
1.K-近邻算法基础
1:k-紧邻算法的概念
K Nearest Neighbor算法又叫KNN算法,这个算法是机器学习里面一个比较经典的算法, 总体来说KNN算法是相对比较容易理解的算法
1:定义:
如果一个样本再特征空间中中的 k个最相似(即特征空间中最邻近)的样本中的大多数属于某一个类别,则该样本属于这个类别
2:来源:
KNN算法最早是由Cover和Hart提出的一种分类算法
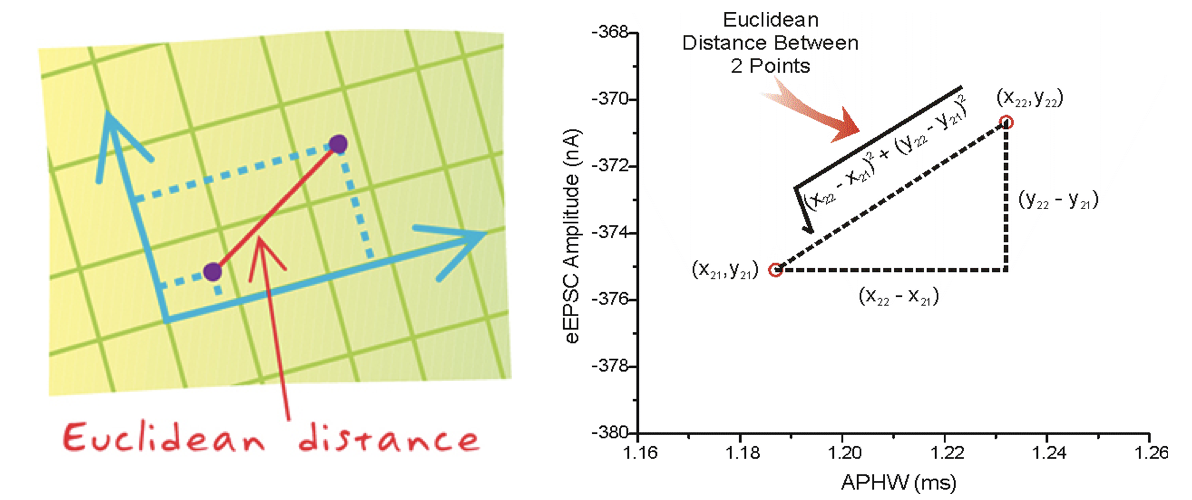
3:距离公式
两个样本的距离可以通过如下公式计算,又叫欧式距离 ,关于距离公式会在后面进行讨论
1.2 电影类型分析
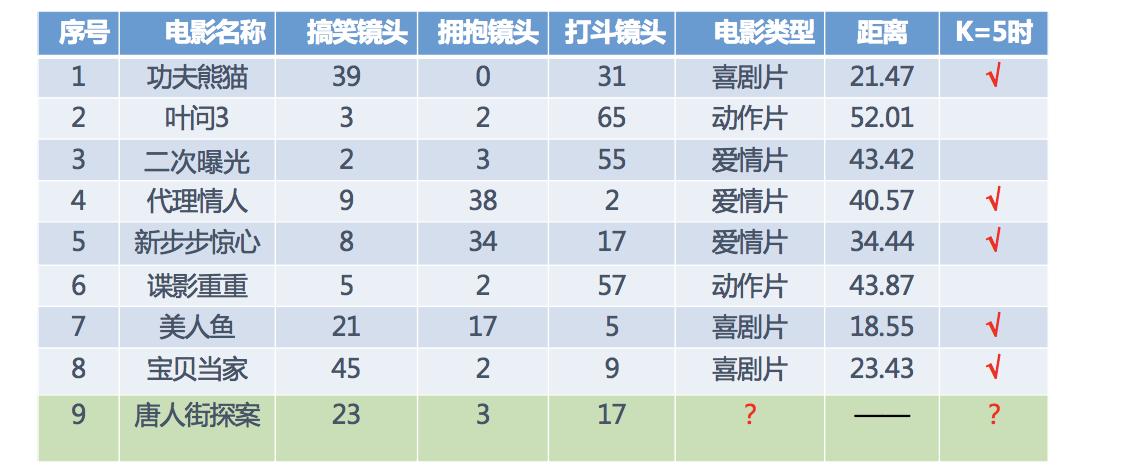
假设我们现在有几部电影
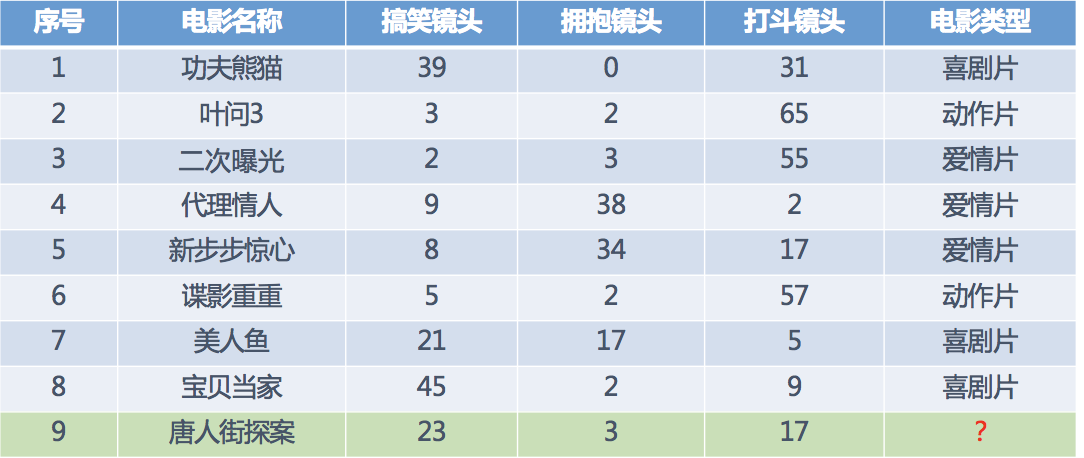
其中? 号电影不知道类别,如何去预测?我们可以利用K近邻算法的思想
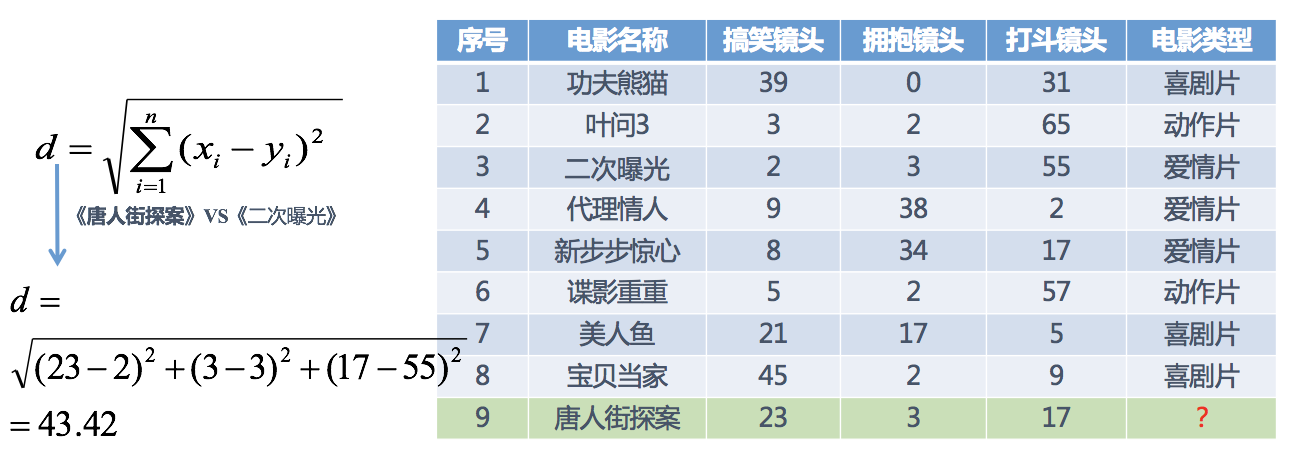
分别计算每个电影和被预测电影的距离,然后求解
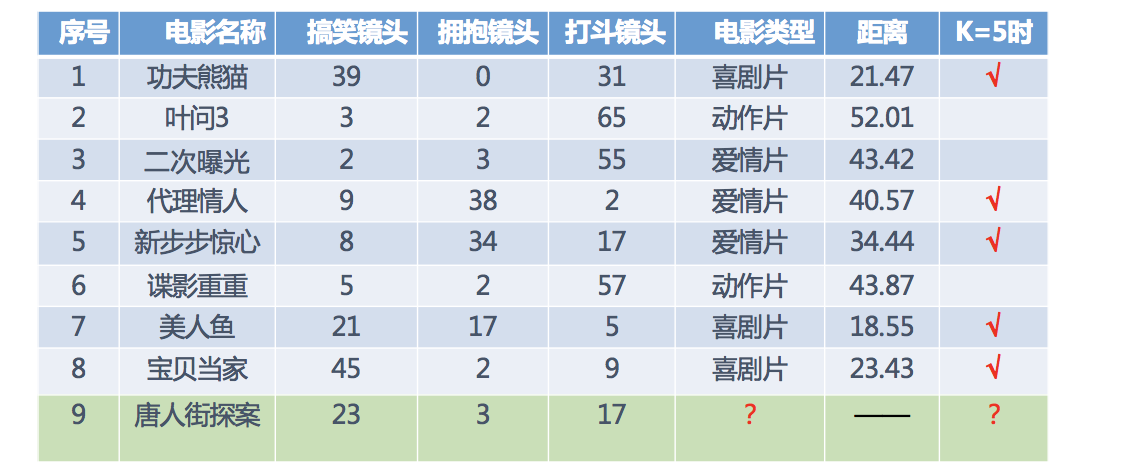
2:K近邻算法api初步使用
1:机器学习流程
- 获取数据集
- 数据基本处理
- 特征工程
- 机器学习
- 模型评估
2:Scikit-learn工具介绍
- Python语言的机器学习工具
