_rate ='invscaling', eta0=0.01)
- SGDRegressor类实现了随机梯度下降学习,它支持不同的loss函数和正则化惩罚项来拟合线性回归模型。
- loss:损失类型
- loss=”squared_loss”: 普通最小二乘法
- fit_intercept:是否计算偏置
- learning_rate : string, optional
- 学习率填充
- 'constant': eta = eta0
- 'optimal': eta = 1.0 / (alpha * (t + t0)) [default]
- 'invscaling': eta = eta0 / pow(t, power_t)
- power_t=0.25:存在父类当中
- 对于一个常数值的学习率来说,可以使用learning_rate=’constant’ ,并使用eta0来指定学习率。
- SGDRegressor.coef_:回归系数
- SGDRegressor.intercept_:偏置
波士顿房价预测
1:数据集介绍


给定的这些特征,是专家们得出的影响房价的结果属性。我们此阶段不需要自己去探究特征是否有用,只需要使用这些特征。到后面量化很多特征需要我们自己去寻找
1 分析
回归当中的数据大小不一致,是否会导致结果影响较大。所以需要做标准化处理。
- 数据分割与标准化处理
- 回归预测
- 线性回归的算法效果评估
2 回归性能评估
均方误差(Mean Squared Error)MSE)评价机制:
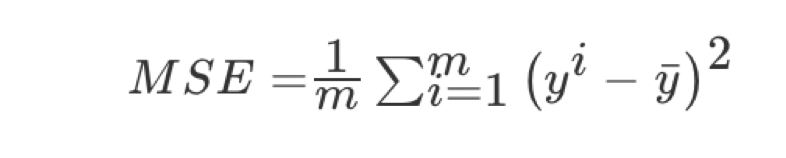
注:yi为预测值,¯y为真实值
- sklearn.metrics.mean_squared_error(y_true, y_pred)
- 均方误差回归损失
- y_true:真实值
- y_pred:预测值
- return:浮点数结果
代码:


# 波士顿数据集 from sklearn.datasets import load_boston # 数据集划分 from sklearn.model_selection import train_test_split # 特征处理 from sklearn.preprocessing import StandardScaler #机器学习 from sklearn.linear_model import LinearRegression,SGDRegressor # 均方误差 from sklearn.metrics import mean_squared_error def line_model1(): """ 线性回归:正规方程 :return: """ #1. 获取数据集 data = load_boston() #2. 数据集划分 x_train,x_test,y_train,y_test= train_test_split(data.data,data.target,random_state=22) # 3. 特征工程 (transfer 转换器) transfer = StandardScaler() x_train = transfer.fit_transform(x_train) x_test = transfer.fit_transform(x_test) # 4. 机器学习 (线性回归方程) estimator:评估器 estimator = LinearRegression() estimator.fit(x_train,y_train) #5. 模型评估 # 5.1 获取系数等值 y_predict = estimator.predict(x_test) print("预测值为:\n", y_predict) print("模型中的系数为:\n", estimator.coef_) print("模型中的偏置为:\n", estimator.intercept_) #5.2 评价 #均方差 error = mean_squared_error(y_test,y_predict) print("误差为:\n", error) def linear_model2(): """ 线性回归:梯度下降法 :return:None """ # 1.获取数据 data = load_boston() # 2.数据集划分 x_train, x_test, y_train, y_test = train_test_split(data.data, data.target, random_state=22) # 3.特征工程-标准化 transfer = StandardScaler() x_train = transfer.fit_transform(x_train) x_test = transfer.fit_transform(x_test) # 4.机器学习-线性回归(特征方程) estimator = SGDRegressor(max_iter=1000) estimator.fit(x_train, y_train) # 5.模型评估 # 5.1 获取系数等值 y_predict = estimator.predict(x_test) print("预测值为:\n", y_predict) print("模型中的系数为:\n", estimator.coef_) print("模型中的偏置为:\n", estimator.intercept_) # 5.2 评价 # 均方误差 error = mean_squared_error(y_test, y_predict) print("误差为:\n", error) if __name__ == '__main__': # line_model1() linear_model2()