- Scikit-learn包括许多知名的机器学习算法的实现
- Scikit-learn文档完善,容易上手,丰富的API (https://www.cntofu.com/book/170/docs/79.md)
- 目前稳定版本0.19.1
2.1:安装
pip3 install scikit-learn==0.19.1
安装好之后可以通过以下命令查看是否安装成功
import sklearn
2.2 Scilit-learn 包含得内容
- 分类、聚类、回归
- 特征工程
- 模型选择、调优
3:K-近邻算法API
- sklearn.neighbors.KNeighborsClassifier(n_neighbors=5)
- n_neighbors:int,可选(默认= 5),k_neighbors查询默认使用的邻居数
4:案例
from sklearn.neighbors import KNeighborsClassifier x = [[0], [1], [2], [3]] y = [0, 0, 1, 1] # 实例化api estimator = KNeighborsClassifier(n_neighbors=2) # 使用fit 方法进行训练 estimator.fit(x,y) ret = estimator.predict([[1]]) print(ret)
3:距离度量
1:欧式距离
欧氏距离是最容易直观理解的距离度量方法,我们小学、初中和高中接触到的两个点在空间中的距离一般都是指欧氏距离

举例:
X=[[1,1],[2,2],[3,3],[4,4]];
经计算得:
d = 1.4142 2.8284 4.2426 1.4142 2.8284 1.4142
2:曼哈顿距离
在曼哈顿街区要从一个十字路口开车到另一个十字路口,驾驶距离显然不是两点间的直线距离。这个实际驾驶距离就是“曼哈顿距离”。曼哈顿距离也称为“城市街区距离”(City Block distance)
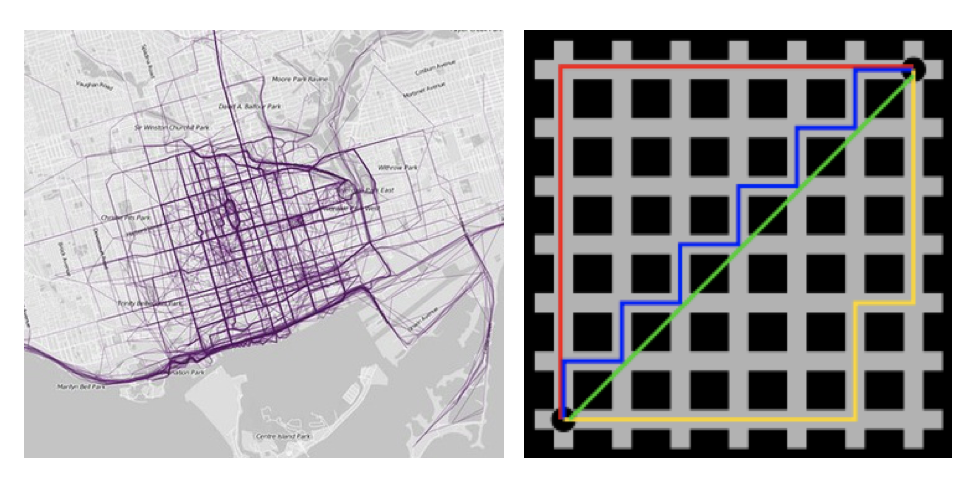
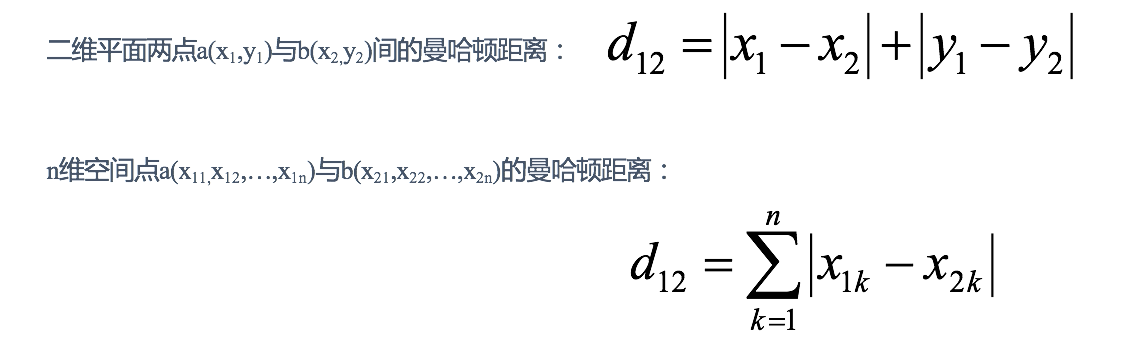
举例:
X=[[1,1],[2,2],[3,3],[4,4]];
经计算得:
d = 2 4 6 2 4 2
3:切比雪夫距离
国际象棋中,国王可以直行、横行、斜行,所以国王走一步可以移动到相邻8个方格中的任意一个。国王从格子(x1,y1)走到格子(x2,y2)最少需要多少步?这个距离就叫切比雪夫距离
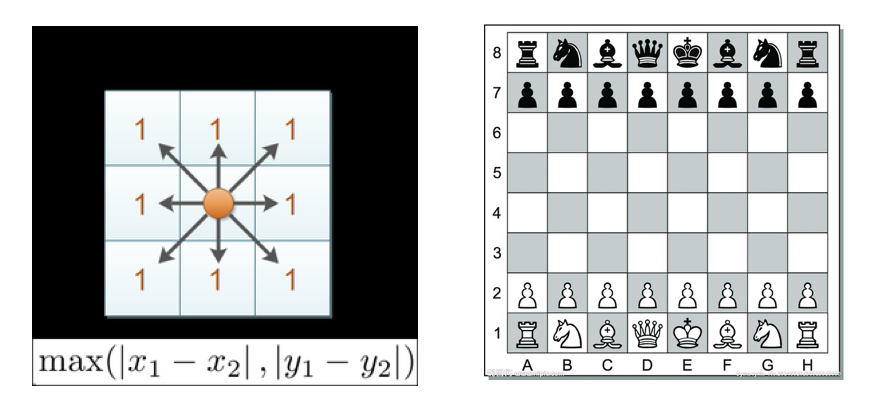
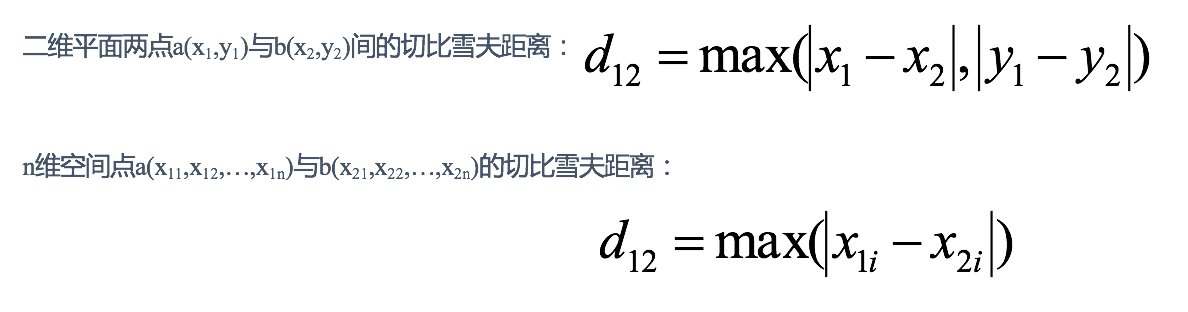
举例:
X=[[1,1],[2,2],[3,3],[4,4]];
经计算得:
d = 1 2 3 1 2 1
4: 闵可夫斯基距离
闵氏距离不是一种距离,而是一组距离的定义,是对多个距离度量公式的概括性的表述。
两个n维变量a(x11,x12,…,x1n)与b(x21,x22,…,x2n)间的闵可夫斯基距离定义为:
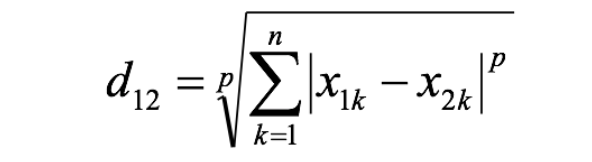
其中p是一个变参数:
当p=1时,就是曼哈顿距离;
当p=2时,就是欧氏距离;
当p→∞时,就是切比雪夫距离。
根据p的不同,闵氏距离可以表示某一类/种的距离。
小结:
1 闵氏距离,包括曼哈顿距离、欧氏距离和切比雪夫距离都存在明显的缺点:
e.g. 二维样本(身高[单位:cm],体重[单位:kg]),现有三个样本:a(180,50),b(190,50),c(180,60)。
a与b的闵氏距离(无论是曼哈顿距离、欧氏距离或切比雪夫距离)等于a与c的闵氏距离。但实际上身高的10cm并不能和体重的10kg划等号。
2 闵氏距离的缺点:
(1)将各个分量的量纲(scale),也就是“单位”相同的看待了;
(2)未考虑各个分量的分布(期望,方差等)可能是不同的
5:标准化欧式距离
标准化欧氏距离是针对欧氏距离的缺点而作的一种改进。
思路:既然数据各维分量的分布不一样,那先将各个分量都“标准化”到均值、方差相等。假设样本集X的均值(mean)为m,标准差(standard deviation)为s,X的“标准化变量”表示为
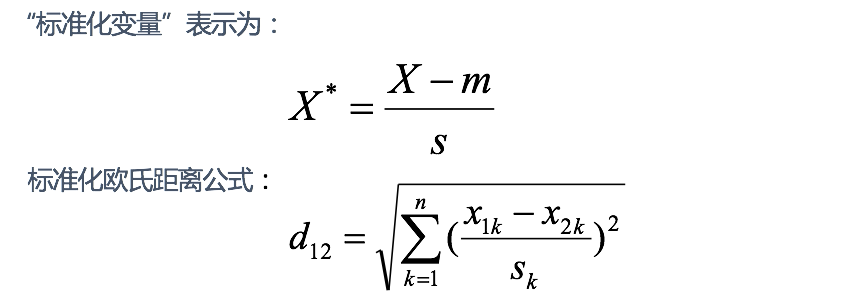
如果将方差的倒数看成一个权重,也可称之为加权欧氏距离(Weighted Euclidean distance)。
举例:
X=[[1,1],[2,2],[3,3],[4,4]];(假设两个分量的标准差分别为0.5和1)
经计算得:
d = 2.2361 4.4721 6.7082 2.2361 4.4721 2.2361
6:余弦距离
几何中,夹角余弦可用来衡量两个向量方向的差异;机器学习中,借用这一概念来衡量样本向量之间的差异。
- 二维空间中向量A(x1,y1)与向量B(x2,y2)的夹角余弦公式:
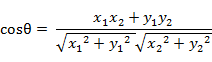
- 两个n维样本点a(x11,x12,…,x1n)和b(x21,x22,…,x2n)的夹角余弦为:
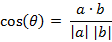
即:
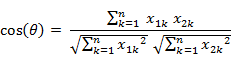
夹角余弦取值范围为[-1,1]。余弦越大表示两个向量的夹角越小,余弦越小表示两向量的夹角越大。当两个向量的方向重合时余弦取最大值1,当两个向量的方向完全相反余弦取最小值-1。
举例:
X=[[1,1],[1,2],[2,5],[1,-4]]
经计算得:
d = 0.9487 0.9191 -0.5145 0.9965 -0.7593 -0.8107
7:汉明距离(了解)
8:杰卡德距离(了解)
9:马氏距离(了解)
4:K值得选择
K值过小:
容易受到异常点的影响
k值过大:
受到样本均衡的问题
K值选择问题,李航博士的一书「统计学习方法」上所说:
1) 选择较小的K值,就相当于用较小的领域中的训练实例进行预测,“学习”近似误差会减小,只有与输入实例较近或相似的训练实例才会对预测结果起作用,与此同时带来的问题是“学习”的估计误差会增大,换句话说,K值的减小就意味着整体模型变得复杂,容易发生过拟合;
2) 选择较大的K值,就相当于用较大领域中的训练实例进行预测,其优点是可以减少学习的估计误差,但缺点是学习的近似误差会增大。这时候,与输入实例较远(不相似的)训练实例也会对预测器作用,使预测发生错误,且K值的增大就意味着整体的模型变得简单。
3) K=N(N为训练样本个数),则完全不足取,因为此时无论输入实例是什么,都只是简单的预测它属于在训练实例中最多的类,模型过于简单,忽略了训练实例中大量有用信息。
在实际应用中,K值一般取一个比较小的数值,例如采用交叉验证法(简单来说,就是把训练数据在分成两组:训练集和验证集)来选择最优的K值。对这个简单的分类器进行泛化,用核方法把这个线性模型扩展到非线性的情况,具体方法是把低维数据集映射到高维特征空间。
近似误差:
对现有训练集的训练误差,关注训练集,如果近似误差过小可能会出现过拟合的现象,对现有的训练集能有很好的预测,但是对未知的测试样本将会出现较大偏差的预测。模型本身不是最接近最佳模型。
估计误差:
可以理解为对测试集的测试误差,关注测试集,估计误差小说明对未知数据的预测能力好,模型本身最接近最佳模型。

